Analisis cluster pengorganisasian kumpulan pola ke dalam cluster (kelompok-kelompok) berdasar atas kesamaannya. Pola-pola dalam suatu cluster akan
|
|
|
- Surya Gunawan
- 5 tahun lalu
- Tontonan:
Transkripsi

1

2 Analisis cluster pengorganisasian kumpulan pola ke dalam cluster (kelompok-kelompok) berdasar atas kesamaannya. Pola-pola dalam suatu cluster akan memiliki kesamaan ciri/sifat daripada pola-pola dalam kluster yang lainnya.

; yaitu kesamaan antar anggota dalam satu cluster.")
3 Tujuan dari Analisis Cluster adalah mengelompokkan obyek berdasarkan kesamaan karakteristik di antara obyek-obyek tersebut. Dengan demikian, ciri-ciri suatu cluster yang baik yaitu mepunyai : Homogenitas internal (within cluster); yaitu kesamaan antar anggota dalam satu cluster. Heterogenitas external (between cluster); yaitu perbedaan antara cluster yang satu dengan cluster yang lain.
4 Hirarkis memulai pengelompokan dengan dua atau lebih obyek yang mempunyai kesamaan paling dekat. terdapat tingkatan (hirarki) yang jelas antar obyek, dari yang paling mirip hingga yang paling tidak mirip. Tools dendogram Non Hirarkis dimulai dengan menentukan terlebih dahulu jumlah cluster yang diinginkan (dua,tiga, atau yang lain). Setelah jumlah cluster ditentukan, maka proses cluster dilakukan dengan tanpa mengikuti proses hirarki. Metode ini biasa disebut K-Means Cluster.


5 Wellseparated clusters Centerbased clusters Densitybased clusters sehimpunan titik yang memiliki kemiripan dengan titik lain dalam cluster daripada di cluster lain. Sebuah cluster yang memiliki anggota-anggota yang mirip dengan pusat cluster daripada pusat cluster lain. Pusat cluster: Centroid: Rata-rata dari semua titik dalam cluster Medoid: memilih titik sebagi titik tengah. area padat titik, yang dipisahkan dengan area kepadatan rendah, dari area kepadatan tinggi lainnya. Digunakan ketika cluster tidak teratur atau saling terkait, dan ketika noise dan outliers hadir.

6 Kedekatan pola biasanya diukur dengan fungsi jarak antar dua pasang pola. cosine similarity, manhattan distance, dan euclidean distance.
7 Sampel yang diambil benar-benar dapat mewakili populasi yang ada (representativeness of the sample) Multikolinieritas.
8 CONTOH Dari penelitian yang dilakukan terhadap 12 kota, ingin diketahui pengelompokan kota-kota tersebut berdasarkan instrumen 5 variabel yaitu : 1. jumlah pendapatan kota (trilyun Rp) 2. jumlah pinjaman pemerintah kota (milyar Rp) 3. jumlah dana hibah yang dimiliki kota (milyar Rp) 4. jumlah konsumsi pemerintah kota (milyar Rp) 5. Jumlah penduduk kota (juta jiwa).
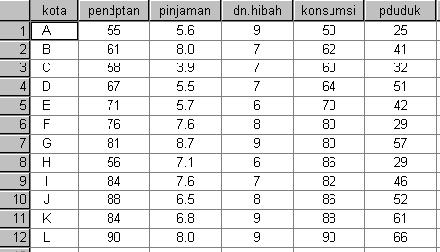
9
 Setelah keseluruhan data yang dikumpulkan tersebut diatas dientry dalam program SPSS, selanjutnya klik menu analyze dan pilih sub menu Descriptives Statistics lalu")
10 Mengingat data yang terkumpul mempunyai variabilitas satuan, maka perlu dilakukan langkah standardisasi atau transformasi terhadap variabel yang relevan ke bentuk zscore, sebagai berikut : 1) Setelah keseluruhan data yang dikumpulkan tersebut diatas dientry dalam program SPSS, selanjutnya klik menu analyze dan pilih sub menu Descriptives Statistics lalu Descriptives
11
12 Masukkan ke dalam kotak VARIABLES seluruh variabel instrumen penilai, yaitu variabel jumlah pendapatan, jumlah pinjaman, jumlah dana hibah, jumlah konsumsi,dan jumlah penduduk. (dalam hal ini variabel kota tidak dimasukkan karena data bertipe string). Kemudian aktifkan bagian Save standardized values as Variables. Abaikan bagian yang lain lalu tekan OK untuk menampilkan output aplikasi program SPSS.
13 Sebagai dasar perhitungan Z- score

14 Tampilan dataview

15 Dari tampilan data yang tertera (hasil standardisasi/transformasi), buka menu Analyze, lalu pilih sub menu Classify dan pilih K- Means Cluster
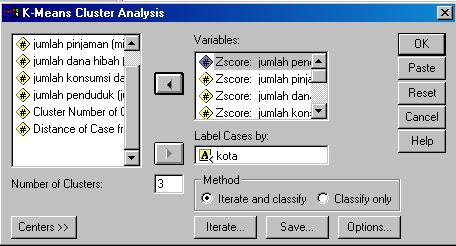
16
17 Masukkan seluruh variabel Z-Score ke dalam kotak VARIABLES. Kemudian variabel Kota dimasukkan dalam kotak Label Cases by... Number of Clusters dalam hal ini diisi menurut jumlah cluster yang akan dibentuk dalam penelitian yang dimaksud. Misal diiisi 3, berarti diharapkan akan dibentuknya 3 cluster. Kemudian klik mouse pada kotak Save

18 Aktifkan kedua kotak dalam menu Save, yaitu Cluster membership dan Distance from cluster center. Selanjutnya tekan tombol Continue untuk kembali ke menu utama.

19 Pada bagian Statistics, aktifkan Initial cluster centers dan ANOVA table. Abaikan bagian yang lain, lalu tekan Continue untuk kembali ke menu utama.

20 Tampilan pertama proses clustering data sebelum dilakukan iterasi

21 Untuk mendeteksi berapa kali proses iterasi yang dilakukan dalam proses clustering dari 12 obyek yang diteliti, dapat dilihat pad tabel berikut: Tahapan clustering cukup dengan 2 iterasi Jarak minimum
22 Output Final Cluster Centers tersebut masih terkait dengan proses standardisasi data sebelumnya, yang mengacu pada z-score dengan ketentuan sebagai berikut : Nilai negatif (-) berarti data berada di bawah rata-rata total. Nilai positif (+)berarti data berada di atas rata-rata total.
23 Rumus umum yang digunakan yaitu : Sebagai contoh, apabila ingin diketahui rata-rata jumlah pendapatan kota di cluster-1 yaitu : (rata-rata pendapatan seluruh kota) + (0,98858 x standar deviasi rata-rata pendapatan) = 72,58 + (0,98858 x 12,965) = 85,3969 Jadi rata-rata jumlah pendapatan kota yang berada di cluster-1 adalah Rp 85,3969 trilyun. Demikian seterusnya dapat diketahui rata-rata nilai masing-masing variabel dalam tiap cluster.
24 Cluster-1 Dalam cluster-1 ini berisikan kota-kota yang mempunyai jumlah pendapatan kota, jumlah pinjaman, jumlah dana hibah, jumlah konsumsi, dan jumlah penduduk yang lebih dari rata-rata populasi kota yang diteliti. Hal ini terbukti dari nilai positif (+) yang terdapat pada tabel Final Cluster Centers dalam keseluruhan variabel. Dengan demikian, dapat diduga bahwa cluster-1 ini merupakan pengelompokan dari kota-kota besar
25 Karakteristik kota yang masuk dalam pengelompokan cluster-2 yaitu memiliki ratarata jumlah pinjaman dan jumlah konsumsi yang melebihi rata-rata populasi kota yang diteliti. Dengan demikian, dapat diduga sekumpulan kotakota menengah berada pada cluster-2.
26 Sedangkan karakteristik kota-kota yang mengelompok pada cluster- 3 adalah keseluruhan instrumen penilai berada pada posisi dibawah ratarata populasi kota yang diteliti. Sehingga dapat diduga bahwa cluster-3 merupakan pengelompokan kota-kota kecil.
27
28 Tahapan berikutnya adalah melihat perbedaan variabel pada cluster yang terbentuk. Dalam hal ini dapat dilihat dari nilai F dan nilai probabilitas (sig) masing-masing variabel
29

30 Cluster 1 beranggotakan 5 kota Cluster 2 beranggotakan 3 kota Cluster 3 beranggotakan 4 kota

31 Nomor CLuster Jarak antara objek dengan pusat Cluster
32 Cluster-1 berisikan kota G, I, J, K, dan L dengan masing-masing jarak terhadap pusat cluster-1 adalah 1,13345; 1,45998; 0,90703; 0,84724; dan 1, Cluster-2 berisikan kota B, F, dan H, dengan masingmasing jarak terhadap pusat cluster-2 adalah 1,28390; 1,31905; dan 1, Cluster-3 berisikan kota A, C, D, dan E, dengan masing-masing jarak terhadap pusat cluster-3 adalah 2,07346; 1,10283; 1,11895; dan 1,51738.
33 Konsep dari metode hirarkis ini dimulai dengan menggabungkan 2 obyek yang paling mirip, kemudian gabungan 2 obyek tersebut akan bergabung lagi dengan satu atau lebih obyek yang paling mirip lainnya. Proses clustering ini pada akhirnya akan menggumpal menjadi satu cluster besar yang mencakup semua obyek. Metode ini disebut juga sebagai metode aglomerativ yang digambarkan dengan dendogram.

34 Langkah SPSS 1. Masih dengan data sebelumnya, yang merupakan hasil standardisasi, buka menu Analyze lalu pilih sub menu Classify kemudian Hierarchical Cluster hingga muncul tampilan seperti berikut ini : 2. Masukkan seluruh variabel yang telah distandardkan (Z-score) ke dalam bagian Variable(s). Untuk bagian Label Cases by isi dengan variabel kota; sedangkan untuk bagian Cluster pilih Cases; pada bagian Display pilih keduanya yaitu Statistics dan Plots.
35
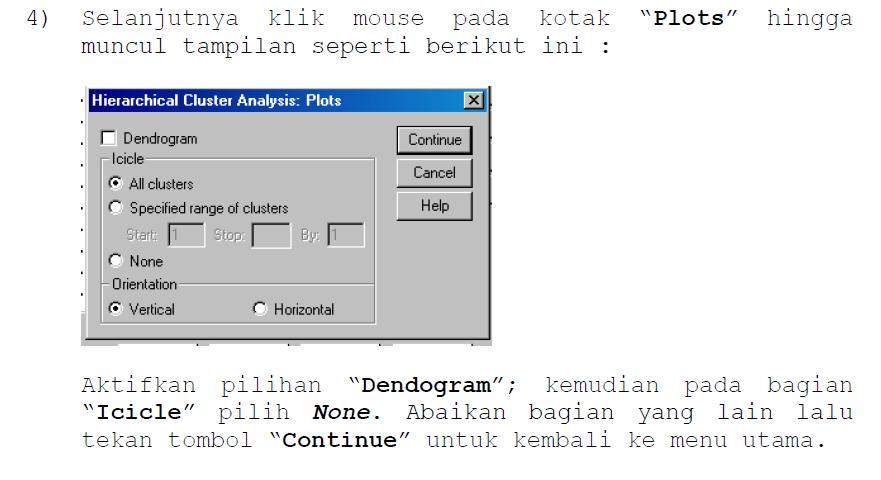
36

37 Pada bagian Cluster Method pilih Between groups linkage. Kemudian buka kotak combo Square Euclidean distance pada Measure ; dan pada Transform Values buka kotak combo pada pilihan Z-score. Abaikan bagian yang lain lalu tekan tombol Continue untuk kembali ke menu utama.

38 menunjukkan bahwa semua data sejumlah 12 obyek telah diproses tanpa ada data yang hilang. menujukkan matrik jarak antar variabel Semakin kecil jarak euclidean, maka semakin mirip kedua variabel tersebut sehingga akan membentuk kelompok (cluster).
39 hasil proses clustering dengan metode Between Group Linkage. Setelah jarak antar variabel diukur dengan jarak euclidean, maka dilakukan pengelompokan, yang dilakukan secara bertingkat.
40 Stage 1 : terbentuk 1 cluster yang beranggotakan Kota K dan Kota L dengan jarak 1,139 Karena proses aglomerasi dimulai dari 2 obyek yang terdekat, maka jarak tersebut adalah yang terdekat dari sekian kombinasi jarak 12 obyek yang ada.
41 Baris ke-4 (stage 4) terlihat obyek ke-7 (Kota G) membentuk cluster dengan Kota K. Dengan demikian, sekarang cluster terdiri dari 3 obyek yaitu Kota G, K, dan L. Sedangkan jarak sebesar 2,097 merupakan jarak rata-rata obyek terakhir yang bergabing dengan 2 obyek sebelumnya, seperti tampak dalam Proximity matrix dan dapat dihitung sebagai berikut : - Jarak Kota G dan K = 2,432 - Jarak Kota G dan L = 1,761 - Jarak rata-rata = (2, ,761) / 2 = 2,0965
42 Stage 2 : terjadi pembentukan cluster Kota D dan Kota E berjarak 1,515), yang kemudian berlanjut ke stage 6. Demikian seterusnya dari stage 3 dilanjutkan ke stage 5, sampai ke stage terakhir.

43 Proses aglomerasi ini bersifat kompleks, khususnya perhitungan koefisien yang melibatkan sekian banyak obyek dan terus bertambah. Proses aglomerasi pada akhirnya akan menyatukan semua obyek menjadi satu cluster. Hanya saja dalam prosesnya dihasilkan beberapa cluster dengan masing-masing anggotanya, tergantung jumlah cluster yang dibentuk.
44 Apabila diinginkan dibentuk 4 cluster, maka : Anggota cluster 1 adalah Kota A Anggota cluster 2 adalah Kota B dan Kota H Anggota cluster 3 adalah C, D, dan E Anggota cluster 4 adalah Kota F, G, I, J, K, dan L.
45 Apabila ditentukan dibentuk 3 cluster, maka : Anggota cluster 1 adalah Kota A Anggota cluster 2 adalah Kota B, C, D, E, dan H. Anggota cluster 3 adalah Kota F, G, I, J, K, dan L.
46 Apabila ditentukan dibentuk 2 cluster, maka : Anggota cluster 1 adalah Kota A, B, C, D, E, dan H Anggota cluster 2 adalah Kota F, G, I, J, K, dan L.
47 Dendogram berguna untuk menunjukkan anggota cluster yang ada jika akan ditentukan berapa cluster yang seharusnya dibentuk. Sebagai contoh yang terlihat dalam dendogram, apabila akan dibentuk 2 cluster, maka cluster 1 beranggotakan Kota K sampai dengan Kota F (sesuai urutan dalam dendogram); dan cluster2 beranggotakan Kota D sampai dengan Kota A. Demikian seterusnya dapat dengan mudah dilihat anggota tiap cluster sesuai jumlah cluster yang diinginkan.
48
MODUL 6 ANALISIS CLUSTER
 MODUL 6 ANALISIS CLUSTER Tujuan Praktikum Pada modul 6 ini, tujuan yang hendak dicapai dalam pelaksanaan praktikum antara lain : Mahasiswa mampu mengenali karakteristik analisis cluster. Mahasiswa memahami
MODUL 6 ANALISIS CLUSTER Tujuan Praktikum Pada modul 6 ini, tujuan yang hendak dicapai dalam pelaksanaan praktikum antara lain : Mahasiswa mampu mengenali karakteristik analisis cluster. Mahasiswa memahami
BAB I PENDAHULUAN. 1.1 Latar Belakang
 BAB I PENDAHULUAN 1.1 Latar Belakang Analisis cluster merupakan teknik multivariat yang mempunyai tujuan utama untuk mengelompokkan objek-objek berdasarkan karakteristik yang dimilikinya. Analisis cluster
BAB I PENDAHULUAN 1.1 Latar Belakang Analisis cluster merupakan teknik multivariat yang mempunyai tujuan utama untuk mengelompokkan objek-objek berdasarkan karakteristik yang dimilikinya. Analisis cluster
BAB IV PENGOLAHAN DATA
 BAB IV PENGOLAHAN DATA 4.1 Non-Hirarki Cluster (K-Means Cluster) 4.1.1 Print Output dan Analisa Output A. Initial Cluster Center Initial Cluster Centers Cluster 1 2 Kenyamanan 2 5 Kebersihan 3 5 Luas_Parkir
BAB IV PENGOLAHAN DATA 4.1 Non-Hirarki Cluster (K-Means Cluster) 4.1.1 Print Output dan Analisa Output A. Initial Cluster Center Initial Cluster Centers Cluster 1 2 Kenyamanan 2 5 Kebersihan 3 5 Luas_Parkir
Tipe Clustering. Partitional Clustering. Hirerarchical Clustering
 Analisis Cluster Analisis Cluster Analisis cluster adalah pengorganisasian kumpulan pola ke dalam cluster (kelompok-kelompok) berdasar atas kesamaannya. Pola-pola dalam suatu cluster akan memiliki kesamaan
Analisis Cluster Analisis Cluster Analisis cluster adalah pengorganisasian kumpulan pola ke dalam cluster (kelompok-kelompok) berdasar atas kesamaannya. Pola-pola dalam suatu cluster akan memiliki kesamaan
MODUL 3 ANALISIS FAKTOR
 TUJUAN PRAKTIKUM Tujuan dari praktikum modul 3 ini adalah : 1. Mahasiswa memahami apa yang dilakukan dalam proses Analisis Faktor; 2. Mahasiswa dapat menjalankan prosedur Analisis Faktor dalam SPSS; 3.
TUJUAN PRAKTIKUM Tujuan dari praktikum modul 3 ini adalah : 1. Mahasiswa memahami apa yang dilakukan dalam proses Analisis Faktor; 2. Mahasiswa dapat menjalankan prosedur Analisis Faktor dalam SPSS; 3.
MODUL 1 UJI DATA ( 1 ) ANALISIS MISSING VALUE & OUTLIER
 ANALISIS MISSING VALUE & OUTLIER") MODUL 1 UJI DATA ( 1 ) ANALISIS MISSING VALUE & OUTLIER Tujuan dari praktikum modul 1 ini, agar mahasiswa mampu : 1. Mengenali karakteristik missing value.. Memberikan perlakuan atau solusi pemecahan terhadap
MODUL 1 UJI DATA ( 1 ) ANALISIS MISSING VALUE & OUTLIER Tujuan dari praktikum modul 1 ini, agar mahasiswa mampu : 1. Mengenali karakteristik missing value.. Memberikan perlakuan atau solusi pemecahan terhadap
MODUL 5 ANALISIS DISKRIMINAN
 MODUL 5 ANALISIS DISKRIMINAN TUJUAN PRAKTIKUM Tujuan yang diharapkan dalam pelaksanaan praktikum ini, antara lain : Mahasiswa memahami karakteristik dan kegunaan Metode Analisis Diskriminan. Mahasiswa
MODUL 5 ANALISIS DISKRIMINAN TUJUAN PRAKTIKUM Tujuan yang diharapkan dalam pelaksanaan praktikum ini, antara lain : Mahasiswa memahami karakteristik dan kegunaan Metode Analisis Diskriminan. Mahasiswa
ANALISIS CLUSTER PADA DOKUMEN TEKS
 Text dan Web Mining - FTI UKDW - BUDI SUSANTO 1 ANALISIS CLUSTER PADA DOKUMEN TEKS Budi Susanto (versi 1.3) Text dan Web Mining - FTI UKDW - BUDI SUSANTO 2 Tujuan Memahami konsep analisis clustering Memahami
Text dan Web Mining - FTI UKDW - BUDI SUSANTO 1 ANALISIS CLUSTER PADA DOKUMEN TEKS Budi Susanto (versi 1.3) Text dan Web Mining - FTI UKDW - BUDI SUSANTO 2 Tujuan Memahami konsep analisis clustering Memahami
MATERI PRAKTIKUM PRAKTIKUM 3 ANALISA CLUSTER
 PRAKTIKUM 3 ANALISA CLUSTER Definisi Analisis cluster merupakan pengelompokan objek berdasarkan informasi yang diperoleh dari suatu data yang menjelaskan hubungan antar objek satu dengan objek lainnya.
PRAKTIKUM 3 ANALISA CLUSTER Definisi Analisis cluster merupakan pengelompokan objek berdasarkan informasi yang diperoleh dari suatu data yang menjelaskan hubungan antar objek satu dengan objek lainnya.
Analisis Cluster Studi Kasus: Kabupaten Jepara Jawa Tengah
 Analisis Cluster Studi Kasus: Kabupaten Jepara Jawa Tengah Disusun untuk Memenuhi Tugas Mata Kuliah Metode Analisis Perencanaan (TKP 34) Dosen Pengampu: Dr. Iwan Rudiarto Widjanarko, S.T., M.T. Sri Rahayu,
Analisis Cluster Studi Kasus: Kabupaten Jepara Jawa Tengah Disusun untuk Memenuhi Tugas Mata Kuliah Metode Analisis Perencanaan (TKP 34) Dosen Pengampu: Dr. Iwan Rudiarto Widjanarko, S.T., M.T. Sri Rahayu,
ANALISIS CLUSTER PADA DOKUMEN TEKS
 Budi Susanto ANALISIS CLUSTER PADA DOKUMEN TEKS Text dan Web Mining - FTI UKDW - BUDI SUSANTO 1 Tujuan Memahami konsep analisis clustering Memahami tipe-tipe data dalam clustering Memahami beberapa algoritma
Budi Susanto ANALISIS CLUSTER PADA DOKUMEN TEKS Text dan Web Mining - FTI UKDW - BUDI SUSANTO 1 Tujuan Memahami konsep analisis clustering Memahami tipe-tipe data dalam clustering Memahami beberapa algoritma
BAB III METODE PENELITIAN
 BAB III METODE PENELITIAN 3.1 Tempat dan Waktu Penelitian Penelitian telah dilaksanakan di Kebun Bibit Permanen, Kecamatan Kedungpring, Lamongan dan di Laboratorium Biosistematika, Departemen Biologi,
BAB III METODE PENELITIAN 3.1 Tempat dan Waktu Penelitian Penelitian telah dilaksanakan di Kebun Bibit Permanen, Kecamatan Kedungpring, Lamongan dan di Laboratorium Biosistematika, Departemen Biologi,
DATA MINING DAN WAREHOUSE A N D R I
 DATA MINING DAN WAREHOUSE A N D R I CLUSTERING Secara umum cluster didefinisikan sebagai sejumlah objek yang mirip yang dikelompokan secara bersama, Namun definisi dari cluster bisa beragam tergantung
DATA MINING DAN WAREHOUSE A N D R I CLUSTERING Secara umum cluster didefinisikan sebagai sejumlah objek yang mirip yang dikelompokan secara bersama, Namun definisi dari cluster bisa beragam tergantung
BAB 2 TINJAUAN PUSTAKA
 BAB 2 TINJAUAN PUSTAKA 2.1. Tinjauan Pustaka Riset pasar dilakukan terlebih dahulu untuk mengetahui produk yang memungkinkan untuk diproduksi di UPT Ragam Metal. Riset pasar yang dilakukan oleh Fiktarina
BAB 2 TINJAUAN PUSTAKA 2.1. Tinjauan Pustaka Riset pasar dilakukan terlebih dahulu untuk mengetahui produk yang memungkinkan untuk diproduksi di UPT Ragam Metal. Riset pasar yang dilakukan oleh Fiktarina
MATERI PRAKTIKUM PRAKTIKUM 3 ANALISA CLUSTER
 PRAKTIKUM 3 ANALISA CLUSTER Definisi Cluster Analisis cluster merupakan pengelompokan objek berdasarkan informasi yang diperoleh dari suatu data yang menjelaskan hubungan antar objek satu dengan objek
PRAKTIKUM 3 ANALISA CLUSTER Definisi Cluster Analisis cluster merupakan pengelompokan objek berdasarkan informasi yang diperoleh dari suatu data yang menjelaskan hubungan antar objek satu dengan objek
Rancangan Percobaan dengan SPSS 13.0 (Untuk kalangan sendiri)
") Rancangan Percobaan dengan SPSS 13.0 (Untuk kalangan sendiri) Statistical Product and Service Solution (SPSS) merupakan salah satu perangkat lunak/software statistik yang dapat digunakan sebagai alat pengambil
Rancangan Percobaan dengan SPSS 13.0 (Untuk kalangan sendiri) Statistical Product and Service Solution (SPSS) merupakan salah satu perangkat lunak/software statistik yang dapat digunakan sebagai alat pengambil
MODUL 2 UJI DATA NORMALITAS, HOMOSEDASTISITAS, & LINIERITAS
 TUJUAN PRAKTIKUM Tujuan dari praktikum modul 2 ini adalah : 1. Mahasiswa mampu menilai kualitas data yang hendak digunakan dalam penelitian; 2. Mahasiswa mampu menelaah apakah data yang dimiliki memenuhi
TUJUAN PRAKTIKUM Tujuan dari praktikum modul 2 ini adalah : 1. Mahasiswa mampu menilai kualitas data yang hendak digunakan dalam penelitian; 2. Mahasiswa mampu menelaah apakah data yang dimiliki memenuhi
PAIRED-SAMPLES T TEST
 PAIRED-SAMPLES T TEST Bab ini menjelaskan tentang: Pengertian dasar prosedur Paired-Samples T Test Contoh studi kasus Paired-Samples T Test Langkah melakukan prosedur Paired-Samples T Test Teknik membaca
PAIRED-SAMPLES T TEST Bab ini menjelaskan tentang: Pengertian dasar prosedur Paired-Samples T Test Contoh studi kasus Paired-Samples T Test Langkah melakukan prosedur Paired-Samples T Test Teknik membaca
Analisis Diskriminan
 Analisis Diskriminan Analisis Diskriminan adalah teknik Multivariat yang termasuk pada Dependence Method, dengan ciri adanya variabel dependen dan independen. Dengan demikian, ada variabel yang hasilnya
Analisis Diskriminan Analisis Diskriminan adalah teknik Multivariat yang termasuk pada Dependence Method, dengan ciri adanya variabel dependen dan independen. Dengan demikian, ada variabel yang hasilnya
Perhitungan Uji Keseragaman & Keseragaman Data Menggunakan Excel Nama. Dicatat Oleh: Waktu Penyelesaian (detik)
") Perhitungan Uji Keseragaman & Keseragaman Data Menggunakan Excel Tanggal 06/Mei/2013 Waktu 07.00-14.00 Nama WIB Proses: Operator Pak. Septian Kebisingan 70-80 db Dicatat Oleh: Jumlah Waktu Penyelesaian
Perhitungan Uji Keseragaman & Keseragaman Data Menggunakan Excel Tanggal 06/Mei/2013 Waktu 07.00-14.00 Nama WIB Proses: Operator Pak. Septian Kebisingan 70-80 db Dicatat Oleh: Jumlah Waktu Penyelesaian
PENGELOMPOKAN KABUPATEN/KOTA DI KALIMANTAN BARAT BERDASARKAN INDIKATOR DALAM PEMERATAAN PENDIDIKAN MENGGUNAKAN METODE MINIMAX LINKAGE
 Buletin Ilmiah Mat. Stat. dan Terapannya (Bimaster) Volume 05, No. 02 (2016), hal 253-260 PENGELOMPOKAN KABUPATEN/KOTA DI KALIMANTAN BARAT BERDASARKAN INDIKATOR DALAM PEMERATAAN PENDIDIKAN MENGGUNAKAN
Buletin Ilmiah Mat. Stat. dan Terapannya (Bimaster) Volume 05, No. 02 (2016), hal 253-260 PENGELOMPOKAN KABUPATEN/KOTA DI KALIMANTAN BARAT BERDASARKAN INDIKATOR DALAM PEMERATAAN PENDIDIKAN MENGGUNAKAN
BAB IV ANALISIS DAN PERANCANGAN
 BAB IV ANALISIS DAN PERANCANGAN 4.1. Analisa 4.1.1 Analisis Data Pada tahap analisa data ini akan dibahas mengenai citra CT Scan yang akan dilakukan proses segmentasi atau pengelompokan data. Data citra
BAB IV ANALISIS DAN PERANCANGAN 4.1. Analisa 4.1.1 Analisis Data Pada tahap analisa data ini akan dibahas mengenai citra CT Scan yang akan dilakukan proses segmentasi atau pengelompokan data. Data citra
Analisa Anggaran Pendapatan dan Belanja Daerah (APBD) dengan Metode Hierarchical Clustering
 dengan Metode Hierarchical Clustering") SEMINAR NASIONAL MATEMATIKA DAN PENDIDIKAN MATEMATIKA UNY 2016 Analisa Anggaran Pendapatan dan Belanja Daerah (APBD) dengan Metode Hierarchical Clustering Viga Apriliana Sari, Nur Insani Jurusan Pendidikan
SEMINAR NASIONAL MATEMATIKA DAN PENDIDIKAN MATEMATIKA UNY 2016 Analisa Anggaran Pendapatan dan Belanja Daerah (APBD) dengan Metode Hierarchical Clustering Viga Apriliana Sari, Nur Insani Jurusan Pendidikan
Analisis Perbandingan Rata-rata: Independent-Sample T Test
 Analisis Perbandingan Rata-rata: Tim Pengajar 1 O digunakan untuk menguji signifikansi beda ratarata dua kelompok. Tes ini juga digunakan untuk menguji pengaruh variabel independen terhadap variabel dependen.
Analisis Perbandingan Rata-rata: Tim Pengajar 1 O digunakan untuk menguji signifikansi beda ratarata dua kelompok. Tes ini juga digunakan untuk menguji pengaruh variabel independen terhadap variabel dependen.
METODE CLUSTERING DENGAN ALGORITMA K-MEANS. Oleh : Nengah Widya Utami
 METODE CLUSTERING DENGAN ALGORITMA K-MEANS Oleh : Nengah Widya Utami 1629101002 PROGRAM STUDI S2 ILMU KOMPUTER PROGRAM PASCASARJANA UNIVERSITAS PENDIDIKAN GANESHA SINGARAJA 2017 1. Definisi Clustering
METODE CLUSTERING DENGAN ALGORITMA K-MEANS Oleh : Nengah Widya Utami 1629101002 PROGRAM STUDI S2 ILMU KOMPUTER PROGRAM PASCASARJANA UNIVERSITAS PENDIDIKAN GANESHA SINGARAJA 2017 1. Definisi Clustering
PENERAPAN ALGORITMA K-MEANS PADA KUALITAS GIZI BAYI DI INDONESIA
 PENERAPAN ALGORITMA K-MEANS PADA KUALITAS GIZI BAYI DI INDONESIA Diajeng Tyas Purwa Hapsari Teknik Informatika STMIK AMIKOM Yogyakarta Jl Ring road Utara, Condongcatur, Sleman, Yogyakarta 55281 Email :
PENERAPAN ALGORITMA K-MEANS PADA KUALITAS GIZI BAYI DI INDONESIA Diajeng Tyas Purwa Hapsari Teknik Informatika STMIK AMIKOM Yogyakarta Jl Ring road Utara, Condongcatur, Sleman, Yogyakarta 55281 Email :
3.1. Hal-Hal Tentang Analisis Faktor
 Analisis Faktor Setelah sebuah data diuji dan layak untuk diolah dengan metode statistik multivariat tertentu, mulai bab ini akan dijelaskan metode-metode statistik multivariat, yang dimulai dengan pembahasan
Analisis Faktor Setelah sebuah data diuji dan layak untuk diolah dengan metode statistik multivariat tertentu, mulai bab ini akan dijelaskan metode-metode statistik multivariat, yang dimulai dengan pembahasan
BAB III METODE PENELITIAN. Alasan memilih Ciputra Taman Dayu Pandaan dikarenakan Ciputra Taman Dayu
 BAB III METODE PENELITIAN 1.1 Lokasi Penelitian Lokasi penelitian ini di Ciputra Taman Dayu Property Pandaan Pasuruan yang terletak di Jl. Raya Surabaya Km. 48 Pandaan 67156 Pasuruan Jawa Timur. Alasan
BAB III METODE PENELITIAN 1.1 Lokasi Penelitian Lokasi penelitian ini di Ciputra Taman Dayu Property Pandaan Pasuruan yang terletak di Jl. Raya Surabaya Km. 48 Pandaan 67156 Pasuruan Jawa Timur. Alasan
ANOVA (analisis varians), sering disebut juga dengan uji F, mempunyai tujuan yang sama dengan uji t, yakni: o
, sering disebut juga dengan uji F, mempunyai tujuan yang sama dengan uji t, yakni: o") Uji Beda: ANOVA ANOVA (analisis varians), sering disebut juga dengan uji F, mempunyai tujuan yang sama dengan uji t, yakni: o o Menguji apakah rata-rata lebih dari dua sampel berbeda secara signifikan
Uji Beda: ANOVA ANOVA (analisis varians), sering disebut juga dengan uji F, mempunyai tujuan yang sama dengan uji t, yakni: o o Menguji apakah rata-rata lebih dari dua sampel berbeda secara signifikan
BAB III METODOLOGI PENELITIAN. Definisi operasional yang dimaksud yaitu untuk menghindari kesalahan
 BAB III METODOLOGI PENELITIAN 3.1 Definisi Operasional Definisi operasional yang dimaksud yaitu untuk menghindari kesalahan pemahaman dan perbedaan penafsiran yang berkaitan dengan istilah-istilah dalam
BAB III METODOLOGI PENELITIAN 3.1 Definisi Operasional Definisi operasional yang dimaksud yaitu untuk menghindari kesalahan pemahaman dan perbedaan penafsiran yang berkaitan dengan istilah-istilah dalam
ANALISIS KLASTERING LIRIK LAGU INDONESIA
 ANALISIS KLASTERING LIRIK LAGU INDONESIA Afdilah Marjuki 1, Herny Februariyanti 2 1,2 Program Studi Sistem Informasi, Fakultas Teknologi Informasi, Universitas Stikubank e-mail: 1 bodongben@gmail.com,
ANALISIS KLASTERING LIRIK LAGU INDONESIA Afdilah Marjuki 1, Herny Februariyanti 2 1,2 Program Studi Sistem Informasi, Fakultas Teknologi Informasi, Universitas Stikubank e-mail: 1 bodongben@gmail.com,
UJI PERSYARATAN ANALISIS DATA
 PERTEMUAN KE-6 Materi : UJI PERSYARATAN ANALISIS DATA Uji nonparametrik digunakan apabila asumsi-asumsi pada uji parametrik tidak dipenuhi. Asumsi yang paling lazim pada uji parametrik adalah sampel acak
PERTEMUAN KE-6 Materi : UJI PERSYARATAN ANALISIS DATA Uji nonparametrik digunakan apabila asumsi-asumsi pada uji parametrik tidak dipenuhi. Asumsi yang paling lazim pada uji parametrik adalah sampel acak
Statistik Deskriptif untuk Data Nominal dan Ordinal
 Statistik Deskriptif untuk Data Nominal dan Ordinal Salah satu ciri utama sehingga sebuah data harus diproses dengan metode nonparametrik adalah jika tipe data tersebut semuanya adalah data nominal atau
Statistik Deskriptif untuk Data Nominal dan Ordinal Salah satu ciri utama sehingga sebuah data harus diproses dengan metode nonparametrik adalah jika tipe data tersebut semuanya adalah data nominal atau
Jika terdapat k variabel bebas, x dan Y merupakan variabel tergantung, maka diperoleh model linier dari regresi berganda seperti rumus [3.1]. [3.
![Jika terdapat k variabel bebas, x dan Y merupakan variabel tergantung, maka diperoleh model linier dari regresi berganda seperti rumus [3.1]. [3.](/thumbs/55/35555243.jpg "Jika terdapat k variabel bebas, x dan Y merupakan variabel tergantung, maka diperoleh model linier dari regresi berganda seperti rumus [3.1]. [3.") Analisis Regresi Analisis regresi merupakan salah satu alat statistika yang sangat populer digunakan user dalam mengolah data statistika. Analisis regresi digunakan untuk mengetahui hubungan satu atau
Analisis Regresi Analisis regresi merupakan salah satu alat statistika yang sangat populer digunakan user dalam mengolah data statistika. Analisis regresi digunakan untuk mengetahui hubungan satu atau
BAB 10 ANALISIS REGRESI LINIER SEDERHANA
 BAB 10 ANALISIS REGRESI LINIER SEDERHANA Analisis regresi linier merupakan salah satu jenis metode regresi yang paling banyak digunakan. Regresi linier sederhana terdiri atas satu variabel terikat (dependent)
BAB 10 ANALISIS REGRESI LINIER SEDERHANA Analisis regresi linier merupakan salah satu jenis metode regresi yang paling banyak digunakan. Regresi linier sederhana terdiri atas satu variabel terikat (dependent)
ANALISIS REGRESI DENGAN VARIABEL MODERATING
 ANALISIS REGRESI DENGAN VARIABEL MODERATING Variabel moderating adalah variabel independen yang akan memperkuat atau memperlemah hubungan antara variabel independen lainnya terhadap variabel dependen.
ANALISIS REGRESI DENGAN VARIABEL MODERATING Variabel moderating adalah variabel independen yang akan memperkuat atau memperlemah hubungan antara variabel independen lainnya terhadap variabel dependen.
LAPORAN PRAKTIKUM 8 & 9 STATISTIKA TENTANG UJI HIPOTESIS (Z OR T) DAN UJI RERATA (STUDENT T)
 DAN UJI RERATA (STUDENT T)") LAPORAN PRAKTIKUM 8 & 9 STATISTIKA TENTANG UJI HIPOTESIS (Z OR T) DAN UJI RERATA (STUDENT T) STATISTIKA DISUSUN OLEH : MELINA KRISNAWATI 12.12.0328 SI 12 F JURUSAN SISTEM INFORMASI SEKOLAH TINGGI MANAJEMEN
LAPORAN PRAKTIKUM 8 & 9 STATISTIKA TENTANG UJI HIPOTESIS (Z OR T) DAN UJI RERATA (STUDENT T) STATISTIKA DISUSUN OLEH : MELINA KRISNAWATI 12.12.0328 SI 12 F JURUSAN SISTEM INFORMASI SEKOLAH TINGGI MANAJEMEN
STATISTIKA DESKRIPTIF
 STATISTIKA DESKRIPTIF 1 Statistika deskriptif berkaitan dengan penerapan metode statistika untuk mengumpulkan, mengolah, menyajikan dan menganalisis data kuantitatif secara deskriptif. Statistika inferensia
STATISTIKA DESKRIPTIF 1 Statistika deskriptif berkaitan dengan penerapan metode statistika untuk mengumpulkan, mengolah, menyajikan dan menganalisis data kuantitatif secara deskriptif. Statistika inferensia
KORELASI. Alat hitung koefisien korelasi Pearson (data kuantitatif dan berskala rasio) Kendall, Spearman (data kualitatif dan berskala ordinal)
 Kendall, Spearman (data kualitatif dan berskala ordinal)") KORELASI Pada SPSS korelasi ada pada menu Correlate dengan submenu: 1. BIVARIATE Besar hubungan antara dua (bi) variabel. a. Koefisien korelasi bivariate/product moment Pearson Mengukur keeratan hubungan
KORELASI Pada SPSS korelasi ada pada menu Correlate dengan submenu: 1. BIVARIATE Besar hubungan antara dua (bi) variabel. a. Koefisien korelasi bivariate/product moment Pearson Mengukur keeratan hubungan
II. MENDESKRIPSIKAN DATA 13 Desember 2005
 II. MENDESKRIPSIKAN DATA 13 Desember 2005 1 Analisis Deskriptif Tujuan dari analisis deskritif adalah memberikan gambaran ringkas tentang suatu data. Data bisa berupa data categorical atau data non-categorical.
II. MENDESKRIPSIKAN DATA 13 Desember 2005 1 Analisis Deskriptif Tujuan dari analisis deskritif adalah memberikan gambaran ringkas tentang suatu data. Data bisa berupa data categorical atau data non-categorical.
BAB IV DESKRIPSI DAN ANALISI DATA
 BAB IV DESKRIPSI DAN ANALISI DATA A. Deskripsi Data Hasil Penelitian 1. Deskripsi Data Umum Penelitian Deskripsi data umum berisi mengenai gambaran umum tempat penelitian yakni di SMP N 1 Pamotan. SMP
BAB IV DESKRIPSI DAN ANALISI DATA A. Deskripsi Data Hasil Penelitian 1. Deskripsi Data Umum Penelitian Deskripsi data umum berisi mengenai gambaran umum tempat penelitian yakni di SMP N 1 Pamotan. SMP
BAB I PENDAHULUAN. Masalah dalam kehidupan sehari-hari tidak hanya didasarkan pada
 BAB I PENDAHULUAN 1.1 Latar Belakang Masalah dalam kehidupan sehari-hari tidak hanya didasarkan pada hubungan satu variabel atau dua variabel saja, akan tetapi cenderung melibatkan banyak variabel. Analisis
BAB I PENDAHULUAN 1.1 Latar Belakang Masalah dalam kehidupan sehari-hari tidak hanya didasarkan pada hubungan satu variabel atau dua variabel saja, akan tetapi cenderung melibatkan banyak variabel. Analisis
BAB III PROSEDUR PENELITIAN. Lebih lanjut Surakhmad (1998, hlm. 131) menjelaskan bahwa:
 menjelaskan bahwa:") BAB III PROSEDUR PENELITIAN A. Metode Penelitian. Dalam setiap penelitian diperlukan suatu metode. Metode penelitian adalah suatu cara yang dipakai peneliti dalam melakukan penelitiannya. Sugiyono (2013,
BAB III PROSEDUR PENELITIAN A. Metode Penelitian. Dalam setiap penelitian diperlukan suatu metode. Metode penelitian adalah suatu cara yang dipakai peneliti dalam melakukan penelitiannya. Sugiyono (2013,
PENGKLASIFIKASIAN KARAKTERISTIK MAHASISWA BARU DALAM MEMILIH PROGRAM STUDI MENGGUNAKAN ANALISIS CLUSTER
 PENGKLASIFIKASIAN KARAKTERISTIK MAHASISWA BARU DALAM MEMILIH PROGRAM STUDI MENGGUNAKAN ANALISIS CLUSTER Maxsi Ary Program Studi Manajemen Informatika Akademik Manajemen Informatika dan Komputer BSI Bandung
PENGKLASIFIKASIAN KARAKTERISTIK MAHASISWA BARU DALAM MEMILIH PROGRAM STUDI MENGGUNAKAN ANALISIS CLUSTER Maxsi Ary Program Studi Manajemen Informatika Akademik Manajemen Informatika dan Komputer BSI Bandung
ANALISIS BIVARIAT DATA KATEGORIK DAN NUMERIK Uji t dan ANOVA
 ANALISIS BIVARIAT DATA KATEGORIK DAN NUMERIK Uji t dan ANOVA Uji t Independen Sebagai contoh kita gunakan data ASI Eksklusif yang sudah anda copy dengan melakukan uji hubungan perilaku menyusui dengan
ANALISIS BIVARIAT DATA KATEGORIK DAN NUMERIK Uji t dan ANOVA Uji t Independen Sebagai contoh kita gunakan data ASI Eksklusif yang sudah anda copy dengan melakukan uji hubungan perilaku menyusui dengan
Crosstab dan Chi-Square: Analisis Hubungan Antarvariabel Kategorikal
 Crosstab dan Chi-Square: Analisis Hubungan Antarvariabel Kategorikal Sebelum masuk ke pembahasan crosstab (tabel silang) dan perhitungan statistik chi-square, akan dijelaskan dahulu kaitan dua perhitungan
Crosstab dan Chi-Square: Analisis Hubungan Antarvariabel Kategorikal Sebelum masuk ke pembahasan crosstab (tabel silang) dan perhitungan statistik chi-square, akan dijelaskan dahulu kaitan dua perhitungan
BAB IV DESKRIPSI DAN ANALISIS DATA
 BAB IV DESKRIPSI DAN ANALISIS DATA A. Deskripsi Data Hasil Penelitian 1. Deskripsi Data Umum Deskripsi data umum berisi mengenai gambaran umum tempat penelitian yakni di MTs N 1 Kudus. MTs N 1 Kudus beralamatkan
BAB IV DESKRIPSI DAN ANALISIS DATA A. Deskripsi Data Hasil Penelitian 1. Deskripsi Data Umum Deskripsi data umum berisi mengenai gambaran umum tempat penelitian yakni di MTs N 1 Kudus. MTs N 1 Kudus beralamatkan
LABORATORIUM DATA MINING JURUSAN TEKNIK INDUSTRI FAKULTAS TEKNOLOGI INDUSTRI UNIVERSITAS ISLAM INDONESIA. Modul II CLUSTERING
 LABORATORIUM DATA MINING JURUSAN TEKNIK INDUSTRI FAKULTAS TEKNOLOGI INDUSTRI UNIVERSITAS ISLAM INDONESIA Modul II CLUSTERING TUJUA PRAKTIKUM 1. Mahasiswa mempunyai pengetahuan dan kemampuan dasar dalam
LABORATORIUM DATA MINING JURUSAN TEKNIK INDUSTRI FAKULTAS TEKNOLOGI INDUSTRI UNIVERSITAS ISLAM INDONESIA Modul II CLUSTERING TUJUA PRAKTIKUM 1. Mahasiswa mempunyai pengetahuan dan kemampuan dasar dalam
LECTURE 9 REGRESI LOGISTIK & DISKRIMINAN
 LECTURE 9 REGRESI LOGISTIK & DISKRIMINAN DR. MUDRAJAD KUNCORO, M.Soc.Sc Fakultas Ekonomi & Pascasarjana UGM Outline: Multinomial Regresi Binary Logistik Analisis Diskriminan Perbandingan multinomial, binary,
LECTURE 9 REGRESI LOGISTIK & DISKRIMINAN DR. MUDRAJAD KUNCORO, M.Soc.Sc Fakultas Ekonomi & Pascasarjana UGM Outline: Multinomial Regresi Binary Logistik Analisis Diskriminan Perbandingan multinomial, binary,
Mendesain Tabel Statistik Secara Profesional
 Mendesain Tabel Statistik Secara Profesional Tabel adalah salah satu output statistik deskriptif yang sering digunakan dalam praktik. Selain karena praktis, tampilan tabel juga mempunyai keunggulan jika
Mendesain Tabel Statistik Secara Profesional Tabel adalah salah satu output statistik deskriptif yang sering digunakan dalam praktik. Selain karena praktis, tampilan tabel juga mempunyai keunggulan jika
Model regresi linier berganda dapat dirumuskan : Y = β + β X + β X +. + β X + ε
 TUJUAN PRAKTIKUM Tujuan dari praktikum modul 4 ini adalah : 1. Menaksir model regresi linier berganda;. Menguji signifikansi parameter dari persamaan regresi linier berganda; 3. Menentukan kualitas dari
TUJUAN PRAKTIKUM Tujuan dari praktikum modul 4 ini adalah : 1. Menaksir model regresi linier berganda;. Menguji signifikansi parameter dari persamaan regresi linier berganda; 3. Menentukan kualitas dari
yang menunjang dalam pengembangan program cluster. Aplikasi cluster ini dikembangkan pada laptop, dengan spesifikasi terdapat
 BAB IV IMPLEMENTASI Bab ini akan menjelaskan mengenai implementasi dari sistem yang akan dikembangkan, berdasarkan hasil analisis yang telah diperoleh sebelumnya. Bab ini terdiri dari penjelasan mengenai
BAB IV IMPLEMENTASI Bab ini akan menjelaskan mengenai implementasi dari sistem yang akan dikembangkan, berdasarkan hasil analisis yang telah diperoleh sebelumnya. Bab ini terdiri dari penjelasan mengenai
BAB 14 UJI DESKRIPTIF, VALIDITAS DAN NORMALITAS DATA
 BAB 14 UJI DESKRIPTIF, VALIDITAS DAN NORMALITAS DATA SPSS menyediakan fasilitas untuk melakukan analisis deskriptif data seperti uji deskriptif, validitas dan normalitas data. Uji deskriptif yang dilakukan
BAB 14 UJI DESKRIPTIF, VALIDITAS DAN NORMALITAS DATA SPSS menyediakan fasilitas untuk melakukan analisis deskriptif data seperti uji deskriptif, validitas dan normalitas data. Uji deskriptif yang dilakukan
Clustering. Virginia Postrel
 8 Clustering Most of us cluster somewhere in the middle of most statistical distributions. But there are lots of bell curves, and pretty much everyone is on a tail of at least one of them. We may collect
8 Clustering Most of us cluster somewhere in the middle of most statistical distributions. But there are lots of bell curves, and pretty much everyone is on a tail of at least one of them. We may collect
BAB IV DESKRIPSI DAN ANALISIS DATA
 BAB IV DESKRIPSI DAN ANALISIS DATA A. Deskripsi data Hasil Penelitian Data Pengamalan PAI dan Perilaku seks bebas peserta didik SMA N 1 Dempet diperoleh dari hasil angket yang telah diberikan kepada responden
BAB IV DESKRIPSI DAN ANALISIS DATA A. Deskripsi data Hasil Penelitian Data Pengamalan PAI dan Perilaku seks bebas peserta didik SMA N 1 Dempet diperoleh dari hasil angket yang telah diberikan kepada responden
UJI NORMALITAS DATA DAN VARIANS. UNIVERSITAS MUHAMMADIYAH PAREPARE Parepare, 2009
 Dengan Materi: UJI NORMALITAS DATA DAN VARIANS Presented by: Andi Rusdi, S.Pd. UNIVERSITAS MUHAMMADIYAH PAREPARE Parepare, 2009 UJI NORMALITAS DATA DAN VARIANS Uji Prasyarat Infrensial (Statistik induktif)
Dengan Materi: UJI NORMALITAS DATA DAN VARIANS Presented by: Andi Rusdi, S.Pd. UNIVERSITAS MUHAMMADIYAH PAREPARE Parepare, 2009 UJI NORMALITAS DATA DAN VARIANS Uji Prasyarat Infrensial (Statistik induktif)
Uji Hipotesis dengan SPSS
 Uji Hipotesis dengan SPSS Atina Ahdika, S.Si, M.Si Universitas Islam Indonesia 2015 Uji Hipotesis Satu Rata-Rata Berikut adalah data banyaknya kelahiran dalam 20 hari dari suatu negara. Seorang pengamat
Uji Hipotesis dengan SPSS Atina Ahdika, S.Si, M.Si Universitas Islam Indonesia 2015 Uji Hipotesis Satu Rata-Rata Berikut adalah data banyaknya kelahiran dalam 20 hari dari suatu negara. Seorang pengamat
Uji statistik multivariat digunakan untuk menguji
 132 PEMANFAATAN SPSS DALAM PENELITIAN BIDANG KESEHATAN & UMUM PEMANFAATAN SPSS DALAM PENELITIAN BIDANG KESEHATAN & UMUM 133 BAB 6 ANALISIS MULTIVARIAT Uji statistik multivariat digunakan untuk menguji
132 PEMANFAATAN SPSS DALAM PENELITIAN BIDANG KESEHATAN & UMUM PEMANFAATAN SPSS DALAM PENELITIAN BIDANG KESEHATAN & UMUM 133 BAB 6 ANALISIS MULTIVARIAT Uji statistik multivariat digunakan untuk menguji
BAB IV PENGOLAHAN DATA
 BAB IV PENGOLAHAN DATA 4.1 Print Output dan Analisa Output A. Diskriminan Parameter : 1. Grup 1 : Konsumen (responden) yang sering berkunjung ke... Grup 2 : Konsumen (responden) yang sering berkunjung
BAB IV PENGOLAHAN DATA 4.1 Print Output dan Analisa Output A. Diskriminan Parameter : 1. Grup 1 : Konsumen (responden) yang sering berkunjung ke... Grup 2 : Konsumen (responden) yang sering berkunjung
BAB I PENDAHULUAN I.1 Latar Belakang
 BAB I PENDAHULUAN I.1 Latar Belakang Di tengah laju kemajuan teknologi telekomunikasi dan informatika, informasi yang cepat dan akurat semakin menjadi kebutuhan pokok para pengambil keputusan. Informasi
BAB I PENDAHULUAN I.1 Latar Belakang Di tengah laju kemajuan teknologi telekomunikasi dan informatika, informasi yang cepat dan akurat semakin menjadi kebutuhan pokok para pengambil keputusan. Informasi
BAB 11 ANALISIS REGRESI LINIER BERGANDA
 BAB 11 ANALISIS REGRESI LINIER BERGANDA Selain regresi linier sederhana, metode regresi yang juga banyak digunakan adalah regresi linier berganda. Regresi linier berganda digunakan untuk penelitian yang
BAB 11 ANALISIS REGRESI LINIER BERGANDA Selain regresi linier sederhana, metode regresi yang juga banyak digunakan adalah regresi linier berganda. Regresi linier berganda digunakan untuk penelitian yang
UJI NONPARAMETRIK. Gambar 6.1 Menjalankan Prosedur Nonparametrik
 6 UJI NONPARAMETRIK Bab ini membahas: Uji Chi-Kuadrat. Uji Dua Sampel Independen. Uji Beberapa Sampel Independen. Uji Dua Sampel Berkaitan. D iperlukannya uji Statistik NonParametrik mengingat bahwa suatu
6 UJI NONPARAMETRIK Bab ini membahas: Uji Chi-Kuadrat. Uji Dua Sampel Independen. Uji Beberapa Sampel Independen. Uji Dua Sampel Berkaitan. D iperlukannya uji Statistik NonParametrik mengingat bahwa suatu
STATISTIK DESKRIPTIF
 BAB 5 STATISTIK DESKRIPTIF Salah satu statistik yang secara sadar maupun tidak, sering digunakan dalam berbagai bidang adalah statistik deskriptif. Pada bagian ini akan dipelajari beberapa contoh kasus
BAB 5 STATISTIK DESKRIPTIF Salah satu statistik yang secara sadar maupun tidak, sering digunakan dalam berbagai bidang adalah statistik deskriptif. Pada bagian ini akan dipelajari beberapa contoh kasus
Independent Sample T Test
 Independent Sample T Test Pengujian Dua Sample Tidak berhubungan (Independent Sample T Test) Uji Independence Sample T Test, digunakan untuk mengetahui ada tidaknya perbedaan rata-rata antara dua kelompok
Independent Sample T Test Pengujian Dua Sample Tidak berhubungan (Independent Sample T Test) Uji Independence Sample T Test, digunakan untuk mengetahui ada tidaknya perbedaan rata-rata antara dua kelompok
Materi Kuliah Metode Penelitian. Uji Asumsi
 Materi Kuliah Metode Penelitian Uji Asumsi Uji Normalitas Uji normalitas dimaksudkan untuk memperlihatkan bahwa sampel dari populasi yang berdistribusi normal. Ada beberapa teknik yang dapat digunakan
Materi Kuliah Metode Penelitian Uji Asumsi Uji Normalitas Uji normalitas dimaksudkan untuk memperlihatkan bahwa sampel dari populasi yang berdistribusi normal. Ada beberapa teknik yang dapat digunakan
BAB II KAJIAN TEORI. linier, varian dan simpangan baku, standarisasi data, koefisien korelasi, matriks
 BAB II KAJIAN TEORI Pada bab II akan dibahas tentang materi-materi dasar yang digunakan untuk mendukung pembahasan pada bab selanjutnya, yaitu matriks, kombinasi linier, varian dan simpangan baku, standarisasi
BAB II KAJIAN TEORI Pada bab II akan dibahas tentang materi-materi dasar yang digunakan untuk mendukung pembahasan pada bab selanjutnya, yaitu matriks, kombinasi linier, varian dan simpangan baku, standarisasi
BAB IV ANALISIS DATA. bebas dan variabel terikat, kemudian data tersebut di analisis dengan
 BAB IV ANALISIS DATA A. Pengujian Hipotesis Setelah diperoleh masing-masing jumlah dari kategori variabel bebas dan variabel terikat, kemudian data tersebut di analisis dengan menggunakan analisis kuantitatif,
BAB IV ANALISIS DATA A. Pengujian Hipotesis Setelah diperoleh masing-masing jumlah dari kategori variabel bebas dan variabel terikat, kemudian data tersebut di analisis dengan menggunakan analisis kuantitatif,
Pendahuluan RRL Model Pengaruh Tetap Model Pengaruh Random
 RANCANGAN RANDOM LENGKAP Pendahuluan RRL RRL atau Rancangan Random Lengkap merupakan rancangan di mana unit eksperimen yang dikenai perlakuan secara random dan menyeluruh lengkap untuk setiap perlakuan.
RANCANGAN RANDOM LENGKAP Pendahuluan RRL RRL atau Rancangan Random Lengkap merupakan rancangan di mana unit eksperimen yang dikenai perlakuan secara random dan menyeluruh lengkap untuk setiap perlakuan.
BAB 08 ANALISIS VARIAN 8.1 ANALISIS VARIAN SATU JALAN
 BAB 08 ANALISIS VARIAN Sebagaimana yang sudah dijelaskan sebelumnya bahwa salah satu statistik parametrik yang sering digunakan dalam penelitian pendidikan yaitu Analisis Varian. Oleh karena itu pada bagian
BAB 08 ANALISIS VARIAN Sebagaimana yang sudah dijelaskan sebelumnya bahwa salah satu statistik parametrik yang sering digunakan dalam penelitian pendidikan yaitu Analisis Varian. Oleh karena itu pada bagian
ANALISIS FAKTOR ANALISIS FAKTOR
 ANALISIS FAKTOR ANALISIS FAKTOR Analisis factor digunakan untuk menemukan hubungan sejumlah variable yang bersifat independent dengan yang lain Analisis Faktor merupakan teknik untuk mengkombinasikan pertanyaan
ANALISIS FAKTOR ANALISIS FAKTOR Analisis factor digunakan untuk menemukan hubungan sejumlah variable yang bersifat independent dengan yang lain Analisis Faktor merupakan teknik untuk mengkombinasikan pertanyaan
PENDAHULUAN. 1.1 Latar Belakang
 DAFTAR TABEL Tabel 3-1 Dokumen Term 1... 17 Tabel 3-2 Representasi... 18 Tabel 3-3 Centroid pada pengulangan ke-0... 19 Tabel 3-4 Hasil Perhitungan Jarak... 19 Tabel 3-5 Hasil Perhitungan Jarak dan Pengelompokkan
DAFTAR TABEL Tabel 3-1 Dokumen Term 1... 17 Tabel 3-2 Representasi... 18 Tabel 3-3 Centroid pada pengulangan ke-0... 19 Tabel 3-4 Hasil Perhitungan Jarak... 19 Tabel 3-5 Hasil Perhitungan Jarak dan Pengelompokkan
PENENTUAN JUMLAH CLUSTER OPTIMAL PADA MEDIAN LINKAGE DENGAN INDEKS VALIDITAS SILHOUETTE
 Buletin Ilmiah Math. Stat. dan Terapannya (Bimaster) Volume 05, No. 2 (2016), hal 97 102. PENENTUAN JUMLAH CLUSTER OPTIMAL PADA MEDIAN LINKAGE DENGAN INDEKS VALIDITAS SILHOUETTE Nicolaus, Evy Sulistianingsih,
Buletin Ilmiah Math. Stat. dan Terapannya (Bimaster) Volume 05, No. 2 (2016), hal 97 102. PENENTUAN JUMLAH CLUSTER OPTIMAL PADA MEDIAN LINKAGE DENGAN INDEKS VALIDITAS SILHOUETTE Nicolaus, Evy Sulistianingsih,
BAB I PENDAHULUAN. Analisis statistik multivariat adalah metode statistik di mana masalah yang
 BAB I PENDAHULUAN 1.1. LATAR BELAKANG MASALAH Analisis statistik multivariat adalah metode statistik di mana masalah yang diteliti bersifat multidimensional dengan menggunakan tiga atau lebih variabel
BAB I PENDAHULUAN 1.1. LATAR BELAKANG MASALAH Analisis statistik multivariat adalah metode statistik di mana masalah yang diteliti bersifat multidimensional dengan menggunakan tiga atau lebih variabel
UJI VALIDITAS KUISIONER
 UJI VALIDITAS KUISIONER Validitas adalah ketepatan atau kecermatan suatu instrumen dalam mengukur apa yang ingin dukur. Dalam pengujian instrumen pengumpulan data, validitas bisa dibedakan menjadi validitas
UJI VALIDITAS KUISIONER Validitas adalah ketepatan atau kecermatan suatu instrumen dalam mengukur apa yang ingin dukur. Dalam pengujian instrumen pengumpulan data, validitas bisa dibedakan menjadi validitas
Tahap pertama yang paling penting dalam mengoperasikan SPSS adalah
 Tips for SPSS Cara Memasukkan Data, Analisis Statistik secara Deskriptif dan Transforming Data Oleh: Freddy Rangkuti Tahap pertama yang paling penting dalam mengoperasikan SPSS adalah memasukkan data dan
Tips for SPSS Cara Memasukkan Data, Analisis Statistik secara Deskriptif dan Transforming Data Oleh: Freddy Rangkuti Tahap pertama yang paling penting dalam mengoperasikan SPSS adalah memasukkan data dan
BAB V HASIL PENELITIAN DAN PEMBAHASAN
 59 BAB V HASIL PENELITIAN DAN PEMBAHASAN 5.1. Gambaran Umum Obyek Penelitian Kawasan Sarbagita merupakan suatu kawasan yang dipersiapkan oleh Departemen Prasarana dan Pemukiman Wilayah (Kimpraswil) sebagai
59 BAB V HASIL PENELITIAN DAN PEMBAHASAN 5.1. Gambaran Umum Obyek Penelitian Kawasan Sarbagita merupakan suatu kawasan yang dipersiapkan oleh Departemen Prasarana dan Pemukiman Wilayah (Kimpraswil) sebagai
Program Studi Pendidikan Ekonomi FE UNY
 LEMBAR KERJA Topik: Uji Homosedastisitas Tujuan: Digunakan untuk mengetahui kesamaan varians error untuk setiap nilai X. Error = residu = e = Y Y Lawan homosedastisitas adalah heterosedastisitas. Analisis
LEMBAR KERJA Topik: Uji Homosedastisitas Tujuan: Digunakan untuk mengetahui kesamaan varians error untuk setiap nilai X. Error = residu = e = Y Y Lawan homosedastisitas adalah heterosedastisitas. Analisis
BAB II LANDASAN TEORI. yang terdiri dari komponen-komponen atau sub sistem yang berorientasi untuk
 BAB II LANDASAN TEORI 2.1 Sistem Menurut Gondodiyoto (2007), sistem adalah merupakan suatu kesatuan yang terdiri dari komponen-komponen atau sub sistem yang berorientasi untuk mencapai suatu tujuan tertentu.
BAB II LANDASAN TEORI 2.1 Sistem Menurut Gondodiyoto (2007), sistem adalah merupakan suatu kesatuan yang terdiri dari komponen-komponen atau sub sistem yang berorientasi untuk mencapai suatu tujuan tertentu.
BAB 3 PENGUMPULAN DAN PENGOLAHAN DATA
 BAB PENGUMPULAN DAN PENGOLAHAN DATA.1 Pengumpulan Data Data yang diambil berupa data karakteristik item spare part baik spare part mekanik maupun elektrik. Data diambil dari salah satu jalur produksi terbesar
BAB PENGUMPULAN DAN PENGOLAHAN DATA.1 Pengumpulan Data Data yang diambil berupa data karakteristik item spare part baik spare part mekanik maupun elektrik. Data diambil dari salah satu jalur produksi terbesar
PENGOLAHAN DATA DENGAN SPSS
 PENGOLAHAN DATA DENGAN SPSS Untuk melakukan analisa data dengan menggunakan program SPSS, langkah awal yang harus dilakukan adalah memasukkan data dalam sheet SPSS. Ada dua jenis sheet dalam SPSS, yaitu
PENGOLAHAN DATA DENGAN SPSS Untuk melakukan analisa data dengan menggunakan program SPSS, langkah awal yang harus dilakukan adalah memasukkan data dalam sheet SPSS. Ada dua jenis sheet dalam SPSS, yaitu
Memulai SPSS dan Mengelola File
 MODUL 1 Memulai SPSS dan Mengelola File A. MEMULAI SPSS Untuk memulai SPSS for Windows langkah yang harus dilakukan adalah: Klik menu Start Programs SPSS for Windows SPSS for Windows. Kemudian akan ditampilkan
MODUL 1 Memulai SPSS dan Mengelola File A. MEMULAI SPSS Untuk memulai SPSS for Windows langkah yang harus dilakukan adalah: Klik menu Start Programs SPSS for Windows SPSS for Windows. Kemudian akan ditampilkan
MODUL II ANALYSIS OF VARIANCE (ANOVA)
") MODUL II ANALYSIS OF VARIANCE (ANOVA) TUJUAN 1. Mahasiswa mampu memahami uji hipotesis harga rata-rata multi populasi dengan menggunakan Analysis of Variance (ANOVA). 2. Mahasiswa mampu memahami penyelesaian
MODUL II ANALYSIS OF VARIANCE (ANOVA) TUJUAN 1. Mahasiswa mampu memahami uji hipotesis harga rata-rata multi populasi dengan menggunakan Analysis of Variance (ANOVA). 2. Mahasiswa mampu memahami penyelesaian
Pengenalan Pola. K-Means Clustering
 Pengenalan Pola K-Means Clustering PTIIK - 2014 Course Contents 1 Definisi k-means 2 Algoritma k-means 3 Studi Kasus 4 Latihan dan Diskusi K-Means Clustering K-Means merupakan salah satu metode pengelompokan
Pengenalan Pola K-Means Clustering PTIIK - 2014 Course Contents 1 Definisi k-means 2 Algoritma k-means 3 Studi Kasus 4 Latihan dan Diskusi K-Means Clustering K-Means merupakan salah satu metode pengelompokan
BAB III METODOLOGI PENELITIAN. Jenis penelitian yang digunakan dalam menyusun skripsi ini menggunakan
 BAB III METODOLOGI PENELITIAN A. Jenis Penelitian Jenis penelitian yang digunakan dalam menyusun skripsi ini menggunakan metode deskriptif. Menurut Sugiono dalam bukunya Metodologi Penelitian Bisnis (2009)
BAB III METODOLOGI PENELITIAN A. Jenis Penelitian Jenis penelitian yang digunakan dalam menyusun skripsi ini menggunakan metode deskriptif. Menurut Sugiono dalam bukunya Metodologi Penelitian Bisnis (2009)
Prediksi Harga Saham dengan ARIMA
 Prediksi Harga Saham dengan ARIMA Peramalan harga saham merupakan sesuatu yang ditunggu-tunggu oleh para investor. Munculnya model prediksi yang baru yang bisa meramalkan harga saham secara tepat merupakan
Prediksi Harga Saham dengan ARIMA Peramalan harga saham merupakan sesuatu yang ditunggu-tunggu oleh para investor. Munculnya model prediksi yang baru yang bisa meramalkan harga saham secara tepat merupakan
ANALISIS DATA KOMPARATIF (T-Test)
") PERTEMUAN KE-10 ANALISIS DATA KOMPARATIF (T-Test) Ringkasan Materi: Komparasi berasal dari kata comparison (Eng) yang mempunyai arti perbandingan atau pembandingan. Teknik analisis komparasi yaitu salah
PERTEMUAN KE-10 ANALISIS DATA KOMPARATIF (T-Test) Ringkasan Materi: Komparasi berasal dari kata comparison (Eng) yang mempunyai arti perbandingan atau pembandingan. Teknik analisis komparasi yaitu salah
Mengolah Data Bidang Industri
 Mengolah Data Bidang Industri Pengolahan data dalam bidang industri menggunakan aplikasi SPSS 20 mempunyai fungsi sebagai alat bantu untuk memberikan gambaran dalam hal prediksi penjualan atau omzet perusahaan,
Mengolah Data Bidang Industri Pengolahan data dalam bidang industri menggunakan aplikasi SPSS 20 mempunyai fungsi sebagai alat bantu untuk memberikan gambaran dalam hal prediksi penjualan atau omzet perusahaan,
K-Means Clustering. Tim Asprak Metkuan. What is Clustering?
 K-Means Clustering Tim Asprak Metkuan What is Clustering? Also called unsupervised learning, sometimes called classification by statisticians and sorting by psychologists and segmentation by people in
K-Means Clustering Tim Asprak Metkuan What is Clustering? Also called unsupervised learning, sometimes called classification by statisticians and sorting by psychologists and segmentation by people in
STATISTIK DESKRIPTIF
 PERTEMUAN KE-3 STATISTIK DESKRIPTIF Ringkasan Materi: Pengukuran Deskriptif Pengukuran deskriptif pada dasarnya memaparkan secara numerik ukuran tendensi sentral, dispersi dan distribusi suatu data. Tendensi
PERTEMUAN KE-3 STATISTIK DESKRIPTIF Ringkasan Materi: Pengukuran Deskriptif Pengukuran deskriptif pada dasarnya memaparkan secara numerik ukuran tendensi sentral, dispersi dan distribusi suatu data. Tendensi
Pertemuan 14 HIERARCHICAL CLUSTERING METHODS
 Pertemuan 14 HIERARCHICAL CLUSTERING METHODS berdasar gambar berdasar warna A A A A Q Q Q Q K K K K J J J J 2 2 2 2 3 3 3 3 4 4 4 4 5 5 5 5 6 6 6 6 7 7 7 7 8 8 8 8 9 9 9 9 10 10 10 10 A K Q J (a). Individual
Pertemuan 14 HIERARCHICAL CLUSTERING METHODS berdasar gambar berdasar warna A A A A Q Q Q Q K K K K J J J J 2 2 2 2 3 3 3 3 4 4 4 4 5 5 5 5 6 6 6 6 7 7 7 7 8 8 8 8 9 9 9 9 10 10 10 10 A K Q J (a). Individual
PRAKTIKUM 3 ANALISA CLUSTER
 PRAKTIKUM 3 ANALISA CLUSTER Definisi Cluster Analisis cluster merupakan suatu teknik data mining yang digunakan untuk mengklasifikasikan obyek atau kasus (responden) ke dalam kelompok yang relatif homogen
PRAKTIKUM 3 ANALISA CLUSTER Definisi Cluster Analisis cluster merupakan suatu teknik data mining yang digunakan untuk mengklasifikasikan obyek atau kasus (responden) ke dalam kelompok yang relatif homogen
UJI PRASYARAT ANALISIS
 UJI PRASYARAT ANALISIS Wahyu Widhiarso Fakultas Psikologi UGM Latar Belakang PENGANTAR Beberapa formula statistika disusun berdasarkan asumsi-asumsi tertentu. Formula tersebut dapat menggambarkan sebuah
UJI PRASYARAT ANALISIS Wahyu Widhiarso Fakultas Psikologi UGM Latar Belakang PENGANTAR Beberapa formula statistika disusun berdasarkan asumsi-asumsi tertentu. Formula tersebut dapat menggambarkan sebuah
ANALISIS REGRESI BERGANDA
 ANALISIS REGRESI BERGANDA Analisis Regresi Berganda Arahkan kursor pada Analyze lalu Regression dan pilih Linear Analisis Regresi Berganda Pada kotak Linear Regression, pindahkan variable Y pada kotak
ANALISIS REGRESI BERGANDA Analisis Regresi Berganda Arahkan kursor pada Analyze lalu Regression dan pilih Linear Analisis Regresi Berganda Pada kotak Linear Regression, pindahkan variable Y pada kotak
POLITEKNIK KESEHATAN SURAKARTA TAHUN
 MODUL PRAKTIKUM SPSS Oleh: Ig. Dodiet Aditya Setyawan, SKM. POLITEKNIK KESEHATAN SURAKARTA TAHUN 2013 LATIHAN 1: ENTRY DATA KASUS 1 Misalnya didapatkan data seperti di bawah ini dan akan memasukkannya
MODUL PRAKTIKUM SPSS Oleh: Ig. Dodiet Aditya Setyawan, SKM. POLITEKNIK KESEHATAN SURAKARTA TAHUN 2013 LATIHAN 1: ENTRY DATA KASUS 1 Misalnya didapatkan data seperti di bawah ini dan akan memasukkannya
Statistika Psikologi 2
 Modul ke: Statistika Psikologi 2 Fakultas Psikologi Program Studi Psikologi Sampling, Sampling Distribution, Confidence Intervals, Effect Size, dan Statistical Power SAMPLING Teknik menentukan sampel dari
Modul ke: Statistika Psikologi 2 Fakultas Psikologi Program Studi Psikologi Sampling, Sampling Distribution, Confidence Intervals, Effect Size, dan Statistical Power SAMPLING Teknik menentukan sampel dari
SEGMENTASI CITRA MENGGUNAKAN K-MEANS DAN FUZZY C- MEANS DENGAN BERBAGAI RUANG WARNA
 SEGMENTASI CITRA MENGGUNAKAN K-MEANS DAN FUZZY C- MEANS DENGAN BERBAGAI RUANG WARNA Kamil Malik Jurusan Teknik Informatika STT Nurul Jadid Paiton nomor1001@gmail.com Andi Hutami Endang Jurusan Teknik Informatika
SEGMENTASI CITRA MENGGUNAKAN K-MEANS DAN FUZZY C- MEANS DENGAN BERBAGAI RUANG WARNA Kamil Malik Jurusan Teknik Informatika STT Nurul Jadid Paiton nomor1001@gmail.com Andi Hutami Endang Jurusan Teknik Informatika
BAB 11 STATISTIK INDUKTIF Uji t
 BAB 11 STATISTIK INDUKTIF Uji t Pada bagian awal dari buku ini telah disebutkan pembagian metode statistik, yakni deskriptif dan induktif. Beberapa bab sebelumnya telah membahas penggunaan metode statistik
BAB 11 STATISTIK INDUKTIF Uji t Pada bagian awal dari buku ini telah disebutkan pembagian metode statistik, yakni deskriptif dan induktif. Beberapa bab sebelumnya telah membahas penggunaan metode statistik
SPSS FOR WINDOWS BASIC. By : Syafrizal
 SPSS FOR WINDOWS BASIC By : Syafrizal SPSS merupakan software statistik yang paling populer, fasilitasnya sangat lengkap dibandingkan dengan software lainnya, penggunaannya pun cukup mudah Langkah pertama
SPSS FOR WINDOWS BASIC By : Syafrizal SPSS merupakan software statistik yang paling populer, fasilitasnya sangat lengkap dibandingkan dengan software lainnya, penggunaannya pun cukup mudah Langkah pertama
LATIHAN SPSS I. A. Entri Data
 A. Entri Data LATIHAN SPSS I Variabel Name Label Type Nama Nama Mahasiswa String NIM Nomor Induk Mahasiswa String JK Numeris 1. 2. TglLahir Tanggal Lahir Date da Daerah Asal Numeris 1. Perkotaan 2. Pinggiran
A. Entri Data LATIHAN SPSS I Variabel Name Label Type Nama Nama Mahasiswa String NIM Nomor Induk Mahasiswa String JK Numeris 1. 2. TglLahir Tanggal Lahir Date da Daerah Asal Numeris 1. Perkotaan 2. Pinggiran
TABEL 3 DATA PENELITIAN
 Analisis Regresi Linier Bentuk LN (Logaritma Natural) Pengubahan data ke bentuk LN dimaksudkan untuk meniadakan atau meminimalkan adanya pelanggaran asumsi normalitas dan asumsi klasik regresi. Jika data-data
Analisis Regresi Linier Bentuk LN (Logaritma Natural) Pengubahan data ke bentuk LN dimaksudkan untuk meniadakan atau meminimalkan adanya pelanggaran asumsi normalitas dan asumsi klasik regresi. Jika data-data