PRAKTIKUM 3 ANALISA CLUSTER
|
|
|
- Doddy Widjaja
- 7 tahun lalu
- Tontonan:
Transkripsi
1 PRAKTIKUM 3 ANALISA CLUSTER Definisi Cluster Analisis cluster merupakan suatu teknik data mining yang digunakan untuk mengklasifikasikan obyek atau kasus (responden) ke dalam kelompok yang relatif homogen yang dinamakan cluster. Pola-pola dalam suatu Cluster akan memiliki kesamaan ciri/sifat daripada pola-pola dalam Cluster yang lainnya. Metodologi Clustering lebih cocok digunakan untuk eksplorasi hubungan antar data untuk membuat suatu penilaian terhadap strukturnya. Tujuan Praktikum Cluster 1. Mahasiswa mempunyai pengetahuan dan kemampuan dasar dalam melakukan dan menerapkan analisis Cluster 2. Mahasiswa dapat mengetahui dan memahami arti dan garis besar dari analisis Cluster dalam data mining, mulai dari pengambilan data, pengolahan data sampai dengan tahap pengelompokan, serta mengaplikasikannya dalam kasus yang dihadapi. Knowledge Discovery in Database (KDD) dan Data Mining Data mining merupakan proses semi otomatik yang menggunakan teknik statistik, matematika, kecerdasan buatan, dan machine learning untuk mengekstraksi dan mengidentifikasi informasi pengetahuan potensial dan berguna yang bermanfaat yang tersimpan di dalam database besar. (Turban et al, 2005 ). Knowledge discovery in database (KDD) adalah keseluruhan proses nontrivial untuk mencari dan mengidentifikasi pola (pattern) dalam data, dimana pola yang ditemukan bersifat sah, baru, dapat bermanfaat dan dapat dimengerti.istilah data mining dan Knowledge Discovery in Database (KDD) sering kali digunakan secara bergantian untuk
2 menjelaskan proses penggalian informasi tersembunyi dalam suatu basis data yang besar. Sebenarnya kedua istilah tersebut memiliki konsep yang berbeda, tetapi berkaitan satu sama lain. Dan salah satu tahapan dalam keseluruhan proses KDD adalah data mining. Proses KDD secara garis besar dapat dijelaskan sebagai berikut (Fayyad, 1996). 1. Data Selection Pemilihan (seleksi) data dari sekumpulan data operasional perlu dilakukan sebelum tahap penggalian informasi dalam KDD dimulai. Data hasil seleksi yang akan digunakan untuk proses data mining, disimpan dalam suatu berkas, terpisah dari basis data operasional. 2. Pre-processing/Cleaning Sebelum proses data mining dapat dilaksanakan, perlu dilakukan proses cleaning pada data yang menjadi fokus KDD. Proses cleaning mencakup antara lain membuang duplikasi data, memeriksa data yang inkonsisten, dan memperbaiki kesalahan pada data, seperti kesalahan cetak (tipografi). Juga dilakukan proses enrichment, yaitu proses memperkaya data yang sudah ada dengan data atau informasi lain yang relevan dan diperlukan untuk KDD, seperti data atau informasi eksternal. 3. Transformation Coding adalah proses transformasi pada data yang telah dipilih, sehingga data tersebut sesuai untuk proses data mining. Proses coding dalam KDD merupakan proses kreatif dan sangat tergantung pada jenis atau pola informasi yang akan dicari dalam basis data. 4. Data Mining
3 Data mining adalah proses mencari pola atau informasi menarik dalam data terpilih dengan menggunakan teknik atau metode tertentu. Teknik, metode, atau algoritma dalam data mining sangat bervariasi. Pemilihan metode dan algoritma yang tepat sangat bergantung pada tujuan dan proses KDD secara keseluruhan. Dalam modul ini kita menggunakan salah satu teknik data mining yaitu cluster. 5. Interpretation/Evaluation Pola informasi yang dihasilkan dari proses data mining perlu ditampilkan dalam bentuk yang mudah dimengerti oleh pihak yang berkepentingan. Tahap ini merupakan bagian dari proses KDD yang disebut interpretation. Tahap ini mencakup pemeriksaan apakah pola atau informasi yang ditemukan bertentangan dengan fakta atau hipotesis yang ada sebelumnya. Konsep Cluster Analisis Cluster merupakan salah satu teknik multivariat yang digunakan dalam data mining yang bertujuan untuk mengidentifikasi sekelompok obyek yang mempunyai kemiripan karakteristik tertentu yang dapat dipisahkan dengan kelompok obyek lainnya, sehingga obyek yang berada dalam kelompok yang sama relatif lebih homogen (sama) daripada obyek yang berada pada kelompok yang berbeda. Di dalam pengclusteran setiap obyek hanya boleh masuk ke dalam satu cluster saja sehingga tidak terjadi tumpang tindih (overlapping atau interaction). Ada beberapa tahapan dalam malekukan Analisis Cluster, diantaranya yaitu: 1. Tujuan Analisis Cluster 2. Desain Penelitian dalam Analisis Cluster 3. Asumsi-asumsi dalam Analisis Cluster 4. Proses Mendapatkan Cluster dan Menilai kelayakan secara keseluruhan (overall fit) 5. Interpretasi terhadap Cluster.
4 6. Proses Validasi dan Pembuatan Profil (profiling) Cluster Penerapan analisis Cluster di dalam pemasaran adalah sebagai berikut : 1. Identifikasi obyek (Recognition) : Dalam bidang image Processing, Computer Vision atau robot vision 2. Decission Support System dan data mining Membuat segmen pasar (segmenting the market). Memahami perilaku pembeli. Mengenali peluang produk baru Tahap-tahap dalam Analisis Cluster Ada beberapa tahapan dalam malekukan Analisis Cluster, diantaranya yaitu: Tahap Pertama : Tujuan Analisis Cluster Tujuan utama analisis Cluster adalah memisahkan suatu himpunan objek menjadi dua kelompok atau lebih berdasarkan kesamaan karakteristik khusus yang dimilikinya. Sedangkan tujuan analisis Cluster secara khusus, antara lain: Penyederhanaan Data Penyederhanaan data merupakan bagian dari suatu taksonomi. Dengan struktur yang terbatas observasi/objek dapat dikelompokkan untuk analisis selanjutnya. Identifikasi Hubungan (Relationship Identification) Hubungan antar objek diidentifikasi secara empiris. Struktur analisis Cluster yang sederhana dapat menggambarkan adanya hubungan atau kesamaan dan perbedaan yang tidak dinyatakan sebelumnya. Pemilihan pada Pengelompokan Variabel
5 Tujuan analisis Cluster tidak dapat dipisahkan dengan pemilihan variabel yang digunakan untuk menggolongkan objek ke dalam clucter-cluster. Cluster yang terbentuk merefleksikan struktur yang melekat pada data seperti yang didefinisikan oleh variabel-variabel. Pemilihan variabel harus sesuai dengan teori dan konsep yang umum digunakan dan harus rasional. Rasionalitas ini didasarkan pada teori-teori eksplisit atau penelitian sebelumnya. Variabelvariabel yang dipilih hanyalah variabel yang dapat mencirikan objek yang akan dikelompokkan dan secara spesifik harus sesuai dengan tujuan analisis Cluster. Tahap Kedua : Desain Penelitian dalam Analisis Cluster 2 hal penting dalam tahap ini adalah pendeteksian outlier dan mengukur kesamaan. Pendeteksian Outliers Outlier adalah suatu objek yang sangat berbeda dengan objek lainnya. Outliers dapat terjadi karena: a. Observasi menyimpang yang tidak mewakili populasi b. Suatu undersampling kelompok-kelompok dalam populasi yang menyebabkan underrepresentation kelompok-kelompok dalam sampel Dalam kedua kasus tersebut, outliers dapat mengubah struktur sebenarnya dalam populasi sehingga kita akan memperoleh Cluster-Cluster yang tidak sesuai dengan struktur sebenarnya dari populasi tersebut dan tidak representatif. Mengukur Kesamaan antar Objek Konsep kesamaan adalah hal yang sangat penting dalam analisis Cluster. Kesamaan antar objek merupakan ukuran kedekatan antar objek. Kesamaan dapat diketahui dengan melakukan pengukuran jarak antar setiap individu. Ukuran jarak merupakan ukuran ketidakmiripan, dimana jarak yang besar menunjukkan sedikit kesamaan sebaliknya jarak yang pendek/kecil menunjukkan bahwa suatu objek makin mirip dengan objek lain.
6 Gambar 1. Ilustrasi Pengukuran jarak Metode untuk mengukur kesamaan obyek antara lain : 1). Euclidean Distance Jarak euclidean antara dua titik i dan j merupakan sisi miring (sisi terpanjang) dari segitiga ABC. ( ) ( ) ( ) ( ) 2). Squared Euclidean Distance Merupakan pengukuran kuadrat jarak euclidean antara dua titik i dan j. ( ) ( ) ( ) ( ) 3). Chebychev D(X,Y) 4). City Block Distance D(X,Y) D(I,j) Tahap Ketiga : Asumsi-asumsi dalam Analisis Cluster Seperti hal teknik analisis lain,analisis Cluster juga menetapkan adanya suatu asumsi. Ada dua asumsi dalam analisis Cluster, yaitu : a. Kecukupan Sampel untuk merepresentasikan/mewakili Populasi
7 Biasanya suatu penelitian dilakukan terhadap populasi diwakili oleh sekelompok sampel. Sampel yang digunakan dalam analisis ckuster harus dapat mewakili populasi yang ingin dijelaskan, karena analisis ini baik jika sampel representatif. Jumlah sampel yang diambil tergantung penelitinya, seorang peneliti harus yakin bahwa sampel yang diambil representatif terhadap populasi. b. Pengaruh Multikolinieritas Ada atau tidaknya multikolinieritas antar variabel sangat diperhatikan dalam analisis Cluster karena hal itu berpengaruh, sehingga variabel-variabel yang bersifat multikolinieritas secara eksplisit dieprtimbangkan dengan lebih seksama. Tahap Keempat : Proses Mendapatkan Cluster dan Menilai kelayakan secara keseluruhan (overall fit) Ada dua proses penting yaitu algoritma Cluster dalam pembentukan Clusterdan menentukan jumlah Cluster yang akan dibentuk. Keduanya mempunyai implikasi substansial tidak hanya pada hasil yang diperoleh tetapi juga pada interpretasi yang akan dilakukan terhadap hasil tersebut.
8 Gambar 2. Algoritma Analisa Kluster Adapun metode pengelompokan dalam analisis Cluster meliputi : 1. Metode Non-Hirarkis. dimulai dengan menentukan terlebih dahulu jumlah Cluster yang diinginkan (dua,tiga, atau yang lain). Setelah jumlah Clusterditentukan, maka proses Cluster dilakukan dengan tanpa mengikuti proses hirarki. Metode ini biasa disebut K-Means Cluster. Berbeda dengan metode hirarkikal, prosedur non hirarkikal (K-means Clustering) dimulai dengan memilih sejumlah nilai Cluster awal sesuai dengan jumlah yang diinginkan dan kemudian obyek digabungkan ke dalam Cluster-Cluster tersebut. a. Sequential Threshold Procedure
9 Metode ini melakukan pengelompokan dengan terlebih dahulu memilih satu obyek dasar yang akan dijadikan nilai awal Cluster, kemudian semua obyek yang ada didalam jarak terdekat dengan Cluster ini akan bergabung lalu dipilih Cluster kedua dan semua obyek yang mempunyai kemiripan dimasukkan dalam Cluster ini. Demikian seterusnya hingga terbentuk beberapa Cluster dengan keseluruhan obyek didalamnya. b. Parallel Threshold Prosedure Secara prinsip sama dengan prosedur sequential threshold, hanya saja dilakukan pemilihan terhadap beberapa obyek awal Cluster sekaligus dan kemudian melakukan penggabungan obyek ke dalamnya secara bersamaan. c. Optimizing Merupakan pengembangan dari kedua metode diatas dengan melakukan optimasi pada penempatan obyek yang ditukar untuk Cluster lainnya dengan pertimbangan krteria optimasi. 2. Metode Hirarkis. Memulai pengelompokan dengan dua atau lebih obyek yang mempunyai kesamaan paling dekat. Kemudian dilanjutkan pada obyek yang lain dan seterusnya hingga Cluster akan membentuk semacam pohon dimana terdapat tingkatan (hirarki) yangjelas antar obyek, dari yang paling mirip hingga yang paling tidak mirip. Teknik hirarki (hierarchical methods) adalah teknik Clustering membentuk kontruksi hirarki atau berdasarkan tingkatan tertentu seperti struktur pohon (struktur pertandingan). Alat yang membantu untukmemperjelas proses hirarki ini disebut dendogram.
10 Teknik hirarki (hierarchical methods) adalah teknik Clustering membentuk kontruksi hirarki atau berdasarkan tingkatan tertentu seperti struktur pohon (struktur pertandingan). Dengan demikian proses pengelompokkannya dilakukan secara bertingkat atau bertahap. Hasil dari pengelompokan ini dapat disajikan dalam bentuk dendogram. Metode-metode yang digunakan dalam teknik hirarki: a. Agglomerative Methods Metode ini dimulai dengan kenyatan bahwa setiap obyek membentuk Clusternya masing-masing. Kemudian dua obyek dengan jarak terdekat bergabung. Selanjutnya obyek ketiga akan bergabung dengan Cluster yang ada atau bersama obyek lain dan membentuk Cluster baru. Hal ini tetap memperhitungkan jarak kedekatan antar obyek. Proses akan berlanjut hingga akhirnya terbentuk satu Cluster yang terdiri dari keseluruhan obyek. Ada beberapa teknik dalam Agglomerative methods yaitu: Single linkage (nearest neighbor methods) Metode ini menggunakan prinsip jarak minimum yang diawali dengan mencari dua obyek terdekat dan keduanya membentuk Cluster yang pertama. Pada langkah selanjutnya terdapat dua kemungkinan, yaitu : a. Obyek ketiga akan bergabung dengan Cluster yang telah terbentuk, atau b. Dua obyek lainnya akan membentu Cluster baru. Proses ini akan berlanjut sampai akhirnya terbentuk Cluster tunggal. Pada metode ini jarak antar Cluster didefinisikan sebagai jarak terdekat antar anggotanya. Contoh : Terdapat matriks jarak antara 5 buah obyek, yaitu :
D = min {dad, dbd}= dad = 6.0 D(AB)E = min {dae, dbe}= dbe = 7.0 Dengan demikian terbentuk matriks jarak yang baru Gambar 4. Matriks 5 Buah Objek Dengan Jarak Baru b).")
11 Gambar 3. Matriks Antara 5 Buah Objek. Langkah penyelesaiannya : a). Mencari obyek dengan jarak minimum Menghitung jarak antara Cluster AB dengan obyek lainnya. D(AB)C = min {dac, dbc}= dbc = 3.0 D(AB)D = min {dad, dbd}= dad = 6.0 D(AB)E = min {dae, dbe}= dbe = 7.0 Dengan demikian terbentuk matriks jarak yang baru Gambar 4. Matriks 5 Buah Objek Dengan Jarak Baru b). Mencari obyek dengan jarak terdekat. D dan E mempunyai jarak terdekat, yaitu 2,0 maka obyek D dan E bergabung menjadi satu Cluster. c). Menghitung jarak antara Cluster dengan obyek lainnya. D(AB)C = 3.0

12 D(AB)(DE) = min {dad, dae, dbd, dbe} = dad = 6.0 D(DE)C = min {dcd, dce} = dcd = 4.0 d). Mencari jarak terdekat antara Cluster dengan obyek dan diperoleh obyek C bergabung dengan Cluster AB e). Pada langkah yang terakhir, Cluster ABC bergabung dengan DE sehingga terbentuk Cluster tunggal. Complete linkage (furthest neighbor methods) Metode ini merupakan kebalikan dari pendekatan yang digunakan pada single linkage. Prinsip jarak yang digunakan adalah jarak terjauh antar obyek. Contoh : Terdapat matriks jarak antara lima buah obyek yaitu : Gambar 5. Matriks Antara 5 Buah Objek. Langkah penyelesaiannya : a) Mencari obyek dengan jarak minimum A dan B mempunyai jarak terdekat yaitu 1.0 maka obyek A dan B bergabung menjadi satu Cluster. b) Menghitung jarak antara Cluster AB dengan obyek lainnya d(ab)c = max {dac, dbc} = dac = 5,0 d(ab)d = max {dad, dbd} = dbd = 8,0 d(ab)e = max {dae, dbe} = dae = 8,0 Dengan demikian terbentuk matriks jarak yang baru :
 Menghitung jarak antara Cluster dengan obyek lainnya.")
13 Gambar 4. Matriks 5 Buah Objek Dengan Jarak Baru c) Mencari obyek dengan jarak terdekat. D dan E mempunyai jarak terdekat yaitu 2.0 maka obyek D dan E bergabung menjadi satu Cluster d) Menghitung jarak antara Cluster dengan obyek lainnya. d(ab)c = 4,0 d(ab)(de) = 1/2{dAD, dae, dbd, dbe} = 7,25 d(de)c = 1/2{dCD, dce,} = dce = 5,00 Maka terbentuklah matrik jarak yang baru, yaitu : Gambar 5. Matriks Akhir e) Mencari jarak terdekat antara Cluster dengan obyek dan diperoleh obyek C bergabung dengan Cluster AB. f) Pada langkah yang terakhir, Cluster ABC bergabung dengan DE sehingga terbentuk Cluster tunggal
14 Ward s error sum of squares methods Ward mengajukan suatu metode pembentukan Cluster yang didasari oleh hilangnya informasi akibat penggabungan obyek menjadi Cluster. Hal ini diukur dengan jumlah total dari deviasi kuadrat pada mean Cluster untuk tiap observasi. Error sum of squares (ESS) digunakan sebagai fungsi obyektif. Dua obyek akan digabungkan apabila mempunyai fungsi obyektif terkecil diantara kemungkinan yang ada. ESS ( ) Dengan Xij adalah nilai untuk obyek ke-i pada Cluster ke-j. b. Divisive Methods Metode divisive berlawanan dengan metode agglomerative. Metode ini pertama-tama diawali dengan satu Cluster besar yang mencakup semua observasi (obyek). Selanjutnya obyek yang mempunyai ketidakmiripan yang cukup besar akan dipisahkan sehingga membentuk Cluster yang lebih kecil. Pemisahan ini dilanjutkan sehingga mencapai sejumlah Cluster yang diinginkan. Splinter average distance methods Metode ini didasarkan pada perhitungan jarak rata-rata masing-masing obyek dengan obyek pada grup splinter dan jarak rata-rata obyek tersebut dengan obyek lain pada grupnya. Proses tersebut dimulai dengan memisahkan obyek dengan jarak terjauh sehingga terbentuklan dua group. Kemudian dibandingkan dengan jarak rata-rata masing-masing obyek dengan group splinter dengan groupnya sendiri. Apabila suatu obyek mempunyai jarak yang lebih dekat ke group splinter daripada ke groupnya sendiri, maka obyek tersebut haruslah dikeluarkan dari groupnya dan dipisahkan ke group splinter. Apabila komposisinya sudah stabil, yaitu jarak suatu obyek ke

15 groupnya selalu lebih kecil daripada jarak obyek itu ke group splinter, maka proses berhenti dan dilanjutkan dengan tahap pemisahan dalam group. Contoh : Terdapat matriks jarak antara 5 buah obyek, yaitu : Gambar 6. Matriks Perbandingan 5 buah Objek Perhitungan : a) Menghitung jarak rata-rata antar obyek A = ¼ ( ) = 21 D = ¼ ( ) = B = ¼ ( ) = E = ¼ ( ) = C = ¼ ( ) = Terlihat bahwa E mempunyai nilai jarak terjauh, yaitu 22.75, maka E dipisahkan dari group utama dan membentuk group splinter. b) Menghitung jarak rata-rata obyek dengan group utama dengan group splinter Gambar 7. Perhitungan Rata-Rata Group Utama Dengan Group Splinter
 Perhitungan jarak rata-rata Gambar 7.")
16 Pada D, jarak rata-rata dengan group splinter lebih dekat daripada dengan group utama. Dengan demikian D harus dikeluarkan dari group utama dan masuk ke group splinter. c) Perhitungan jarak rata-rata Gambar 7. Perhitungan Rata-Rata Group Utama Dengan Group Splinter Karena jarak semua obyek ke group utama sudah lebih besar daripada jaraknya ke group splinter, maka komposisinya sudah stabil. Tahap Kelima : Interpretasi terhadap Cluster Tahap interpretasi meliputi pengujian tiap Cluster dalam term untuk menamai dan menandai dengan suatu label yang secara akurat dapat menjelaskan kealamian Cluster. Membuat profil dan interpretasi Cluster tidak hanya untuk memperoleh suatu gambaran saja melainkan pertama, menyediakan suatu rata-rata untuk menilai korespondensi pada Cluster yang terbentuk, kedua, profil Cluster memberikan araha bagi penilainan terhadap signifikansi praktis. Namun demikian yang perlu diperhatikan pada tahapan interpretasi adalah karakteristik yang membedakan masing-masing Cluster sehingga kita dapat memberikan label pada masing-masing Cluster tersebut. Tahap Keenam: Proses Validasi dan Pembuatan Profil (profiling) Cluster 1. Proses validasi solusi Cluster Proses validasi bertujuan menjamin bahwa solusi yang dihasilkan dari analisis Cluster dapat mewakili populasi dan dapat digeneralisasi untuk objek lain. Pendekatan ini
17 membandingkan solusi Cluster dan menilai korespondensi hasil. Terkadang tidak dapat dipraktekkan karena adanya kendala waktu dan biaya atau ketidaktersediaan objek untuk analisis Cluster ganda. 2. Pembuatan Profil ( profiling) solusi Cluster Tahap ini menggambarkan karakteristik tiap Cluster untuk menjelaskan Cluster-Cluster tersebut dapat dapat berbeda pada dimensi yang relevan. Titik beratnta pada karakteristik yang secara signifikan berbeda antar clustre dan memprediksi anggota dalam suatu Cluster khusus.
18 Studi Kasus Metode Hierarki Fizi Shop merupakan toko yang bergerak dibidang retail. Pihak perusahaan ingin meningkatkan pelayanan terhadap konsumen yang berkunjung melalui web mereka. Dengan menyebarkan kuesioner, dan menggunakan Clustering, pihak perusahaan ingin mengetahui selera konsumen dan faktor faktor yang paling berpengaruh terhadap kemajuan bisnisnya. Berikut adalah hasil kuesioner yang telah dibagikan kepada 20 konsumen yang telah berkunjung ke toko. Data Kuesioner 2 : No Nama Perilaku Karyawan Komunikasi Pelayanan Kelengkapan Harga 1 Rino Abdul Viant Aan Romi Ririn Rahmawati Okta Andre Niko Ayuk Wanti Mey Farah Maryana Sifa Wulan Ulfa Syahdan Awan
19 Data Kuesioner 1 : No Nama Jenis Kelamin Usia Profesi Intensitas Barang Biaya 1 Rino Abdul Viant Aan Romi Ririn Rahmawati Okta Andre Niko Ayuk Wanti Mey Farah Maryana Sifa Wulan Ulfa Syahdan Awan

20 Lakukan prosedur pengclusteran dengan menggunakan metode hirarki dan non-hirarki! Tentukan berapa jumlah Cluster yang terbentuk, dan analisislah hasil profilisasi customernya! Langkah Penyelesaian : 1. Input Data - Variable View Di setiap variabel, atur values sesuai skala yang ada di kuesioner seperti gambar di bawah ini:

21 - Data View 2. Clustering Metode Hirarki a. Pilih analyze klik Classify lalu pilih Hierarchical Cluster

22 b. Variabel : Letakkan semua Variabel X Label case by : Letakkan nama responden Cluster : Case Display : statistic, plot c. Statistik : agglomeration schedule

23 d. Plots : klik Dendogram Icicle : none e. Method : Cluster Method Pilih nearest neighbor measure Interval pilih Squared Euqliden Distance

24 f. Klik save Cluster membership : none 3. Profilisasi Costumer a. Input Data - Variable View:
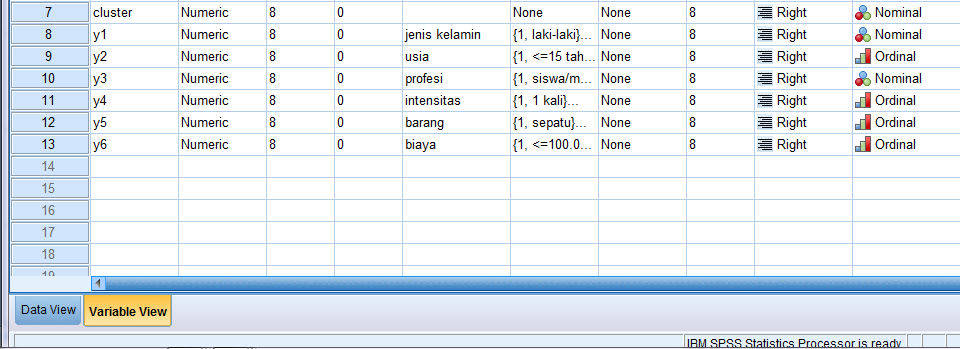
25

26 - Data View b. Pilih Analyze, klik Descriptive Statistic pilih crosstab

27 c. Rows : Letakkan semua variabel Y Columns : Cluster member d. Statistics : Correlation

28 e. Cells Counts : observed, Percentage : total f. Format Row order : ascending. 4. Penentuan Variabel yang harus ditingkatkan a. Input Data o Variable View:

29 o Data View:
 Columns :")
30 b. Pilih Analyze, klik Descriptive Statistic pilih crosstab c. Rows : Letakkan semua variabel profil ( variable x ) Columns : Cluster member

31 d. Statistics : Correlation e. Cells Counts : observed, Percentage : total

32 f. Format Row order : ascending.
33 DAFTAR PUSTAKA Bertalya Konsep Data Mining. Universitas Gunadarma. Fayyad, Usama Advances in Knowledge Discovery and Data Mining. MIT Press. Susanto, Hery Tri Cluster Analysis. Seminar Nasional Matematika dan Pendidikan Matematika. Yogyakarta: Universitas Negeri Yogyakarta. Turban, Efraim et al Decision Support Systems and Intelligent Systems. Yogyakarta: Andi Offset Walpole, Ronald E. dan Myers, Raymond H Ilmu Peluang dan Statistik Untuk Insinyur Dan Ilmuwan. Bandung: ITB Press.
MATERI PRAKTIKUM PRAKTIKUM 3 ANALISA CLUSTER
 PRAKTIKUM 3 ANALISA CLUSTER Definisi Analisis cluster merupakan pengelompokan objek berdasarkan informasi yang diperoleh dari suatu data yang menjelaskan hubungan antar objek satu dengan objek lainnya.
PRAKTIKUM 3 ANALISA CLUSTER Definisi Analisis cluster merupakan pengelompokan objek berdasarkan informasi yang diperoleh dari suatu data yang menjelaskan hubungan antar objek satu dengan objek lainnya.
MATERI PRAKTIKUM PRAKTIKUM 3 ANALISA CLUSTER
 PRAKTIKUM 3 ANALISA CLUSTER Definisi Cluster Analisis cluster merupakan pengelompokan objek berdasarkan informasi yang diperoleh dari suatu data yang menjelaskan hubungan antar objek satu dengan objek
PRAKTIKUM 3 ANALISA CLUSTER Definisi Cluster Analisis cluster merupakan pengelompokan objek berdasarkan informasi yang diperoleh dari suatu data yang menjelaskan hubungan antar objek satu dengan objek
LABORATORIUM DATA MINING JURUSAN TEKNIK INDUSTRI FAKULTAS TEKNOLOGI INDUSTRI UNIVERSITAS ISLAM INDONESIA. Modul II CLUSTERING
 LABORATORIUM DATA MINING JURUSAN TEKNIK INDUSTRI FAKULTAS TEKNOLOGI INDUSTRI UNIVERSITAS ISLAM INDONESIA Modul II CLUSTERING TUJUA PRAKTIKUM 1. Mahasiswa mempunyai pengetahuan dan kemampuan dasar dalam
LABORATORIUM DATA MINING JURUSAN TEKNIK INDUSTRI FAKULTAS TEKNOLOGI INDUSTRI UNIVERSITAS ISLAM INDONESIA Modul II CLUSTERING TUJUA PRAKTIKUM 1. Mahasiswa mempunyai pengetahuan dan kemampuan dasar dalam
BAB I PENDAHULUAN. 1.1 Latar Belakang
 BAB I PENDAHULUAN 1.1 Latar Belakang Analisis cluster merupakan teknik multivariat yang mempunyai tujuan utama untuk mengelompokkan objek-objek berdasarkan karakteristik yang dimilikinya. Analisis cluster
BAB I PENDAHULUAN 1.1 Latar Belakang Analisis cluster merupakan teknik multivariat yang mempunyai tujuan utama untuk mengelompokkan objek-objek berdasarkan karakteristik yang dimilikinya. Analisis cluster
BAB II TINJAUAN PUSTAKA. pengetahuan di dalam database. Data mining adalah proses yang menggunakan
 6 BAB II TINJAUAN PUSTAKA 2.1 Pengertian Data Mining Data mining adalah suatu istilah yang digunakan untuk menguraikan penemuan pengetahuan di dalam database. Data mining adalah proses yang menggunakan
6 BAB II TINJAUAN PUSTAKA 2.1 Pengertian Data Mining Data mining adalah suatu istilah yang digunakan untuk menguraikan penemuan pengetahuan di dalam database. Data mining adalah proses yang menggunakan
BAB II LANDASAN TEORI
 BAB II LANDASAN TEORI 2.1 Data Mining Faktor penentu bagi usaha atau bisnis apapun pada masa sekarang ini adalah kemampuan untuk menggunakan informasi seefektif mungkin. Penggunaan data secara tepat karena
BAB II LANDASAN TEORI 2.1 Data Mining Faktor penentu bagi usaha atau bisnis apapun pada masa sekarang ini adalah kemampuan untuk menggunakan informasi seefektif mungkin. Penggunaan data secara tepat karena
Analisis Cluster, Analisis Diskriminan & Analisis Komponen Utama. Analisis Cluster
 Analisis Cluster Analisis Cluster adalah suatu analisis statistik yang bertujuan memisahkan kasus/obyek ke dalam beberapa kelompok yang mempunyai sifat berbeda antar kelompok yang satu dengan yang lain.
Analisis Cluster Analisis Cluster adalah suatu analisis statistik yang bertujuan memisahkan kasus/obyek ke dalam beberapa kelompok yang mempunyai sifat berbeda antar kelompok yang satu dengan yang lain.
BAB 2 LANDASAN TEORI
 7 BAB 2 LANDASAN TEORI Bab ini membahas tentang teori penunjang dan penelitian sebelumnya yang berhubungan dengan penerapan algoritma hierarchical clustering dan k-means untuk pengelompokan desa tertinggal.
7 BAB 2 LANDASAN TEORI Bab ini membahas tentang teori penunjang dan penelitian sebelumnya yang berhubungan dengan penerapan algoritma hierarchical clustering dan k-means untuk pengelompokan desa tertinggal.
BAB 1 KONSEP DATA MINING 2 Gambar 1.1 Perkembangan Database Permasalahannya kemudian adalah apa yang harus dilakukan dengan data-data itu. Sudah diket
 Bab1 Konsep Data Mining POKOK BAHASAN: Konsep dasar dan pengertian Data Mining Tahapan dalam Data Mining Model Data Mining Fungsi Data Mining TUJUAN BELAJAR: Setelah mempelajari materi dalam bab ini, mahasiswa
Bab1 Konsep Data Mining POKOK BAHASAN: Konsep dasar dan pengertian Data Mining Tahapan dalam Data Mining Model Data Mining Fungsi Data Mining TUJUAN BELAJAR: Setelah mempelajari materi dalam bab ini, mahasiswa
PERTEMUAN 14 DATA WAREHOUSE
 PERTEMUAN 14 DATA WAREHOUSE Data Warehouse Definisi : Data Warehouse adalah Pusat repositori informasi yang mampu memberikan database berorientasi subyek untuk informasi yang bersifat historis yang mendukung
PERTEMUAN 14 DATA WAREHOUSE Data Warehouse Definisi : Data Warehouse adalah Pusat repositori informasi yang mampu memberikan database berorientasi subyek untuk informasi yang bersifat historis yang mendukung
Analisis cluster pengorganisasian kumpulan pola ke dalam cluster (kelompok-kelompok) berdasar atas kesamaannya. Pola-pola dalam suatu cluster akan
 berdasar atas kesamaannya. Pola-pola dalam suatu cluster akan") Analisis cluster pengorganisasian kumpulan pola ke dalam cluster (kelompok-kelompok) berdasar atas kesamaannya. Pola-pola dalam suatu cluster akan memiliki kesamaan ciri/sifat daripada pola-pola dalam
Analisis cluster pengorganisasian kumpulan pola ke dalam cluster (kelompok-kelompok) berdasar atas kesamaannya. Pola-pola dalam suatu cluster akan memiliki kesamaan ciri/sifat daripada pola-pola dalam
BAB II TINJAUAN PUSTAKA
 BAB II TINJAUAN PUSTAKA 2.1 Landasan Teori 2.1.1 Konsep Pemasaran Dalam merancang dan mengembangkan produk, baik yang berupa jasa maupun barang, tidak terlepas dari konsep pemasaran yang bertujuan memenuhi
BAB II TINJAUAN PUSTAKA 2.1 Landasan Teori 2.1.1 Konsep Pemasaran Dalam merancang dan mengembangkan produk, baik yang berupa jasa maupun barang, tidak terlepas dari konsep pemasaran yang bertujuan memenuhi
BAB II TINJAUAN PUSTAKA DAN LANDASAN TEORI. menerapkan metode clustering dengan algoritma K-Means untuk penelitiannya.
 BAB II TINJAUAN PUSTAKA DAN LANDASAN TEORI 2.1 Tinjauan Pustaka Salah satu cara untuk mengetahui faktor nilai cumlaude mahasiswa Fakultas Teknik Universitas Muhammadiyah Yogyakarta adalah dengan menerapkan
BAB II TINJAUAN PUSTAKA DAN LANDASAN TEORI 2.1 Tinjauan Pustaka Salah satu cara untuk mengetahui faktor nilai cumlaude mahasiswa Fakultas Teknik Universitas Muhammadiyah Yogyakarta adalah dengan menerapkan
BAB II LANDASAN TEORI
 BAB II LANDASAN TEORI II.1 Sistem Pendukung Keputusan II.1.1 Definisi Sistem Pendukung Keputusan Berdasarkan Efraim Turban dkk, Sistem Pendukung Keputusan (SPK) / Decision Support System (DSS) adalah sebuah
BAB II LANDASAN TEORI II.1 Sistem Pendukung Keputusan II.1.1 Definisi Sistem Pendukung Keputusan Berdasarkan Efraim Turban dkk, Sistem Pendukung Keputusan (SPK) / Decision Support System (DSS) adalah sebuah
MODUL 6 ANALISIS CLUSTER
 MODUL 6 ANALISIS CLUSTER Tujuan Praktikum Pada modul 6 ini, tujuan yang hendak dicapai dalam pelaksanaan praktikum antara lain : Mahasiswa mampu mengenali karakteristik analisis cluster. Mahasiswa memahami
MODUL 6 ANALISIS CLUSTER Tujuan Praktikum Pada modul 6 ini, tujuan yang hendak dicapai dalam pelaksanaan praktikum antara lain : Mahasiswa mampu mengenali karakteristik analisis cluster. Mahasiswa memahami
BAB II TINJAUAN PUSTAKA DAN LANDASAN TEORI
 BAB II TINJAUAN PUSTAKA DAN LANDASAN TEORI penelitian. Pada bab ini akan dibahas literatur dan landasan teori yang relevan dengan 2.1 Tinjauan Pustaka Kombinasi metode telah dilakukan oleh beberapa peneliti
BAB II TINJAUAN PUSTAKA DAN LANDASAN TEORI penelitian. Pada bab ini akan dibahas literatur dan landasan teori yang relevan dengan 2.1 Tinjauan Pustaka Kombinasi metode telah dilakukan oleh beberapa peneliti
Cluster Analysis. Hery Tri Sutanto. Jurusan Matematika MIPA UNESA. Abstrak
 S-17 Cluster Analysis Hery Tri Sutanto Jurusan Matematika MIPA UNESA Abstrak Dalam analisis cluster mempelajari hubungan interdependensi antara seluruh set variabel perlu diteliti. Tujuan utama analisis
S-17 Cluster Analysis Hery Tri Sutanto Jurusan Matematika MIPA UNESA Abstrak Dalam analisis cluster mempelajari hubungan interdependensi antara seluruh set variabel perlu diteliti. Tujuan utama analisis
BAB I PENDAHULUAN. Analisis statistik multivariat adalah metode statistik di mana masalah yang
 BAB I PENDAHULUAN 1.1. LATAR BELAKANG MASALAH Analisis statistik multivariat adalah metode statistik di mana masalah yang diteliti bersifat multidimensional dengan menggunakan tiga atau lebih variabel
BAB I PENDAHULUAN 1.1. LATAR BELAKANG MASALAH Analisis statistik multivariat adalah metode statistik di mana masalah yang diteliti bersifat multidimensional dengan menggunakan tiga atau lebih variabel
ANALISIS CLUSTER PADA DOKUMEN TEKS
 Text dan Web Mining - FTI UKDW - BUDI SUSANTO 1 ANALISIS CLUSTER PADA DOKUMEN TEKS Budi Susanto (versi 1.3) Text dan Web Mining - FTI UKDW - BUDI SUSANTO 2 Tujuan Memahami konsep analisis clustering Memahami
Text dan Web Mining - FTI UKDW - BUDI SUSANTO 1 ANALISIS CLUSTER PADA DOKUMEN TEKS Budi Susanto (versi 1.3) Text dan Web Mining - FTI UKDW - BUDI SUSANTO 2 Tujuan Memahami konsep analisis clustering Memahami
BAB II LANDASAN TEORI
 BAB II LANDASAN TEORI 2.1 Data Mining Secara sederhana data mining adalah penambangan atau penemuan informasi baru dengan mencari pola atau aturan tertentu dari sejumlah data yang sangat besar. Data mining
BAB II LANDASAN TEORI 2.1 Data Mining Secara sederhana data mining adalah penambangan atau penemuan informasi baru dengan mencari pola atau aturan tertentu dari sejumlah data yang sangat besar. Data mining
IMPLEMENTASI ALGORITMA K-NEAREST NEIGHBOUR UNTUK PREDIKSI WAKTU KELULUSAN MAHASISWA
 IMPLEMENTASI ALGORITMA K-NEAREST NEIGHBOUR UNTUK PREDIKSI WAKTU KELULUSAN MAHASISWA Irwan Budiman 1, Dodon Turianto Nugrahadi 2, Radityo Adi Nugroho 3 Universitas Lambung Mangkurat 1,2,3 irwan.budiman@unlam.ac.id
IMPLEMENTASI ALGORITMA K-NEAREST NEIGHBOUR UNTUK PREDIKSI WAKTU KELULUSAN MAHASISWA Irwan Budiman 1, Dodon Turianto Nugrahadi 2, Radityo Adi Nugroho 3 Universitas Lambung Mangkurat 1,2,3 irwan.budiman@unlam.ac.id
BAB II TINJAUAN PUSTAKA
 BAB II TINJAUAN PUSTAKA 2.1 Dasar Teori 2.1.1 Data Mining Data mining adalah suatu istilah yang digunakan untuk menguraikan penemuan pengetahuan di dalam database. Data mining adalah Proses yang menggunakan
BAB II TINJAUAN PUSTAKA 2.1 Dasar Teori 2.1.1 Data Mining Data mining adalah suatu istilah yang digunakan untuk menguraikan penemuan pengetahuan di dalam database. Data mining adalah Proses yang menggunakan
Jumlah persentase ini tidak harus persis seperti diatas tetapi bisa bervariasi tergantung di perusahaan mana metode ini diterapkan.
 BAB 2 TINJAUAN PUSTAKA 2.1 Metode Pengelompokan ABC Pada abad ke-18, Villfredo Pareto, dalam penelitiannya mengenai distribusi kekayaan penduduk di Milan Italia, menemukan bahwa 20% dari total populasi
BAB 2 TINJAUAN PUSTAKA 2.1 Metode Pengelompokan ABC Pada abad ke-18, Villfredo Pareto, dalam penelitiannya mengenai distribusi kekayaan penduduk di Milan Italia, menemukan bahwa 20% dari total populasi
PENINGKATAN PERFORMA ALGORITMA APRIORI UNTUK ATURAN ASOSIASI DATA MINING
 PENINGKATAN PERFORMA ALGORITMA APRIORI UNTUK ATURAN ASOSIASI DATA MINING Andreas Chandra Teknik Informatika STMIK AMIKOM Yogyakarta Jl Ring road Utara, Condongcatur, Sleman, Yogyakarta 55281 Email : andreaschaandra@yahoo.com
PENINGKATAN PERFORMA ALGORITMA APRIORI UNTUK ATURAN ASOSIASI DATA MINING Andreas Chandra Teknik Informatika STMIK AMIKOM Yogyakarta Jl Ring road Utara, Condongcatur, Sleman, Yogyakarta 55281 Email : andreaschaandra@yahoo.com
PENERAPAN ALGORITMA C4.5 DALAM PEMILIHAN BIDANG PEMINATAN PROGRAM STUDI SISTEM INFORMASI DI STMIK POTENSI UTAMA MEDAN
 PENERAPAN ALGORITMA C4.5 DALAM PEMILIHAN BIDANG PEMINATAN PROGRAM STUDI SISTEM INFORMASI DI STMIK POTENSI UTAMA MEDAN Fina Nasari 1 1 Sistem Informasi, STMIK Potensi Utama 3 Jalan K.L. Yos Sudarso KM.
PENERAPAN ALGORITMA C4.5 DALAM PEMILIHAN BIDANG PEMINATAN PROGRAM STUDI SISTEM INFORMASI DI STMIK POTENSI UTAMA MEDAN Fina Nasari 1 1 Sistem Informasi, STMIK Potensi Utama 3 Jalan K.L. Yos Sudarso KM.
BAB II LANDASAN TEORI
 BAB II LANDASAN TEORI 2.1. Pendahuluan Didalam bab ini menceritakan semua teori-teori yang digunakan didalam proses algoritma decision tree, algoritma Random tree dan Random Florest serta teoriteori dan
BAB II LANDASAN TEORI 2.1. Pendahuluan Didalam bab ini menceritakan semua teori-teori yang digunakan didalam proses algoritma decision tree, algoritma Random tree dan Random Florest serta teoriteori dan
Konsep Data Mining. Pendahuluan. Bertalya. Universitas Gunadarma 2009
 Konsep Data Mining Pendahuluan Bertalya Universitas Gunadarma 2009 Latar Belakang Data yg dikumpulkan semakin bertambah banyak Data web, e-commerce Data pembelian di toko2 / supermarket Transaksi Bank/Kartu
Konsep Data Mining Pendahuluan Bertalya Universitas Gunadarma 2009 Latar Belakang Data yg dikumpulkan semakin bertambah banyak Data web, e-commerce Data pembelian di toko2 / supermarket Transaksi Bank/Kartu
DATA MINING DAN WAREHOUSE A N D R I
 DATA MINING DAN WAREHOUSE A N D R I CLUSTERING Secara umum cluster didefinisikan sebagai sejumlah objek yang mirip yang dikelompokan secara bersama, Namun definisi dari cluster bisa beragam tergantung
DATA MINING DAN WAREHOUSE A N D R I CLUSTERING Secara umum cluster didefinisikan sebagai sejumlah objek yang mirip yang dikelompokan secara bersama, Namun definisi dari cluster bisa beragam tergantung
ANALISIS CLUSTER PADA DOKUMEN TEKS
 Budi Susanto ANALISIS CLUSTER PADA DOKUMEN TEKS Text dan Web Mining - FTI UKDW - BUDI SUSANTO 1 Tujuan Memahami konsep analisis clustering Memahami tipe-tipe data dalam clustering Memahami beberapa algoritma
Budi Susanto ANALISIS CLUSTER PADA DOKUMEN TEKS Text dan Web Mining - FTI UKDW - BUDI SUSANTO 1 Tujuan Memahami konsep analisis clustering Memahami tipe-tipe data dalam clustering Memahami beberapa algoritma
BAB II LANDASAN TEORI
 BAB II LANDASAN TEORI 2.1 Data Mining Data Mining adalah proses yang mempekerjakan satu atau lebih teknik pembelajaran komputer (machine learning) untuk menganalisis dan mengekstraksi pengetahuan (knowledge)
BAB II LANDASAN TEORI 2.1 Data Mining Data Mining adalah proses yang mempekerjakan satu atau lebih teknik pembelajaran komputer (machine learning) untuk menganalisis dan mengekstraksi pengetahuan (knowledge)
Universitas Putra Indonesia YPTK Padang Fakulas Ilmu Komputer Program Studi Teknik Informatika. Knowledge Discovery in Databases (KDD)
") Universitas Putra Indonesia YPTK Padang Fakulas Ilmu Komputer Program Studi Teknik Informatika Knowledge Discovery in Databases (KDD) Knowledge Discovery in Databases (KDD) Definisi Knowledge Discovery
Universitas Putra Indonesia YPTK Padang Fakulas Ilmu Komputer Program Studi Teknik Informatika Knowledge Discovery in Databases (KDD) Knowledge Discovery in Databases (KDD) Definisi Knowledge Discovery
BAB II LANDASAN TEORI. yang terdiri dari komponen-komponen atau sub sistem yang berorientasi untuk
 BAB II LANDASAN TEORI 2.1 Sistem Menurut Gondodiyoto (2007), sistem adalah merupakan suatu kesatuan yang terdiri dari komponen-komponen atau sub sistem yang berorientasi untuk mencapai suatu tujuan tertentu.
BAB II LANDASAN TEORI 2.1 Sistem Menurut Gondodiyoto (2007), sistem adalah merupakan suatu kesatuan yang terdiri dari komponen-komponen atau sub sistem yang berorientasi untuk mencapai suatu tujuan tertentu.
BAB I PENDAHULUAN. Masalah dalam kehidupan sehari-hari tidak hanya didasarkan pada
 BAB I PENDAHULUAN 1.1 Latar Belakang Masalah dalam kehidupan sehari-hari tidak hanya didasarkan pada hubungan satu variabel atau dua variabel saja, akan tetapi cenderung melibatkan banyak variabel. Analisis
BAB I PENDAHULUAN 1.1 Latar Belakang Masalah dalam kehidupan sehari-hari tidak hanya didasarkan pada hubungan satu variabel atau dua variabel saja, akan tetapi cenderung melibatkan banyak variabel. Analisis
BAB 2 TINJAUAN PUSTAKA Klasifikasi Data Mahasiswa Menggunakan Metode K-Means Untuk Menunjang Pemilihan Strategi Pemasaran
 BAB 2 TINJAUAN PUSTAKA 2.1 Tinjauan Pustaka Beberapa penelitian terdahulu telah banyak yang menerapkan data mining, yang bertujuan dalam menyelesaikan beberapa permasalahan seputar dunia pendidikan. Khususnya
BAB 2 TINJAUAN PUSTAKA 2.1 Tinjauan Pustaka Beberapa penelitian terdahulu telah banyak yang menerapkan data mining, yang bertujuan dalam menyelesaikan beberapa permasalahan seputar dunia pendidikan. Khususnya
ANALISIS GEROMBOL CLUSTER ANALYSIS
 ANALISIS GEROMBOL CLUSTER ANALYSIS Pendahuluan Tujuan dari analisis gerombol : Menggabungkan beberapa objek ke dalam kelompok-kelompok berdasarkan sifat kemiripan atau sifat ketidakmiripan antar objek
ANALISIS GEROMBOL CLUSTER ANALYSIS Pendahuluan Tujuan dari analisis gerombol : Menggabungkan beberapa objek ke dalam kelompok-kelompok berdasarkan sifat kemiripan atau sifat ketidakmiripan antar objek
BAB III METODE PENELITIAN. Alasan memilih Ciputra Taman Dayu Pandaan dikarenakan Ciputra Taman Dayu
 BAB III METODE PENELITIAN 1.1 Lokasi Penelitian Lokasi penelitian ini di Ciputra Taman Dayu Property Pandaan Pasuruan yang terletak di Jl. Raya Surabaya Km. 48 Pandaan 67156 Pasuruan Jawa Timur. Alasan
BAB III METODE PENELITIAN 1.1 Lokasi Penelitian Lokasi penelitian ini di Ciputra Taman Dayu Property Pandaan Pasuruan yang terletak di Jl. Raya Surabaya Km. 48 Pandaan 67156 Pasuruan Jawa Timur. Alasan
TAKARIR. : Mengelompokkan suatu objek yang memiliki kesamaan. : Kelompok atau kelas
 TAKARIR Data Mining Clustering Cluster Iteratif Random Centroid : Penggalian data : Mengelompokkan suatu objek yang memiliki kesamaan. : Kelompok atau kelas : Berulang : Acak : Pusat area KDD (Knowledge
TAKARIR Data Mining Clustering Cluster Iteratif Random Centroid : Penggalian data : Mengelompokkan suatu objek yang memiliki kesamaan. : Kelompok atau kelas : Berulang : Acak : Pusat area KDD (Knowledge
Tipe Clustering. Partitional Clustering. Hirerarchical Clustering
 Analisis Cluster Analisis Cluster Analisis cluster adalah pengorganisasian kumpulan pola ke dalam cluster (kelompok-kelompok) berdasar atas kesamaannya. Pola-pola dalam suatu cluster akan memiliki kesamaan
Analisis Cluster Analisis Cluster Analisis cluster adalah pengorganisasian kumpulan pola ke dalam cluster (kelompok-kelompok) berdasar atas kesamaannya. Pola-pola dalam suatu cluster akan memiliki kesamaan
PENGELOMPOKAN KABUPATEN/KOTA DI KALIMANTAN BARAT BERDASARKAN INDIKATOR DALAM PEMERATAAN PENDIDIKAN MENGGUNAKAN METODE MINIMAX LINKAGE
 Buletin Ilmiah Mat. Stat. dan Terapannya (Bimaster) Volume 05, No. 02 (2016), hal 253-260 PENGELOMPOKAN KABUPATEN/KOTA DI KALIMANTAN BARAT BERDASARKAN INDIKATOR DALAM PEMERATAAN PENDIDIKAN MENGGUNAKAN
Buletin Ilmiah Mat. Stat. dan Terapannya (Bimaster) Volume 05, No. 02 (2016), hal 253-260 PENGELOMPOKAN KABUPATEN/KOTA DI KALIMANTAN BARAT BERDASARKAN INDIKATOR DALAM PEMERATAAN PENDIDIKAN MENGGUNAKAN
PENENTUAN JUMLAH CLUSTER OPTIMAL PADA MEDIAN LINKAGE DENGAN INDEKS VALIDITAS SILHOUETTE
 Buletin Ilmiah Math. Stat. dan Terapannya (Bimaster) Volume 05, No. 2 (2016), hal 97 102. PENENTUAN JUMLAH CLUSTER OPTIMAL PADA MEDIAN LINKAGE DENGAN INDEKS VALIDITAS SILHOUETTE Nicolaus, Evy Sulistianingsih,
Buletin Ilmiah Math. Stat. dan Terapannya (Bimaster) Volume 05, No. 2 (2016), hal 97 102. PENENTUAN JUMLAH CLUSTER OPTIMAL PADA MEDIAN LINKAGE DENGAN INDEKS VALIDITAS SILHOUETTE Nicolaus, Evy Sulistianingsih,
Kata kunci: Cluster, Knowledge Discovery in Database, Algoritma K-Means,
 K- Pembentukan cluster dalam Knowledge Discovery in Database dengan Algoritma K-Means Oleh: Sri Andayani Jurusan Pendidikan Matematika FMIPA UNY,email: andayani@uny.ac.id Abstrak Pembentukan cluster merupakan
K- Pembentukan cluster dalam Knowledge Discovery in Database dengan Algoritma K-Means Oleh: Sri Andayani Jurusan Pendidikan Matematika FMIPA UNY,email: andayani@uny.ac.id Abstrak Pembentukan cluster merupakan
Implementasi Data Mining dengan Metode Klastering untuk Meramalkan Permintaan Pasar (Studi Kasus PT. Nutrifood Indonesia )
") Implementasi Data Mining dengan Metode Klastering untuk Meramalkan Permintaan Pasar (Studi Kasus PT. Nutrifood Indonesia ) November 20, 2010 Arimbi Kurniasari Lintang Yuniar Banowosari Alex Hutapea Manajemen
Implementasi Data Mining dengan Metode Klastering untuk Meramalkan Permintaan Pasar (Studi Kasus PT. Nutrifood Indonesia ) November 20, 2010 Arimbi Kurniasari Lintang Yuniar Banowosari Alex Hutapea Manajemen
commit to user 5 BAB II TINJAUAN PUSTAKA 2.1 Dasar Teori Text mining
 BAB II TINJAUAN PUSTAKA 2.1 Dasar Teori 2.1.1 Text mining Text mining adalah proses menemukan hal baru, yang sebelumnya tidak diketahui, mengenai informasi yang berpotensi untuk diambil manfaatnya dari
BAB II TINJAUAN PUSTAKA 2.1 Dasar Teori 2.1.1 Text mining Text mining adalah proses menemukan hal baru, yang sebelumnya tidak diketahui, mengenai informasi yang berpotensi untuk diambil manfaatnya dari
Surmayanti 1, Hari Marfalino 2, Ade Rahmi 3 Fakultas Limu Komputer Universitas Putra Indonesia YPTK Padang
 PENERAPAN ANALYSIS CLUSTERING PADA PENJUALAN KOMPUTER DENGAN PERANCANGANAN APLIKASI DATA MINING MENGGUNAKAN ALGORITMA K-MEANS (STUDY KASUS TOKO TRI BUANA KOMPUTER KOTA SOLOK) Surmayanti 1, Hari Marfalino
PENERAPAN ANALYSIS CLUSTERING PADA PENJUALAN KOMPUTER DENGAN PERANCANGANAN APLIKASI DATA MINING MENGGUNAKAN ALGORITMA K-MEANS (STUDY KASUS TOKO TRI BUANA KOMPUTER KOTA SOLOK) Surmayanti 1, Hari Marfalino
BAB 3 LANDASAN TEORI
 BAB 3 LANDASAN TEORI 3.1. Data Mining Data mining adalah proses menganalisa data dari perspektif yang berbeda dan menyimpulkannya menjadi informasi-informasi penting yang dapat dipakai untuk meningkatkan
BAB 3 LANDASAN TEORI 3.1. Data Mining Data mining adalah proses menganalisa data dari perspektif yang berbeda dan menyimpulkannya menjadi informasi-informasi penting yang dapat dipakai untuk meningkatkan
BAB II TINJAUAN PUSTAKA DAN DASAR TEORI Tinjauan Pustaka Penelitian terkait metode clustering atau algoritma k-means pernah di
 BAB II TINJAUAN PUSTAKA DAN DASAR TEORI 2.1. Tinjauan Pustaka Penelitian terkait metode clustering atau algoritma k-means pernah di lakukan oleh Muhammad Toha dkk (2013), Sylvia Pretty Tulus (2014), Johan
BAB II TINJAUAN PUSTAKA DAN DASAR TEORI 2.1. Tinjauan Pustaka Penelitian terkait metode clustering atau algoritma k-means pernah di lakukan oleh Muhammad Toha dkk (2013), Sylvia Pretty Tulus (2014), Johan
ALGORITMA NEAREST NEIGHBOR UNTUK MENENTUKAN AREA PEMASARAN PRODUK BATIK DI KOTA PEKALONGAN
 ALGORITMA NEAREST NEIGHBOR UNTUK MENENTUKAN AREA PEMASARAN PRODUK BATIK DI KOTA PEKALONGAN Devi Sugianti Program Studi Sistem Informasi,STMIK Widya Pratama Jl. Patriot 25 Pekalongan Telp (0285)427816 email
ALGORITMA NEAREST NEIGHBOR UNTUK MENENTUKAN AREA PEMASARAN PRODUK BATIK DI KOTA PEKALONGAN Devi Sugianti Program Studi Sistem Informasi,STMIK Widya Pratama Jl. Patriot 25 Pekalongan Telp (0285)427816 email
KOMBINASI ALGORITMA AGGLOMERATIVE CLUSTERING DAN K-MEANS UNTUK SEGMENTASI PENGUNJUNG WEBSITE
 KOMBINASI ALGORITMA AGGLOMERATIVE CLUSTERING DAN K-MEANS UNTUK SEGMENTASI PENGUNJUNG WEBSITE Yudha Agung Wirawan, Dra.Indwiarti,M.Si, Yuliant Sibaroni,S.SI., M,T Program Studi Ilmu Komputasi Fakultas Informatika
KOMBINASI ALGORITMA AGGLOMERATIVE CLUSTERING DAN K-MEANS UNTUK SEGMENTASI PENGUNJUNG WEBSITE Yudha Agung Wirawan, Dra.Indwiarti,M.Si, Yuliant Sibaroni,S.SI., M,T Program Studi Ilmu Komputasi Fakultas Informatika
BAB 2 TINJAUAN PUSTAKA DAN DASAR TEORI. yang akan diteliti. Pemanfaatan algoritma apriori sudah cukup banyak digunakan, antara lain
 BAB 2 TINJAUAN PUSTAKA DAN DASAR TEORI 2.1 Tinjauan Pustaka Penelitian ini menggunakan beberapa sumber pustaka yang berhubungan dengan kasus yang akan diteliti. Pemanfaatan algoritma apriori sudah cukup
BAB 2 TINJAUAN PUSTAKA DAN DASAR TEORI 2.1 Tinjauan Pustaka Penelitian ini menggunakan beberapa sumber pustaka yang berhubungan dengan kasus yang akan diteliti. Pemanfaatan algoritma apriori sudah cukup
Timor Setiyaningsih, Nur Syamsiah Teknik Informatika Universitas Darma Persada. Abstrak
 DATA MINING MELIHAT POLA HUBUNGAN NILAI TES MASUK MAHASISWA TERHADAP DATA KELULUSAN MAHASISWA UNTUK MEMBANTU PERGURUAN TINGGI DALAM MENGAMBIL KEBIJAKAN DALAM RANGKA PENINGKATAN MUTU PERGURUAN TINGGI Timor
DATA MINING MELIHAT POLA HUBUNGAN NILAI TES MASUK MAHASISWA TERHADAP DATA KELULUSAN MAHASISWA UNTUK MEMBANTU PERGURUAN TINGGI DALAM MENGAMBIL KEBIJAKAN DALAM RANGKA PENINGKATAN MUTU PERGURUAN TINGGI Timor
BAB II KAJIAN TEORI. linier, varian dan simpangan baku, standarisasi data, koefisien korelasi, matriks
 BAB II KAJIAN TEORI Pada bab II akan dibahas tentang materi-materi dasar yang digunakan untuk mendukung pembahasan pada bab selanjutnya, yaitu matriks, kombinasi linier, varian dan simpangan baku, standarisasi
BAB II KAJIAN TEORI Pada bab II akan dibahas tentang materi-materi dasar yang digunakan untuk mendukung pembahasan pada bab selanjutnya, yaitu matriks, kombinasi linier, varian dan simpangan baku, standarisasi
BAB II LANDASAN TEORI
 BAB II LANDASAN TEORI 2.1 Traveling Salesmen Problem (TSP) Travelling Salesman Problem (TSP) merupakan sebuah permasalahan optimasi yang dapat diterapkan pada berbagai kegiatan seperti routing. Masalah
BAB II LANDASAN TEORI 2.1 Traveling Salesmen Problem (TSP) Travelling Salesman Problem (TSP) merupakan sebuah permasalahan optimasi yang dapat diterapkan pada berbagai kegiatan seperti routing. Masalah
BAB II TINJAUAN PUSTAKA
 BAB II TINJAUAN PUSTAKA 2.1. Aplikasi Data Mining Data mining adalah suatu istilah yang digunakan untuk menemukan pengetahuan yang tersembunyi di dalam database. Data mining merupakan proses semi otomatik
BAB II TINJAUAN PUSTAKA 2.1. Aplikasi Data Mining Data mining adalah suatu istilah yang digunakan untuk menemukan pengetahuan yang tersembunyi di dalam database. Data mining merupakan proses semi otomatik
BAB III K-MEANS CLUSTERING. Analisis klaster merupakan salah satu teknik multivariat metode
 BAB III K-MEANS CLUSTERING 3.1 Analisis Klaster Analisis klaster merupakan salah satu teknik multivariat metode interdependensi (saling ketergantungan). Oleh karena itu, dalam analisis klaster tidak ada
BAB III K-MEANS CLUSTERING 3.1 Analisis Klaster Analisis klaster merupakan salah satu teknik multivariat metode interdependensi (saling ketergantungan). Oleh karena itu, dalam analisis klaster tidak ada
DSS untuk Menganalisis ph Kesuburan Tanah Menggunakan Metode Single Linkage
 61 DSS untuk Menganalisis ph Kesuburan Tanah Menggunakan Metode Single Linkage Abdi Pandu Kusuma, Rini Nur Hasanah, dan Harry Soekotjo Dachlan Abstrak - ph tanah merupakan ukuran jumlah ion hidrogen dalam
61 DSS untuk Menganalisis ph Kesuburan Tanah Menggunakan Metode Single Linkage Abdi Pandu Kusuma, Rini Nur Hasanah, dan Harry Soekotjo Dachlan Abstrak - ph tanah merupakan ukuran jumlah ion hidrogen dalam
dengan Algoritma K Means
 K Pembentukan cluster dalam Knowledge Discovery in Database dengan Algoritma K Means Oleh: Sri Andayani Jurusan Pendidikan Matematika FMIPA UNY,email: andayani@uny.ac.id Abstrak Pembentukan cluster merupakan
K Pembentukan cluster dalam Knowledge Discovery in Database dengan Algoritma K Means Oleh: Sri Andayani Jurusan Pendidikan Matematika FMIPA UNY,email: andayani@uny.ac.id Abstrak Pembentukan cluster merupakan
Data Mining. Pengenalan Sistem & Teknik, Serta Contoh Aplikasi. Avinanta Tarigan. 22 Nov Avinanta Tarigan Data Mining
 Data Mining Pengenalan Sistem & Teknik, Serta Contoh Aplikasi Avinanta Tarigan 22 Nov 2008 1 Avinanta Tarigan Data Mining Outline 1 Pengertian Dasar 2 Classification Mining 3 Association Mining 4 Clustering
Data Mining Pengenalan Sistem & Teknik, Serta Contoh Aplikasi Avinanta Tarigan 22 Nov 2008 1 Avinanta Tarigan Data Mining Outline 1 Pengertian Dasar 2 Classification Mining 3 Association Mining 4 Clustering
Pertemuan 14 HIERARCHICAL CLUSTERING METHODS
 Pertemuan 14 HIERARCHICAL CLUSTERING METHODS berdasar gambar berdasar warna A A A A Q Q Q Q K K K K J J J J 2 2 2 2 3 3 3 3 4 4 4 4 5 5 5 5 6 6 6 6 7 7 7 7 8 8 8 8 9 9 9 9 10 10 10 10 A K Q J (a). Individual
Pertemuan 14 HIERARCHICAL CLUSTERING METHODS berdasar gambar berdasar warna A A A A Q Q Q Q K K K K J J J J 2 2 2 2 3 3 3 3 4 4 4 4 5 5 5 5 6 6 6 6 7 7 7 7 8 8 8 8 9 9 9 9 10 10 10 10 A K Q J (a). Individual
BAB 2 LANDASAN TEORI
 BAB 2 LANDASAN TEORI Bab ini membahas tentang teori penunjang dan penelitian sebelumnya yang berhubungan dengan analisa datadan algoritma Fuzzy C-Means untuk mangetahui pola perilaku konsumen. 2.1. Pola
BAB 2 LANDASAN TEORI Bab ini membahas tentang teori penunjang dan penelitian sebelumnya yang berhubungan dengan analisa datadan algoritma Fuzzy C-Means untuk mangetahui pola perilaku konsumen. 2.1. Pola
SOLUSI PREDIKSI MAHASISWA DROP OUT PADA PROGRAM STUDI SISTEM INFORMASI FAKULTAS ILMU KOMPUTER UNIVERSITAS BINA DARMA
 SOLUSI PREDIKSI MAHASISWA DROP OUT PADA PROGRAM STUDI SISTEM INFORMASI FAKULTAS ILMU KOMPUTER UNIVERSITAS BINA DARMA Ade Putra Fakultas Vokasi, Program Studi Komputerisasi Akuntansi Universitas Bina Darma
SOLUSI PREDIKSI MAHASISWA DROP OUT PADA PROGRAM STUDI SISTEM INFORMASI FAKULTAS ILMU KOMPUTER UNIVERSITAS BINA DARMA Ade Putra Fakultas Vokasi, Program Studi Komputerisasi Akuntansi Universitas Bina Darma
BAB IV METODE PENELITIAN
 44 BAB IV METODE PENELITIAN 4.1. Lokasi Penelitian Penelitian ini dilakukan pada industri kecil dan menengah di Kawasan Sarbagita, Bali yang terdiri dari empat wilayah, yaitu : Kota Denpasar, Kabupaten
44 BAB IV METODE PENELITIAN 4.1. Lokasi Penelitian Penelitian ini dilakukan pada industri kecil dan menengah di Kawasan Sarbagita, Bali yang terdiri dari empat wilayah, yaitu : Kota Denpasar, Kabupaten
ANALISIS CLUSTER DENGAN METODE K-MEANS (TEORI DAN CONTOH STUDY KASUS)
") ANALISIS MULTIVARIAT ANALISIS CLUSTER DENGAN METODE K-MEANS (TEORI DAN CONTOH STUDY KASUS) Oleh : Rizka Fauzia 1311 100 126 Dosen Pengampu: Santi Wulan Purnami S.Si., M.Si. PROGRAM STUDI SARJANA JURUSAN
ANALISIS MULTIVARIAT ANALISIS CLUSTER DENGAN METODE K-MEANS (TEORI DAN CONTOH STUDY KASUS) Oleh : Rizka Fauzia 1311 100 126 Dosen Pengampu: Santi Wulan Purnami S.Si., M.Si. PROGRAM STUDI SARJANA JURUSAN
BAB II LANDASAN TEORI
 BAB II LANDASAN TEORI 2.1 Clustering Analysis Clustering analysis merupakan metode pengelompokkan setiap objek ke dalam satu atau lebih dari satu kelompok,sehingga tiap objek yang berada dalam satu kelompok
BAB II LANDASAN TEORI 2.1 Clustering Analysis Clustering analysis merupakan metode pengelompokkan setiap objek ke dalam satu atau lebih dari satu kelompok,sehingga tiap objek yang berada dalam satu kelompok
PENERAPAN ALGORITMA K-MEANS PADA KUALITAS GIZI BAYI DI INDONESIA
 PENERAPAN ALGORITMA K-MEANS PADA KUALITAS GIZI BAYI DI INDONESIA Diajeng Tyas Purwa Hapsari Teknik Informatika STMIK AMIKOM Yogyakarta Jl Ring road Utara, Condongcatur, Sleman, Yogyakarta 55281 Email :
PENERAPAN ALGORITMA K-MEANS PADA KUALITAS GIZI BAYI DI INDONESIA Diajeng Tyas Purwa Hapsari Teknik Informatika STMIK AMIKOM Yogyakarta Jl Ring road Utara, Condongcatur, Sleman, Yogyakarta 55281 Email :
Pemilihan Distance Measure Pada K-Means Clustering Untuk Pengelompokkan Member Di Alvaro Fitness
 Pemilihan Distance Measure Pada K-Means Clustering Untuk Pengelompokkan Member Di Alvaro Fitness Mario Anggara 1, Herry Sujiani 2, Helfi Nasution 3 Program Studi Teknik Informatika Fakultas Teknik Universitas
Pemilihan Distance Measure Pada K-Means Clustering Untuk Pengelompokkan Member Di Alvaro Fitness Mario Anggara 1, Herry Sujiani 2, Helfi Nasution 3 Program Studi Teknik Informatika Fakultas Teknik Universitas
BAB II TINJAUAN PUSTAKA
 BAB II TINJAUAN PUSTAKA 2.1. Penambangan Data (Data Mining) Penambangan data (Data Mining) adalah serangkaian proses untuk menggali nilai tambah dari sekumpulan data berupa pengetahuan yang selama ini
BAB II TINJAUAN PUSTAKA 2.1. Penambangan Data (Data Mining) Penambangan data (Data Mining) adalah serangkaian proses untuk menggali nilai tambah dari sekumpulan data berupa pengetahuan yang selama ini
Penerapan Metode Fuzzy C-Means dengan Model Fuzzy RFM (Studi Kasus : Clustering Pelanggan Potensial Online Shop)
") 157 Penerapan Metode Fuzzy C-Means dengan Model Fuzzy RFM (Studi Kasus : Clustering Pelanggan Potensial Online Shop) Elly Muningsih AMIK BSI Yogyakarta E-Mail : elly.emh@bsi.ac.id Abstrak Berkembangnya
157 Penerapan Metode Fuzzy C-Means dengan Model Fuzzy RFM (Studi Kasus : Clustering Pelanggan Potensial Online Shop) Elly Muningsih AMIK BSI Yogyakarta E-Mail : elly.emh@bsi.ac.id Abstrak Berkembangnya
Analisa Anggaran Pendapatan dan Belanja Daerah (APBD) dengan Metode Hierarchical Clustering
 dengan Metode Hierarchical Clustering") SEMINAR NASIONAL MATEMATIKA DAN PENDIDIKAN MATEMATIKA UNY 2016 Analisa Anggaran Pendapatan dan Belanja Daerah (APBD) dengan Metode Hierarchical Clustering Viga Apriliana Sari, Nur Insani Jurusan Pendidikan
SEMINAR NASIONAL MATEMATIKA DAN PENDIDIKAN MATEMATIKA UNY 2016 Analisa Anggaran Pendapatan dan Belanja Daerah (APBD) dengan Metode Hierarchical Clustering Viga Apriliana Sari, Nur Insani Jurusan Pendidikan
UKDW BAB I PENDAHULUAN
 BAB I PENDAHULUAN 1.1 Latar Belakang Dalam dunia bisnis pada jaman sekarang, para pelaku bisnis senantiasa selalu berusaha mengembangkan cara-cara untuk dapat mengembangkan usaha mereka dan memperhatikan
BAB I PENDAHULUAN 1.1 Latar Belakang Dalam dunia bisnis pada jaman sekarang, para pelaku bisnis senantiasa selalu berusaha mengembangkan cara-cara untuk dapat mengembangkan usaha mereka dan memperhatikan
Pengenalan Pola. Klasterisasi Data
 Pengenalan Pola Klasterisasi Data PTIIK - 2014 Course Contents 1 Konsep Dasar 2 Tahapan Proses Klasterisasi 3 Ukuran Kemiripan Data 4 Algoritma Klasterisasi Konsep Dasar Klusterisasi Data, atau Data Clustering
Pengenalan Pola Klasterisasi Data PTIIK - 2014 Course Contents 1 Konsep Dasar 2 Tahapan Proses Klasterisasi 3 Ukuran Kemiripan Data 4 Algoritma Klasterisasi Konsep Dasar Klusterisasi Data, atau Data Clustering
BAB I PENDAHULUAN. Sekarang ini penelitian sering kali melibatkan beberapa variabel
 BAB I PENDAHULUAN 1.1 Latar Belakang Masalah Sekarang ini penelitian sering kali melibatkan beberapa variabel pengamatan. Data yang diperoleh dengan mengukur lebih dari satu variabel pengamatan pada setiap
BAB I PENDAHULUAN 1.1 Latar Belakang Masalah Sekarang ini penelitian sering kali melibatkan beberapa variabel pengamatan. Data yang diperoleh dengan mengukur lebih dari satu variabel pengamatan pada setiap
BAB II TINJAUAN PUSTAKA DAN LANDASAN TEORI
 BAB II TINJAUAN PUSTAKA DAN LANDASAN TEORI 2.1. Tinjauan Pustaka Tinjauan pustaka atau disebut juga kajian pustaka (literature review) merupakan sebuah aktivitas untuk meninjau atau mengkaji kembali berbagai
BAB II TINJAUAN PUSTAKA DAN LANDASAN TEORI 2.1. Tinjauan Pustaka Tinjauan pustaka atau disebut juga kajian pustaka (literature review) merupakan sebuah aktivitas untuk meninjau atau mengkaji kembali berbagai
BAB 2 TINJAUAN PUSTAKA DAN LANDASAN TEORI
 BAB 2 TINJAUAN PUSTAKA DAN LANDASAN TEORI Pada bab ini akan membahas 2 hal yaitu tinjauan pustaka dan landasan teori yang digunakan dalam penelitian ini. 2.1. Tinjauan Pustaka Klasifikasi ABC jarang digunakan
BAB 2 TINJAUAN PUSTAKA DAN LANDASAN TEORI Pada bab ini akan membahas 2 hal yaitu tinjauan pustaka dan landasan teori yang digunakan dalam penelitian ini. 2.1. Tinjauan Pustaka Klasifikasi ABC jarang digunakan
BAB 2 LANDASAN TEORI
 BAB 2 LANDASAN TEORI 2.1 Penambangan Data (Data Mining) Pengertian data mining, berdasarkan beberapa orang: 1. Data mining (penambangan data) adalah suatu proses untuk menemukan suatu pengetahuan atau
BAB 2 LANDASAN TEORI 2.1 Penambangan Data (Data Mining) Pengertian data mining, berdasarkan beberapa orang: 1. Data mining (penambangan data) adalah suatu proses untuk menemukan suatu pengetahuan atau
BAB III METODOLOGI PENELITIAN. Jenis penelitian yang digunakan dalam menyusun skripsi ini menggunakan
 BAB III METODOLOGI PENELITIAN A. Jenis Penelitian Jenis penelitian yang digunakan dalam menyusun skripsi ini menggunakan metode deskriptif. Menurut Sugiono dalam bukunya Metodologi Penelitian Bisnis (2009)
BAB III METODOLOGI PENELITIAN A. Jenis Penelitian Jenis penelitian yang digunakan dalam menyusun skripsi ini menggunakan metode deskriptif. Menurut Sugiono dalam bukunya Metodologi Penelitian Bisnis (2009)
2. Tinjauan Pustaka. Gambar 2-1 : Knowledge discovery in database
 2. Tinjauan Pustaka 2.1 Data Mining Data mining merupakan ilmu yang mempelajari tentang proses ekstraksi informasi yang tersembunyi dari sekumpulan data yang berukuran sangat besar dengan menggunakan algoritma
2. Tinjauan Pustaka 2.1 Data Mining Data mining merupakan ilmu yang mempelajari tentang proses ekstraksi informasi yang tersembunyi dari sekumpulan data yang berukuran sangat besar dengan menggunakan algoritma
BAB III DIVISIVE ANALISIS. Pada bab ini akan dipaparkan bagaimana konsep dari divisive analisis serta
 13 BAB III DIVISIVE ANALISIS Pada bab ini akan dipaparkan bagaimana konsep dari divisive analisis serta algoritma dari metode tersebut. 3.1 DEFINISI METODE DIVISIVE Teknik divisive klastering termasuk
13 BAB III DIVISIVE ANALISIS Pada bab ini akan dipaparkan bagaimana konsep dari divisive analisis serta algoritma dari metode tersebut. 3.1 DEFINISI METODE DIVISIVE Teknik divisive klastering termasuk
BAB III METODOLOGI PENELITIAN
 BAB III METODOLOGI PENELITIAN Metodologi penelitian merupakan sistematika tahapan yang dilaksanakan selama pembuatan penelitian tugas akhir. Secara garis besar metodologi penelitian tugas akhir ini dapat
BAB III METODOLOGI PENELITIAN Metodologi penelitian merupakan sistematika tahapan yang dilaksanakan selama pembuatan penelitian tugas akhir. Secara garis besar metodologi penelitian tugas akhir ini dapat
PENDAHULUAN TINJAUAN PUSTAKA
 Latar Belakang PENDAHULUAN Sponge atau poriferans berasal dari bahasa Latin yaitu porus yang artinya pori dan ferre yang artinya memiliki. Sponge adalah hewan berpori, pada umumnya terdapat di lautan,
Latar Belakang PENDAHULUAN Sponge atau poriferans berasal dari bahasa Latin yaitu porus yang artinya pori dan ferre yang artinya memiliki. Sponge adalah hewan berpori, pada umumnya terdapat di lautan,
Klasifikasi Data Karyawan Untuk Menentukan Jadwal Kerja Menggunakan Metode Decision Tree
 Klasifikasi Data Karyawan Untuk Menentukan Jadwal Kerja Menggunakan Metode Decision Tree Disusun oleh : Budanis Dwi Meilani Achmad dan Fauzi Slamat Jurusan Sistem Informasi Fakultas Teknologi Informasi.
Klasifikasi Data Karyawan Untuk Menentukan Jadwal Kerja Menggunakan Metode Decision Tree Disusun oleh : Budanis Dwi Meilani Achmad dan Fauzi Slamat Jurusan Sistem Informasi Fakultas Teknologi Informasi.
Analisis Cluster Studi Kasus: Kabupaten Jepara Jawa Tengah
 Analisis Cluster Studi Kasus: Kabupaten Jepara Jawa Tengah Disusun untuk Memenuhi Tugas Mata Kuliah Metode Analisis Perencanaan (TKP 34) Dosen Pengampu: Dr. Iwan Rudiarto Widjanarko, S.T., M.T. Sri Rahayu,
Analisis Cluster Studi Kasus: Kabupaten Jepara Jawa Tengah Disusun untuk Memenuhi Tugas Mata Kuliah Metode Analisis Perencanaan (TKP 34) Dosen Pengampu: Dr. Iwan Rudiarto Widjanarko, S.T., M.T. Sri Rahayu,
BAB II LANDASAN TEORI
 BAB II LANDASAN TEORI 2.1. Sistem Informasi Pengertian Sistem Informasi pada dasarnya merupakan hasil dari dua arti, yakni sistem dan informasi yang digabungkan. Berikut definisi sistem menurut para ahli
BAB II LANDASAN TEORI 2.1. Sistem Informasi Pengertian Sistem Informasi pada dasarnya merupakan hasil dari dua arti, yakni sistem dan informasi yang digabungkan. Berikut definisi sistem menurut para ahli
BAB I PENDAHULUAN. Universitas Sumatera Utara
 BAB I PENDAHULUAN 1.1 Latar Belakang Data mining adalah suatu konsep yang digunakan untuk menemukan pengetahuan yang tersembunyi di dalam database. Data mining merupakan proses semi otomatik yang menggunakan
BAB I PENDAHULUAN 1.1 Latar Belakang Data mining adalah suatu konsep yang digunakan untuk menemukan pengetahuan yang tersembunyi di dalam database. Data mining merupakan proses semi otomatik yang menggunakan
BAB 2 TINJAUAN PUSTAKA
 BAB 2 TINJAUAN PUSTAKA 2.1. Data Mining Data Mining adalah proses pencarian pengetahuan dari suatu data berukuran besar melalui metode statistik, machine learning, dan artificial algorithm. Hal yang paling
BAB 2 TINJAUAN PUSTAKA 2.1. Data Mining Data Mining adalah proses pencarian pengetahuan dari suatu data berukuran besar melalui metode statistik, machine learning, dan artificial algorithm. Hal yang paling
BAB III ANALISIS III.1 Analisis Konseptual Teknik Pengolahan Data
 BAB III ANALISIS III.1 Analisis Konseptual Teknik Pengolahan Data Data sudah menjadi bagian penting dalam pengambilan keputusan. Data telah banyak terkumpul baik itu data transaksi perbankan, data kependudukan,
BAB III ANALISIS III.1 Analisis Konseptual Teknik Pengolahan Data Data sudah menjadi bagian penting dalam pengambilan keputusan. Data telah banyak terkumpul baik itu data transaksi perbankan, data kependudukan,
BAB II TINJAUAN PUSTAKA
 14 BAB II TINJAUAN PUSTAKA Kajian pustaka dalam penelitian ini adalah sebagai referensi dan literatur penunjang. Kajian pustaka dalam penelitian ini meliputi landasan teori yang menjadi dasar atau pedoman
14 BAB II TINJAUAN PUSTAKA Kajian pustaka dalam penelitian ini adalah sebagai referensi dan literatur penunjang. Kajian pustaka dalam penelitian ini meliputi landasan teori yang menjadi dasar atau pedoman
Jurnal Ilmiah Komputer dan Informatika (KOMPUTA) 45 Edisi... Volume..., Bulan 20.. ISSN :
 45 Edisi... Volume..., Bulan 20.. ISSN :") Jurnal Ilmiah Komputer dan Informatika (KOMPUTA) 45 PENERAPAN DATA MINING UNTUK MEMBENTUK KELOMPOK BELAJAR MENGGUNAKAN METODE CLUSTERING DI SMPN 19 BANDUNG Andre Catur Prasetyo Teknik Informatika Universitas
Jurnal Ilmiah Komputer dan Informatika (KOMPUTA) 45 PENERAPAN DATA MINING UNTUK MEMBENTUK KELOMPOK BELAJAR MENGGUNAKAN METODE CLUSTERING DI SMPN 19 BANDUNG Andre Catur Prasetyo Teknik Informatika Universitas
BAB II LANDASAN TEORI. Teori teori yang digunakan sebagai landasan dalam desain dan. implementasi dari sistem ini adalah sebagai berikut :
 BAB II LANDASAN TEORI Teori teori yang digunakan sebagai landasan dalam desain dan implementasi dari sistem ini adalah sebagai berikut : 2.1. Sistem Informasi Manajemen Sistem Informasi Manajemen adalah
BAB II LANDASAN TEORI Teori teori yang digunakan sebagai landasan dalam desain dan implementasi dari sistem ini adalah sebagai berikut : 2.1. Sistem Informasi Manajemen Sistem Informasi Manajemen adalah
ANALISIS PEUBAH GANDA ANALISIS GEROMBOL HAZMIRA YOZZA JURUSAN MATEMATIKA UNAND LOGO
 ANALISIS PEUBAH GANDA ANALISIS GEROMBOL HAZMIRA YOZZA JURUSAN MATEMATIKA UNAND Kompetensi menghitung jarak antar individu Membentuk gerombol dengan menggunakan metode gerombol berhierarkhi Membentuk gerombol
ANALISIS PEUBAH GANDA ANALISIS GEROMBOL HAZMIRA YOZZA JURUSAN MATEMATIKA UNAND Kompetensi menghitung jarak antar individu Membentuk gerombol dengan menggunakan metode gerombol berhierarkhi Membentuk gerombol
1.2 Rumusan Masalah 1.3 Batasan Masalah 1.4 Tujuan Penelitian
 Penerapan Data Mining dengan Menggunakan Metode Clustering K-Mean Untuk Mengukur Tingkat Ketepatan Kelulusan Mahasiswa Program Teknik Informatika S1 Fakultas Ilmu Komputer Universitas Dian Nuswantoro Semarang
Penerapan Data Mining dengan Menggunakan Metode Clustering K-Mean Untuk Mengukur Tingkat Ketepatan Kelulusan Mahasiswa Program Teknik Informatika S1 Fakultas Ilmu Komputer Universitas Dian Nuswantoro Semarang
Nandang Arif Saefuloh, M.Pd. *) Universitas Islam Nusantara, Jl. Soekarno-Hatta No. 530, Bandung, Abstrak
 Universitas Islam Nusantara, Jl. Soekarno-Hatta No. 530, Bandung, Abstrak") Jurnal Euclid, vol.3, No.1, p.502 ANALISIS KORESPONDENSI, ALTERNATIF UJI STATISTIK PENELITIAN (Hubungan Tingkat Pendidikan dan Penghasilan Orangtua dengan Nilai Raport Matematika Siswa) Nandang Arif Saefuloh,
Jurnal Euclid, vol.3, No.1, p.502 ANALISIS KORESPONDENSI, ALTERNATIF UJI STATISTIK PENELITIAN (Hubungan Tingkat Pendidikan dan Penghasilan Orangtua dengan Nilai Raport Matematika Siswa) Nandang Arif Saefuloh,
IMPLEMENTASI METODE KLASTERING K-MEANS UNTUK MENGELOMPOKAN HASIL EVALUASI MAHASISWA. FEBRIZAL ALFARASY SYAM Dosen STMIK Dharmapala Riau ABSTRAK
 Jurnal Ilmu Komputer dan Bisnis, Volume 8, Nomor 1, Mei 017 IMPLEMENTASI METODE KLASTERING K-MEANS UNTUK MENGELOMPOKAN HASIL EVALUASI MAHASISWA FEBRIZAL ALFARASY SYAM Dosen STMIK Dharmapala Riau ABSTRAK
Jurnal Ilmu Komputer dan Bisnis, Volume 8, Nomor 1, Mei 017 IMPLEMENTASI METODE KLASTERING K-MEANS UNTUK MENGELOMPOKAN HASIL EVALUASI MAHASISWA FEBRIZAL ALFARASY SYAM Dosen STMIK Dharmapala Riau ABSTRAK
BAB III K-MEDIANS CLUSTERING
 BAB III 3.1 ANALISIS KLASTER Analisis klaster merupakan salah satu teknik multivariat metode interdependensi (saling ketergantungan). Metode interdependensi berfungsi untuk memberikan makna terhadap seperangkat
BAB III 3.1 ANALISIS KLASTER Analisis klaster merupakan salah satu teknik multivariat metode interdependensi (saling ketergantungan). Metode interdependensi berfungsi untuk memberikan makna terhadap seperangkat
METODE CLUSTERING DENGAN ALGORITMA K-MEANS. Oleh : Nengah Widya Utami
 METODE CLUSTERING DENGAN ALGORITMA K-MEANS Oleh : Nengah Widya Utami 1629101002 PROGRAM STUDI S2 ILMU KOMPUTER PROGRAM PASCASARJANA UNIVERSITAS PENDIDIKAN GANESHA SINGARAJA 2017 1. Definisi Clustering
METODE CLUSTERING DENGAN ALGORITMA K-MEANS Oleh : Nengah Widya Utami 1629101002 PROGRAM STUDI S2 ILMU KOMPUTER PROGRAM PASCASARJANA UNIVERSITAS PENDIDIKAN GANESHA SINGARAJA 2017 1. Definisi Clustering
KLASTERISASI PROSES SELEKSI PEMAIN MENGGUNAKAN ALGORITMA K-MEANS
 1 KLASTERISASI PROSES SELEKSI PEMAIN MENGGUNAKAN ALGORITMA K-MEANS (Study Kasus : Tim Hockey Kabupaten Kendal) Alith Fajar Muhammad Jurusan Teknik Informatika FIK UDINUS, Jl. Nakula No. 5-11 Semarang-50131
1 KLASTERISASI PROSES SELEKSI PEMAIN MENGGUNAKAN ALGORITMA K-MEANS (Study Kasus : Tim Hockey Kabupaten Kendal) Alith Fajar Muhammad Jurusan Teknik Informatika FIK UDINUS, Jl. Nakula No. 5-11 Semarang-50131
PENERAPAN DATA MINING UNTUK EVALUASI KINERJA AKADEMIK MAHASISWA MENGGUNAKAN ALGORITMA NAÏVE BAYES CLASSIFIER
 PENERAPAN DATA MINING UNTUK EVALUASI KINERJA AKADEMIK MAHASISWA MENGGUNAKAN ALGORITMA NAÏVE BAYES CLASSIFIER I. PENDAHULUAN Mahasiswa merupakan salah satu aspek penting dalam evaluasi keberhasilan penyelenggaraan
PENERAPAN DATA MINING UNTUK EVALUASI KINERJA AKADEMIK MAHASISWA MENGGUNAKAN ALGORITMA NAÏVE BAYES CLASSIFIER I. PENDAHULUAN Mahasiswa merupakan salah satu aspek penting dalam evaluasi keberhasilan penyelenggaraan
BAB I PENDAHULUAN. Saat ini, konsep data mining semakin dikenal sebagai tools penting dalam
 BAB I PENDAHULUAN 1.1 LATAR BELAKANG Saat ini, konsep data mining semakin dikenal sebagai tools penting dalam manajemen informasi karena jumlah informasi yang semakin besar jumlahnya. Data mining sendiri
BAB I PENDAHULUAN 1.1 LATAR BELAKANG Saat ini, konsep data mining semakin dikenal sebagai tools penting dalam manajemen informasi karena jumlah informasi yang semakin besar jumlahnya. Data mining sendiri
BAB II LANDASAN TEORI
 BAB II LANDASAN TEORI 1.1 Data Mining Data mining adalah proses yang menggunakan teknik statistik, matematika, kecerdasan buatan, dan machine learning untuk mengekstrasi dan mengidentifikasi informasi
BAB II LANDASAN TEORI 1.1 Data Mining Data mining adalah proses yang menggunakan teknik statistik, matematika, kecerdasan buatan, dan machine learning untuk mengekstrasi dan mengidentifikasi informasi
BAB II TINJAUAN PUSTAKA
 BAB II TINJAUAN PUSTAKA 2.1. Data Mining Dengan perkembangan pesat teknologi informasi termasuk diantaranya teknologi pengelolaan data, penyimpanan data, pengambilan data disertai kebutuhan pengambilan
BAB II TINJAUAN PUSTAKA 2.1. Data Mining Dengan perkembangan pesat teknologi informasi termasuk diantaranya teknologi pengelolaan data, penyimpanan data, pengambilan data disertai kebutuhan pengambilan
BAB II TINJAUAN PUSTAKA Indeks Prestasi Kumulatif dan Lama Studi. menggunakan dokumen/format resmi hasil penilaian studi mahasiswa yang sudah
 BAB II TINJAUAN PUSTAKA 2.1 Landasan Teori 2.1.1 Indeks Prestasi Kumulatif dan Lama Studi Mahasiswa yang telah menyelesaikan keseluruhan beban program studi yang telah ditetapkan dapat dipertimbangkan
BAB II TINJAUAN PUSTAKA 2.1 Landasan Teori 2.1.1 Indeks Prestasi Kumulatif dan Lama Studi Mahasiswa yang telah menyelesaikan keseluruhan beban program studi yang telah ditetapkan dapat dipertimbangkan