Surmayanti 1, Hari Marfalino 2, Ade Rahmi 3 Fakultas Limu Komputer Universitas Putra Indonesia YPTK Padang
|
|
|
- Devi Pranata
- 6 tahun lalu
- Tontonan:
Transkripsi
1 PENERAPAN ANALYSIS CLUSTERING PADA PENJUALAN KOMPUTER DENGAN PERANCANGANAN APLIKASI DATA MINING MENGGUNAKAN ALGORITMA K-MEANS (STUDY KASUS TOKO TRI BUANA KOMPUTER KOTA SOLOK) Surmayanti 1, Hari Marfalino 2, Ade Rahmi 3 Fakultas Limu Komputer Universitas Putra Indonesia YPTK Padang Surmayanti@yahoo.co.id, hari.marfalino@yahoo.co.id, Dhecacute@ymail.com Abstrak - Clustering merupakan salah satu metode Data Mining yang bersifat tanpa arahan (unsupervised), dan K-Means merupakan salah satu metode data Clustering non hirarki yang berusaha mempartisi data yang ada ke dalam bentuk satu atau lebih cluster/kelompok. Tujuan pembuatan aplikasi ini yaitumemberi informasi yang terkandung dari suatu data, sehingga usermendapatkan informasi yang belum didapatkandari data tersebut. Berdasarkan hasil uji coba,cepat atau lambatnya proses pengelompokan data (Clustering) dipengaruhi oleh spesifikasi suatu perangkat keras yang menjalankan aplikasi ini, operating sistem yang digunakan dan banyaknya data atau pembagiankelompok dari suatu data. Kata kunci : Clustering, K-Means, Informasi Clustering is one of data mining method without a trait (unsupervised), and K-Means is a kind of non hierarchical Clustering method that try to partition existing data into a kind or more cluster / group. The aim of this application is to provide information contained in a data, so user could get the information that hasn t been obtained from these data previously. Based on the test result, the speed of data clustrering depends on, a specification of a hardware device and operating system that performed the application and also the amount of data or the distribution of a data. Key Words : Clustering, K-Means, Information l. PENDAHULUAN Latar Belakang Dengan kemajuan teknologi informasi dewasa ini, kebutuhan akan informasi yang akurat sangat dibutuhkan dalam kehidupan sehari-hari, sehingga informasi akan menjadi suatu elemen penting dalam perkembangan masyarakat saat ini dan waktu mendatang. Namun kebutuhan informasi yang tinggi kadang tidak diimbangi dengan penyajian informasi yang memadai, sering kali informasi tersebut masih harus digali ulang dari data yang jumlahnya sangat besar. Toko Tri Buwana Komputer merupakan toko yang bergerak dalam penjualan computer. Dalam rangka menghadapi persaingan bisnis terdapat beberapa permasalahan yang kerap muncul mengenai penjualan laptop. Toko Tri Buwana Computer sulit mendapatkan informasi-informasi strategis seperti tingkat penjualan per periode. Ketersediaan data penjualan yang besar DI Toko Tri Buwana Computer tidak digunakan Universitas Putra Indonesia YPTK Padang 50
2 semaksimal mungkin, sehingga data penjualan tersebut tidak dimanfaatkan secara optimal. Berdasarkan pada latar belakang diatas maka permasalahan diatas maka permasalahan yang ada yaitu belum adanya penerapan data mining untuk mengolah data penjualan computer. Berdasarkan kebutuhan diatas penulis mencoba memberi alternatif bantuan yang diwujudkan dalam sebuah penelitian dengan judul PENERAPAN ANALYSIS CLUSTERING PADA PENJUALAN KOMPUTER DENGAN PERANCANGAN APLIKASI DATA MINING MENGGUNAKAN ALGORITMA K- MEANS (STUDY KASUS TOKO TRI BUWANA KOMPUTER KOTA SOLOK) Perumusan Masalah Berdasarkan permasalahan diatas, maka rumusan masalah yang akan dibahas dalam penelitian ini adalah sebagai berikut : 1. Bagaimanakah aplikasi data mining mengefektifkan kinerja Toko Tri Buwana Komputer yang masih cenderung lambat? 2. Bagaimana aplikasi data mining memberikan arti yang sempurna dalam pengolahan data, karena dengan pengolahan data yang baik akan mudah mengakses data yang dibutuhkan? 3. Bagaimana aplikasi data mining ini dapat membantu pihak toko dalam memprediksi tingkat penjualan laptop di Toko Tri Buwana Komputer? Hipotesa Dari rumusan diatas maka dapat dikemukakan hipotesa yaitu, dengan menganalisa data penjualan laptop pada Toko Tri Buwana Komputer diharapkan membantu pihak toko dalam menganalisa dan mengambil keputusan serta dapat mengefektifkan kinerja toko yang masih cenderung lambat. Tujuan Penelitian Penelitian ini bertujuan untuk membangun sebuah perangkat lunak untuk memprediksi presentase suatu produk laptop, dimana perangkat lunak ini dapat mudah dioperasikan dan dipahami oleh pihak toko Tri Buwana Computer dalam menganalisa dan mengambil keputusan serta dapat mengoptimalkan dan mengefektifkan kinerja toko tersebut. 2. LANDASAN TEORI Data mining adalah proses yang mempekerjakan satu atau lebih teknik pembelajaran komputer (machine learning) untuk menganalisis dan mengekstraksi pengetahuan (knowledge) secara otomatis ( Fajar Astuti Hermawati, 2009). Data mining adalah suatu istilah yang digunakan untuk menguraikan penemuan pengetahuan didalam database. Data mining adalah proses yang menggunakan teknik statistic, matematika, kecerdasan buatan, dan machine learning untuk mengekstraksi dan mengidentifikasi informasi yang bermanfaat dan pengetahuan yang terakit dari berbagai database besar (Turban,dkk. 2005) / (Kusrini & Luthfi,2009). Pengelompokan Data Mining Data Mining dibagi menjadi beberapa kelompok berdasarkan tugas yang dilakukan, yaitu (Larose, 2005) / (Kusrini & Luthfi,2009) : 1. Deskripsi Terkadang peneliti dan analisis secara sederhana ingin mencari cara untuk menggambarkan pola dan kecenderungan yang terdapat dalam data. Sebagai contoh, petugas pengumpulan suaramungkin tidak dapat menemukan keterangan atau fakta bahwa siapa yang tidak cukup professional akan sedikit didukung dalam pemilihan presiden. Deskripsi dari pola dan kecenderungan sering memberikan kemungkinan penjelasan untuk suatu pola atau kecenderungan. 2. Estimasi Estimasi hamper sama dengan klasifikasi, kecuali variable target estimasilebih kearah numeric dari pada ke arah kategori. Model dibangun menggunakan record lengkap yang menyediakan nilai dari variable target sebagai nilai prediksi. Selanjutnya, pada peninjauan berikutnya estimasi nilai dari variabel target dapat dibuat berdasarkan nilai variable prediksi. Sebagai contoh, akan dilakukan estimasi tekanan darah sistolik pada pasien rumah sakit berdasarkan umur pasien, jenis kelamin, berat badan, dan level sodium darah. Hubungan antara tekanan darah sistolik dan nilai variable prediksi dalam proses Universitas Putra Indonesia YPTK Padang 51
3 pembelajararn akan menghasilkan model estimasi. Model estimasi yang digunakan untuk kasus baru lainnya. 3. Prediksi Prediksi hamper sama dengan klasifikasi dan estimasi, kecuali bahwa dalam prediksi nilai dari hasil akan ada dimasa mendatang. Contoh prediksi dalam bisnis dan penelitian adalah: a. Prediksi harga beras dalam tiga bulan yang akan datang. b. Prediksi presentase kenaikan kecelakaan lalu lintas tahun depan jika batas bawah kecepatan dinaikkan Beberapa metode dan teknik yang digunakan dalam klasifikasi dan estimasi dapat pula digunakan (untuk keadaan yang tepat) untuk prediksi. 4. Klasifikasi Dalam klasifikasi, terdapat target variable kategori. Sebagai contoh, penggolongan pendapatan dapat dipisahkan dalam tiga kategori, yaitu pendapatan tinggi, pendapatan sedang, dan pendapatan rendah. Contoh lain klasifikasi dalam bisnis dan penelitian adalah: a. Menentukan apakah suatu transaksi kartu kredit merupakan transaksi yang curang atau bukan. b. Memperkirakan apakah suatu pengajuan hipotek oleh nasabah merupakan suatu kredit yang baik atau buruk. c. Mendiagnosa penyakit seorang pasien untuk mendapatkan termasuk kategori apa. 5. Pengklusteran Pengklusteran mrerupakan pengelompokan record pengamatan, atau memperhatikan atau membentuk kelas objek-objek yang memiliki kemiripan. Kluster adalah kumpulan record yang memiliki kemiripan suatu dengan yang lainnya dan memiliki ketidakmiripan dengan record dalam kluster lain. Pengklusteran berbeda dengan klasifikasi yaitu tidak adanya variable target dalam pengklusteran. Pengklusteran tidak mencoba untuk melakukan klasifikasi, mengestimasi,atau memprediksi nilai dari variable target. Akan tetapi, algoritma pengklusteran mencoba untuk melakukan pembagian terhadap keseluruhan data menjadi kelompok-kelompok yang memiliki kemiripan (homogen), yang mana kemiripan dengan record dalam kelompok lain akan bernilai minimal. Contoh pengklusteran dalam bisnis dan penelitian adalah: a. Mendapatkan kelompok-kelompok konsumen untuk target pemasaran dari suatu produkbagi perusahaan yang tidak memiliki dana pemasaran yang besar. b. Untuk tujuan auditakutasi, yaitu melakukan pemisahan terhadap prilaku financial dalam baik dan mencurigakan. c. Melakukan pengklusteran terhadap ekspresi dari gen, dalam jumlah besar. 6. Asosiasi Tugas asosisasi dalam data mining adalah menentukan atribut yang muncul dalam suatu waktu. Dalam dunia bisnis lebih umum disebut analisis keranjang belanja. Contoh asosiasi dalam penelitian adalah: a. Meneliti jumlah pelanggan dari perusahaan telekomunikasi seluler yang diharapkan untuk memberikan respon positif terhadap penawaran upgrade layanan yang diberikan. b. Menemukan barang dalam supermarket yang dibeli secara bersamaan dan barang yang tidak pernah dibeli secara bersamaan. Tantangan Dalam Data Mining Tantangan dalam data mining meliputi ( Fajar Astuti Hermawati, 2009) : 1. Scalability, yaitu besarnya ukuran basis data yang digunakan. 2. Dimensionality, yaitu banyaknya jumlah atribut dalam data yang akan diproses. 3. Complex and Heterogeneous Data, yaitu data yang kompleks dan mempunyai variasi yang beragam. 4. Data Quality, kualitas data yang akan diproses seperti data yang bersih dari noise, missing value, dsb. Universitas Putra Indonesia YPTK Padang 52
4 5. Data Ownership and Distribution, yaitu siapa yang memiliki data dan bagaimana distribusinya. 6. Privacy Preservation, yaitu menjaga kerahasiaan data yang banyak dierapkan pada data nasabah perbankan. 7. Streaming Data, yaitu aliran data itu sendiri Kemajuan Dalam Data Mining Kemajuan luar biasa yang terus berlanjut dalam bidang data mining didorong oleh beberapa factor, antara lain (Larose, 2005) / (Kusrini & Luthfi,2009). 1. Pertumbuhan yang cepat dalm kumpulan data. 2. Penyimpanan data dalam data warehouse, sehingga seluruh perusahaan memiliki akses ke dalam database yang andal. 3. Adanya peningkatan akses data melalui navigasi web dan intranet. 4. Tekanan kompetensi bisnis untuk meningkatkan penguasaan pasar dalam globalisasi ekonomi. 5. Perkembangan teknologi perangkat lunak untuk data mining (ketersediaan teknologi). 6. Perkembangan yang hebat dalam kemampuan komputasi dan pengembangan kapasitas media penyimpanan. Tahap-tahap Data Mining Istilah data mining dan knowledge discovery in database (KDD) sering kali digunakan secara bergantian unutk menjelaskan proses penggalian informasi tersembunyi dalam suatu basis data yang besar. Sebenarnya kedua istilah tersebut memiliki konsep yang berbeda,tetapi berkaitan satu sama lain. Dan salah satu tahapan dalam keseluruhan proses KDD adalah data mining. Proses KDD secara garis besar dapat dijelaskan sebagai berikut (Fayyad, 1996) / ((Kusrini & Luthfi,2009). 1. Data Selection Pemilihan (seleksi) data dari sekumpulan data operasional perlu dilakukan sebelum tahap penggalian informasi dalam KDD dimulai dari data hasil seleksi yang akan digunakan untuk proses data mining disimpan dalam suatu berkas, terpisah dari basis data operasional. 2. Pre-processing / Cleaning Sebelum proses data mining dapat dilaksanakan, perlu dilakukan proses cleaning pada data yang menjadi fokus KDD. Proses cleaning mencakup antara lain membuang duplikasi data, memeriksa data yang konsisten, dan memperbaiki kesalahan pada data, seperti kesalahan cetak (tipografi). Juga dilakukan proses enrichment, yaitu proses memperkaya data yang sudah ada. Dengan data atau informasi lain yang relevan dan diperlukan untuk KDD, seperti data atau informasi eksternal. 3. Transformation Coding adalah proses transformasi pada data yang telah dipilih sehingga data tersebut sesuai untuk proses data mining. Proses coding dalam KDD merupakan proses kreatif dan sangat tergantung kepada jenis atau pola informasi yang akan dicari dalam bisnis data. 4. Data Mining Data Mining adalah proses mencari pola atau informasi menarik dalam data terpilih dengan menggunakan teknik atau metode tertentu. Teknik, metode atau algoritma dalam data mining sangat bervariasi. Pemilihan metode atau algoritma yang tepat sangat bergantung pada tujuan dan proses KDD secara keseluruhan. 5. Interpretation/Evaluation Pola informasi yang dihasilkan dari proses data mining perlu ditampilkan dalam bentuk yang mudah dimengerti oleh pihak yang berkepentingan. Tahap ini merupakan bagian dari proses KDD yang disebut interpretation. Tahap ini mencakup pemeriksaan apakah pola atau informasi yang ditemukan bertentangan dengan fakta atau hipotesis yang ada sebelumnya. Clustering Analisa cluster yaitu menemukan kumpulan objek hingga objek-objek dalam satu kelompok sama (atau punya hubungan) dengan yang lain dan berbeda (atau tidak berhubungan) dengan objek-objek dalam kelompok lain (Fajar Astuti Hermawati,2013). Clustering adalah metode penganalisaan data, yang sering dimasukkan sebagai salah satu metode Data Mining, yang tujuannya adalah untuk mengelompokkan data dengan karakteristik yang sama ke suatu wilayah yang sama dan data dengan karakteristik yang berbeda ke wilayah yang lain. Ada beberapa pendekatan yang digunakan dalam mengembangkan metode clustering. Universitas Putra Indonesia YPTK Padang 53


5 Dua pendekatan utama adalah clustering dengan pendekatan partisi dan clustering dengan pendekatan hirarki. Clustering dengan pendekatan partisi atau sering disebut dengan partition-based clustering mengelompokkan data dengan memilah-milah data yang dianalisa ke dalam cluster-cluster yang ada. Clustering dengan pendekatan hirarki atau sering disebut dengan hierarchical clustering mengelompokkan data dengan membuat suatu hirarki berupa dendogram dimana data yang mirip akan ditempatkan pada hirarki yang berdekatan dan yang tidak pada hirarki yang berjauhan. Tujuan Clustering Ada pun tujuan dari data clustering ini adalah untuk meminimalisasikan objective function yang diset dalam proses clustering, yang pada umumnya berusaha meminimalisasikan variasi di dalam suatu cluster dan memaksimalisasikan variasi antar cluster (Jurnal Sistem dan Informatika Vol. 3, 2007). K-means Defenisi K-means K-Means merupakan salah satu metode data clustering non hirarki yang berusaha mempartisi data yang ada ke dalam bentuk satu atau lebih cluster/kelompok. Metode ini mempartisi data ke dalam cluster/kelompok sehingga data yang memiliki karakteristik yang sama dikelompokkan ke dalam satu cluster yang sama dan data yang mempunyai karakteristik yang berbeda dikelompokkan ke dalam kelompok yang lain. (Jurnal Sistem dan Informatika Vol. 3, 2007). K-means Clustering Menggunakan pendekatan partitional clustering. Tiap cluster dihubungkan dengan sebuah centroid (titik pusat). Tiap titik pusat ditempatkan ke dalam cluster dengan centroid terdekat. Jumlah cluster, K, harus ditentukan. Algoritma dasarnya sangat sederhana, yaitu (Fajar Astuti Hermawati, 2013) : 1. Pilih K titik sebagai centroid awal 2. Ulangi 3. Bentuk K cluster dengan menempatkan semua titik yang terdekat. 4. Ulangi perhitungan centroid dari tiap cluster. 5. Sampai centroid tidak berubah. 3. Analisa dan Hasil 1. Analisa Sistem Untuk analisa sistem, penulis menggunakan aturan asosiasi dimana bentuk umum dari aturan asosiasi adalah : Algoritma pengelompokkan data : a. Ambil nilai jarak tiap pusat cluster dengan data b. Cari nilai jarak terkecil c. Kelompokkan data dengan pusat cluster yang memiliki jarak terkecil. 1. Penentuan pusat cluster baru Untuk mendapatkan pusat cluster baru bisa dihitung dari rata-rata nilai anggota cluster dan pusat cluster. Pusat cluster yang baru digunakan untuk melakukan iterasi selanjutnya, jika hasil yang didapatkan belum konvergen. Proses iterasi akan berhenti jika telah memenuhi maksimum iterasi yang dimasukkan oleh user atau hasil yang dicapai sudah konvergen (pusat cluster baru sama dengan pusat cluster lama). Algoritma penentuan pusat cluster : a. Cari jumlah anggota tiap cluster b. Hitung pusat baru dengan rumus Dimana : X1, X2, X3,... Xn = anggota cluster Xp = pusat lama Dari aturan-aturan asosiasi tersebut, penulis merancang sistem dengan melakukan perhitungan terhadap data yang telah didapat. Data yang masuk dalam perhitungan, penulis menggunakan beberapa data transaksi saja sebagai sampel dari perancangan sistem. Tabel Transaksi Penjualan Universitas Putra Indonesia YPTK Padang 54
6 (19, 8). Lalu dilakukan penghitungan jarak dari sisa sampel data dengan pusat cluster yang dimisalkan dengan M(a,b), dimana a merupakan jumlah stock, dan b jumlah terjual yang diperkecil menjadi angka puluhan juta agar cara penghitungan lebih mudah. Pada tahap ini akan dilakukan proses utama yaitu segmentasi atau pengelompokkan data Penjualan Barang yang diakses dari database, yaitu sebuah metode clustering algoritma K-Means. Dari banyak data penjualan yang diperoleh, Percobaan dilakukan dengan menggunakan parameter-parameter berikut : Jumlah cluster : 2 Jumlah data : 18 Jumlah atribut : 2 Pada table dibawah ini merupakan sampel data yang digunakan untuk melakukan percobaan perhitungan manual. 1. M1 = (34,17) 2. M2 = (35,24) 3. M3 = (55,31) 4. M4 = (27, 24) 5. M5 = (36,24) 6. M6 = (31,26) 7. M7 = (14,5) 8. M8 = (25,10) 9. M9 = (13,7) 10. M10 = (27,11) 11. M11 = (23,11) 12. M12 = (19,11) 13. M13 = (14,2) 14. M14 = (45,26) 15. M15 = (23,13) 16. M16 = (16,7) 17. M17= (20,5) 18.M18 = (19,11) 2. Proses Iterasi ke-1 1. Penentuan pusat awal cluster Pusat awal cluster atau centroid didapatkan secara random, untuk penentuan awal cluster di asumsikan : Pusat Cluster 1: (37,24) Pusat Cluster 2: (19,8) 2. Perhitungan jarak pusat cluster Untuk mengukur jarak antara data dengan pusat cluster digunakan Euclidian distance, kemudian akan didapatkan matrik jarak sebagai berikut: Gambar Hasil Diagram Clustering Hitung Euclidean distance dari semua data kesetiap titik pusat pertama : Dengan cara yang sama hitung jarak titik ketitik pusat ke-2 dan kita akan mendapatkan : d Rumus euclidian distance : n 2 y x i i y 1 i x X = Pusat cluster Y = data Dari 10 data yang dijadikan sampel telah dipilih pusat awal cluster yaitu C1 (37, 24), dan C2 Universitas Putra Indonesia YPTK Padang 55



7 {M1, M2,M3,M4,M5,M6,M14}: Anggota C1 {,M7,M8,M9,M10,M11,M12,M13,M15,M16,17,M18} : Anggota C2 Kesimpulan : M1,M2,M3,M4,M5,M6,M14 merupakan anggota dari cluster 1 dan M7,M8,M9,M10,M11,M12,M15,M16,M17,M 18 merupakan anggota dari cluster Proses Iterasi ke-2 1. Hitung titik pusat baru Tentukan posisi centroid baru (Ck ) dengan cara menghitung nilai rata-rata dari data-data yang ada pada centroid yang sama. C 1 nk k d1 Dari hasil penghitungan Euclidean distance, kita dapat membandingkan : Dimana nk adalah jumlah dokumen dalam cluster k dan di adalah dokumen dalam cluster k. Antara C1 dan C2, C1 menerangkan barang yang tidak laris sedangkan C2 menerangkan barang yang laris. Disini penulis hanya mengambil dua cluster karena penulis ingin membatasinya. Tabel Hasil Iterasi 1 Universitas Putra Indonesia YPTK Padang 56
 Sehingga didapatkan titik pusat atau centroid yang baru yaitu : C1= (37,5, 24,5) C2= (19,3, 8,4) 2.")

8 C1, (263 / 7 ),(172 / 7 ) (37.5,24.5) C2, (213 /11 ),(93 /11 ) (19.3,8.4) Sehingga didapatkan titik pusat atau centroid yang baru yaitu : C1= (37,5, 24,5) C2= (19,3, 8,4) 2. Perhitungan jarak pusat cluster Hitung Euclidean distance dari semua data ketitik pusat yang baru (C1, C2) seperti yang telah dilakukan pada tahap 1. Setelah hasil perhitungan kita dapatkan, kemudian bandingkan hasil tersebut. Jika hasil posisi cluster pada iterasi ke 2 sama dengan posisi iterasi pertama, maka proses dihentikan, namun jika tidak proses dilanjutkan ke iterasi ke 3. Dengan cara yang sama hitung jarak tiap titik ketitik pusat baru ke-2 dan kita akan mendapatkan : Tabel Hasil Iterasi 2 Karena pada Iterasi ke-2 posisi cluster tidak berubah/sama dengan posisi cluster pada iterasi pertama maka proses iterasi dihentikan. {M1, M2,M3,M4,M5,M6,M14} : Anggota C1 Universitas Putra Indonesia YPTK Padang 57

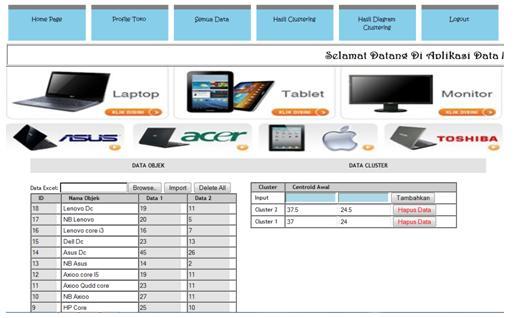
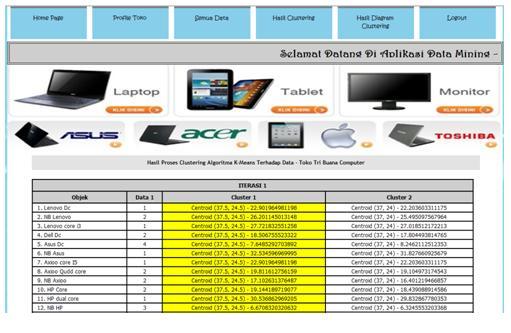

9 {,M7,M8,M9,M10,M11,M12,M13,M15,M16,17,M18} : Anggota C2 Kesimpulan : M1,M2,M3,M4,M5,M6,M14 merupakan anggota dari cluster 1 dan M7,M8,M9,M10,M11,M12,M15,M16,M17,M 18 merupakan anggota dari cluster PENGUJIAN 1. Tampilan Home 4. Tampilan Hasil Clustering 2. Tampilan Profil 5. Tampilan Hasil Diagram Clustering 3. Tampilan Semua Data Universitas Putra Indonesia YPTK Padang 58
10 5. PENUTUP Kesimpulan Dari penulisan penelitian ini mulai dari tahapan analisa permasalahan yang ada, hingga pengujian aplikasi sistem yang baru maka dapat diambil beberapa kesimpulan yaitu : 1. Aplikasi data mining ini dapat membantu pimpinan untuk mengambil keputusan dalam meningkatkan efektifitas penjualan laptop di toko Tri Buana Computer yang sebelumnya masih cenderung lambat. 2. Aplikasi data mining memberikan kemudahan dalam pengolahan data, pimpinan hanya menginputkan data lalu aplikasi akan melakukan proses dan melakukan hasil analisa. 3. Dari hasil analisa yang telah dilakukan maka aplikasi dapat membantu mempermudah pihak toko dalam memprediksi tingkat penjualan. Dari hasil analisis yang dilakukan, sistem yang dirancang masih memiliki keterbatasan yaitu, aplikasi data mining ini pada intinya hanya bisa memberikan informasi kepada pimpinan untuk menganalisa dan mengambil keputusan terhadap proses analisa barang DAFTAR PUSTAKA Hermawati, Fajar Astuti.2013, Data Mining, Bandung : Dunia Koputer. Kusrini, Emha Taufiq Lutfhi, 2011 Algoritma Data Mining. Bandung : Andi Publisher. Oktavian, Diar Puji, Komputerpedia Membuat Website Powerfull Menggunakan PHP. Yogyakarta: MEDIA KOM Sommerville, Ian, 2013, Software Enginering. Jakarta : Erlangga. S, Rosa A. dan M Shalahuddin, Rekayasa Perangkat Lunak Terstruktur dan Berorientasi Objek. Bandung : Informatika Universitas Putra Indonesia YPTK Padang 59
BAB II TINJAUAN PUSTAKA
 BAB II TINJAUAN PUSTAKA 2.1 Landasan Teori 2.1.1 Konsep Pemasaran Dalam merancang dan mengembangkan produk, baik yang berupa jasa maupun barang, tidak terlepas dari konsep pemasaran yang bertujuan memenuhi
BAB II TINJAUAN PUSTAKA 2.1 Landasan Teori 2.1.1 Konsep Pemasaran Dalam merancang dan mengembangkan produk, baik yang berupa jasa maupun barang, tidak terlepas dari konsep pemasaran yang bertujuan memenuhi
BAB II TINJAUAN PUSTAKA. pengetahuan di dalam database. Data mining adalah proses yang menggunakan
 6 BAB II TINJAUAN PUSTAKA 2.1 Pengertian Data Mining Data mining adalah suatu istilah yang digunakan untuk menguraikan penemuan pengetahuan di dalam database. Data mining adalah proses yang menggunakan
6 BAB II TINJAUAN PUSTAKA 2.1 Pengertian Data Mining Data mining adalah suatu istilah yang digunakan untuk menguraikan penemuan pengetahuan di dalam database. Data mining adalah proses yang menggunakan
STMIK GI MDP. Program Studi Teknik Informatika Skripsi Sarjana Komputer Semester Ganjil Tahun 2011/2012
 Program Studi Teknik Informatika Skripsi Sarjana Komputer Semester Ganjil Tahun 2011/2012 CLUSTERING DATA PENJUALAN DAN PERSEDIAAN BARANG PADA PT SAYAP MAS UTAMA DENGAN METODE K-MEANS Ahmad Afif 2008250031
Program Studi Teknik Informatika Skripsi Sarjana Komputer Semester Ganjil Tahun 2011/2012 CLUSTERING DATA PENJUALAN DAN PERSEDIAAN BARANG PADA PT SAYAP MAS UTAMA DENGAN METODE K-MEANS Ahmad Afif 2008250031
BAB II LANDASAN TEORI
 BAB II LANDASAN TEORI 2.1 Data Mining Faktor penentu bagi usaha atau bisnis apapun pada masa sekarang ini adalah kemampuan untuk menggunakan informasi seefektif mungkin. Penggunaan data secara tepat karena
BAB II LANDASAN TEORI 2.1 Data Mining Faktor penentu bagi usaha atau bisnis apapun pada masa sekarang ini adalah kemampuan untuk menggunakan informasi seefektif mungkin. Penggunaan data secara tepat karena
BAB II TINJAUAN PUSTAKA
 BAB II TINJAUAN PUSTAKA 2.1 Dasar Teori 2.1.1 Data Mining Data mining adalah suatu istilah yang digunakan untuk menguraikan penemuan pengetahuan di dalam database. Data mining adalah Proses yang menggunakan
BAB II TINJAUAN PUSTAKA 2.1 Dasar Teori 2.1.1 Data Mining Data mining adalah suatu istilah yang digunakan untuk menguraikan penemuan pengetahuan di dalam database. Data mining adalah Proses yang menggunakan
PERTEMUAN 14 DATA WAREHOUSE
 PERTEMUAN 14 DATA WAREHOUSE Data Warehouse Definisi : Data Warehouse adalah Pusat repositori informasi yang mampu memberikan database berorientasi subyek untuk informasi yang bersifat historis yang mendukung
PERTEMUAN 14 DATA WAREHOUSE Data Warehouse Definisi : Data Warehouse adalah Pusat repositori informasi yang mampu memberikan database berorientasi subyek untuk informasi yang bersifat historis yang mendukung
BAB 1 KONSEP DATA MINING 2 Gambar 1.1 Perkembangan Database Permasalahannya kemudian adalah apa yang harus dilakukan dengan data-data itu. Sudah diket
 Bab1 Konsep Data Mining POKOK BAHASAN: Konsep dasar dan pengertian Data Mining Tahapan dalam Data Mining Model Data Mining Fungsi Data Mining TUJUAN BELAJAR: Setelah mempelajari materi dalam bab ini, mahasiswa
Bab1 Konsep Data Mining POKOK BAHASAN: Konsep dasar dan pengertian Data Mining Tahapan dalam Data Mining Model Data Mining Fungsi Data Mining TUJUAN BELAJAR: Setelah mempelajari materi dalam bab ini, mahasiswa
BAB II TINJAUAN PUSTAKA DAN LANDASAN TEORI. menerapkan metode clustering dengan algoritma K-Means untuk penelitiannya.
 BAB II TINJAUAN PUSTAKA DAN LANDASAN TEORI 2.1 Tinjauan Pustaka Salah satu cara untuk mengetahui faktor nilai cumlaude mahasiswa Fakultas Teknik Universitas Muhammadiyah Yogyakarta adalah dengan menerapkan
BAB II TINJAUAN PUSTAKA DAN LANDASAN TEORI 2.1 Tinjauan Pustaka Salah satu cara untuk mengetahui faktor nilai cumlaude mahasiswa Fakultas Teknik Universitas Muhammadiyah Yogyakarta adalah dengan menerapkan
BAB 2 LANDASAN TEORI
 7 BAB 2 LANDASAN TEORI Bab ini membahas tentang teori penunjang dan penelitian sebelumnya yang berhubungan dengan penerapan algoritma hierarchical clustering dan k-means untuk pengelompokan desa tertinggal.
7 BAB 2 LANDASAN TEORI Bab ini membahas tentang teori penunjang dan penelitian sebelumnya yang berhubungan dengan penerapan algoritma hierarchical clustering dan k-means untuk pengelompokan desa tertinggal.
BAB II LANDASAN TEORI
 BAB II LANDASAN TEORI 2.1 Data Mining Secara sederhana data mining adalah penambangan atau penemuan informasi baru dengan mencari pola atau aturan tertentu dari sejumlah data yang sangat besar. Data mining
BAB II LANDASAN TEORI 2.1 Data Mining Secara sederhana data mining adalah penambangan atau penemuan informasi baru dengan mencari pola atau aturan tertentu dari sejumlah data yang sangat besar. Data mining
DATA MINING DENGAN TEKNIK CLUSTERING UNTUK MENGGALI INFORMASI TENTANG BIMBINGAN KONSELING SISWA (STUDI KASUS : SMA NEGERI 1 X KOTO SINGKARAK)
") Jurnal Ilmiah Fakultas Teknik LIMIT S Vol.13 No 1 Maret 2017 38 DATA MINING DENGAN TEKNIK CLUSTERING UNTUK MENGGALI INFORMASI TENTANG BIMBINGAN KONSELING SISWA (STUDI KASUS : SMA NEGERI 1 X KOTO SINGKARAK)
Jurnal Ilmiah Fakultas Teknik LIMIT S Vol.13 No 1 Maret 2017 38 DATA MINING DENGAN TEKNIK CLUSTERING UNTUK MENGGALI INFORMASI TENTANG BIMBINGAN KONSELING SISWA (STUDI KASUS : SMA NEGERI 1 X KOTO SINGKARAK)
Universitas Putra Indonesia YPTK Padang Fakulas Ilmu Komputer Program Studi Teknik Informatika. Knowledge Discovery in Databases (KDD)
") Universitas Putra Indonesia YPTK Padang Fakulas Ilmu Komputer Program Studi Teknik Informatika Knowledge Discovery in Databases (KDD) Knowledge Discovery in Databases (KDD) Definisi Knowledge Discovery
Universitas Putra Indonesia YPTK Padang Fakulas Ilmu Komputer Program Studi Teknik Informatika Knowledge Discovery in Databases (KDD) Knowledge Discovery in Databases (KDD) Definisi Knowledge Discovery
BAB 2 LANDASAN TEORI
 BAB 2 LANDASAN TEORI Bab ini membahas tentang teori penunjang dan penelitian sebelumnya yang berhubungan dengan analisa datadan algoritma Fuzzy C-Means untuk mangetahui pola perilaku konsumen. 2.1. Pola
BAB 2 LANDASAN TEORI Bab ini membahas tentang teori penunjang dan penelitian sebelumnya yang berhubungan dengan analisa datadan algoritma Fuzzy C-Means untuk mangetahui pola perilaku konsumen. 2.1. Pola
Data Mining : Klasifikasi Menggunakan Algoritma C4.5
 Data Mining : Klasifikasi Menggunakan Algoritma C4.5 Yuli Mardi Dosen Akademi Perekam dan Informasi Kesehatan (APIKES) Iris Padang Jl. Gajah Mada No. 23 Padang, Sumatera Barat adimardi@yahoo.com ABSTRAK
Data Mining : Klasifikasi Menggunakan Algoritma C4.5 Yuli Mardi Dosen Akademi Perekam dan Informasi Kesehatan (APIKES) Iris Padang Jl. Gajah Mada No. 23 Padang, Sumatera Barat adimardi@yahoo.com ABSTRAK
Timor Setiyaningsih, Nur Syamsiah Teknik Informatika Universitas Darma Persada. Abstrak
 DATA MINING MELIHAT POLA HUBUNGAN NILAI TES MASUK MAHASISWA TERHADAP DATA KELULUSAN MAHASISWA UNTUK MEMBANTU PERGURUAN TINGGI DALAM MENGAMBIL KEBIJAKAN DALAM RANGKA PENINGKATAN MUTU PERGURUAN TINGGI Timor
DATA MINING MELIHAT POLA HUBUNGAN NILAI TES MASUK MAHASISWA TERHADAP DATA KELULUSAN MAHASISWA UNTUK MEMBANTU PERGURUAN TINGGI DALAM MENGAMBIL KEBIJAKAN DALAM RANGKA PENINGKATAN MUTU PERGURUAN TINGGI Timor
PENINGKATAN PERFORMA ALGORITMA APRIORI UNTUK ATURAN ASOSIASI DATA MINING
 PENINGKATAN PERFORMA ALGORITMA APRIORI UNTUK ATURAN ASOSIASI DATA MINING Andreas Chandra Teknik Informatika STMIK AMIKOM Yogyakarta Jl Ring road Utara, Condongcatur, Sleman, Yogyakarta 55281 Email : andreaschaandra@yahoo.com
PENINGKATAN PERFORMA ALGORITMA APRIORI UNTUK ATURAN ASOSIASI DATA MINING Andreas Chandra Teknik Informatika STMIK AMIKOM Yogyakarta Jl Ring road Utara, Condongcatur, Sleman, Yogyakarta 55281 Email : andreaschaandra@yahoo.com
BAB II LANDASAN TEORI. yang terdiri dari komponen-komponen atau sub sistem yang berorientasi untuk
 BAB II LANDASAN TEORI 2.1 Sistem Menurut Gondodiyoto (2007), sistem adalah merupakan suatu kesatuan yang terdiri dari komponen-komponen atau sub sistem yang berorientasi untuk mencapai suatu tujuan tertentu.
BAB II LANDASAN TEORI 2.1 Sistem Menurut Gondodiyoto (2007), sistem adalah merupakan suatu kesatuan yang terdiri dari komponen-komponen atau sub sistem yang berorientasi untuk mencapai suatu tujuan tertentu.
TAKARIR. : Mengelompokkan suatu objek yang memiliki kesamaan. : Kelompok atau kelas
 TAKARIR Data Mining Clustering Cluster Iteratif Random Centroid : Penggalian data : Mengelompokkan suatu objek yang memiliki kesamaan. : Kelompok atau kelas : Berulang : Acak : Pusat area KDD (Knowledge
TAKARIR Data Mining Clustering Cluster Iteratif Random Centroid : Penggalian data : Mengelompokkan suatu objek yang memiliki kesamaan. : Kelompok atau kelas : Berulang : Acak : Pusat area KDD (Knowledge
IMPLEMENTASI ALGORITMA K-NEAREST NEIGHBOUR UNTUK PREDIKSI WAKTU KELULUSAN MAHASISWA
 IMPLEMENTASI ALGORITMA K-NEAREST NEIGHBOUR UNTUK PREDIKSI WAKTU KELULUSAN MAHASISWA Irwan Budiman 1, Dodon Turianto Nugrahadi 2, Radityo Adi Nugroho 3 Universitas Lambung Mangkurat 1,2,3 irwan.budiman@unlam.ac.id
IMPLEMENTASI ALGORITMA K-NEAREST NEIGHBOUR UNTUK PREDIKSI WAKTU KELULUSAN MAHASISWA Irwan Budiman 1, Dodon Turianto Nugrahadi 2, Radityo Adi Nugroho 3 Universitas Lambung Mangkurat 1,2,3 irwan.budiman@unlam.ac.id
BAB II LANDASAN TEORI
 BAB II LANDASAN TEORI 2.1. Pendahuluan Didalam bab ini menceritakan semua teori-teori yang digunakan didalam proses algoritma decision tree, algoritma Random tree dan Random Florest serta teoriteori dan
BAB II LANDASAN TEORI 2.1. Pendahuluan Didalam bab ini menceritakan semua teori-teori yang digunakan didalam proses algoritma decision tree, algoritma Random tree dan Random Florest serta teoriteori dan
PENERAPAN ALGORITMA C4.5 DALAM PEMILIHAN BIDANG PEMINATAN PROGRAM STUDI SISTEM INFORMASI DI STMIK POTENSI UTAMA MEDAN
 PENERAPAN ALGORITMA C4.5 DALAM PEMILIHAN BIDANG PEMINATAN PROGRAM STUDI SISTEM INFORMASI DI STMIK POTENSI UTAMA MEDAN Fina Nasari 1 1 Sistem Informasi, STMIK Potensi Utama 3 Jalan K.L. Yos Sudarso KM.
PENERAPAN ALGORITMA C4.5 DALAM PEMILIHAN BIDANG PEMINATAN PROGRAM STUDI SISTEM INFORMASI DI STMIK POTENSI UTAMA MEDAN Fina Nasari 1 1 Sistem Informasi, STMIK Potensi Utama 3 Jalan K.L. Yos Sudarso KM.
DESAIN APLIKASI UNTUK MENAMPILKAN INFORMASI TINGKAT KELULUSAN MAHASISWA. Oleh : Rita Prima Bendriyanti ABSTRAK
 DESAIN APLIKASI UNTUK MENAMPILKAN INFORMASI TINGKAT KELULUSAN MAHASISWA Oleh : Rita Prima Bendriyanti ABSTRAK Penelitian ini menggunakan metode observasi, dengan melihat atau mengamati secara langsung
DESAIN APLIKASI UNTUK MENAMPILKAN INFORMASI TINGKAT KELULUSAN MAHASISWA Oleh : Rita Prima Bendriyanti ABSTRAK Penelitian ini menggunakan metode observasi, dengan melihat atau mengamati secara langsung
BAB 2 TINJAUAN PUSTAKA DAN DASAR TEORI. yang akan diteliti. Pemanfaatan algoritma apriori sudah cukup banyak digunakan, antara lain
 BAB 2 TINJAUAN PUSTAKA DAN DASAR TEORI 2.1 Tinjauan Pustaka Penelitian ini menggunakan beberapa sumber pustaka yang berhubungan dengan kasus yang akan diteliti. Pemanfaatan algoritma apriori sudah cukup
BAB 2 TINJAUAN PUSTAKA DAN DASAR TEORI 2.1 Tinjauan Pustaka Penelitian ini menggunakan beberapa sumber pustaka yang berhubungan dengan kasus yang akan diteliti. Pemanfaatan algoritma apriori sudah cukup
 BAB 1. PENDAHULUAN 1.1. Latar Belakang Pelanggan merupakan salah satu posisi penting dalam pengembangan strategi bisnis, pelanggan juga merupakan salah satu sumber keuntungan dalam perusahaan. Untuk itu
BAB 1. PENDAHULUAN 1.1. Latar Belakang Pelanggan merupakan salah satu posisi penting dalam pengembangan strategi bisnis, pelanggan juga merupakan salah satu sumber keuntungan dalam perusahaan. Untuk itu
PENERAPAN ALGORITMA K-MEANS UNTUK CLUSTERING DATA ANGGARAN PENDAPATAN BELANJA DAERAH DI KABUPATEN XYZ
 PENERAPAN ALGORITMA K-MEANS UNTUK CLUSTERING DATA ANGGARAN PENDAPATAN BELANJA DAERAH DI KABUPATEN XYZ SKRIPSI Diajukan untuk memenuhi salah satu syarat memperoleh Gelar Sarjana pada Program Studi Sistem
PENERAPAN ALGORITMA K-MEANS UNTUK CLUSTERING DATA ANGGARAN PENDAPATAN BELANJA DAERAH DI KABUPATEN XYZ SKRIPSI Diajukan untuk memenuhi salah satu syarat memperoleh Gelar Sarjana pada Program Studi Sistem
PENERAPAN ALGORITMA K-MEANS PADA KUALITAS GIZI BAYI DI INDONESIA
 PENERAPAN ALGORITMA K-MEANS PADA KUALITAS GIZI BAYI DI INDONESIA Diajeng Tyas Purwa Hapsari Teknik Informatika STMIK AMIKOM Yogyakarta Jl Ring road Utara, Condongcatur, Sleman, Yogyakarta 55281 Email :
PENERAPAN ALGORITMA K-MEANS PADA KUALITAS GIZI BAYI DI INDONESIA Diajeng Tyas Purwa Hapsari Teknik Informatika STMIK AMIKOM Yogyakarta Jl Ring road Utara, Condongcatur, Sleman, Yogyakarta 55281 Email :
Abidah Elcholiqi, Beta Noranita, Indra Waspada
 Abidah Elcholiqi, Beta Noranita, Indra Waspada PENENTUAN BESAR PINJAMAN DI KOPERASI SIMPAN PINJAM DENGAN ALGORITMA K-NEAREST NEIGHBOR (Studi Kasus di Koperasi Simpan Pinjam BMT Bina Insani Pringapus) Abidah
Abidah Elcholiqi, Beta Noranita, Indra Waspada PENENTUAN BESAR PINJAMAN DI KOPERASI SIMPAN PINJAM DENGAN ALGORITMA K-NEAREST NEIGHBOR (Studi Kasus di Koperasi Simpan Pinjam BMT Bina Insani Pringapus) Abidah
PENERAPAN DATA MINING UNTUK MENGANALISA JUMLAH PELANGGAN AKTIF DENGAN MENGGUNAKAN ALGORITMA C4.5
 PENERAPAN DATA MINING UNTUK MENGANALISA JUMLAH PELANGGAN AKTIF DENGAN MENGGUNAKAN ALGORITMA C4.5 Annisak Izzaty Jamhur Universitas Putera Indonesia YPTK Padang e-mail: annisakizzaty@yahoo.com Abstract
PENERAPAN DATA MINING UNTUK MENGANALISA JUMLAH PELANGGAN AKTIF DENGAN MENGGUNAKAN ALGORITMA C4.5 Annisak Izzaty Jamhur Universitas Putera Indonesia YPTK Padang e-mail: annisakizzaty@yahoo.com Abstract
BAB 2 TINJAUAN PUSTAKA Klasifikasi Data Mahasiswa Menggunakan Metode K-Means Untuk Menunjang Pemilihan Strategi Pemasaran
 BAB 2 TINJAUAN PUSTAKA 2.1 Tinjauan Pustaka Beberapa penelitian terdahulu telah banyak yang menerapkan data mining, yang bertujuan dalam menyelesaikan beberapa permasalahan seputar dunia pendidikan. Khususnya
BAB 2 TINJAUAN PUSTAKA 2.1 Tinjauan Pustaka Beberapa penelitian terdahulu telah banyak yang menerapkan data mining, yang bertujuan dalam menyelesaikan beberapa permasalahan seputar dunia pendidikan. Khususnya
Klasifikasi Data Karyawan Untuk Menentukan Jadwal Kerja Menggunakan Metode Decision Tree
 Klasifikasi Data Karyawan Untuk Menentukan Jadwal Kerja Menggunakan Metode Decision Tree Disusun oleh : Budanis Dwi Meilani Achmad dan Fauzi Slamat Jurusan Sistem Informasi Fakultas Teknologi Informasi.
Klasifikasi Data Karyawan Untuk Menentukan Jadwal Kerja Menggunakan Metode Decision Tree Disusun oleh : Budanis Dwi Meilani Achmad dan Fauzi Slamat Jurusan Sistem Informasi Fakultas Teknologi Informasi.
BAB III METODOLOGI PENELITIAN
 BAB III METODOLOGI PENELITIAN Metodologi penelitian digunakan sebagai pedoman dalam pelaksanaan penelitian agar hasil yang dicapai tidak menyimpang dari tujuan yang akan dicapai. Dalam penulisan tugas
BAB III METODOLOGI PENELITIAN Metodologi penelitian digunakan sebagai pedoman dalam pelaksanaan penelitian agar hasil yang dicapai tidak menyimpang dari tujuan yang akan dicapai. Dalam penulisan tugas
ALGORITMA NEAREST NEIGHBOR UNTUK MENENTUKAN AREA PEMASARAN PRODUK BATIK DI KOTA PEKALONGAN
 ALGORITMA NEAREST NEIGHBOR UNTUK MENENTUKAN AREA PEMASARAN PRODUK BATIK DI KOTA PEKALONGAN Devi Sugianti Program Studi Sistem Informasi,STMIK Widya Pratama Jl. Patriot 25 Pekalongan Telp (0285)427816 email
ALGORITMA NEAREST NEIGHBOR UNTUK MENENTUKAN AREA PEMASARAN PRODUK BATIK DI KOTA PEKALONGAN Devi Sugianti Program Studi Sistem Informasi,STMIK Widya Pratama Jl. Patriot 25 Pekalongan Telp (0285)427816 email
Konsep Data Mining. Pendahuluan. Bertalya. Universitas Gunadarma 2009
 Konsep Data Mining Pendahuluan Bertalya Universitas Gunadarma 2009 Latar Belakang Data yg dikumpulkan semakin bertambah banyak Data web, e-commerce Data pembelian di toko2 / supermarket Transaksi Bank/Kartu
Konsep Data Mining Pendahuluan Bertalya Universitas Gunadarma 2009 Latar Belakang Data yg dikumpulkan semakin bertambah banyak Data web, e-commerce Data pembelian di toko2 / supermarket Transaksi Bank/Kartu
BAB II TINJAUAN PUSTAKA
 BAB II TINJAUAN PUSTAKA A. Knowledge Discovery in Database (KDD) dan Data Mining Banyak orang menggunakan istilah data mining dan knowledge discovery in databases (KDD) secara bergantian untuk menjelaskan
BAB II TINJAUAN PUSTAKA A. Knowledge Discovery in Database (KDD) dan Data Mining Banyak orang menggunakan istilah data mining dan knowledge discovery in databases (KDD) secara bergantian untuk menjelaskan
BAB 1 PENDAHULUAN. 1.1 Latar Belakang
 BAB 1 PENDAHULUAN 1.1 Latar Belakang Pesatnya perkembangan dunia pariwisata, tidak diiringi dengan perkembangan teknologi yang digunakan. Ditambah lagi dengan kondisi, banyak wisatawan yang tidak mau berwisata
BAB 1 PENDAHULUAN 1.1 Latar Belakang Pesatnya perkembangan dunia pariwisata, tidak diiringi dengan perkembangan teknologi yang digunakan. Ditambah lagi dengan kondisi, banyak wisatawan yang tidak mau berwisata
BAB III ANALISIS DAN PERANCANGAN SISTEM
 BAB III ANALISIS DAN PERANCANGAN SISTEM Bab ini menjelaskan tentang analisis dan perancangan dalam membangun Aplikasi Data Mining. Analisis meliputi analisis data mining, analisis lingkungan sistem serta
BAB III ANALISIS DAN PERANCANGAN SISTEM Bab ini menjelaskan tentang analisis dan perancangan dalam membangun Aplikasi Data Mining. Analisis meliputi analisis data mining, analisis lingkungan sistem serta
1.2 Rumusan Masalah 1.3 Batasan Masalah 1.4 Tujuan Penelitian
 Penerapan Data Mining dengan Menggunakan Metode Clustering K-Mean Untuk Mengukur Tingkat Ketepatan Kelulusan Mahasiswa Program Teknik Informatika S1 Fakultas Ilmu Komputer Universitas Dian Nuswantoro Semarang
Penerapan Data Mining dengan Menggunakan Metode Clustering K-Mean Untuk Mengukur Tingkat Ketepatan Kelulusan Mahasiswa Program Teknik Informatika S1 Fakultas Ilmu Komputer Universitas Dian Nuswantoro Semarang
BAB II LANDASAN TEORI
 BAB II LANDASAN TEORI 2.1 Data Mining Data Mining adalah proses yang mempekerjakan satu atau lebih teknik pembelajaran komputer (machine learning) untuk menganalisis dan mengekstraksi pengetahuan (knowledge)
BAB II LANDASAN TEORI 2.1 Data Mining Data Mining adalah proses yang mempekerjakan satu atau lebih teknik pembelajaran komputer (machine learning) untuk menganalisis dan mengekstraksi pengetahuan (knowledge)
PENGELOMPOKAN MINAT BACA MAHASISWA MENGGUNAKAN METODE K-MEANS
 Jurnal Ilmiah ILKOM Volume 8 mor (Agustus 16) ISSN: 87-1716 PENGELOMPOKAN MINAT BACA MAHASISWA MENGGUNAKAN METODE K-MEANS Widya Safira Azis 1 dan Dedy Atmajaya 1 safiraazis18@gmail.com dan dedy.atmajaya@umi.ac.id
Jurnal Ilmiah ILKOM Volume 8 mor (Agustus 16) ISSN: 87-1716 PENGELOMPOKAN MINAT BACA MAHASISWA MENGGUNAKAN METODE K-MEANS Widya Safira Azis 1 dan Dedy Atmajaya 1 safiraazis18@gmail.com dan dedy.atmajaya@umi.ac.id
Clustering Terhadap Indeks Prestasi Mahasiswa STMIK Akakom Menggunakan K-Means
 Clustering Terhadap Indeks Prestasi Mahasiswa STMIK Akakom Menggunakan K-Means Sri Redjeki Andreas 1), Andreas Pamungkas, Pamungkas Hastin 2), Hastin Al-fatah Al-fatah 3) 1)2)3) STMIK dzeky@akakom.ac.id
Clustering Terhadap Indeks Prestasi Mahasiswa STMIK Akakom Menggunakan K-Means Sri Redjeki Andreas 1), Andreas Pamungkas, Pamungkas Hastin 2), Hastin Al-fatah Al-fatah 3) 1)2)3) STMIK dzeky@akakom.ac.id
IMPLEMENTASI METODE K-MEANS PADA PENERIMAAN SISWA BARU
 PROYEK TUGAS AKHIR IMPLEMENTASI METODE K-MEANS PADA PENERIMAAN SISWA BARU (Studi Kasus : SMK Pembangunan Nasional Purwodadi) Disusun oleh: Novian Hari Pratama 10411 PROGRAM STUDI TEKNIK INFORMATIKA FAKULTAS
PROYEK TUGAS AKHIR IMPLEMENTASI METODE K-MEANS PADA PENERIMAAN SISWA BARU (Studi Kasus : SMK Pembangunan Nasional Purwodadi) Disusun oleh: Novian Hari Pratama 10411 PROGRAM STUDI TEKNIK INFORMATIKA FAKULTAS
BAB 3 LANDASAN TEORI
 BAB 3 LANDASAN TEORI 3.1. Data Mining Data mining adalah proses menganalisa data dari perspektif yang berbeda dan menyimpulkannya menjadi informasi-informasi penting yang dapat dipakai untuk meningkatkan
BAB 3 LANDASAN TEORI 3.1. Data Mining Data mining adalah proses menganalisa data dari perspektif yang berbeda dan menyimpulkannya menjadi informasi-informasi penting yang dapat dipakai untuk meningkatkan
Materi 1 DATA MINING 3 SKS Semester 6 S1 Sistem Informasi UNIKOM 2015 Nizar Rabbi Radliya
 Materi 1 DATA MINING 3 SKS Semester 6 S1 Sistem Informasi UNIKOM 2015 Nizar Rabbi Radliya nizar.radliya@yahoo.com Nama Mahasiswa NIM Kelas 1. Memahami cakupan materi dan sistem perkuliahan Data Mining.
Materi 1 DATA MINING 3 SKS Semester 6 S1 Sistem Informasi UNIKOM 2015 Nizar Rabbi Radliya nizar.radliya@yahoo.com Nama Mahasiswa NIM Kelas 1. Memahami cakupan materi dan sistem perkuliahan Data Mining.
Materi 2 DATA MINING 3 SKS Semester 6 S1 Sistem Informasi UNIKOM 2015 Nizar Rabbi Radliya
 Materi 2 DATA MINING 3 SKS Semester 6 S1 Sistem Informasi UNIKOM 2015 Nizar Rabbi Radliya nizar.radliya@yahoo.com Nama Mahasiswa NIM Kelas Memahami definisi, proses serta teknik data mining. Pengenalan
Materi 2 DATA MINING 3 SKS Semester 6 S1 Sistem Informasi UNIKOM 2015 Nizar Rabbi Radliya nizar.radliya@yahoo.com Nama Mahasiswa NIM Kelas Memahami definisi, proses serta teknik data mining. Pengenalan
PROPOSAL PENERAPAN DATA MINING UNTUK MENENTUKAN STRATEGI PENJUALAN PADA TOKO BUKU GRAMEDIA PALEMBANG MENGGUNAKAN METODE CLUSTERING
 1 PROPOSAL PENERAPAN DATA MINING UNTUK MENENTUKAN STRATEGI PENJUALAN PADA TOKO BUKU GRAMEDIA PALEMBANG MENGGUNAKAN METODE CLUSTERING I. Pendahuluan 1.1. Latar Belakang Seiring dengan pertumbuhan bisnis
1 PROPOSAL PENERAPAN DATA MINING UNTUK MENENTUKAN STRATEGI PENJUALAN PADA TOKO BUKU GRAMEDIA PALEMBANG MENGGUNAKAN METODE CLUSTERING I. Pendahuluan 1.1. Latar Belakang Seiring dengan pertumbuhan bisnis
PENERAPAN ALGORITMA K-MEANS PADA SISWA BARU SEKOLAHMENENGAH KEJURUAN UNTUK CLUSTERING JURUSAN
 PENERAPAN ALGORITMA K-MEANS PADA SISWA BARU SEKOLAHMENENGAH KEJURUAN UNTUK CLUSTERING JURUSAN Fauziah Nur1, Prof. M. Zarlis2, Dr. Benny Benyamin Nasution3 Program Studi Magister Teknik Informatika, Universitas
PENERAPAN ALGORITMA K-MEANS PADA SISWA BARU SEKOLAHMENENGAH KEJURUAN UNTUK CLUSTERING JURUSAN Fauziah Nur1, Prof. M. Zarlis2, Dr. Benny Benyamin Nasution3 Program Studi Magister Teknik Informatika, Universitas
BAB II TINJAUAN PUSTAKA
 BAB II TINJAUAN PUSTAKA 2.1 Pengertian Data Mining Data mining adalah suatu istilah yang digunakan untuk menemukan pengetahuan yang tersembunyi di dalam database. Data mining merupakan proses semi otomatik
BAB II TINJAUAN PUSTAKA 2.1 Pengertian Data Mining Data mining adalah suatu istilah yang digunakan untuk menemukan pengetahuan yang tersembunyi di dalam database. Data mining merupakan proses semi otomatik
BAB 1 PENDAHULUAN 1.1. Latar Belakang
 BAB 1 PENDAHULUAN 1.1. Latar Belakang Analisis cluster merupakan salah satu alat yang penting dalam pengolahan data statistik untuk melakukan analisis data. Analisis cluster merupakan seperangkat metodologi
BAB 1 PENDAHULUAN 1.1. Latar Belakang Analisis cluster merupakan salah satu alat yang penting dalam pengolahan data statistik untuk melakukan analisis data. Analisis cluster merupakan seperangkat metodologi
TINJAUAN PUSTAKA Data Mining
 25 TINJAUAN PUSTAKA 2.1. Data Mining Definisi sederhana dari data mining adalah ekstraksi informasi atau pola yang penting atau menarik dari data yang ada di database. Secara lengkap, Data mining merupakan
25 TINJAUAN PUSTAKA 2.1. Data Mining Definisi sederhana dari data mining adalah ekstraksi informasi atau pola yang penting atau menarik dari data yang ada di database. Secara lengkap, Data mining merupakan
BAB II TINJAUAN PUSTAKA DAN LANDASAN TEORI
 BAB II TINJAUAN PUSTAKA DAN LANDASAN TEORI penelitian. Pada bab ini akan dibahas literatur dan landasan teori yang relevan dengan 2.1 Tinjauan Pustaka Kombinasi metode telah dilakukan oleh beberapa peneliti
BAB II TINJAUAN PUSTAKA DAN LANDASAN TEORI penelitian. Pada bab ini akan dibahas literatur dan landasan teori yang relevan dengan 2.1 Tinjauan Pustaka Kombinasi metode telah dilakukan oleh beberapa peneliti
Implementasi Data Mining dengan Metode Klastering untuk Meramalkan Permintaan Pasar (Studi Kasus PT. Nutrifood Indonesia )
") Implementasi Data Mining dengan Metode Klastering untuk Meramalkan Permintaan Pasar (Studi Kasus PT. Nutrifood Indonesia ) November 20, 2010 Arimbi Kurniasari Lintang Yuniar Banowosari Alex Hutapea Manajemen
Implementasi Data Mining dengan Metode Klastering untuk Meramalkan Permintaan Pasar (Studi Kasus PT. Nutrifood Indonesia ) November 20, 2010 Arimbi Kurniasari Lintang Yuniar Banowosari Alex Hutapea Manajemen
BAB I PENDAHULUAN. pesat, ini dapat dilihat dari kemunculan berbagai aplikasi-aplikasi yang dapat
 BAB I PENDAHULUAN I.1. Latar Belakang Perkembangan teknologi perangkat lunak pada masa sekarang ini sangatlah pesat, ini dapat dilihat dari kemunculan berbagai aplikasi-aplikasi yang dapat memudahkan user
BAB I PENDAHULUAN I.1. Latar Belakang Perkembangan teknologi perangkat lunak pada masa sekarang ini sangatlah pesat, ini dapat dilihat dari kemunculan berbagai aplikasi-aplikasi yang dapat memudahkan user
BAB 2 LANDASAN TEORI
 6 BAB 2 LANDASAN TEORI Pada tinjauan pustaka ini akan dibahas tentang konsep dasar dan teori-teori yang mendukung pembahasan yang berhubungan dengan sistem yang akan dibuat. 2.1 Basis Data (Database) Database
6 BAB 2 LANDASAN TEORI Pada tinjauan pustaka ini akan dibahas tentang konsep dasar dan teori-teori yang mendukung pembahasan yang berhubungan dengan sistem yang akan dibuat. 2.1 Basis Data (Database) Database
BAB 2 PENELITIAN TERKAIT DAN LANDASAN TEORI
 BAB 2 PENELITIAN TERKAIT DAN LANDASAN TEORI 2.1 Penelitian Terkait Ada beberapa penelitian terkait dengan penggunaan Data Mining metode cluster dengan menggunakan Algoritma Fuzzy C-Means untuk dapat mengelompokkan
BAB 2 PENELITIAN TERKAIT DAN LANDASAN TEORI 2.1 Penelitian Terkait Ada beberapa penelitian terkait dengan penggunaan Data Mining metode cluster dengan menggunakan Algoritma Fuzzy C-Means untuk dapat mengelompokkan
PENERAPAN METODE ASOSIASI DATA MINING MENGGUNAKAN ALGORITMA APRIORI UNTUK MENGETAHUI KOMBINASI ANTAR ITEMSET PADA PONDOK KOPI
 PENERAPAN METODE ASOSIASI DATA MINING MENGGUNAKAN ALGORITMA APRIORI UNTUK MENGETAHUI KOMBINASI ANTAR ITEMSET PADA PONDOK KOPI Fitri Nurchalifatun Fakultas Ilmu Komputer, Universitas Dian Nuswantoro, Jl.
PENERAPAN METODE ASOSIASI DATA MINING MENGGUNAKAN ALGORITMA APRIORI UNTUK MENGETAHUI KOMBINASI ANTAR ITEMSET PADA PONDOK KOPI Fitri Nurchalifatun Fakultas Ilmu Komputer, Universitas Dian Nuswantoro, Jl.
BAB II LANDASAN TEORI
 BAB II LANDASAN TEORI 2.1. Sistem Informasi Pengertian Sistem Informasi pada dasarnya merupakan hasil dari dua arti, yakni sistem dan informasi yang digabungkan. Berikut definisi sistem menurut para ahli
BAB II LANDASAN TEORI 2.1. Sistem Informasi Pengertian Sistem Informasi pada dasarnya merupakan hasil dari dua arti, yakni sistem dan informasi yang digabungkan. Berikut definisi sistem menurut para ahli
KLUSTER K-MEANS DATA MAHASISWA BARU TERHADAP PROGRAM STUDI YANG DIPILIH
 KLUSTER K-MEANS DATA MAHASISWA BARU TERHADAP PROGRAM STUDI YANG DIPILIH Citra Arum Sari dan Dwi Sukma D Program Studi Teknik Industri, FTI-UPN Jatim ABSTRAK Besarnya peminat dari setiap program studi di
KLUSTER K-MEANS DATA MAHASISWA BARU TERHADAP PROGRAM STUDI YANG DIPILIH Citra Arum Sari dan Dwi Sukma D Program Studi Teknik Industri, FTI-UPN Jatim ABSTRAK Besarnya peminat dari setiap program studi di
BAB I PENDAHULUAN. secara manual dari suatu kumpulan data. Defenisi lain data mining adalah sebagai
 BAB I PENDAHULUAN I.1. Latar Belakang Data mining merupakan serangkaian proses untuk menggali nilai tambah dari suatu kumpulan data berupa pengetahuan yang selama ini tidak diketahui secara manual dari
BAB I PENDAHULUAN I.1. Latar Belakang Data mining merupakan serangkaian proses untuk menggali nilai tambah dari suatu kumpulan data berupa pengetahuan yang selama ini tidak diketahui secara manual dari
BAB II TINJAUAN PUSTAKA
 BAB II TINJAUAN PUSTAKA 2.1. Penambangan Data (Data Mining) Penambangan data (Data Mining) adalah serangkaian proses untuk menggali nilai tambah dari sekumpulan data berupa pengetahuan yang selama ini
BAB II TINJAUAN PUSTAKA 2.1. Penambangan Data (Data Mining) Penambangan data (Data Mining) adalah serangkaian proses untuk menggali nilai tambah dari sekumpulan data berupa pengetahuan yang selama ini
Penerapan Metode Fuzzy C-Means dengan Model Fuzzy RFM (Studi Kasus : Clustering Pelanggan Potensial Online Shop)
") 157 Penerapan Metode Fuzzy C-Means dengan Model Fuzzy RFM (Studi Kasus : Clustering Pelanggan Potensial Online Shop) Elly Muningsih AMIK BSI Yogyakarta E-Mail : elly.emh@bsi.ac.id Abstrak Berkembangnya
157 Penerapan Metode Fuzzy C-Means dengan Model Fuzzy RFM (Studi Kasus : Clustering Pelanggan Potensial Online Shop) Elly Muningsih AMIK BSI Yogyakarta E-Mail : elly.emh@bsi.ac.id Abstrak Berkembangnya
APLIKASI K-MEANS UNTUK PENGELOMPOKKAN MAHASISWA BERDASARKAN NILAI BODY MASS INDEX (BMI) & UKURAN KERANGKA
 & UKURAN KERANGKA") APLIKASI K-MEANS UNTUK PENGELOMPOKKAN MAHASISWA BERDASARKAN NILAI BODY MASS INDEX (BMI) & UKURAN KERANGKA Tedy Rismawan 1 dan Sri Kusumadewi 2 1 Laboratorium Komputasi dan Sistem Cerdas, Jurusan Teknik
APLIKASI K-MEANS UNTUK PENGELOMPOKKAN MAHASISWA BERDASARKAN NILAI BODY MASS INDEX (BMI) & UKURAN KERANGKA Tedy Rismawan 1 dan Sri Kusumadewi 2 1 Laboratorium Komputasi dan Sistem Cerdas, Jurusan Teknik
BAB II TINJAUAN PUSTAKA Indeks Prestasi Kumulatif dan Lama Studi. menggunakan dokumen/format resmi hasil penilaian studi mahasiswa yang sudah
 BAB II TINJAUAN PUSTAKA 2.1 Landasan Teori 2.1.1 Indeks Prestasi Kumulatif dan Lama Studi Mahasiswa yang telah menyelesaikan keseluruhan beban program studi yang telah ditetapkan dapat dipertimbangkan
BAB II TINJAUAN PUSTAKA 2.1 Landasan Teori 2.1.1 Indeks Prestasi Kumulatif dan Lama Studi Mahasiswa yang telah menyelesaikan keseluruhan beban program studi yang telah ditetapkan dapat dipertimbangkan
Bab 2 Tinjauan Pustaka
 Bab 2 Tinjauan Pustaka 2.1 Penelitian Terdahulu Adapun penelitian terdahulu yang berkaitan dalam penelitian ini berjudul Penentuan Wilayah Usaha Pertambangan Menggunakan Metode Fuzzy K-Mean Clustering
Bab 2 Tinjauan Pustaka 2.1 Penelitian Terdahulu Adapun penelitian terdahulu yang berkaitan dalam penelitian ini berjudul Penentuan Wilayah Usaha Pertambangan Menggunakan Metode Fuzzy K-Mean Clustering
BAB 1 PENDAHULUAN. terhadap peran sistem informasi dalam perusahaan sebagai bagian dari produktivitas.
 BAB 1 PENDAHULUAN 1.1. Latar Belakang Masalah Perkembangan teknologi informasi telah mampu mengubah persepsi manusia terhadap peran sistem informasi dalam perusahaan sebagai bagian dari produktivitas.
BAB 1 PENDAHULUAN 1.1. Latar Belakang Masalah Perkembangan teknologi informasi telah mampu mengubah persepsi manusia terhadap peran sistem informasi dalam perusahaan sebagai bagian dari produktivitas.
BAB II TINJAUAN PUSTAKA DAN LANDASAN TEORI. yang tepat. Sistem data mining mampu memberikan informasi yang tepat dan
 BAB II TINJAUAN PUSTAKA DAN LANDASAN TEORI 2.1. Tinjauan Pustaka Sistem data mining akan lebih efektif dan efisiensi dengan komputerisasi yang tepat. Sistem data mining mampu memberikan informasi yang
BAB II TINJAUAN PUSTAKA DAN LANDASAN TEORI 2.1. Tinjauan Pustaka Sistem data mining akan lebih efektif dan efisiensi dengan komputerisasi yang tepat. Sistem data mining mampu memberikan informasi yang
BAB II TINJAUAN PUSTAKA. sekumpulan besar data yang tersimspan dalam penyimpanan dengan
 BAB II TINJAUAN PUSTAKA 2.1 Landasan Teori 2.1.1 Data Mining A. Pengertian Data Mining Menurut Gartner Group data mining adalah suatu proses menemukan hubungan yang berarti, pola, dan kecenderungan dengan
BAB II TINJAUAN PUSTAKA 2.1 Landasan Teori 2.1.1 Data Mining A. Pengertian Data Mining Menurut Gartner Group data mining adalah suatu proses menemukan hubungan yang berarti, pola, dan kecenderungan dengan
ANALISA DAN PERANCANGAN APLIKASI ALGORITMA APRIORI UNTUK KORELASI PENJUALAN PRODUK (STUDI KASUS : APOTIK DIORY FARMA)
") ANALISA DAN PERANCANGAN APLIKASI ALGORITMA APRIORI UNTUK KORELASI PENJUALAN PRODUK (STUDI KASUS : APOTIK DIORY FARMA) Harvei Desmon Hutahaean 1, Bosker Sinaga 2, Anastasya Aritonang Rajagukguk 2 1 Program
ANALISA DAN PERANCANGAN APLIKASI ALGORITMA APRIORI UNTUK KORELASI PENJUALAN PRODUK (STUDI KASUS : APOTIK DIORY FARMA) Harvei Desmon Hutahaean 1, Bosker Sinaga 2, Anastasya Aritonang Rajagukguk 2 1 Program
ANALISIS DATA POLA PEMBELIAN KONSUMEN DENGAN ALGORITMA APRIORI PADA TRANSAKSI PENJUALAN SUPERMARKET PAMELLA YOGYAKARTA 1.
 ANALISIS DATA POLA PEMBELIAN KONSUMEN DENGAN ALGORITMA APRIORI PADA TRANSAKSI PENJUALAN SUPERMARKET PAMELLA YOGYAKARTA M. Didik R. Wahyudi 1) Fusna Failasufa 2) 1) 2) Teknik Informatika FST UIN Sunan Kalijaga
ANALISIS DATA POLA PEMBELIAN KONSUMEN DENGAN ALGORITMA APRIORI PADA TRANSAKSI PENJUALAN SUPERMARKET PAMELLA YOGYAKARTA M. Didik R. Wahyudi 1) Fusna Failasufa 2) 1) 2) Teknik Informatika FST UIN Sunan Kalijaga
IMPLEMENTASI METODE KLASTERING K-MEANS UNTUK MENGELOMPOKAN HASIL EVALUASI MAHASISWA. FEBRIZAL ALFARASY SYAM Dosen STMIK Dharmapala Riau ABSTRAK
 Jurnal Ilmu Komputer dan Bisnis, Volume 8, Nomor 1, Mei 017 IMPLEMENTASI METODE KLASTERING K-MEANS UNTUK MENGELOMPOKAN HASIL EVALUASI MAHASISWA FEBRIZAL ALFARASY SYAM Dosen STMIK Dharmapala Riau ABSTRAK
Jurnal Ilmu Komputer dan Bisnis, Volume 8, Nomor 1, Mei 017 IMPLEMENTASI METODE KLASTERING K-MEANS UNTUK MENGELOMPOKAN HASIL EVALUASI MAHASISWA FEBRIZAL ALFARASY SYAM Dosen STMIK Dharmapala Riau ABSTRAK
METODE CLUSTERING DENGAN ALGORITMA K-MEANS. Oleh : Nengah Widya Utami
 METODE CLUSTERING DENGAN ALGORITMA K-MEANS Oleh : Nengah Widya Utami 1629101002 PROGRAM STUDI S2 ILMU KOMPUTER PROGRAM PASCASARJANA UNIVERSITAS PENDIDIKAN GANESHA SINGARAJA 2017 1. Definisi Clustering
METODE CLUSTERING DENGAN ALGORITMA K-MEANS Oleh : Nengah Widya Utami 1629101002 PROGRAM STUDI S2 ILMU KOMPUTER PROGRAM PASCASARJANA UNIVERSITAS PENDIDIKAN GANESHA SINGARAJA 2017 1. Definisi Clustering
CLUSTERING PENENTUAN POTENSI KEJAHATAN DAERAH DI KOTA BANJARBARU DENGAN METODE K-MEANS
 Volume 01, No01 September 2014 CLUSTERING PENENTUAN POTENSI KEJAHATAN DAERAH DI KOTA BANJARBARU DENGAN METODE K-MEANS Sri Rahayu 1,Dodon T Nugrahadi 2, Fatma Indriani 3 1,2,3 Prog Studi Ilmu Komputer Fakultas
Volume 01, No01 September 2014 CLUSTERING PENENTUAN POTENSI KEJAHATAN DAERAH DI KOTA BANJARBARU DENGAN METODE K-MEANS Sri Rahayu 1,Dodon T Nugrahadi 2, Fatma Indriani 3 1,2,3 Prog Studi Ilmu Komputer Fakultas
ANALISIS CLUSTER PADA DOKUMEN TEKS
 Budi Susanto ANALISIS CLUSTER PADA DOKUMEN TEKS Text dan Web Mining - FTI UKDW - BUDI SUSANTO 1 Tujuan Memahami konsep analisis clustering Memahami tipe-tipe data dalam clustering Memahami beberapa algoritma
Budi Susanto ANALISIS CLUSTER PADA DOKUMEN TEKS Text dan Web Mining - FTI UKDW - BUDI SUSANTO 1 Tujuan Memahami konsep analisis clustering Memahami tipe-tipe data dalam clustering Memahami beberapa algoritma
BAB 3 ANALISA SISTEM
 BAB 3 ANALISA SISTEM Pada perancangan suatu sistem diperlakukan analisa yang tepat, sehingga proses pembuatan sistem dapat berjalan dengan lancar dan sesuai seperti yang diinginkan. Setelah dilakukan analisis
BAB 3 ANALISA SISTEM Pada perancangan suatu sistem diperlakukan analisa yang tepat, sehingga proses pembuatan sistem dapat berjalan dengan lancar dan sesuai seperti yang diinginkan. Setelah dilakukan analisis
BAB I PENDAHULUAN. bersaing. Dalam dunia bisnis yang dinamis dan penuh persaingan. Seiring dengan
 BAB I PENDAHULUAN 1.1 Latar Belakang Kemajuan perkembangan teknologi informasi pada era globalisasi sekarang ini sangat pesat, hal ini menuntut setiap perusahaan untuk dapat saling bersaing. Dalam dunia
BAB I PENDAHULUAN 1.1 Latar Belakang Kemajuan perkembangan teknologi informasi pada era globalisasi sekarang ini sangat pesat, hal ini menuntut setiap perusahaan untuk dapat saling bersaing. Dalam dunia
BAB II TINJAUAN PUSTAKA DAN LANDASAN TEORI
 BAB II TINJAUAN PUSTAKA DAN LANDASAN TEORI 2.1. Tinjauan Pustaka Tinjauan pustaka atau disebut juga kajian pustaka (literature review) merupakan sebuah aktivitas untuk meninjau atau mengkaji kembali berbagai
BAB II TINJAUAN PUSTAKA DAN LANDASAN TEORI 2.1. Tinjauan Pustaka Tinjauan pustaka atau disebut juga kajian pustaka (literature review) merupakan sebuah aktivitas untuk meninjau atau mengkaji kembali berbagai
DATA MINING DAN WAREHOUSE A N D R I
 DATA MINING DAN WAREHOUSE A N D R I CLUSTERING Secara umum cluster didefinisikan sebagai sejumlah objek yang mirip yang dikelompokan secara bersama, Namun definisi dari cluster bisa beragam tergantung
DATA MINING DAN WAREHOUSE A N D R I CLUSTERING Secara umum cluster didefinisikan sebagai sejumlah objek yang mirip yang dikelompokan secara bersama, Namun definisi dari cluster bisa beragam tergantung
BAB 2 LANDASAN TEORI
 BAB 2 LANDASAN TEORI 2.1 Penambangan Data (Data Mining) Pengertian data mining, berdasarkan beberapa orang: 1. Data mining (penambangan data) adalah suatu proses untuk menemukan suatu pengetahuan atau
BAB 2 LANDASAN TEORI 2.1 Penambangan Data (Data Mining) Pengertian data mining, berdasarkan beberapa orang: 1. Data mining (penambangan data) adalah suatu proses untuk menemukan suatu pengetahuan atau
BAB I PENDAHULUAN. efektivitas dan efisiensi kerja tercapai. STIKOM Surabaya merupakan salah
 BAB I PENDAHULUAN 1.1 Latar belakang masalah Solusi pemanfaatan teknologi komputer sebagai alat bantu dalam mendukung kegiatan operasional suatu bidang usaha memudahkan manusia dalam mendapatkan data atau
BAB I PENDAHULUAN 1.1 Latar belakang masalah Solusi pemanfaatan teknologi komputer sebagai alat bantu dalam mendukung kegiatan operasional suatu bidang usaha memudahkan manusia dalam mendapatkan data atau
Data Mining. Pengenalan Sistem & Teknik, Serta Contoh Aplikasi. Avinanta Tarigan. 22 Nov Avinanta Tarigan Data Mining
 Data Mining Pengenalan Sistem & Teknik, Serta Contoh Aplikasi Avinanta Tarigan 22 Nov 2008 1 Avinanta Tarigan Data Mining Outline 1 Pengertian Dasar 2 Classification Mining 3 Association Mining 4 Clustering
Data Mining Pengenalan Sistem & Teknik, Serta Contoh Aplikasi Avinanta Tarigan 22 Nov 2008 1 Avinanta Tarigan Data Mining Outline 1 Pengertian Dasar 2 Classification Mining 3 Association Mining 4 Clustering
DATA MINING CLUSTERING DENGAN ALGORITMA FUZZY C-MEANS UNTUK PENGELOMPOKAN JADWAL KEBERANGKATAN DI TRAVEL PT. XYZ TASIKMALAYA
 DATA MINING CLUSTERING DENGAN ALGORITMA FUZZY C-MEANS UNTUK PENGELOMPOKAN JADWAL KEBERANGKATAN DI TRAVEL PT. XYZ TASIKMALAYA Aseptian Nugraha, Acep Irham Gufroni, Rohmat Gunawan Teknik Informatika Fakultas
DATA MINING CLUSTERING DENGAN ALGORITMA FUZZY C-MEANS UNTUK PENGELOMPOKAN JADWAL KEBERANGKATAN DI TRAVEL PT. XYZ TASIKMALAYA Aseptian Nugraha, Acep Irham Gufroni, Rohmat Gunawan Teknik Informatika Fakultas
BAB II TINJAUAN PUSTAKA
 BAB II TINJAUAN PUSTAKA 2.1 Penelitian terkait Penelitian ini sebelumnya dilakukan studi kepustakaan dari penelitian terdahulu sebagai dasar atau acuan untuk menyelesaikan tugas akhir. Dari studi kepustakaan
BAB II TINJAUAN PUSTAKA 2.1 Penelitian terkait Penelitian ini sebelumnya dilakukan studi kepustakaan dari penelitian terdahulu sebagai dasar atau acuan untuk menyelesaikan tugas akhir. Dari studi kepustakaan
ANALISIS PENERAPAN TEKNIK DATAMINING DALAM PENGIMPLEMENTASIAN DAN PENGEMBANGAN MODEL ACTIVE LEARNING DENGAN METODE KELOMPOK
 ANALISIS PENERAPAN TEKNIK DATAMINING DALAM PENGIMPLEMENTASIAN DAN PENGEMBANGAN MODEL ACTIVE LEARNING DENGAN METODE KELOMPOK Dody Herdiana, S.T., M. Kom. Dosen PNS DPK pada Program Studi Teknik Informatika
ANALISIS PENERAPAN TEKNIK DATAMINING DALAM PENGIMPLEMENTASIAN DAN PENGEMBANGAN MODEL ACTIVE LEARNING DENGAN METODE KELOMPOK Dody Herdiana, S.T., M. Kom. Dosen PNS DPK pada Program Studi Teknik Informatika
PENERAPAN K-MEANS CLUSTERING PADA DATA PENERIMAAN MAHASISWA BARU (STUDI KASUS : UNIVERSITAS POTENSI UTAMA)
") Seminar Nasional Teknologi Informasi dan Multimedia 5 ISSN : 3-385 STMIK AMIKOM Yogyakarta, 6-8 Februari 5 PENERAPAN K-MEANS CLUSTERING PADA DATA PENERIMAAN MAHASISWA BARU (STUDI KASUS : UNIVERSITAS POTENSI
Seminar Nasional Teknologi Informasi dan Multimedia 5 ISSN : 3-385 STMIK AMIKOM Yogyakarta, 6-8 Februari 5 PENERAPAN K-MEANS CLUSTERING PADA DATA PENERIMAAN MAHASISWA BARU (STUDI KASUS : UNIVERSITAS POTENSI
BAB 1 PENDAHULUAN Latar Belakang. Pertumbuhan pasar swalayan dewasa ini telah meningkat dengan pesat di
 BAB 1 PENDAHULUAN 1.1. Latar Belakang Pertumbuhan pasar swalayan dewasa ini telah meningkat dengan pesat di Indonesia, ditandai dengan semakin banyak dan menjamurnya pasar swalayan di berbagai tempat.
BAB 1 PENDAHULUAN 1.1. Latar Belakang Pertumbuhan pasar swalayan dewasa ini telah meningkat dengan pesat di Indonesia, ditandai dengan semakin banyak dan menjamurnya pasar swalayan di berbagai tempat.
Tipe Clustering. Partitional Clustering. Hirerarchical Clustering
 Analisis Cluster Analisis Cluster Analisis cluster adalah pengorganisasian kumpulan pola ke dalam cluster (kelompok-kelompok) berdasar atas kesamaannya. Pola-pola dalam suatu cluster akan memiliki kesamaan
Analisis Cluster Analisis Cluster Analisis cluster adalah pengorganisasian kumpulan pola ke dalam cluster (kelompok-kelompok) berdasar atas kesamaannya. Pola-pola dalam suatu cluster akan memiliki kesamaan
BAB I PENDAHULUAN. informasi yang akurat sangat dibutuhkan dalam kehidupan sehari-hari, sehingga
 BAB I PENDAHULUAN I.1. Latar Belakang Dengan kemajuan teknologi informasi dewasa ini, kebutuhan akan informasi yang akurat sangat dibutuhkan dalam kehidupan sehari-hari, sehingga informasi akan menjadi
BAB I PENDAHULUAN I.1. Latar Belakang Dengan kemajuan teknologi informasi dewasa ini, kebutuhan akan informasi yang akurat sangat dibutuhkan dalam kehidupan sehari-hari, sehingga informasi akan menjadi
Penerapan Fungsi Data Mining Klasifikasi untuk Prediksi Masa Studi Mahasiswa Tepat Waktu pada Sistem Informasi Akademik Perguruan Tinggi
 IJCCS, Vol.x, No.x, July xxxx, pp. 1~5 ISSN: 1978-1520 39 Penerapan Fungsi Data Mining Klasifikasi untuk Prediksi Masa Studi Mahasiswa Tepat Waktu pada Sistem Informasi Akademik Perguruan Tinggi Irwan
IJCCS, Vol.x, No.x, July xxxx, pp. 1~5 ISSN: 1978-1520 39 Penerapan Fungsi Data Mining Klasifikasi untuk Prediksi Masa Studi Mahasiswa Tepat Waktu pada Sistem Informasi Akademik Perguruan Tinggi Irwan
REKOMENDASI PEMBELIAN PERSONAL KOMPUTER DENGAN METODE RANKED CLUSTERING
 REKOMENDASI PEMBELIAN PERSONAL KOMPUTER DENGAN METODE RANKED CLUSTERING Fadly Shabir 1 dan Abdul Rachman M 2 1 kyofadly@gmail.com, 2 emanrstc@yahoo.co.id 1 Stimik Handayani, 2 Universitas Muslim Indonesia
REKOMENDASI PEMBELIAN PERSONAL KOMPUTER DENGAN METODE RANKED CLUSTERING Fadly Shabir 1 dan Abdul Rachman M 2 1 kyofadly@gmail.com, 2 emanrstc@yahoo.co.id 1 Stimik Handayani, 2 Universitas Muslim Indonesia
ARTIKEL PENILAIAN PRESTASI KERJA PEGAWAI NEGERI SIPIL
 ARTIKEL PENERAPAN METODE K-MEANS DALAM PROSES CLUSTERING PENILAIAN PRESTASI KERJA PEGAWAI NEGERI SIPIL Oleh: IRFAN DWI NURCAHYO BUDIARTO 13.1.03.02.0117 Dibimbing oleh : 1. Hermin Istiasih, ST.,M.M.,M.T.
ARTIKEL PENERAPAN METODE K-MEANS DALAM PROSES CLUSTERING PENILAIAN PRESTASI KERJA PEGAWAI NEGERI SIPIL Oleh: IRFAN DWI NURCAHYO BUDIARTO 13.1.03.02.0117 Dibimbing oleh : 1. Hermin Istiasih, ST.,M.M.,M.T.
PENERAPAN DATA MINING UNTUK EVALUASI KINERJA AKADEMIK MAHASISWA MENGGUNAKAN ALGORITMA NAÏVE BAYES CLASSIFIER
 PENERAPAN DATA MINING UNTUK EVALUASI KINERJA AKADEMIK MAHASISWA MENGGUNAKAN ALGORITMA NAÏVE BAYES CLASSIFIER I. PENDAHULUAN Mahasiswa merupakan salah satu aspek penting dalam evaluasi keberhasilan penyelenggaraan
PENERAPAN DATA MINING UNTUK EVALUASI KINERJA AKADEMIK MAHASISWA MENGGUNAKAN ALGORITMA NAÏVE BAYES CLASSIFIER I. PENDAHULUAN Mahasiswa merupakan salah satu aspek penting dalam evaluasi keberhasilan penyelenggaraan
BAB I PENDAHULUAN 1.1. Latar Belakang
 BAB I PENDAHULUAN 1.1. Latar Belakang Seiring dengan perkembangan jaman, komputer semakin banyak berperan di dalam kehidupan masyarakat. Hampir semua bidang kehidupan telah menggunakan komputer sebagai
BAB I PENDAHULUAN 1.1. Latar Belakang Seiring dengan perkembangan jaman, komputer semakin banyak berperan di dalam kehidupan masyarakat. Hampir semua bidang kehidupan telah menggunakan komputer sebagai
PENGKLASIFIKASIAN DATA SEKOLAH PENGGUNA INTERNET PENDIDIKAN MENGGUNAKAN TEKNIK CLUSTERING DENGAN ALGORITMA K-MEANS STUDI KASUS PT TELKOM SURABAYA
 Artikel Skripsi PENGKLASIFIKASIAN DATA SEKOLAH PENGGUNA INTERNET PENDIDIKAN MENGGUNAKAN TEKNIK CLUSTERING DENGAN ALGORITMA K-MEANS STUDI KASUS PT TELKOM SURABAYA SKRIPSI Diajukan Untuk Memenuhi Sebagian
Artikel Skripsi PENGKLASIFIKASIAN DATA SEKOLAH PENGGUNA INTERNET PENDIDIKAN MENGGUNAKAN TEKNIK CLUSTERING DENGAN ALGORITMA K-MEANS STUDI KASUS PT TELKOM SURABAYA SKRIPSI Diajukan Untuk Memenuhi Sebagian
KLASIFIKASI PROSES BUSINESS DATA MAHASISWA UNIVERSITAS KANJURUHAN MALANG MENGGUNAKAN TEKNIK DATA MINING
 KLASIFIKASI PROSES BUSINESS DATA MAHASISWA UNIVERSITAS KANJURUHAN MALANG MENGGUNAKAN TEKNIK DATA MINING Moh Ahsan Universitas Kanjuruhan Malang ahsan@unikama.ac.id ABSTRAK. Universitas Kanjuruhan Malang
KLASIFIKASI PROSES BUSINESS DATA MAHASISWA UNIVERSITAS KANJURUHAN MALANG MENGGUNAKAN TEKNIK DATA MINING Moh Ahsan Universitas Kanjuruhan Malang ahsan@unikama.ac.id ABSTRAK. Universitas Kanjuruhan Malang
BAB 1 PENDAHULUAN 1.1 Pengantar Pendahuluan 1.2 Latar Belakang Masalah
 BAB 1 PENDAHULUAN 1.1 Pengantar Pendahuluan Kehadiran teknologi informasi memang dirasakan manfaatnya dalam mempermudah kegiatan dan kerja manusia dalam melakukan pekerjaannya. Lembaga bisnis pastilah
BAB 1 PENDAHULUAN 1.1 Pengantar Pendahuluan Kehadiran teknologi informasi memang dirasakan manfaatnya dalam mempermudah kegiatan dan kerja manusia dalam melakukan pekerjaannya. Lembaga bisnis pastilah
PENGKLASIFIKASIAN MINAT BELAJAR MAHASISWA DENGAN MODEL DATA MINING MENGGUNANAKAN METODE CLUSTERING
 PENGKLASIFIKASIAN MINAT BELAJAR MAHASISWA DENGAN MODEL DATA MINING MENGGUNANAKAN METODE CLUSTERING Marlindawati 1) Andri 2) 1) Manajemen Informatika Universitas Bina Darma Jl. Ahmad Yani No. 3, Palembang
PENGKLASIFIKASIAN MINAT BELAJAR MAHASISWA DENGAN MODEL DATA MINING MENGGUNANAKAN METODE CLUSTERING Marlindawati 1) Andri 2) 1) Manajemen Informatika Universitas Bina Darma Jl. Ahmad Yani No. 3, Palembang
2.2 Data Mining. Universitas Sumatera Utara
 Basis data adalah kumpulan terintegrasi dari occurences file/table yang merupakan representasi data dari suatu model enterprise. Sistem basisdata sebenarnya tidak lain adalah sistem penyimpanan-record
Basis data adalah kumpulan terintegrasi dari occurences file/table yang merupakan representasi data dari suatu model enterprise. Sistem basisdata sebenarnya tidak lain adalah sistem penyimpanan-record
UKDW BAB I PENDAHULUAN
 BAB I PENDAHULUAN 1.1 Latar Belakang Dalam dunia bisnis pada jaman sekarang, para pelaku bisnis senantiasa selalu berusaha mengembangkan cara-cara untuk dapat mengembangkan usaha mereka dan memperhatikan
BAB I PENDAHULUAN 1.1 Latar Belakang Dalam dunia bisnis pada jaman sekarang, para pelaku bisnis senantiasa selalu berusaha mengembangkan cara-cara untuk dapat mengembangkan usaha mereka dan memperhatikan
Prodi Sistem Informasi, STMIK Triguna Dharma Medan. Prodi Sistem Komputer, STMIK Triguna Dharma Medan . : #1
 ISSN : 1978-6603 Penerapan Data Mining dengan Algoritma Naive Bayes Clasifier untuk Mengetahui Minat Beli Pelanggan terhadap Kartu Internet XL (Studi Kasus di CV. Sumber Utama Telekomunikasi) Dicky Nofriansyah
ISSN : 1978-6603 Penerapan Data Mining dengan Algoritma Naive Bayes Clasifier untuk Mengetahui Minat Beli Pelanggan terhadap Kartu Internet XL (Studi Kasus di CV. Sumber Utama Telekomunikasi) Dicky Nofriansyah
SISTEM PENDUKUNG KEPUTUSAN PENENTUAN PEMBERIAN BANTUAN BIAYA PENDIDIKAN MENGGUNAKAN ALGORITMA K-MEANS
 SISTEM PENDUKUNG KEPUTUSAN PENENTUAN PEMBERIAN BANTUAN BIAYA PENDIDIKAN MENGGUNAKAN ALGORITMA K-MEANS Sinawati ), Ummi Syafiqoh 2) ), 2) Sistem Informasi STMIK PPKIA Tarakanita Rahmawati Tarakan Jl Yos
SISTEM PENDUKUNG KEPUTUSAN PENENTUAN PEMBERIAN BANTUAN BIAYA PENDIDIKAN MENGGUNAKAN ALGORITMA K-MEANS Sinawati ), Ummi Syafiqoh 2) ), 2) Sistem Informasi STMIK PPKIA Tarakanita Rahmawati Tarakan Jl Yos
TUGAS KONSEP DASAR DATA MINING
 TUGAS KONSEP DASAR DATA MINING Di susun Oleh: Nurkholifah Npm : 2014210052 FAKULTAS ILMU KOMPUTER JURUSAN SISTEM INFORMASI UNIVERSITAS INDO GLOBAL MANDIRI TAHUN 2016 BAB I PENDAHULUAN 1.1 Latar Belakang
TUGAS KONSEP DASAR DATA MINING Di susun Oleh: Nurkholifah Npm : 2014210052 FAKULTAS ILMU KOMPUTER JURUSAN SISTEM INFORMASI UNIVERSITAS INDO GLOBAL MANDIRI TAHUN 2016 BAB I PENDAHULUAN 1.1 Latar Belakang