DATA MINING DAN WAREHOUSE A N D R I
|
|
|
- Suparman Setiawan
- 9 tahun lalu
- Tontonan:
Transkripsi
1 DATA MINING DAN WAREHOUSE A N D R I

2 CLUSTERING Secara umum cluster didefinisikan sebagai sejumlah objek yang mirip yang dikelompokan secara bersama, Namun definisi dari cluster bisa beragam tergantung dari sudut pandang yang digunakan, beberapa definisi cluster berdasarkan sudut pandang adalah sebagai berikut :

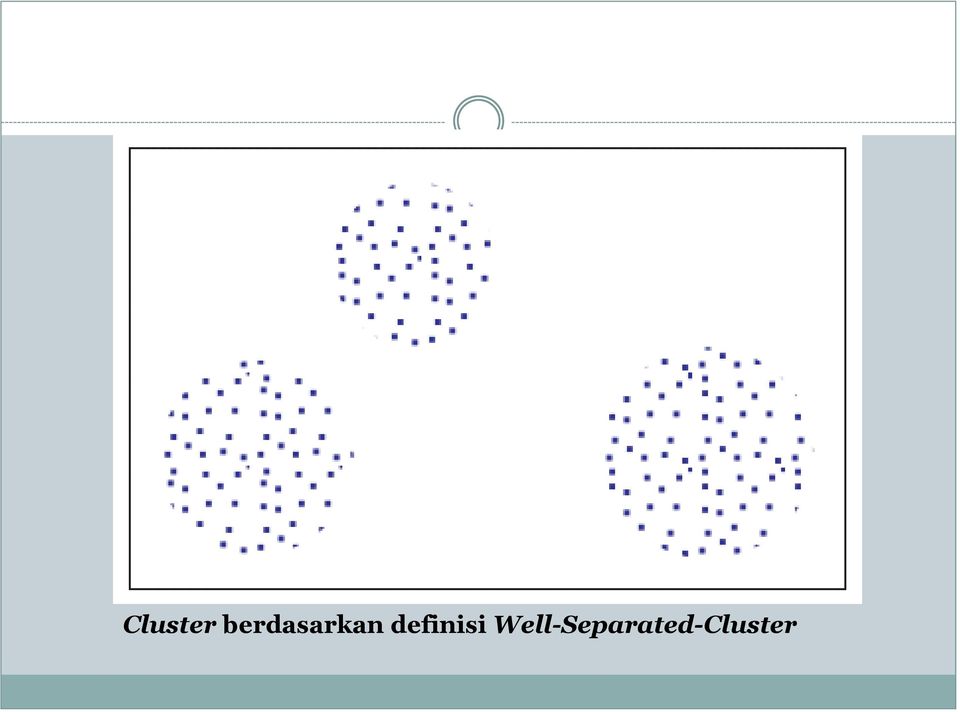
3 Definisi Well-Separated Cluster Berdasarkan definisi ini cluster adalah sekelompok titik(objek) dimana sebuah titik pada kelompok itu lebih dekat atau mirip dengan semua titik(objek) yang ada pada kelompok tersebut dari pada titik-titik (objekobjek) lain yang tidak terdapat pada kelompok itu. Biasanya digunakan sebuah nilai batas (threshold) untuk menentukan titik-titik (objek-objek) yang dianggap cukup dekat satu sama lainnya. Namun terdapat kelemahan pada definisi ini yaitu titik-titik yang terdapat pada pojok sebuah cluster pada kenyataannya mungkin saja lebih dekat dengan titik-titik pada cluster yang lain.


4 Cluster berdasarkan definisi Well-Separated-Cluster
5 Definisi Center-Based Cluster Berdasarkan definisi ini sebuah cluster didefinisikan sebagai sekelompok titik (objek) dimana semua titik pada kelompok itu lebih dekat dengan pusat atau center dari kelompok tersebut dari pada pusat pada kelompok lainnya. Umumnya pusat cluster adalah centroid, yaitu ratarata dari semua titik pada cluster tersebut, namun dapat juga digunakan medoid, yaitu titik yang paling mewakili pada sebuah cluster.


6 Cluster berdasarkan definisi Center-Based Cluster

7 Cluster Analysis Cluster analysis merupakan salah satu metode Data mining yang bersifat tanpa latihan (unsupervised analisys) yang mempunyai tujuan untuk mengelompokan data kedalam kelompok-kelompok dimana data-data yang berada dalam kelompok yang sama akan mempunyai sifat yang relatif homogen.

8 Jika ada n objek pengamatan dengan p variable maka terlebih dulu ditentukan ukuran kedekatan sifat antar data, ukuran kedekatan sifat data yang bisa digunakan adalah jarak euclidius (Euclidean distance) antara dua objek dari p dimensi pengamatan, jika objek pertama yang akan diamati adalah X = [x 1,x 2,x 3,.x p ] dan Y=[y 1,y 2,y 3,.y p ] maka euclidean distance dirumuskan sebagai berikut :

9 Secara formal definisi dari cluster analysis adalah sebagai berikut: Misalkan S adalah himpunan objek yang mempunyai n buah elemen, S = {o 1,o 2,o 3 o n } (II.1) Cluster analysis membagi S (didefinisikan pada persamaan II.1) menjadi k himpunan C 1,C 2,C 3 C k, himpunan-himpunan tersebut disebut dengan cluster. Sebuah cluster C i adalah subset atau himpunan bagian dari S,. Solusi atau keluaran dari sebuah cluster Analysis dinyatakan sebagai himpunan dari semua cluster,

10 Jika S adalah himpunan objek yang mempunyai n buah elemen dan terdiri dari r variable maka ketika S dibagi menjadi k cluster, maka model dari cluster dapat didefinisikan dengan dua buah matrik yaitu matrik data D nxk = (d ik ) dan matrik variable F rxk = (f jk ), d ik 1, data ke i anggota kluster ke k 0,data ke i bukan anggota kluster ke k Proses clustering mengasumsikan bahwa data akan menjadi anggota dari satu dan hanya satu cluster. f jk 1, Variable ke j anggota kluster ke k 0,Variable ke j bukan anggota kluster ke k

11 Klasifikasi Metode Cluster Analysis Metode cluster analysis pada dasarnya ada dua jenis, yaitu metode cluster analysis hirarki (hierarchical clustering method) dan Metode cluster analysis non hirarki (non hierarchical clustering method).
.")
12 Metode clustering hirarki Metode clustering hirarki digunakan apabila belum ada informasi jumlah cluster yang akan dipilih, metode hirarki akan menghasilkan cluster-cluster yang bersarang (nested) sehingga masing-masing cluster dapat memiliki sub-cluster. Prinsip utama metode cluster analysis hirarki adalah mengatur semua objek dalam sebuah pohon keputusan (umumnya berupa pohon biner) berdasarkan suatu fungsi kriteria tertentu. Pohon tersebut disebut dendogram.


13 Contoh Dendogram
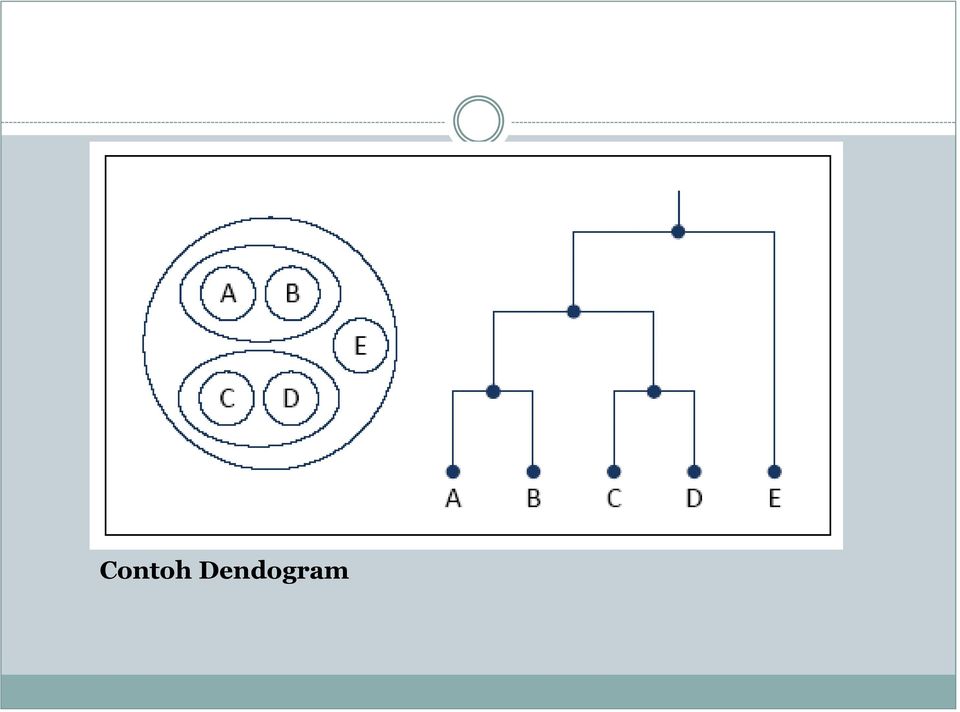
14 Semakin tinggi level simpul pohon maka semakin rendah tingkat similaritas antar objeknya, metode cluster analysis hirarki dapat dilakukan dengan dua pendekatan yaitu bottom-up (agglomerative) dan top-down (divisive). Pada pendekatan aggromerative setiap objek pada awalnya berada pada cluster masing-masing, kemudian setiap cluster yang paling mirip akan dikelompokan dalam satu cluster, hingga membentuk suatu hirarki cluster.

15 Pada pendekatan divisive, pada awalnya hanya terdapat satu buah cluster tunggal yang beranggotakan seluruh objek, kemudian dilakukan pemecahan atas cluster tersebut menjadi beberapa sub-cluster, contoh algoritma metode cluster hirarki adalah HAC (Hieararchical Aggromerative Clustering) dengan beberapa variasi perhitungan similaritas antar cluster seperti single-link, complete-link dan group average.

16 Metode Cluster Analysis Non Hirarki Metode cluster analysis non hirarki biasa juga disebut dengan partitional clustering bertujuan mengelompokan n objek kedalam k cluster (k < n) dimana nilai k sudah ditentukan sebelumnya. Salah satu prosedur clustering non hirarki adalah menggunakan metode K-Means clustering analisis, yaitu metode yang bertujuan untuk mengelompokan objek atau data sedemikian rupa sehingga jarak tiap objek ke pusat cluster (centroid) adalah minimum, titik pusat cluster terbentuk dari rata-rata nilai dari setiap variable.
 adalah minimum, titik pusat cluster")
17 Secara umum proses cluster analysis dimulai dengan perumusan masalah clustering dengan mendefinisikan variable-variable yang akan digunakan sebagai dasar proses cluster. Konsep dasar dari cluster analysis adalah konsep pengukuran jarak (distance) atau kesamaaan (similarity), distance adalah ukuran tentang jarak pisah antar objek sedangkan similaritas adalah ukuran kedekatan. Pengukuran jarak (distance type measure) digunakan untuk data-data yang bersifat metrik, sedangkan pengukuran kesesuaian (matching type measure) digunakan untuk datadata yang bersifat kualitatif atau non metrik.

18 Proses clustering yang baik seharusnya menghasilkan cluster-cluster yang berkualitas tinggi dengan sifat-sifat sebagai berikut : 1. Setiap objek pada cluster memiliki kemiripan (intra cluster similarity) yang tinggi satu sama lainnya. 2. Kemiripan objek pada cluster yang berbeda(inter cluster similarity) rendah.

19 K-Means Cluster Analysis K-means cluster analysis merupakan salah satu metode cluster analysis non hirarki yang berusaha untuk mempartisi data yang ada kedalam satu atau lebih cluster atau kelompok data berdasarkan karakteristiknya, sehingga data yang mempunyai karakteristik yang sama dikelompokan dalam satu cluster yang sama dan data yang mempunyai karakteristik yang berbeda dikelompokan ke dalam cluster yang lain. Tujuannya adalah untuk meminimalkan objective function yang di set dalam proses clustering, yang pada dasarnya berusaha untuk meminimalkan variasi dalam satu cluster dan memaksimalkan variasi antar cluster.

20 K-Means meliputi sequential threshold, pararel threshold dan optimizing threshold Sequential threshold melakukan pengelompokan dengan terlebih dahulu memilih satu objek dasar yang akan dijadikan nilai awal cluster, kemudian semua cluster yang ada dalam jarak terdekat dengan cluster ini akan bergabung, lalu dipilih cluster kedua dan semua objek yang mempunyai kemiripan dengan cluster ini akan digabungkan, demikian seterusnya sehingga terbentuk beberapa cluster dengan keseluruhan objek terdapat didalamnya.

21 Pararel threshold secara prinsip sama dengan sequential threshold hanya saja dilakukan dengan melakukan pemilihan terhadap beberapa objek awal cluster sekaligus dan kemudian melakukan penggabungan objek kedalamnya secara bersamaan. Optimizing threshold merupakan pengembangan dari sequential dan pararel dengan melakukan optimalisasi penempatan objek dengan melakukan reassigned ke dalam cluster untuk mengoptimalisasikan suatu kriteria secara menyeluruh, seperti average within distance untuk sejumlah cluster tertentu
22 Algoritma K-Means Cluster Analysis Jika diberikan sekumpulan data X=(x 1,x 2,.x n ) maka algoritma k-means cluster analysis akan mempartisi X dalam k buah cluster, setiap cluster memiliki centroid (titik tengah) atau mean dari data-data dalam cluster tersebut. Pada tahap awal algoritma k-means cluster analysis akan memilih secara acak k buah data sebagai centroid (titik tengah), kemudian jarak antara data dengan centroid dihitung dengan menggunakan Euclidean distance, data akan ditempatkan dalam cluster yang terdekat dihitung dari titik tengah cluster. Centroid baru akan ditetapkan jika semua data sudah ditempatkan dalam cluster terdekat. Proses penentuan centroid dan penempatan data dalam cluster diulangi sampai nilai centroid konvergen (centroid dari semua cluster tidak berubah lagi)
23 Secara umum K-Means Cluster analysis menggunakan algoritma sebagai berikut : 1. Tentukan k sebagai jumlah cluster yang akan di bentuk 2. Bangkitkan k Centroid (titik pusat cluster) awal secara random 3. Hitung jarak setiap data ke masing-masing centroid dari masing-masing cluster 4. Alokasikan masing-masing data ke dalam centroid yang paling terdekat 5. Lakukan iterasi, kemudian tentukan posisi centroid baru dengan cara menghitung rata-rata dari data-data yang berada pada centroid yang sama 6. Ulangi langkah 3 jika posisi centroid baru dan centroid lama tidak sama
24 Start Tentukan Jumlah Kluster K Tentukan Centroid Hitung Jarak Objek dengan Centroid Alokasikan Objek berdasarkan Minumum Jarak NO Konvergen Yes End
25 Menentukan Banyaknya Cluster k Untuk menentukan nilai banyaknya cluster k dilakukan dengan beberapa pertimbangan sebagai berikut : 1. Pertimbangan teoritis, konseptual, praktis yang mungkin diusulkan untuk menentukan berapa banyak jumlah cluster. 2. Besarnya relative cluster seharusnya bermanfaat, pemecahan cluster yang menghasilkan 1 objek anggota cluster dikatakan tidak bermanfaat sehingga hal ini perlu untuk dihindari.
26 Menentukan Centroid Penentuan centroid awal dilakukan secara random/acak dari data/objek yang tersedia sebanyak jumlah kluster k, kemudian untuk menghitung centroid cluster berikutnya ke i, v i digunakan rumus sebagai berikut : V k : centroid pada cluster ke k Xi : Data ke i N k : Banyaknya objek/jumlah data yang menjadi anggota cluster ke k V k N i i 1 N X k i
27 Menghitung Jarak Antara Data Dengan Centroid Untuk menghitung jarak antara data dengan centroid terdapat beberapa cara yang dapat dilakukan yaitu Manhattan/City Block distance (L 1 ), Euclidean Distance (L 2 ). Jarak antara dua titik X 1 dan X 2 pada manhattan/citi block dihitung dengan menggunakan rumus : Dimana P : Dimensi data. : Nilai Absolut
28 Sedangkan untuk euclidean distance jarak antara data dengan centroid dihitung dengan menggunakan rumus : Dimana P : Dimensi data. : Nilai Absolut
29 Pengalokasian Ulang Data Kedalam Masing-masing Cluster Untuk melakukan pengalokasian data kedalam masing-masing cluster pada saat iterasi dilakukan secara umum dengan dua cara yaitu dengan cara pengalokasian dengan cara hard k-means, dimana secara tegas setiap objek dinyatakan sebagai anggota cluster satu dan tidak menjadi anggota cluster lainnya. Cara lain adalah dengan cara fuzzy k-means dimana masing-masing objek diberikan nilai kemungkinan untuk bisa bergabung dengan setiap cluster yang ada.
30 Hard K-means, pengalokasian kembali objek kedalam masing-masing cluster pada metoda hard K-means didasarkan pada perbandingan jarak antara data dengan centroid setiap cluster yang ada, objek dialokasikan secara tegas kedalam cluster yang mempunyai jarak ke centroid terdekat dengan data tersebut. Pengalokasian ini dirumuskan sebagai berikut : a ik v i : keanggotaan data atau objek ke k pada cluster ke i : Nilai centroid cluster ke i
31 fuzzy k-means, pada fuzzy k-means atau lebih sering disebut fuzzy c-means mengalokasikan kembali objek atau data kedalam masing-masing cluster dengan menggunakan membership function, u ik,yang merujuk pada seberapa besar suatu objek atau data bisa menjadi anggota suatu cluster. Pada fuzzy k-means yang diusulkan oleh Bezdek diperkenalkan juga suatu variable m yang merupakan weighting exponent dari membership function. m mempunyai wilayah nilai m>1, sampai sekarang belum jelas berapa nilai m yang optimal dalam melakukan proses optimalisasi suatu permasalahan clustering
32 Nilai m yang umum digunakan adalah 2. Membership function untuk suatu data kedalam suatu cluster tertentu dihitung dengan menggunakan rumus : Dimana u ik : membership function untuk data atau objek ke k pada cluster ke i v i : Nilai centroid cluster ke i m : Weighting component c : Jumlah cluster
33 Konvergensi Pengecekan konvergensi dilakukan dengan membandingkan matrik group assignment pada iterasi sebelumnya dengan matrik group assignment pada iterasi yang sedang berjalan. Jika hasilnya sama maka algoritma k-means cluster analysis sudah konvergen, tetapi jika berbeda maka belum konvergen sehingga perlu dilakukan iterasi berikutnya
34 Menilai Kualitas Cluster Hasil dari cluster analysis yang bagus jika setiap cluster memiliki tingkat similaritas yang tinggi satu sama lain (internal homogeneity) diukur dengan variance dalam cluster V w yang sama sekali berbeda dengan nilai anggota cluster yang lain (external homogeneity) yang diukur dengan varian antar cluster V b Cluster dianggap ideal jika mempunya V w seminimal mungkin dan V b semaksimal mungkin, sehingga nilai homogenity dapat dirumuskan sebagai berikut : V Min V V w b
35 untuk rumus ini maka semakin kecil nilai V min maka homogenity semakin bagus, atau homogenity juga dapat dirumuskan sebagai berikut : Vb VMax Vw untuk rumus ini maka semakin besar nilai V max maka homogenity semakin bagus
36 Untuk menghitung nilai varians dari semua data pada tiap cluster dapat dilakukan dengan menggunakan rumus : Dimana V 2 c =variance pada cluster c c = 1..k dimana k = jumlah cluster n c = Jumlah data pada cluster ke c d i d i = data ke i pada suatu cluster = rata-rata atau centroid dari data pada suatu cluster
37 Sedangkan menghitung variance dalam cluster dapat dihitung dengan menggunakan rumus : Dimana V w = Varians dalam cluster N = Jumlah semua data k = Banyaknya cluster n i = Jumlah data dalam cluster ke i v i 2 = Variance pada cluster ke i
38 Sedangkan untuk menghitung varians antar cluster dihitung dengan menggunakan rumus : Dimana d rata rata d i Sedangkan nilai variance dari semua cluster diperoleh dengan membagi nilai variance dalam cluster dengan nilai variance antar cluster, dimana semakin kecil nilai tersebut maka semakin bagus cluster yang dihasilkan.
39 Beberapa Permasalahan K-Means Cluster Analysis Terdapat beberapa permasalahan yang sering ditemukan pada pemakaian algoritma K-means Cluster Analysis, antara lain yaitu : 1. Pemilihan jumlah custer yang tepat 2. Ditemukannya beberapa hasil cluster yang berbeda. 3. Nilai distance yang sama, sehingga berpengaruh pada alokasi data dalam cluster 4. Kegagalan Konvergensi 5. Pendeteksian Outlier
40 Contoh Penerapan Algoritma K-Means Cluster Analysis Misalkan kita mempunyai dua variable X 1 dan X 2 dengan masing-masing mempunyai item-item A, B, C dan D sebagai berikut : Observasi Item X 1 X 2 A 1 1 B 2 1 C 4 3 D 5 4
41 Tujuannya adalah membagi semua item menjadi 2 cluster ( k = 2), dengan menggunakan algoritma yang disebutkan diatas maka langkah-langkah yang dikerjakan adalah sebagai berikut : 1. Tentukan k sebagai jumlah cluster yang akan di bentuk k = 2 2. Bangkitkan k Centroid (titik pusat cluster) awal secara random Secara random kita tentukan A dan B sebagai centroid yang pertama, sehingga diperoleh c 1 =(1,1) dan c 2 =(2,1) 3. Hitung jarak setiap data ke masing-masing centroid dari masing-masing cluster dengan Euclidian distance sebagai berikut :
42 Dimana P : Dimensi data. : Nilai Absolut
43 D(C 1,B) = D(C 1,C) = D(C 1,D) = D(C 2,A) = D(C 2,B) = D(C 2,C) = D(C 2,D) = 2 2 (2 1) (1 1) (4 1) (3 1) 3, (5 1) (4 1) (1 2) (1 1) (2 2) (1 1) (4 2) (3 1) 2, (5 2) (4 1) 4, 24
44 Sehingga distance yang diperoleh adalah sebagai berikut Distance Cluster Centroid A B C D C ,61 5 C ,83 4,24
45 4. Alokasikan masing-masing data ke dalam centroid yang paling terdekat Proses alokasi dilakukan dengan melihat minimum distance. Dari table distance diatas maka terlihat bahwa jarak item A terdekat pada cluster C1 sehingga item A dialokasikan kepada cluster C 1, sementara item B, Item C, Item D jarak terdekatnya pada cluster C 2, sehingga item B, C, D dialokasikan pada cluster C 2.
46 Dengan menggunakan rumus alokasi dibawah ini, Maka diperoleh table group assigmentnya adalah sebagai berikut : A B C D
47 5. Lakukan iterasi-1, kemudian tentukan posisi centroid baru dengan cara menghitung rata-rata dari data-data yang berada pada centroid yang sama. Dengan menggunakan rumus, V i N i k 1 N X i k
48 Maka diperoleh centroid baru untuk kedua cluster tersebut adalah C 1 = (1,1), karena beranggotakan 1 anggota C 2( x ) ,67 C 2( x ) ,67 C 2 =(3.67, 2.67)
49 6. Ulangi langkah 3 jika posisi centroid baru dan centroid lama tidak sama, karena nilai centroidnya berbeda maka langkah no 3 diulangi kembali sebagai berikut :
50 D 1 (C 1,A) = D 1 (C 1,B) = D 1 (C 1,C) = D 1 (C 1,D) = D 1 (C 2,A) = D 1 (C 2,B) = D 1 (C 2,C) = D 1 (C 2,D) = 2 2 (1 1) (1 1) (2 1) (1 1) (4 1) (3 1) 3, (5 1) (4 1) (1 3,67) (1 2,67) 3, (2 3,67) (1 2,67) 2, (4 3,67) (3 2,67) 0, (5 3,67) (4 2,67) 1,89
51 Sehingga distance yang diperoleh pada iterasi 1 adalah sebagai berikut Distance Cluster Centroid A B C D C ,61 5 C2 3,14 2,36 0,47 1,89
52 Alokasikan masing-masing data ke dalam centroid yang paling terdekat Maka diperoleh table group assigmentnya pada iterasi 1 adalah sebagai berikut : A B C D
53 Karena hasil table group assignment pada iterasi 1 berbeda dengan table group assignment sebelumya maka hasilnya belum konvergen sehingga perlu dilakukan iterasi berikutnya, sebagai berikut Lakukan iterasi-2, tentukan posisi centroid baru dengan cara menghitung rata-rata dari data-data yang berada pada centroid yang sama. Maka diperoleh centroid baru untuk kedua cluster tersebut adalah
54 C 1( x ) C C 1 =(1.5, 1) 1 1( x ) , C C 2( x ) 1 2( x ) , ,5 2 C 2 =(4.5, 3.5)
55 karena nilai centroid-nya berbeda dengan iterasi 1 maka langkah berikutnya menghitung kembali distance-nya sebagai berikut :
56 D 2 (C 1,A) = D 2 (C 1,B) = D 2 (C 1,C) = D 1 (C 1,D) = D 2 (C 2,A) = D 2 (C 2,B) = D 2 (C 2,C) = D 2 (C 2,D) = 2 2 (1 1,5) (1 1) 0,5 2 2 (2 1,5) (1 1) 0,5 2 2 (4 1,5) (3 1) 3, (5 1,5) (4 1) 4, (1 4,5) (1 3,5) 4, (2 4.5) (1 3,5) 3, (4 4,5) (3 3,5) 0, (5 4,5) (4 3,5) 0,71
57 Sehingga distance yang diperoleh pada iterasi 1 adalah sebagai berikut Distance Cluster Centroid A B C D C1 0,5 0,5 3,2 4,61 C2 4,3 3,54 0,71 0,71
58 Alokasikan masing-masing data ke dalam centroid yang paling terdekat Maka diperoleh table group assigmentnya pada iterasi 2 adalah sebagai berikut : A B C D
59 Dari hasil table assignment pada iterasi 2 ternyata hasilnya sama dengan table group assignment pada iterasi 1 sehingga pada iterasi 2 ini sudah konvergen sehingga tidak perlu dilakukan iterasi kembali, dan hasil akhir cluster yg diperoleh adalah : Observasi Item X 1 X 2 Cluster A B C D 5 4 2
LABORATORIUM DATA MINING JURUSAN TEKNIK INDUSTRI FAKULTAS TEKNOLOGI INDUSTRI UNIVERSITAS ISLAM INDONESIA. Modul II CLUSTERING
 LABORATORIUM DATA MINING JURUSAN TEKNIK INDUSTRI FAKULTAS TEKNOLOGI INDUSTRI UNIVERSITAS ISLAM INDONESIA Modul II CLUSTERING TUJUA PRAKTIKUM 1. Mahasiswa mempunyai pengetahuan dan kemampuan dasar dalam
LABORATORIUM DATA MINING JURUSAN TEKNIK INDUSTRI FAKULTAS TEKNOLOGI INDUSTRI UNIVERSITAS ISLAM INDONESIA Modul II CLUSTERING TUJUA PRAKTIKUM 1. Mahasiswa mempunyai pengetahuan dan kemampuan dasar dalam
Tipe Clustering. Partitional Clustering. Hirerarchical Clustering
 Analisis Cluster Analisis Cluster Analisis cluster adalah pengorganisasian kumpulan pola ke dalam cluster (kelompok-kelompok) berdasar atas kesamaannya. Pola-pola dalam suatu cluster akan memiliki kesamaan
Analisis Cluster Analisis Cluster Analisis cluster adalah pengorganisasian kumpulan pola ke dalam cluster (kelompok-kelompok) berdasar atas kesamaannya. Pola-pola dalam suatu cluster akan memiliki kesamaan
BAB 2 LANDASAN TEORI
 BAB 2 LANDASAN TEORI 2.1 Clustering Pada dasarnya clustering terhadap data adalah suatu proses untuk mengelompokkan sekumpulan data tanpa suatu atribut kelas yang telah didefinisikan sebelumnya, berdasarkan
BAB 2 LANDASAN TEORI 2.1 Clustering Pada dasarnya clustering terhadap data adalah suatu proses untuk mengelompokkan sekumpulan data tanpa suatu atribut kelas yang telah didefinisikan sebelumnya, berdasarkan
METODE CLUSTERING DENGAN ALGORITMA K-MEANS. Oleh : Nengah Widya Utami
 METODE CLUSTERING DENGAN ALGORITMA K-MEANS Oleh : Nengah Widya Utami 1629101002 PROGRAM STUDI S2 ILMU KOMPUTER PROGRAM PASCASARJANA UNIVERSITAS PENDIDIKAN GANESHA SINGARAJA 2017 1. Definisi Clustering
METODE CLUSTERING DENGAN ALGORITMA K-MEANS Oleh : Nengah Widya Utami 1629101002 PROGRAM STUDI S2 ILMU KOMPUTER PROGRAM PASCASARJANA UNIVERSITAS PENDIDIKAN GANESHA SINGARAJA 2017 1. Definisi Clustering
BAB II LANDASAN TEORI
 BAB II LANDASAN TEORI II.1 Sistem Pendukung Keputusan II.1.1 Definisi Sistem Pendukung Keputusan Berdasarkan Efraim Turban dkk, Sistem Pendukung Keputusan (SPK) / Decision Support System (DSS) adalah sebuah
BAB II LANDASAN TEORI II.1 Sistem Pendukung Keputusan II.1.1 Definisi Sistem Pendukung Keputusan Berdasarkan Efraim Turban dkk, Sistem Pendukung Keputusan (SPK) / Decision Support System (DSS) adalah sebuah
ANALISIS CLUSTER PADA DOKUMEN TEKS
 Text dan Web Mining - FTI UKDW - BUDI SUSANTO 1 ANALISIS CLUSTER PADA DOKUMEN TEKS Budi Susanto (versi 1.3) Text dan Web Mining - FTI UKDW - BUDI SUSANTO 2 Tujuan Memahami konsep analisis clustering Memahami
Text dan Web Mining - FTI UKDW - BUDI SUSANTO 1 ANALISIS CLUSTER PADA DOKUMEN TEKS Budi Susanto (versi 1.3) Text dan Web Mining - FTI UKDW - BUDI SUSANTO 2 Tujuan Memahami konsep analisis clustering Memahami
Analisis cluster pengorganisasian kumpulan pola ke dalam cluster (kelompok-kelompok) berdasar atas kesamaannya. Pola-pola dalam suatu cluster akan
 berdasar atas kesamaannya. Pola-pola dalam suatu cluster akan") Analisis cluster pengorganisasian kumpulan pola ke dalam cluster (kelompok-kelompok) berdasar atas kesamaannya. Pola-pola dalam suatu cluster akan memiliki kesamaan ciri/sifat daripada pola-pola dalam
Analisis cluster pengorganisasian kumpulan pola ke dalam cluster (kelompok-kelompok) berdasar atas kesamaannya. Pola-pola dalam suatu cluster akan memiliki kesamaan ciri/sifat daripada pola-pola dalam
Pengenalan Pola. K-Means Clustering
 Pengenalan Pola K-Means Clustering PTIIK - 2014 Course Contents 1 Definisi k-means 2 Algoritma k-means 3 Studi Kasus 4 Latihan dan Diskusi K-Means Clustering K-Means merupakan salah satu metode pengelompokan
Pengenalan Pola K-Means Clustering PTIIK - 2014 Course Contents 1 Definisi k-means 2 Algoritma k-means 3 Studi Kasus 4 Latihan dan Diskusi K-Means Clustering K-Means merupakan salah satu metode pengelompokan
STUDI KOMPARATIF PENERAPAN METODE HIERARCHICAL, K-MEANS DAN SELF ORGANIZING MAPS (SOM) CLUSTERING PADA BASIS DATA. Abstract
 CLUSTERING PADA BASIS DATA. Abstract") STUDI KOMPARATIF PENERAPAN METODE HIERARCHICAL, K-MEANS DAN SELF ORGANIZING MAPS (SOM) CLUSTERING PADA BASIS DATA Undang Syaripudin 1, Ijang Badruzaman 2, Erwan Yani 3, Dede K 4, M. Ramdhani 5 1, 2 Teknik
STUDI KOMPARATIF PENERAPAN METODE HIERARCHICAL, K-MEANS DAN SELF ORGANIZING MAPS (SOM) CLUSTERING PADA BASIS DATA Undang Syaripudin 1, Ijang Badruzaman 2, Erwan Yani 3, Dede K 4, M. Ramdhani 5 1, 2 Teknik
ANALISIS CLUSTER PADA DOKUMEN TEKS
 Budi Susanto ANALISIS CLUSTER PADA DOKUMEN TEKS Text dan Web Mining - FTI UKDW - BUDI SUSANTO 1 Tujuan Memahami konsep analisis clustering Memahami tipe-tipe data dalam clustering Memahami beberapa algoritma
Budi Susanto ANALISIS CLUSTER PADA DOKUMEN TEKS Text dan Web Mining - FTI UKDW - BUDI SUSANTO 1 Tujuan Memahami konsep analisis clustering Memahami tipe-tipe data dalam clustering Memahami beberapa algoritma
BAB II LANDASAN TEORI
 BAB II LANDASAN TEORI 2.1 Clustering Analysis Clustering analysis merupakan metode pengelompokkan setiap objek ke dalam satu atau lebih dari satu kelompok,sehingga tiap objek yang berada dalam satu kelompok
BAB II LANDASAN TEORI 2.1 Clustering Analysis Clustering analysis merupakan metode pengelompokkan setiap objek ke dalam satu atau lebih dari satu kelompok,sehingga tiap objek yang berada dalam satu kelompok
BAB III ANALISIS DAN PERANCANGAN SISTEM
 BAB III ANALISIS DAN PERANCANGAN SISTEM Bab ini menjelaskan tentang analisis dan perancangan dalam membangun Aplikasi Data Mining. Analisis meliputi analisis data mining, analisis lingkungan sistem serta
BAB III ANALISIS DAN PERANCANGAN SISTEM Bab ini menjelaskan tentang analisis dan perancangan dalam membangun Aplikasi Data Mining. Analisis meliputi analisis data mining, analisis lingkungan sistem serta
BAB 2 TINJAUAN PUSTAKA
 4 BAB 2 TINJAUAN PUSTAKA 2.1 Metode Clustering Clustering adalah metode penganalisaan data, yang sering dimasukkan sebagai salah satu metode Data Mining, yang tujuannya adalah untuk mengelompokkan data
4 BAB 2 TINJAUAN PUSTAKA 2.1 Metode Clustering Clustering adalah metode penganalisaan data, yang sering dimasukkan sebagai salah satu metode Data Mining, yang tujuannya adalah untuk mengelompokkan data
SISTEM PENDUKUNG KEPUTUSAN MINAT PEMILIHAN JURUSAN SMA DENGAN METODE K-MEANS CLUSTER ANALYSIS
 SISTEM PENDUKUNG KEPUTUSAN MINAT PEMILIHAN JURUSAN SMA DENGAN METODE K-MEANS CLUSTER ANALYSIS Sahirul Muklis Magister Teknik Informatika STMIK AMIKOM Yogyakarta Jl Ring road Utara, Condongcatur, Sleman,
SISTEM PENDUKUNG KEPUTUSAN MINAT PEMILIHAN JURUSAN SMA DENGAN METODE K-MEANS CLUSTER ANALYSIS Sahirul Muklis Magister Teknik Informatika STMIK AMIKOM Yogyakarta Jl Ring road Utara, Condongcatur, Sleman,
BAB II TINJAUAN PUSTAKA
 BAB II TINJAUAN PUSTAKA A. Tinjauan Pustaka Pada penelitian yang dilakukan oleh (Chen, Sain, & Guo, 2012) berfokus untuk mengetahui pola penjualan, pelanggan mana yang paling berharga, pelanggan mana yang
BAB II TINJAUAN PUSTAKA A. Tinjauan Pustaka Pada penelitian yang dilakukan oleh (Chen, Sain, & Guo, 2012) berfokus untuk mengetahui pola penjualan, pelanggan mana yang paling berharga, pelanggan mana yang
DATA MINING. Pertemuan 9. Nizar Rabbi Radliya 3 SKS Semester 6 S1 Sistem Informasi
 DATA MINING 3 SKS Semester 6 S1 Sistem Informasi Pertemuan 9 Nizar Rabbi Radliya nizar.radliya@yahoo.com Universitas Komputer Indonesia 2016 Clustering Data Mining Penklusteran (clustering) digunakan untuk
DATA MINING 3 SKS Semester 6 S1 Sistem Informasi Pertemuan 9 Nizar Rabbi Radliya nizar.radliya@yahoo.com Universitas Komputer Indonesia 2016 Clustering Data Mining Penklusteran (clustering) digunakan untuk
Jumlah persentase ini tidak harus persis seperti diatas tetapi bisa bervariasi tergantung di perusahaan mana metode ini diterapkan.
 BAB 2 TINJAUAN PUSTAKA 2.1 Metode Pengelompokan ABC Pada abad ke-18, Villfredo Pareto, dalam penelitiannya mengenai distribusi kekayaan penduduk di Milan Italia, menemukan bahwa 20% dari total populasi
BAB 2 TINJAUAN PUSTAKA 2.1 Metode Pengelompokan ABC Pada abad ke-18, Villfredo Pareto, dalam penelitiannya mengenai distribusi kekayaan penduduk di Milan Italia, menemukan bahwa 20% dari total populasi
PENERAPAN ALGORITMA K-MEANS PADA SISWA BARU SEKOLAHMENENGAH KEJURUAN UNTUK CLUSTERING JURUSAN
 PENERAPAN ALGORITMA K-MEANS PADA SISWA BARU SEKOLAHMENENGAH KEJURUAN UNTUK CLUSTERING JURUSAN Fauziah Nur1, Prof. M. Zarlis2, Dr. Benny Benyamin Nasution3 Program Studi Magister Teknik Informatika, Universitas
PENERAPAN ALGORITMA K-MEANS PADA SISWA BARU SEKOLAHMENENGAH KEJURUAN UNTUK CLUSTERING JURUSAN Fauziah Nur1, Prof. M. Zarlis2, Dr. Benny Benyamin Nasution3 Program Studi Magister Teknik Informatika, Universitas
Analisis Cluster, Analisis Diskriminan & Analisis Komponen Utama. Analisis Cluster
 Analisis Cluster Analisis Cluster adalah suatu analisis statistik yang bertujuan memisahkan kasus/obyek ke dalam beberapa kelompok yang mempunyai sifat berbeda antar kelompok yang satu dengan yang lain.
Analisis Cluster Analisis Cluster adalah suatu analisis statistik yang bertujuan memisahkan kasus/obyek ke dalam beberapa kelompok yang mempunyai sifat berbeda antar kelompok yang satu dengan yang lain.
Clustering. Virginia Postrel
 8 Clustering Most of us cluster somewhere in the middle of most statistical distributions. But there are lots of bell curves, and pretty much everyone is on a tail of at least one of them. We may collect
8 Clustering Most of us cluster somewhere in the middle of most statistical distributions. But there are lots of bell curves, and pretty much everyone is on a tail of at least one of them. We may collect
BAB II LANDASAN TEORI
 BAB II LANDASAN TEORI 2.1 Traveling Salesmen Problem (TSP) Travelling Salesman Problem (TSP) merupakan sebuah permasalahan optimasi yang dapat diterapkan pada berbagai kegiatan seperti routing. Masalah
BAB II LANDASAN TEORI 2.1 Traveling Salesmen Problem (TSP) Travelling Salesman Problem (TSP) merupakan sebuah permasalahan optimasi yang dapat diterapkan pada berbagai kegiatan seperti routing. Masalah
BAB II TINJAUAN PUSTAKA DAN LANDASAN TEORI. Penelitian dengan menggunakan metode k-means dan metode fuzzy c-means
 BAB II TINJAUAN PUSTAKA DAN LANDASAN TEORI Pada bagian ini akan memuat literatur dan landasan teori yang mendukung serta relevan dengan laporan penelitian. 2.1 Tinjauan Pustaka Penelitian dengan menggunakan
BAB II TINJAUAN PUSTAKA DAN LANDASAN TEORI Pada bagian ini akan memuat literatur dan landasan teori yang mendukung serta relevan dengan laporan penelitian. 2.1 Tinjauan Pustaka Penelitian dengan menggunakan
JURNAL TEKNOLOGI INFORMASI & PENDIDIKAN ISSN : VOL. 9 NO. 1 April 2016
 ANALISA DAN PENERAPAN DATA MINING UNTUK MENENTUKAN KUBIKASI AIR TERJUAL BERDASARKAN PENGELOMPOKAN PELANGGAN MENGGUNAKAN ALGORITMA K-MEANS CLUSTERING Sri Tria Siska 1 ABSTRACT This study aims to determine
ANALISA DAN PENERAPAN DATA MINING UNTUK MENENTUKAN KUBIKASI AIR TERJUAL BERDASARKAN PENGELOMPOKAN PELANGGAN MENGGUNAKAN ALGORITMA K-MEANS CLUSTERING Sri Tria Siska 1 ABSTRACT This study aims to determine
TAKARIR. : Mengelompokkan suatu objek yang memiliki kesamaan. : Kelompok atau kelas
 TAKARIR Data Mining Clustering Cluster Iteratif Random Centroid : Penggalian data : Mengelompokkan suatu objek yang memiliki kesamaan. : Kelompok atau kelas : Berulang : Acak : Pusat area KDD (Knowledge
TAKARIR Data Mining Clustering Cluster Iteratif Random Centroid : Penggalian data : Mengelompokkan suatu objek yang memiliki kesamaan. : Kelompok atau kelas : Berulang : Acak : Pusat area KDD (Knowledge
IMPLEMENTASI METODE K-MEANS PADA PENERIMAAN SISWA BARU
 PROYEK TUGAS AKHIR IMPLEMENTASI METODE K-MEANS PADA PENERIMAAN SISWA BARU (Studi Kasus : SMK Pembangunan Nasional Purwodadi) Disusun oleh: Novian Hari Pratama 10411 PROGRAM STUDI TEKNIK INFORMATIKA FAKULTAS
PROYEK TUGAS AKHIR IMPLEMENTASI METODE K-MEANS PADA PENERIMAAN SISWA BARU (Studi Kasus : SMK Pembangunan Nasional Purwodadi) Disusun oleh: Novian Hari Pratama 10411 PROGRAM STUDI TEKNIK INFORMATIKA FAKULTAS
BAB I PENDAHULUAN. Analisis statistik multivariat adalah metode statistik di mana masalah yang
 BAB I PENDAHULUAN 1.1. LATAR BELAKANG MASALAH Analisis statistik multivariat adalah metode statistik di mana masalah yang diteliti bersifat multidimensional dengan menggunakan tiga atau lebih variabel
BAB I PENDAHULUAN 1.1. LATAR BELAKANG MASALAH Analisis statistik multivariat adalah metode statistik di mana masalah yang diteliti bersifat multidimensional dengan menggunakan tiga atau lebih variabel
BAB II KAJIAN TEORI. linier, varian dan simpangan baku, standarisasi data, koefisien korelasi, matriks
 BAB II KAJIAN TEORI Pada bab II akan dibahas tentang materi-materi dasar yang digunakan untuk mendukung pembahasan pada bab selanjutnya, yaitu matriks, kombinasi linier, varian dan simpangan baku, standarisasi
BAB II KAJIAN TEORI Pada bab II akan dibahas tentang materi-materi dasar yang digunakan untuk mendukung pembahasan pada bab selanjutnya, yaitu matriks, kombinasi linier, varian dan simpangan baku, standarisasi
BAB I PENDAHULUAN Latar Belakang
 BAB I PENDAHULUAN 1.1. Latar Belakang Mobilitas adalah hal yang tidak dapat dipisahkan dalam gaya hidup masyarakat sekarang ini. Serangkaian aktifitas menuntut seseorang untuk berada di suatu tempat bahkan
BAB I PENDAHULUAN 1.1. Latar Belakang Mobilitas adalah hal yang tidak dapat dipisahkan dalam gaya hidup masyarakat sekarang ini. Serangkaian aktifitas menuntut seseorang untuk berada di suatu tempat bahkan
BAB III K-MEDIANS CLUSTERING
 BAB III 3.1 ANALISIS KLASTER Analisis klaster merupakan salah satu teknik multivariat metode interdependensi (saling ketergantungan). Metode interdependensi berfungsi untuk memberikan makna terhadap seperangkat
BAB III 3.1 ANALISIS KLASTER Analisis klaster merupakan salah satu teknik multivariat metode interdependensi (saling ketergantungan). Metode interdependensi berfungsi untuk memberikan makna terhadap seperangkat
MEMANFAATKAN ALGORITMA K-MEANS DALAM MENENTUKAN PEGAWAI YANG LAYAK MENGIKUTI ASESSMENT CENTER UNTUK CLUSTERING PROGRAM SDP
 MEMANFAATKAN ALGORITMA K-MEANS DALAM MENENTUKAN PEGAWAI YANG LAYAK MENGIKUTI ASESSMENT CENTER UNTUK CLUSTERING PROGRAM SDP Page 87 Iin Parlina 1, Agus Perdana Windarto 2, Anjar Wanto 3, M.Ridwan Lubis
MEMANFAATKAN ALGORITMA K-MEANS DALAM MENENTUKAN PEGAWAI YANG LAYAK MENGIKUTI ASESSMENT CENTER UNTUK CLUSTERING PROGRAM SDP Page 87 Iin Parlina 1, Agus Perdana Windarto 2, Anjar Wanto 3, M.Ridwan Lubis
Pengenalan Pola. Klasterisasi Data
 Pengenalan Pola Klasterisasi Data PTIIK - 2014 Course Contents 1 Konsep Dasar 2 Tahapan Proses Klasterisasi 3 Ukuran Kemiripan Data 4 Algoritma Klasterisasi Konsep Dasar Klusterisasi Data, atau Data Clustering
Pengenalan Pola Klasterisasi Data PTIIK - 2014 Course Contents 1 Konsep Dasar 2 Tahapan Proses Klasterisasi 3 Ukuran Kemiripan Data 4 Algoritma Klasterisasi Konsep Dasar Klusterisasi Data, atau Data Clustering
PENGELOMPOKAN MINAT BACA MAHASISWA MENGGUNAKAN METODE K-MEANS
 Jurnal Ilmiah ILKOM Volume 8 mor (Agustus 16) ISSN: 87-1716 PENGELOMPOKAN MINAT BACA MAHASISWA MENGGUNAKAN METODE K-MEANS Widya Safira Azis 1 dan Dedy Atmajaya 1 safiraazis18@gmail.com dan dedy.atmajaya@umi.ac.id
Jurnal Ilmiah ILKOM Volume 8 mor (Agustus 16) ISSN: 87-1716 PENGELOMPOKAN MINAT BACA MAHASISWA MENGGUNAKAN METODE K-MEANS Widya Safira Azis 1 dan Dedy Atmajaya 1 safiraazis18@gmail.com dan dedy.atmajaya@umi.ac.id
PENGGUNAAN METODE PENGKLASTERAN UNTUK MENENTUKAN BIDANG TUGAS AKHIR MAHASISWA TEKNIK INFORMATIKA PENS BERDASARKAN NILAI
 PENGGUNAAN PENGKLASTERAN UNTUK MENENTUKAN BIDANG TUGAS AKHIR MAHASISWA TEKNIK INFORMATIKA PENS BERDASARKAN NILAI Entin Martiana S.Kom,M.Kom, Nur Rosyid Mubtada i S. Kom, Edi Purnomo Jurusan Teknik Informatika
PENGGUNAAN PENGKLASTERAN UNTUK MENENTUKAN BIDANG TUGAS AKHIR MAHASISWA TEKNIK INFORMATIKA PENS BERDASARKAN NILAI Entin Martiana S.Kom,M.Kom, Nur Rosyid Mubtada i S. Kom, Edi Purnomo Jurusan Teknik Informatika
Proses mengelompokkan suatu set objek ke dalam kelompok-kelompok objek yang sejenis. Bentuk yang paling umum digunakan adalah unsupervised learning
 CLUSTERING DEFINISI Clustering : Proses mengelompokkan suatu set objek ke dalam kelompok-kelompok objek yang sejenis Bentuk yang paling umum digunakan adalah unsupervised learning # Unsupervised learning
CLUSTERING DEFINISI Clustering : Proses mengelompokkan suatu set objek ke dalam kelompok-kelompok objek yang sejenis Bentuk yang paling umum digunakan adalah unsupervised learning # Unsupervised learning
BAB II TINJAUAN PUSTAKA
 BAB II TINJAUAN PUSTAKA A. Knowledge Discovery in Database (KDD) dan Data Mining Banyak orang menggunakan istilah data mining dan knowledge discovery in databases (KDD) secara bergantian untuk menjelaskan
BAB II TINJAUAN PUSTAKA A. Knowledge Discovery in Database (KDD) dan Data Mining Banyak orang menggunakan istilah data mining dan knowledge discovery in databases (KDD) secara bergantian untuk menjelaskan
BAB 2 TINJAUAN PUSTAKA Klasifikasi Data Mahasiswa Menggunakan Metode K-Means Untuk Menunjang Pemilihan Strategi Pemasaran
 BAB 2 TINJAUAN PUSTAKA 2.1 Tinjauan Pustaka Beberapa penelitian terdahulu telah banyak yang menerapkan data mining, yang bertujuan dalam menyelesaikan beberapa permasalahan seputar dunia pendidikan. Khususnya
BAB 2 TINJAUAN PUSTAKA 2.1 Tinjauan Pustaka Beberapa penelitian terdahulu telah banyak yang menerapkan data mining, yang bertujuan dalam menyelesaikan beberapa permasalahan seputar dunia pendidikan. Khususnya
JULIO ADISANTOSO - ILKOM IPB 1
 KOM341 Temu Kembali Informasi KULIAH #9 Text Clustering (Ch.16 & 17) Clustering Pengelompokan, penggerombolan Proses pengelompokan sekumpulan obyek ke dalam kelas-kelas obyek yang memiliki sifat sama.
KOM341 Temu Kembali Informasi KULIAH #9 Text Clustering (Ch.16 & 17) Clustering Pengelompokan, penggerombolan Proses pengelompokan sekumpulan obyek ke dalam kelas-kelas obyek yang memiliki sifat sama.
BAB II LANDASAN TEORI
 BAB II LANDASAN TEORI 2.1 Data Mining Faktor penentu bagi usaha atau bisnis apapun pada masa sekarang ini adalah kemampuan untuk menggunakan informasi seefektif mungkin. Penggunaan data secara tepat karena
BAB II LANDASAN TEORI 2.1 Data Mining Faktor penentu bagi usaha atau bisnis apapun pada masa sekarang ini adalah kemampuan untuk menggunakan informasi seefektif mungkin. Penggunaan data secara tepat karena
BAB II TINJAUAN PUSTAKA DAN DASAR TEORI. Pada penelitian Rismawan dan Kusumadewi (2008) mengelompokkan
 mengelompokkan") BAB II TINJAUAN PUSTAKA DAN DASAR TEORI 2.1. Tinjauan Pustaka Pada penelitian Rismawan dan Kusumadewi (2008) mengelompokkan mahasiswa berdasarkan status gizi Body Mass Index (BMI) dan ukuran kerangka.
BAB II TINJAUAN PUSTAKA DAN DASAR TEORI 2.1. Tinjauan Pustaka Pada penelitian Rismawan dan Kusumadewi (2008) mengelompokkan mahasiswa berdasarkan status gizi Body Mass Index (BMI) dan ukuran kerangka.
BAB II TINJAUAN PUSTAKA
 BAB II TINJAUAN PUSTAKA 2.1 Konsep Clustering dalam Data Mining Konsep dasar data mining adalah menemukan informasi tersembunyi dalam sebuah basis data dan merupakan bagian dari Knowledge Discovery in
BAB II TINJAUAN PUSTAKA 2.1 Konsep Clustering dalam Data Mining Konsep dasar data mining adalah menemukan informasi tersembunyi dalam sebuah basis data dan merupakan bagian dari Knowledge Discovery in
PENGKLASIFIKASIAN DATA SEKOLAH PENGGUNA INTERNET PENDIDIKAN MENGGUNAKAN TEKNIK CLUSTERING DENGAN ALGORITMA K-MEANS STUDI KASUS PT TELKOM SURABAYA
 Artikel Skripsi PENGKLASIFIKASIAN DATA SEKOLAH PENGGUNA INTERNET PENDIDIKAN MENGGUNAKAN TEKNIK CLUSTERING DENGAN ALGORITMA K-MEANS STUDI KASUS PT TELKOM SURABAYA SKRIPSI Diajukan Untuk Memenuhi Sebagian
Artikel Skripsi PENGKLASIFIKASIAN DATA SEKOLAH PENGGUNA INTERNET PENDIDIKAN MENGGUNAKAN TEKNIK CLUSTERING DENGAN ALGORITMA K-MEANS STUDI KASUS PT TELKOM SURABAYA SKRIPSI Diajukan Untuk Memenuhi Sebagian
BAB II TINJAUAN PUSTAKA
 BAB II TINJAUAN PUSTAKA 2.1. Penambangan Data (Data Mining) Penambangan data (Data Mining) adalah serangkaian proses untuk menggali nilai tambah dari sekumpulan data berupa pengetahuan yang selama ini
BAB II TINJAUAN PUSTAKA 2.1. Penambangan Data (Data Mining) Penambangan data (Data Mining) adalah serangkaian proses untuk menggali nilai tambah dari sekumpulan data berupa pengetahuan yang selama ini
JURNAL TEKNIK POMITS Vol. 1, No. 1, (2012) 1-5 1
 1-5 1") JURNAL TEKNIK POMITS Vol. 1, No. 1, (2012) 1-5 1 ANALISA PERBANDINGAN METODE HIERARCHICAL CLUSTERING, K-MEANS DAN GABUNGAN KEDUANYA DALAM MEMBENTUK CLUSTER DATA (STUDI KASUS : PROBLEM KERJA PRAKTEK JURUSAN
JURNAL TEKNIK POMITS Vol. 1, No. 1, (2012) 1-5 1 ANALISA PERBANDINGAN METODE HIERARCHICAL CLUSTERING, K-MEANS DAN GABUNGAN KEDUANYA DALAM MEMBENTUK CLUSTER DATA (STUDI KASUS : PROBLEM KERJA PRAKTEK JURUSAN
BAB IV ANALISIS DAN PERANCANGAN
 BAB IV ANALISIS DAN PERANCANGAN 4.1. Analisa 4.1.1 Analisis Data Pada tahap analisa data ini akan dibahas mengenai citra CT Scan yang akan dilakukan proses segmentasi atau pengelompokan data. Data citra
BAB IV ANALISIS DAN PERANCANGAN 4.1. Analisa 4.1.1 Analisis Data Pada tahap analisa data ini akan dibahas mengenai citra CT Scan yang akan dilakukan proses segmentasi atau pengelompokan data. Data citra
Klasifikasi Kecamatan Berdasarkan Nilai Akhir SMA/MA di Kabupaten Aceh Selatan Menggunakan Analisis Diskriminan
 Statistika, Vol. 15 No. 2, 87-97 November 215 Klasifikasi Kecamatan Berdasarkan Nilai Akhir SMA/MA di Kabupaten Aceh Selatan Menggunakan Analisis Diskriminan Fitriana A.R. 1, Nurhasanah 2, Ririn Raudhatul
Statistika, Vol. 15 No. 2, 87-97 November 215 Klasifikasi Kecamatan Berdasarkan Nilai Akhir SMA/MA di Kabupaten Aceh Selatan Menggunakan Analisis Diskriminan Fitriana A.R. 1, Nurhasanah 2, Ririn Raudhatul
Analisis Perbandingan Algoritma Fuzzy C-Means dan K-Means
 Analisis Perbandingan Algoritma Fuzzy C-Means dan K-Means Yohannes Teknik Informatika STMIK GI MDD Palembang, Indonesia Abstrak Klasterisasi merupakan teknik pengelompokkan data berdasarkan kemiripan data.
Analisis Perbandingan Algoritma Fuzzy C-Means dan K-Means Yohannes Teknik Informatika STMIK GI MDD Palembang, Indonesia Abstrak Klasterisasi merupakan teknik pengelompokkan data berdasarkan kemiripan data.
IMPLEMENTASI METODE KLASTERING K-MEANS UNTUK MENGELOMPOKAN HASIL EVALUASI MAHASISWA. FEBRIZAL ALFARASY SYAM Dosen STMIK Dharmapala Riau ABSTRAK
 Jurnal Ilmu Komputer dan Bisnis, Volume 8, Nomor 1, Mei 017 IMPLEMENTASI METODE KLASTERING K-MEANS UNTUK MENGELOMPOKAN HASIL EVALUASI MAHASISWA FEBRIZAL ALFARASY SYAM Dosen STMIK Dharmapala Riau ABSTRAK
Jurnal Ilmu Komputer dan Bisnis, Volume 8, Nomor 1, Mei 017 IMPLEMENTASI METODE KLASTERING K-MEANS UNTUK MENGELOMPOKAN HASIL EVALUASI MAHASISWA FEBRIZAL ALFARASY SYAM Dosen STMIK Dharmapala Riau ABSTRAK
BAB III K-MEANS CLUSTERING. Analisis klaster merupakan salah satu teknik multivariat metode
 BAB III K-MEANS CLUSTERING 3.1 Analisis Klaster Analisis klaster merupakan salah satu teknik multivariat metode interdependensi (saling ketergantungan). Oleh karena itu, dalam analisis klaster tidak ada
BAB III K-MEANS CLUSTERING 3.1 Analisis Klaster Analisis klaster merupakan salah satu teknik multivariat metode interdependensi (saling ketergantungan). Oleh karena itu, dalam analisis klaster tidak ada
BAB II LANDASAN TEORI
 BAB II LANDASAN TEORI 2.1 Text Mining Text mining, yang juga disebut text data mining (TDM) atau knowledge discovery in text( KDT), secara umum mengacu pada proses ekstraksi informasi dari dokumen-dokumen
BAB II LANDASAN TEORI 2.1 Text Mining Text mining, yang juga disebut text data mining (TDM) atau knowledge discovery in text( KDT), secara umum mengacu pada proses ekstraksi informasi dari dokumen-dokumen
BAB II LANDASAN TEORI. yang terdiri dari komponen-komponen atau sub sistem yang berorientasi untuk
 BAB II LANDASAN TEORI 2.1 Sistem Menurut Gondodiyoto (2007), sistem adalah merupakan suatu kesatuan yang terdiri dari komponen-komponen atau sub sistem yang berorientasi untuk mencapai suatu tujuan tertentu.
BAB II LANDASAN TEORI 2.1 Sistem Menurut Gondodiyoto (2007), sistem adalah merupakan suatu kesatuan yang terdiri dari komponen-komponen atau sub sistem yang berorientasi untuk mencapai suatu tujuan tertentu.
CLUSTERING MENGGUNAKAN K-MEANS ALGORITHM (K-MEANS ALGORITHM CLUSTERING)
") CLUSTERING MENGGUNAKAN K-MEANS ALGORITHM (K-MEANS ALGORITHM CLUSTERING) Nur Wakhidah Fakultas Teknologi Informasi dan Komunikasi Universitas Semarang Abstract Classification is the process of organizing
CLUSTERING MENGGUNAKAN K-MEANS ALGORITHM (K-MEANS ALGORITHM CLUSTERING) Nur Wakhidah Fakultas Teknologi Informasi dan Komunikasi Universitas Semarang Abstract Classification is the process of organizing
IMPLEMENTASI DETEKSI OUTLIER PADA ALGORITMA HIERARCHICAL CLUSTERING
 IMPLEMENTASI DETEKSI OUTLIER PADA ALGORITMA HIERARCHICAL CLUSTERING Yoga Bhagawad Gita 1, Ahmad Saikhu 2 1,2 Jurusan Teknik Informatika, Fakultas Teknologi Informasi Institut Teknologi Sepuluh Nopember
IMPLEMENTASI DETEKSI OUTLIER PADA ALGORITMA HIERARCHICAL CLUSTERING Yoga Bhagawad Gita 1, Ahmad Saikhu 2 1,2 Jurusan Teknik Informatika, Fakultas Teknologi Informasi Institut Teknologi Sepuluh Nopember
Jl. Raya Dukuhwaluh Purwokerto )
") Sistem Klasterisasi Menggunakan Metode K-Means dalam Menentukan Posisi Access Point Berdasarkan Posisi Hotspot di Universitas Muhammadiyah Purwokerto (Clustering System Using K-Means Method in Determining
Sistem Klasterisasi Menggunakan Metode K-Means dalam Menentukan Posisi Access Point Berdasarkan Posisi Hotspot di Universitas Muhammadiyah Purwokerto (Clustering System Using K-Means Method in Determining
BAB I PENDAHULUAN Latar Belakang
 1 BAB I PENDAHULUAN 1.1. Latar Belakang Clustering adalah proses di dalam mencari dan mengelompokkan data yang memiliki kemiripan karakteristik (similarity) antara satu data dengan data yang lain. Clustering
1 BAB I PENDAHULUAN 1.1. Latar Belakang Clustering adalah proses di dalam mencari dan mengelompokkan data yang memiliki kemiripan karakteristik (similarity) antara satu data dengan data yang lain. Clustering
BAB 2 LANDASAN TEORI
 BAB 2 LANDASAN TEORI Bab ini berisi penjelasan mengenai image clustering, pengukuran kemiripan dan pengukuran jarak, representasi citra, ruang warna, algoritma clustering, dan penelitian yang berhubungan.
BAB 2 LANDASAN TEORI Bab ini berisi penjelasan mengenai image clustering, pengukuran kemiripan dan pengukuran jarak, representasi citra, ruang warna, algoritma clustering, dan penelitian yang berhubungan.
ANALISIS KLASTERING LIRIK LAGU INDONESIA
 ANALISIS KLASTERING LIRIK LAGU INDONESIA Afdilah Marjuki 1, Herny Februariyanti 2 1,2 Program Studi Sistem Informasi, Fakultas Teknologi Informasi, Universitas Stikubank e-mail: 1 bodongben@gmail.com,
ANALISIS KLASTERING LIRIK LAGU INDONESIA Afdilah Marjuki 1, Herny Februariyanti 2 1,2 Program Studi Sistem Informasi, Fakultas Teknologi Informasi, Universitas Stikubank e-mail: 1 bodongben@gmail.com,
BAB II TINJAUAN PUSTAKA DAN DASAR TEORI Tinjauan Pustaka Penelitian terkait metode clustering atau algoritma k-means pernah di
 BAB II TINJAUAN PUSTAKA DAN DASAR TEORI 2.1. Tinjauan Pustaka Penelitian terkait metode clustering atau algoritma k-means pernah di lakukan oleh Muhammad Toha dkk (2013), Sylvia Pretty Tulus (2014), Johan
BAB II TINJAUAN PUSTAKA DAN DASAR TEORI 2.1. Tinjauan Pustaka Penelitian terkait metode clustering atau algoritma k-means pernah di lakukan oleh Muhammad Toha dkk (2013), Sylvia Pretty Tulus (2014), Johan
UKDW BAB I PENDAHULUAN
 BAB I PENDAHULUAN 1.1 Latar Belakang Dalam dunia bisnis pada jaman sekarang, para pelaku bisnis senantiasa selalu berusaha mengembangkan cara-cara untuk dapat mengembangkan usaha mereka dan memperhatikan
BAB I PENDAHULUAN 1.1 Latar Belakang Dalam dunia bisnis pada jaman sekarang, para pelaku bisnis senantiasa selalu berusaha mengembangkan cara-cara untuk dapat mengembangkan usaha mereka dan memperhatikan
IMPLEMENTASI ALGORITMA K-MEANS CLUSTERING UNTUK MENENTUKAN PENJURUSAN KELAS IPA, IPS, DAN SASTRA
 IMPLEMENTASI ALGORITMA K-MEANS CLUSTERING UNTUK MENENTUKAN PENJURUSAN KELAS IPA, IPS, DAN SASTRA Nama : Nandang Syaefulloh NPM : 55412243 Fakultas : Teknologi Industri Jurusan : Teknik Informatika Pembimbing
IMPLEMENTASI ALGORITMA K-MEANS CLUSTERING UNTUK MENENTUKAN PENJURUSAN KELAS IPA, IPS, DAN SASTRA Nama : Nandang Syaefulloh NPM : 55412243 Fakultas : Teknologi Industri Jurusan : Teknik Informatika Pembimbing
JURNAL TEKNIK ITS Vol. 1, (Sept, 2012) ISSN: A-521
 ISSN: A-521") JURNAL TEKNIK ITS Vol. 1, (Sept, 2012) ISSN: 2301-9271 A-521 Analisa Perbandingan Metode Hierarchical Clustering, K-means dan Gabungan Keduanya dalam Cluster Data (Studi kasus : Problem Kerja Praktek Jurusan
JURNAL TEKNIK ITS Vol. 1, (Sept, 2012) ISSN: 2301-9271 A-521 Analisa Perbandingan Metode Hierarchical Clustering, K-means dan Gabungan Keduanya dalam Cluster Data (Studi kasus : Problem Kerja Praktek Jurusan
Data Mining. Clustering. Oleh : Suprayogi
 Data Mining Clustering Oleh : Suprayogi Pendahuluan Saat ini terjadi fenomena yaitu berupa data yang melimpah, setiap hari banyak orang yang berurusan dengan data yang bersumber dari berbagai jenis observasi
Data Mining Clustering Oleh : Suprayogi Pendahuluan Saat ini terjadi fenomena yaitu berupa data yang melimpah, setiap hari banyak orang yang berurusan dengan data yang bersumber dari berbagai jenis observasi
K-PROTOTYPE UNTUK PENGELOMPOKAN DATA CAMPURAN
 1 K-PROTOTYPE UNTUK PENGELOMPOKAN DATA CAMPURAN Rani Nooraeni*, Dr. Jadi Supriadi, DEA, Zulhanif, S.Si,M.Sc Jurusan statistika terapan, Fakultas MIPA UNPAD rnooraeni@gmail.com* Abstrak.Membagi suatu data
1 K-PROTOTYPE UNTUK PENGELOMPOKAN DATA CAMPURAN Rani Nooraeni*, Dr. Jadi Supriadi, DEA, Zulhanif, S.Si,M.Sc Jurusan statistika terapan, Fakultas MIPA UNPAD rnooraeni@gmail.com* Abstrak.Membagi suatu data
Pertemuan 14 HIERARCHICAL CLUSTERING METHODS
 Pertemuan 14 HIERARCHICAL CLUSTERING METHODS berdasar gambar berdasar warna A A A A Q Q Q Q K K K K J J J J 2 2 2 2 3 3 3 3 4 4 4 4 5 5 5 5 6 6 6 6 7 7 7 7 8 8 8 8 9 9 9 9 10 10 10 10 A K Q J (a). Individual
Pertemuan 14 HIERARCHICAL CLUSTERING METHODS berdasar gambar berdasar warna A A A A Q Q Q Q K K K K J J J J 2 2 2 2 3 3 3 3 4 4 4 4 5 5 5 5 6 6 6 6 7 7 7 7 8 8 8 8 9 9 9 9 10 10 10 10 A K Q J (a). Individual
ARTIKEL SISTEM PEMBAGIAN KELOMPOK BELAJAR SISWA MENGGUNAKAN METODE K-MEANS CLUSTERING DI SD NEGERI 1 NGEBONG KABUPATEN TULUNGAGUNG
 ARTIKEL SISTEM PEMBAGIAN KELOMPOK BELAJAR SISWA MENGGUNAKAN METODE K-MEANS CLUSTERING DI SD NEGERI 1 NGEBONG KABUPATEN TULUNGAGUNG Oleh: BAGUS YAYANG FATKHURRAHMAN 13.1.03.02.0180 Dibimbing oleh : 1. Ahmad
ARTIKEL SISTEM PEMBAGIAN KELOMPOK BELAJAR SISWA MENGGUNAKAN METODE K-MEANS CLUSTERING DI SD NEGERI 1 NGEBONG KABUPATEN TULUNGAGUNG Oleh: BAGUS YAYANG FATKHURRAHMAN 13.1.03.02.0180 Dibimbing oleh : 1. Ahmad
BAB 2 LANDASAN TEORI
 7 BAB 2 LANDASAN TEORI Bab ini membahas tentang teori penunjang dan penelitian sebelumnya yang berhubungan dengan penerapan algoritma hierarchical clustering dan k-means untuk pengelompokan desa tertinggal.
7 BAB 2 LANDASAN TEORI Bab ini membahas tentang teori penunjang dan penelitian sebelumnya yang berhubungan dengan penerapan algoritma hierarchical clustering dan k-means untuk pengelompokan desa tertinggal.
BAB II LANDASAN TEORI
 BAB II LANDASAN TEORI 2.1. Sistem Informasi Pengertian Sistem Informasi pada dasarnya merupakan hasil dari dua arti, yakni sistem dan informasi yang digabungkan. Berikut definisi sistem menurut para ahli
BAB II LANDASAN TEORI 2.1. Sistem Informasi Pengertian Sistem Informasi pada dasarnya merupakan hasil dari dua arti, yakni sistem dan informasi yang digabungkan. Berikut definisi sistem menurut para ahli
PENENTUAN NILAI PANGKAT PADA ALGORITMA FUZZY C- MEANS
 PENENTUAN NILAI PANGKAT PADA ALGORITMA FUZZY C- MEANS WULAN ANGGRAENI wulangussetiyo@gmail.com Program Studi Pendidikan Matematika Universitas Indraprasta PGRI Abstract. The purpose of this study was to
PENENTUAN NILAI PANGKAT PADA ALGORITMA FUZZY C- MEANS WULAN ANGGRAENI wulangussetiyo@gmail.com Program Studi Pendidikan Matematika Universitas Indraprasta PGRI Abstract. The purpose of this study was to
BAB I PENDAHULUAN I.1 Latar Belakang
 BAB I PENDAHULUAN I.1 Latar Belakang Di tengah laju kemajuan teknologi telekomunikasi dan informatika, informasi yang cepat dan akurat semakin menjadi kebutuhan pokok para pengambil keputusan. Informasi
BAB I PENDAHULUAN I.1 Latar Belakang Di tengah laju kemajuan teknologi telekomunikasi dan informatika, informasi yang cepat dan akurat semakin menjadi kebutuhan pokok para pengambil keputusan. Informasi
SEGMENTASI CITRA. thresholding
 SEGMENTASI CITRA Dalam visi komputer, Segmentasi adalah proses mempartisi citra digital menjadi beberapa segmen (set piksel, juga dikenal sebagai superpixels). Tujuan dari segmentasi adalah untuk menyederhanakan
SEGMENTASI CITRA Dalam visi komputer, Segmentasi adalah proses mempartisi citra digital menjadi beberapa segmen (set piksel, juga dikenal sebagai superpixels). Tujuan dari segmentasi adalah untuk menyederhanakan
DETEKSI MAHASISWA BERPRESTASI DAN BERMASALAH DENGAN METODE K- MEANS KLASTERING YANG DIOPTIMASI DENGAN ALGORITMA GENETIKA
 DETEKSI MAHASISWA BERPRESTASI DAN BERMASALAH DENGAN METODE K- MEANS KLASTERING YANG DIOPTIMASI DENGAN ALGORITMA GENETIKA Akmal Hidayat 1) & Entin Martiana 2) 1) Teknik Elektro Politeknik Bengkalis Jl.
DETEKSI MAHASISWA BERPRESTASI DAN BERMASALAH DENGAN METODE K- MEANS KLASTERING YANG DIOPTIMASI DENGAN ALGORITMA GENETIKA Akmal Hidayat 1) & Entin Martiana 2) 1) Teknik Elektro Politeknik Bengkalis Jl.
BAB I PENDAHULUAN. 1.1 Latar Belakang
 BAB I PENDAHULUAN 1.1 Latar Belakang Analisis cluster merupakan teknik multivariat yang mempunyai tujuan utama untuk mengelompokkan objek-objek berdasarkan karakteristik yang dimilikinya. Analisis cluster
BAB I PENDAHULUAN 1.1 Latar Belakang Analisis cluster merupakan teknik multivariat yang mempunyai tujuan utama untuk mengelompokkan objek-objek berdasarkan karakteristik yang dimilikinya. Analisis cluster
PENERAPAN ALGORITMA K-MEANS PADA KUALITAS GIZI BAYI DI INDONESIA
 PENERAPAN ALGORITMA K-MEANS PADA KUALITAS GIZI BAYI DI INDONESIA Diajeng Tyas Purwa Hapsari Teknik Informatika STMIK AMIKOM Yogyakarta Jl Ring road Utara, Condongcatur, Sleman, Yogyakarta 55281 Email :
PENERAPAN ALGORITMA K-MEANS PADA KUALITAS GIZI BAYI DI INDONESIA Diajeng Tyas Purwa Hapsari Teknik Informatika STMIK AMIKOM Yogyakarta Jl Ring road Utara, Condongcatur, Sleman, Yogyakarta 55281 Email :
BAB II LANDASAN TEORI
 BAB II LANDASAN TEORI 2.1 DATA MINNING Data mining merupakan proses pengekstrakan informasi dari jumlah kumpulan data yang besar dengan menggunakan algoritma dan tehnik gambar dari statistik, mesin pembelajaran
BAB II LANDASAN TEORI 2.1 DATA MINNING Data mining merupakan proses pengekstrakan informasi dari jumlah kumpulan data yang besar dengan menggunakan algoritma dan tehnik gambar dari statistik, mesin pembelajaran
BAB 3 ANALISA SISTEM
 BAB 3 ANALISA SISTEM Pada perancangan suatu sistem diperlakukan analisa yang tepat, sehingga proses pembuatan sistem dapat berjalan dengan lancar dan sesuai seperti yang diinginkan. Setelah dilakukan analisis
BAB 3 ANALISA SISTEM Pada perancangan suatu sistem diperlakukan analisa yang tepat, sehingga proses pembuatan sistem dapat berjalan dengan lancar dan sesuai seperti yang diinginkan. Setelah dilakukan analisis
PENGELOMPOKAN TINGKAT KELULUSAN MAHASISWA MENGGUNAKAN ALGORITMA K-MEANS
 PENGELOMPOKAN TINGKAT KELULUSAN MAHASISWA MENGGUNAKAN ALGORITMA K-MEANS Yulius Palumpun 1), Sitti Nur Alam 2) 1) Program Studi Sistem Informasi Fakultas Ilmu Komputer dan Manajemen (FIKOM) - Universitas
PENGELOMPOKAN TINGKAT KELULUSAN MAHASISWA MENGGUNAKAN ALGORITMA K-MEANS Yulius Palumpun 1), Sitti Nur Alam 2) 1) Program Studi Sistem Informasi Fakultas Ilmu Komputer dan Manajemen (FIKOM) - Universitas
Data Mining Clustering Oleh : Suprayogi
 Data Mining Clustering Oleh : Suprayogi Pendahuluan Saat ini terjadi fenomena yaitu berupa data yang melimpah, setiap hari banyak orang yang berurusan dengan data yang bersumber dari berbagai jenis observasi
Data Mining Clustering Oleh : Suprayogi Pendahuluan Saat ini terjadi fenomena yaitu berupa data yang melimpah, setiap hari banyak orang yang berurusan dengan data yang bersumber dari berbagai jenis observasi
Makalah DATA MINING UNIVERSITAS MUHAMMADIYAH SIDOARJO TITIS FITRIA 6B PAGI 3/11/2014
 2014 Makalah DATA MINING UNIVERSITAS MUHAMMADIYAH SIDOARJO TITIS FITRIA 6B PAGI 3/11/2014 Bab 1. Data Mining 1.1 Pengertian Data Mining Data Mining adalah kegiatan yang meliputi pengumpulan dan penggunaan
2014 Makalah DATA MINING UNIVERSITAS MUHAMMADIYAH SIDOARJO TITIS FITRIA 6B PAGI 3/11/2014 Bab 1. Data Mining 1.1 Pengertian Data Mining Data Mining adalah kegiatan yang meliputi pengumpulan dan penggunaan
Pemilihan Distance Measure Pada K-Means Clustering Untuk Pengelompokkan Member Di Alvaro Fitness
 Pemilihan Distance Measure Pada K-Means Clustering Untuk Pengelompokkan Member Di Alvaro Fitness Mario Anggara 1, Herry Sujiani 2, Helfi Nasution 3 Program Studi Teknik Informatika Fakultas Teknik Universitas
Pemilihan Distance Measure Pada K-Means Clustering Untuk Pengelompokkan Member Di Alvaro Fitness Mario Anggara 1, Herry Sujiani 2, Helfi Nasution 3 Program Studi Teknik Informatika Fakultas Teknik Universitas
WEB MINING UNTUK PENCARIAN DOKUMEN BAHASA INGGRIS MENGGUNAKAN HILL CLIMBING AUTOMATIC CLUSTER
 WEB MINING UNTUK PENCARIAN DOKUMEN BAHASA INGGRIS MENGGUNAKAN HILL CLIMBING AUTOMATIC CLUSTER Hervilorra Eldira 1, Entin Martiana K 2., S.Kom M.Kom, Nur Rosyid M 2., S.Kom 1 Mahasiswa, 2 Dosen Pembimbing
WEB MINING UNTUK PENCARIAN DOKUMEN BAHASA INGGRIS MENGGUNAKAN HILL CLIMBING AUTOMATIC CLUSTER Hervilorra Eldira 1, Entin Martiana K 2., S.Kom M.Kom, Nur Rosyid M 2., S.Kom 1 Mahasiswa, 2 Dosen Pembimbing
BAB III DIVISIVE ANALISIS. Pada bab ini akan dipaparkan bagaimana konsep dari divisive analisis serta
 13 BAB III DIVISIVE ANALISIS Pada bab ini akan dipaparkan bagaimana konsep dari divisive analisis serta algoritma dari metode tersebut. 3.1 DEFINISI METODE DIVISIVE Teknik divisive klastering termasuk
13 BAB III DIVISIVE ANALISIS Pada bab ini akan dipaparkan bagaimana konsep dari divisive analisis serta algoritma dari metode tersebut. 3.1 DEFINISI METODE DIVISIVE Teknik divisive klastering termasuk
PERANCANGAN APLIKASI MENENTUKAN BERAT BADAN IDEAL DENGAN MENGGUNAKAN ALGORITMA K-MEANS CLUSTERING
 PERANCANGAN APLIKASI MENENTUKAN BERAT BADAN IDEAL DENGAN MENGGUNAKAN ALGORITMA K-MEANS CLUSTERING Johan Candra Juliner Hutabarat Mahasiswa Program Studi Teknik Informatika STMIK Budi Darma Medan Jl. Sisingamangaraja
PERANCANGAN APLIKASI MENENTUKAN BERAT BADAN IDEAL DENGAN MENGGUNAKAN ALGORITMA K-MEANS CLUSTERING Johan Candra Juliner Hutabarat Mahasiswa Program Studi Teknik Informatika STMIK Budi Darma Medan Jl. Sisingamangaraja
PENDAHULUAN. 1.1 Latar Belakang
 DAFTAR TABEL Tabel 3-1 Dokumen Term 1... 17 Tabel 3-2 Representasi... 18 Tabel 3-3 Centroid pada pengulangan ke-0... 19 Tabel 3-4 Hasil Perhitungan Jarak... 19 Tabel 3-5 Hasil Perhitungan Jarak dan Pengelompokkan
DAFTAR TABEL Tabel 3-1 Dokumen Term 1... 17 Tabel 3-2 Representasi... 18 Tabel 3-3 Centroid pada pengulangan ke-0... 19 Tabel 3-4 Hasil Perhitungan Jarak... 19 Tabel 3-5 Hasil Perhitungan Jarak dan Pengelompokkan
Pengelompokan Data dengan Metode...(Luh Joni Erawati Dewi)
") ISSN0216-3241 17 PENGELOMPOKAN DATA DENGAN METODE KLASTERISASI HIRARKI Oleh Luh Joni Erawati Dewi Jurusan Manajemen Informatika, FTK, Undiksha Abstrak Pengelompokan data sangat diperlukan untuk mengetahui
ISSN0216-3241 17 PENGELOMPOKAN DATA DENGAN METODE KLASTERISASI HIRARKI Oleh Luh Joni Erawati Dewi Jurusan Manajemen Informatika, FTK, Undiksha Abstrak Pengelompokan data sangat diperlukan untuk mengetahui
PENDAHULUAN TINJAUAN PUSTAKA
 Latar Belakang PENDHULUN Listrik merupakan sumber daya yang sangat dibutuhkan saat ini. Penggunaan listrik setiap tahun, bahkan setiap bulan terus meningkat. Hal ini dibuktikan dengan selalu bertambahnya
Latar Belakang PENDHULUN Listrik merupakan sumber daya yang sangat dibutuhkan saat ini. Penggunaan listrik setiap tahun, bahkan setiap bulan terus meningkat. Hal ini dibuktikan dengan selalu bertambahnya
APLIKASI K-MEANS UNTUK PENGELOMPOKAN RUMAH TANGGA DI SALATIGA BERDASARKAN DATA SUSENAS
 APLIKASI KMEANS UNTUK PENGELOMPOKAN RUMAH TANGGA DI SALATIGA BERDASARKAN DATA SUSENAS Tinus Septioko, Hanna Arini Parhusip, Tundjung Mahatma Mahasiswa Program Studi Matematika FSM UKSW, Dosen Program Studi
APLIKASI KMEANS UNTUK PENGELOMPOKAN RUMAH TANGGA DI SALATIGA BERDASARKAN DATA SUSENAS Tinus Septioko, Hanna Arini Parhusip, Tundjung Mahatma Mahasiswa Program Studi Matematika FSM UKSW, Dosen Program Studi
PENGGUNAAN CLUSTER-BASED SAMPLING UNTUK PENGGALIAN KAIDAH ASOSIASI MULTI OBYEKTIF
 Vol. 5, No. 1, Januari 2009 ISSN 0216-0544 PENGGUNAAN CLUSTER-BASED SAMPLING UNTUK PENGGALIAN KAIDAH ASOSIASI MULTI OBYEKTIF * Febriana Santi Wahyuni, Daniel O Siahaan dan Chastine Fatichah Jurusan Teknik
Vol. 5, No. 1, Januari 2009 ISSN 0216-0544 PENGGUNAAN CLUSTER-BASED SAMPLING UNTUK PENGGALIAN KAIDAH ASOSIASI MULTI OBYEKTIF * Febriana Santi Wahyuni, Daniel O Siahaan dan Chastine Fatichah Jurusan Teknik
DAFTAR ISI... HALAMAN JUDUL... HALAMAN PENGESAHAN... HALAMAN PERNYATAAN... HALAMAN PERSEMBAHAN... PRAKATA... DAFTAR LAMBANG... DAFTAR GAMBAR...
 DAFTAR ISI Halaman HALAMAN JUDUL... HALAMAN PENGESAHAN... HALAMAN PERNYATAAN... HALAMAN PERSEMBAHAN... PRAKATA... DAFTAR ISI... DAFTAR LAMBANG... DAFTAR GAMBAR... DAFTAR TABEL... INTISARI... ABSTRACT...
DAFTAR ISI Halaman HALAMAN JUDUL... HALAMAN PENGESAHAN... HALAMAN PERNYATAAN... HALAMAN PERSEMBAHAN... PRAKATA... DAFTAR ISI... DAFTAR LAMBANG... DAFTAR GAMBAR... DAFTAR TABEL... INTISARI... ABSTRACT...
BAB II TINJAUAN PUSTAKA DAN LANDASAN TEORI. menerapkan metode clustering dengan algoritma K-Means untuk penelitiannya.
 BAB II TINJAUAN PUSTAKA DAN LANDASAN TEORI 2.1 Tinjauan Pustaka Salah satu cara untuk mengetahui faktor nilai cumlaude mahasiswa Fakultas Teknik Universitas Muhammadiyah Yogyakarta adalah dengan menerapkan
BAB II TINJAUAN PUSTAKA DAN LANDASAN TEORI 2.1 Tinjauan Pustaka Salah satu cara untuk mengetahui faktor nilai cumlaude mahasiswa Fakultas Teknik Universitas Muhammadiyah Yogyakarta adalah dengan menerapkan
PENINGKATAN KINERJA ALGORITMA K-MEANS DENGAN FUNGSI KERNEL POLYNOMIAL UNTUK KLASTERISASI OBJEK DATA
 PENINGKATAN KINERJA ALGORITMA K-MEANS DENGAN FUNGSI KERNEL POLYNOMIAL UNTUK KLASTERISASI OBJEK DATA Heri Awalul Ilhamsah Jurusan Teknik Industri Universitas Trunojoyo Madura Kampus Universitas Trunojoyo
PENINGKATAN KINERJA ALGORITMA K-MEANS DENGAN FUNGSI KERNEL POLYNOMIAL UNTUK KLASTERISASI OBJEK DATA Heri Awalul Ilhamsah Jurusan Teknik Industri Universitas Trunojoyo Madura Kampus Universitas Trunojoyo
BAB 2 TINJAUAN PUSTAKA
 BAB 2 TINJAUAN PUSTAKA 2.1. Data Mining Data Mining adalah proses pencarian pengetahuan dari suatu data berukuran besar melalui metode statistik, machine learning, dan artificial algorithm. Hal yang paling
BAB 2 TINJAUAN PUSTAKA 2.1. Data Mining Data Mining adalah proses pencarian pengetahuan dari suatu data berukuran besar melalui metode statistik, machine learning, dan artificial algorithm. Hal yang paling
Pendekatan Algoritma Divide and Conquer pada Hierarchical Clustering
 Pendekatan Algoritma Divide and Conquer pada Hierarchical Clustering Agnes Theresia Damanik / 13510100 1 Program Studi Teknik Informatika Sekolah Teknik Elektro dan Informatika Institut Teknologi Bandung,
Pendekatan Algoritma Divide and Conquer pada Hierarchical Clustering Agnes Theresia Damanik / 13510100 1 Program Studi Teknik Informatika Sekolah Teknik Elektro dan Informatika Institut Teknologi Bandung,
PENERAPAN ALGORITMA K-MEANS UNTUK MENETAPKAN KELOMPOK MUTU KARET
 PENERAPAN ALGORITMA K-MEANS UNTUK MENETAPKAN KELOMPOK MUTU KARET Handi Kurniawan Sohdianata 1, Sushermanto 2 Jurusan Teknik Informatika STMIK Banjarbaru 1, Jurusan Sistem Informasi STMIK Banjarbaru 2 Jl.
PENERAPAN ALGORITMA K-MEANS UNTUK MENETAPKAN KELOMPOK MUTU KARET Handi Kurniawan Sohdianata 1, Sushermanto 2 Jurusan Teknik Informatika STMIK Banjarbaru 1, Jurusan Sistem Informasi STMIK Banjarbaru 2 Jl.
Bab 2 Tinjauan Pustaka
 Bab 2 Tinjauan Pustaka 2.1 Penelitian Terdahulu Adapun penelitian terdahulu yang berkaitan dalam penelitian ini berjudul Penentuan Wilayah Usaha Pertambangan Menggunakan Metode Fuzzy K-Mean Clustering
Bab 2 Tinjauan Pustaka 2.1 Penelitian Terdahulu Adapun penelitian terdahulu yang berkaitan dalam penelitian ini berjudul Penentuan Wilayah Usaha Pertambangan Menggunakan Metode Fuzzy K-Mean Clustering
TEMU KEMBALI INFORMASI BERDASARKAN LOKASI PADA DOKUMEN YANG DIKELOMPOKKAN MENGGUNAKAN METODE CENTROID LINKAGE HIERARCHICAL
 TEMU KEMBALI INFORMASI BERDASARKAN LOKASI PADA DOKUMEN YANG DIKELOMPOKKAN MENGGUNAKAN METODE CENTROID LINKAGE HIERARCHICAL Nadia Damayanti 1, Nur Rosyid Mubtada i, S.Kom, M.Kom 2, Afrida Helen S.T, M.Kom
TEMU KEMBALI INFORMASI BERDASARKAN LOKASI PADA DOKUMEN YANG DIKELOMPOKKAN MENGGUNAKAN METODE CENTROID LINKAGE HIERARCHICAL Nadia Damayanti 1, Nur Rosyid Mubtada i, S.Kom, M.Kom 2, Afrida Helen S.T, M.Kom
Gambar 3.1 Contoh Citra yang digunakan
 BAB III DATASET DAN RANCANGAN PENELITIAN Pada bab ini dijelaskan tentang dataset citra yang digunakan dalam penelitian ini serta rancangan untuk melakukan penelitian. 3.1 DATASET PENELITIAN Penelitian
BAB III DATASET DAN RANCANGAN PENELITIAN Pada bab ini dijelaskan tentang dataset citra yang digunakan dalam penelitian ini serta rancangan untuk melakukan penelitian. 3.1 DATASET PENELITIAN Penelitian
BAB 6 ANALISIS CLUSTER
 BAB 6 ANALISIS CLUSTER Pendahuluan Analisis cluster membagi data ke dalam grup (cluster) yang bermakna, berguna, atau keduanya. Jika tujuannya mencari grup yang memiliki makna, maka cluster seharusnya
BAB 6 ANALISIS CLUSTER Pendahuluan Analisis cluster membagi data ke dalam grup (cluster) yang bermakna, berguna, atau keduanya. Jika tujuannya mencari grup yang memiliki makna, maka cluster seharusnya
TEKNOSI, Vol. 02, No. 03, Desember Koko Handoko Universitas Putera Batam (cooresponding author)
") TEKNOSI, Vol. 02, No. 03, Desember 2016 31 PENERAPAN DATA MINING DALAM MENINGKATKAN MUTU PEMBELAJARAN PADA INSTANSI PERGURUAN TINGGI MENGGUNAKAN METODE K-MEANS CLUSTERING (STUDI KASUS DI PROGRAM STUDI
TEKNOSI, Vol. 02, No. 03, Desember 2016 31 PENERAPAN DATA MINING DALAM MENINGKATKAN MUTU PEMBELAJARAN PADA INSTANSI PERGURUAN TINGGI MENGGUNAKAN METODE K-MEANS CLUSTERING (STUDI KASUS DI PROGRAM STUDI
Kata kunci: Cluster, Knowledge Discovery in Database, Algoritma K-Means,
 K- Pembentukan cluster dalam Knowledge Discovery in Database dengan Algoritma K-Means Oleh: Sri Andayani Jurusan Pendidikan Matematika FMIPA UNY,email: andayani@uny.ac.id Abstrak Pembentukan cluster merupakan
K- Pembentukan cluster dalam Knowledge Discovery in Database dengan Algoritma K-Means Oleh: Sri Andayani Jurusan Pendidikan Matematika FMIPA UNY,email: andayani@uny.ac.id Abstrak Pembentukan cluster merupakan
KLASTERISASI KOMPETENSI GURU MENGGUNAKAN HASIL PENILAIAN PORTOFOLIO SERTIFIKASI GURU DENGAN METODE DATA MINING
 KLASTERISASI KOMPETENSI GURU MENGGUNAKAN HASIL PENILAIAN PORTOFOLIO SERTIFIKASI GURU DENGAN METODE DATA MINING Ari Kurniawan, Mochamad Hariadi S2 Teknik Elektro (Telematika), Institut Teknologi Sepuluh
KLASTERISASI KOMPETENSI GURU MENGGUNAKAN HASIL PENILAIAN PORTOFOLIO SERTIFIKASI GURU DENGAN METODE DATA MINING Ari Kurniawan, Mochamad Hariadi S2 Teknik Elektro (Telematika), Institut Teknologi Sepuluh
ANALISIS CLUSTER DENGAN METODE K-MEANS (TEORI DAN CONTOH STUDY KASUS)
") ANALISIS MULTIVARIAT ANALISIS CLUSTER DENGAN METODE K-MEANS (TEORI DAN CONTOH STUDY KASUS) Oleh : Rizka Fauzia 1311 100 126 Dosen Pengampu: Santi Wulan Purnami S.Si., M.Si. PROGRAM STUDI SARJANA JURUSAN
ANALISIS MULTIVARIAT ANALISIS CLUSTER DENGAN METODE K-MEANS (TEORI DAN CONTOH STUDY KASUS) Oleh : Rizka Fauzia 1311 100 126 Dosen Pengampu: Santi Wulan Purnami S.Si., M.Si. PROGRAM STUDI SARJANA JURUSAN