APLIKASI PERBAIKAN EJAAN PADA KARYA TULIS ILMIAH DIPROGRAM STUDI TEKNIK INFORMATIKA DENGAN MENERAPKAN ALGORITMA LEVENSHTEIN DISTANCE
|
|
|
- Sonny Kusumo
- 6 tahun lalu
- Tontonan:
Transkripsi
1 APLIKASI PERBAIKAN EJAAN PADA KARYA TULIS ILMIAH DIPROGRAM STUDI TEKNIK INFORMATIKA DENGAN MENERAPKAN ALGORITMA LEVENSHTEIN DISTANCE Roby Nur Hamzah Artikel Skripsi Universitas Nusantara PGRI Kediri Di Publish 12 Agustus 2016 EMIL SALIM SARMAN

2 LATAR BELAKANG MASALAH REVISI BERULANG-ULANG KARENA TYPOGRAPHICAL ERROR SOLUSI EXPERT SYSTEM

3 TUJUAN PENELITIAN Mempermudah pengetikan karya tulis ilmiah Meperbaiki kesalahan pengetikan Kualitas karya tulis jadi lebih baik Expert system
4 METODE/TEKNIK YANG DITERAPKAN Metode yang diterapkan menggunakan algoritma levenshtein distance. CARA KERJA Menghitung jarak terdekat dari string sumber (s) dengan String target (t). Jika selisih String sumber (s) dengan String target (t) memiliki jarak terendah, maka akan dijadikan saran perbaikan berdasarkan urutan jarak String terendah hingga terbesar. Acuan perhitungan dengan algoritma dalam penelitian ini dibatasi dengan jarak toleransi = 2 dan banyaknya saran perbaikan adalah 20 kata.
5 HASIL DAN PEMBAHASAN/DISKUSI PEMBAHASAN Untuk mengetahui proses perhitungan algoritma Levenshtein Distance dalam memperbaiki kesalahan ejaan. Maka akan dilakukan sebuah simulasi algoritma dengan contoh sebagai berikut : Diketahui sebuah String sumber (s) = teknuk dan String target (t) = teknik untuk menyamakan String maka akan dilakukan perhitungan: Rumus : = d(t,t) + d(e,e) + d(k,k) + d(n,n) + d(u,i) + d(k,k) = = 1 Sehingga jarak levenshtein antara String (s) = teknuk dan (t) = teknik adalah D(s,t) = 1



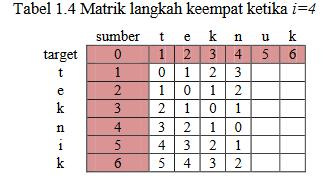
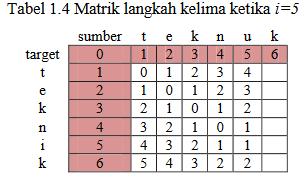
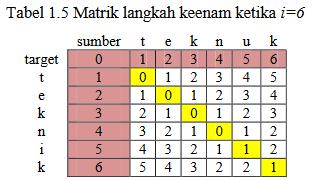
6 HASIL DAN PEMBAHASAN/DISKUSI Tabel penjelasan algoritma
7 KESIMPULAN Berdasarkan hasil penelitian dan implementasi sistem, maka dapat diambil kesimpulan sebagai berikut : 1. Aplikasi ini dikhususkan pada karya tulis ilmiah yang berformat *docx. 2. Acuan saran perbaikan menggunakan data dari KBBI Kemendikbud versi 3 yang disimpan pada database dan dikoneksikan pada aplikasi untuk menjadi acuan saran perbaikan kesalahan penulisan ejaan.
8 KAKAS BANTU PENDETEKSI KESALAHAN TADA BACA PADA KARYA TULIS ILMIAH Ratih Nur Esti Anggraini, Mohammad Ahmaluddin Zinni, dan Siti Rochimah Jurusan Teknik Informatika Institut Teknologi Sepuluh Nopember Abdullah Lubis
9 LATAR BELAKANG MASALAH Dirjen DIKTI tahun 2012 : Karya ilmiah dijadikan sebagai syarat kelulusan mahasiswa S1, S2 dan S3. Namun demikian, tidak semua karya ilmiah yang dihasilkan tersebut memiliki kualitas yang baik. Penulisan Kata Tanda Baca Tidak Sesuai Ejaan Yang Disempurnakan (EYD).
10 TUJUAN PENELITIAN Koreksi kesalahan penggunaan tanda baca Kualitas karya tulis jadi lebih baik Membantu dunia keilmiahan Indonesia dalam upaya meningkatkan kualitas tulisan karya ilmiah Expert system
11 METODE/TEKNIK YANG DITERAPKAN Metode yang diterapkan menggunakan Algoritma Boyer-Moore. CARA KERJA Heuristik looking-glass : Perbandingkan suatu karakter akhir pada kata w dengan suatu karakter pada teks s. Jika karakter tersebut sama maka jendela karakter akan berjalan mundur pada kedua string dan memeriksa kembali kedua karakter. Heuristik character-jump : Melakukan suatu aksi ketika terdapat perbandingan antara dua karakter yang berbeda.
12 HASIL DAN PEMBAHASAN/DISKUSI PEMBAHASAN Untuk dapat mengetahui tingkat performansi suatu sistem yang mampu mendapatkan kembali informasi-informasi tertentu dapat diketahui menggunakan perhitungan presisi dan recall. Presisi merupakan probabilitas informasi yang relevan dari semua informasi yang didapatkan kembali oleh sistem. Rumus untuk menghitung presisi dan recall : rumus presisi (P) berdasarkan table contingency rumus recall (R) berdasarkan tabel contingency Rumus perhitungan akurasi berdasarkan tabel contingency
13 HASIL DAN PEMBAHASAN/DISKUSI Proses pencarian menggunakan algoritma pencarian string Boyer-Moore
14 KESIMPULAN Berdasarkan hasil penelitian dan implementasi sistem,maka dapat diambil kesimpulan sebagai berikut : 1. Sistem dapat membangkitkan telaah kesalahan tanda baca berdasarkan kesalahan yang dideteksi dari karya ilmiah serta penggunaan algoritma pencarian kata (dalam kasus ini menggunakan algoritma Boyer-Moore) dapat digunakan pada kasus-kasus pendeteksian kesalahan tanda baca yang berhubungan dengan penggunaan spasi atau tidak, serta penggunaan huruf kapital atau huruf normal. 2. Aplikasi ini dikhususkan pada karya tulis ilmiah yang berformat *docx.
15 APLIKASI KOREKSI KESALAHAN BERBASIS PADA TULISAN BERBAHASA INDONESIA UNTUK MENINGKATKAN KUALITAS PENULISAN KARYA ILMIAH Andri, Sunda Ariana, Margareta Andriani Fakultas Ilmu Komputer Universitas Bina Darma Palembang Prosiding Seminar Nasional Aplikasi Sains & Teknologi (SNAST) 2014 ISSN: X Yogyakarta, 15 November 2014 Moh Mahpudin
16 LATAR BELAKANG MASALAH Kebiasaan berbicara sehari-hari dengan Bahasa daerah Kurang menguasai Bahasa Indonesia yang baku Indikasi penguasaan Bahasa Indonesia yang rendah dapat dilihat dari rendahnya nilai rata-rata Bahasa Indonesia dibandingkan dengan bahasa Inggris pada Ujian Nasional (Ariana, 2010).
17 TUJUAN PENELITIAN Membuat sebuah program aplikasi berbasis komputer Mengkoreksi kesalahan penggunaan EYD Memperbaiki kesalahan penulisan karya ilmiah
18 Metode/Teknik Yang Diterapkan Analisis kebutuhan sistem Perancangan aplikasi Implementasi dan penerapan algoritma Kesimpulan Penelitian ini menghasilkan sebuah perangkat lunak aplikasi yang dapat digunakan untuk melakukan koreksi kesalahan penggunaan EyD dalam dokumen berbahasa Indonesia.

19 HASIL DAN PEMBAHASAN Bentuk user interface aplikasi pada penelitian ini Aplikasi koreksi ini menyediakan fungsi untuk melakukan pengecekan penggunaan kata-kata yang sesuai dengan EYD.
20 Metode yang digunakan untuk penentuan solusi kata yang tidak sesuai dengan EYD dalam penelitian ini menggunakan metode N-Gram. N-Gram merupakan sebuah metode yang diaplikasikan untuk pembangkitan kata atau karakter. Menurut (Gergely, 2005) N Gram adalah substring sepanjangn karakter dari sebuah string. Metode N- Gram digunakan untuk mengambil potongan-potongan karakter huruf sejumlah n dalam sebuah kata yang secara kontinu dibaca dari kata sumber hingga akhir dari dokumen. Contoh pada kata TEXT dapat dijelaskan ke dalam beberapa N-Gram sebagai berikut: Uni-gram : T,E,X,T Bi-gram : TE,EX,XT Tri-gram : TEX,EXT Quad-gram : TEXT,EXT Salah satu keunggulan menggunakan N-Gram dan bukan suatu kata utuh secara keseluruhan adalah bahwa N-Gram tidak terlalu sensitif terhadap kesalahan penulisan yang terdapat pada suatu dokumen (Hanafi, 2009). Alur proses aplikasi koreksi
21 KESIMPULAN Dari proses implementasi dan pengujian dapat diambil beberapa kesimpulan sebagai berikut: 1. Aplikasi koreksi yang dibuat dapat mendeteksi kesalahan-kesalahan yang terjadi pada dokumen-dokumen Bahasa Indonesia. 2. Aplikasi koreksi dapat melakukan perbaikan secara otomatis terhadap kata dan kalimat yang tidak sesuai dengan EyD.
22 APLIKASI PREDICTIVE TEXT BERBAHASA INDONESIA DENGAN METODE N-GRAM Silvia Rostianingsih, Sendy Andrian Sugianto, Liliana. Program Studi Teknik Informatika Fakultas Teknologi Industri Universitas Kristen Petra. ROKHMAT
 PENULISAN KATA TIDAK SESUAI EJAAN YANG DISEMPURNAKAN (EYD).")
23 LATAR BELAKANG MASALAH PROSES PENGETIKAN LAMA SERINGNYA TERJADI KESALAHAN KETIK (TYPO) PENULISAN KATA TIDAK SESUAI EJAAN YANG DISEMPURNAKAN (EYD). EXPERT SYSTEM
24 TUJUAN PENELITIAN MEMPERCEPAT DALAM PENGETIKAN SUATU KATA MEMPERMUDAH PENGETIKAN KARYA TULIS ILMIAH KUALITAS KARYA TULIS JADI LEBIH BAIK Expert system
25 METODE/TEKNIK YANG DITERAPKAN CARA KERJA Metodologi penelitian dilakukan dengan mempelajari tentang metode N-Gram- Based, dilanjutkan dengan membuat perancangan sistem tentang pengolahan kata dan metode scoring kata. Pembuatan perangkat lunak yaitu dengan mengimplementasikan desain sistem yang telah dibuat ke dalam bahasa pemrograman, meliputi language model, frequency scoring, semantic scoring, Ngram scoring. Selanjutnya dilakukan pengujian aplikasi dalam melakukan prediksi dan keystroke saving yang dihasilkan oleh tiap metode scoring. Kesimpulan dilakukan dengan membandingkan hasil prediksi dan keystroke saving yang dihasilkan dari aplikasi.
26 DESAIN SISTEM Dalam melakukan predictive text, user terlebih dahulu memasukkan metode n- gram yang digunakan. Selanjutnya sistem akan melakukan load file kata yang ada sesuai metode n-gram yang dipilih. Sistem akan membaca input karakter dari user dan melakukan parsing data. Selanjutnya sistem melakukan searching dan scoring kata dari file untuk menghasilkan predictive text. Terakhir, sistem memberikan usulan kata yang menjadi predictive text kepada user. Rancangan sistem kerja aplikasi secara garis besar ditunjukkan pada Gambar 1.

 dan Trigram (Tabel 2) menunjukkan nilai yang hampir sama.")
27 HASIL DAN PEMBAHASAN/DISKUSI Pengujian dilakukan antara lain menguji bobot dari tiap metode scoring-nya, yakni Keystroke Saving (KS) dan Score Prediksi Efektif (SPE). Pengujian dengan menghitung keystroke saving adalah untuk menghitung seberapa banyak karakter yang dapat dihemat untuk menghasilkan sebuah teks tertentu. SPE didapat dari jumlah prediksi efektif yang terjadi dibandingkan dengan jumlah total prediksi yang terjadi. Hasil perhitungan yang didapat dari pengujian pada Bigram (Tabel 1) dan Trigram (Tabel 2) menunjukkan nilai yang hampir sama. Sedangkan untuk persentase frekuensi kata keluar (Tabel 3) menunjukkan bahwa metode bigram dan trigram masih memiliki persentase frekuensi kata keluar yang lebih tinggi dibanding metode lainnya.
28 KESIMPULAN Dari hasil penelitian dapat disimpulkan: 1. Rata-rata keystroke saving yang dihasilkan pada pengujian ini adalah 15 hingga 25 persen bergantung pada data training. 2. Rata-rata prediksi efektif terjadi di atas 30% dari total prediksi yang terjadi. Hal ini dikarenakan oleh pengaruh dari language model yang dapat langsung memprediksi kata dengan lebih efektif dan akurat. 3. Frekuensi dari language model yang tinggi sangat mempengaruhi scoring sistem, karena semakin tinggi frekuensi language model suatu kata, maka akan semakin tinggi pula bobot / nilai dari kata itu sendiri. 4. Semakin besar nilai n dalam n-gram berbanding terbalik dengan jumlah frekuensi keluar yang didapat, yaitu semakin kecil atau lebih jarang keluar. Penggunaan model bi-gram dan tri-gram untuk language model masih memungkinkan, karena hasil dari jumlah frekuensi keluar pada suku n-gramnya masih cukup besar dan datanya masih valid apabila diproses lebih lanjut.
29 Koreksi Ejaan Istilah Komputer Berbasis Kombinasi Algoritma Damerau Levenshtein dan Algoritma Soundex Akhmad Pahdi STMIK Banjarbaru Journal Speed Sentra Penelitian Engineering dan Edukasi Volume 8 No ISSN : (Print) (Online) Fajar Rusdi Wibowo
30 LATAR BELAKANG MASALAH Kesulitan dalam mengingat, menyebutkan, dan atau menuliskan kata dan penamaan istilah didunia komputer.
31 TUJUAN PENELITIAN Mengukur tingkat efektivtas algoritma Damerau-Levenstein yang dikombinasikan dengan algoritma Soundex dalam koreksi ejaan dan pencocokan kata.
32 METODE/TEKNIK YANG DITERAPKAN Metode yang diterapkan menggunakan algoritma Damerau-Levenshtein dikombinasikan dengan algoritma Soundex.. CARA KERJA Damerau-Levenshtein mencari jarak terpendak dalam mentransformasi kata menjadi kata yang lain, selanjutnya Soundex memembagi dan mengkelompokkan huruf sesuai dengan kesamaan bunyi.
 berupa jarak edit dengan rumusan: jarak_edit = max(n, m) lalu lompat ke langkah 7. 2.")

33 PEMBAHASAN Algoritma Damerau-Levenshtein 1.Inisialisasikan n sebagai panjang karakter dari s dan m sebagai panjang karakter dari t. Jika n = 0 atau m = 0, maka kembalikan nilai (return value) berupa jarak edit dengan rumusan: jarak_edit = max(n, m) lalu lompat ke langkah Buat sebuah matriks d sebanyak m + 1 baris dan n + 1 kolom. 3. Isi baris pertama dengan 0..n dan isi kolom pertama dengan 0..m. 4. Periksa setiap karakter dari s terhadap t Jika s[i] = t[j] maka cost = 0. Jika s[i] t[j] maka cost = Isikan nilai dari setiap sel d[i, j] baris per baris dengan: d[i, j] = min(x, y, z) Algoritma Soundex 1. Ubah semua huruf menjadi huruf besar atau uppercase, buang semua huruf vokal, tanda baca yang tidak ada hubungan dengan kata, konsonan H,W, dan Y, serta urutan huruf yang sama (misalnya. sss). Huruf pertama selalu dibiarkan seperti semula. 2. Gabung huruf pertama dengan angka pengganti yang sesuai dengan kode numerik yang ditunjukkan pada Tabel Ambil empat kode terdepan dan selanjutnya kode tersebut menjadi kode Soundex.



![terakhir. 7. Selesai. 4. Periksa setiap karakter dari s terhadap t. 5. Isikan nilai dari setiap sel d[i, j] baris per baris.](/docs-images/64/51458077/images/34-3.jpg "Langkah ini akan selalu berulang sampai semua matriks terisi.")
34 PROSES PENCOCOKAN KATA Kata kunci : getwey Jumlah karakter : 6 1. Inisialisasi n sebagai panjang karakter kata kunci, dan m sebagai panjang karakter kata-kata yang akan diukur jarak kedekatannya (asumsi, kata activity ), sehingga mendapatkan penghitungan jumlah n=6 dan jumlah m=8 2. Buat matrix d sebanyak m+1 dan n+1 kolom. 3. Pada matriks yang telah dibuat, isi baris pertama dengan 0..n dan isi kolom pertama dengan 0..m. Pencarian kata yang sesuai 6. Setelah langkah iterasi di atas selesai, maka jarak edit akan ditemukan pada sel d[n, m] yaitu sel pada pojok kanan baris terakhir. 7. Selesai. 4. Periksa setiap karakter dari s terhadap t. 5. Isikan nilai dari setiap sel d[i, j] baris per baris. Langkah ini akan selalu berulang sampai semua matriks terisi. d[1,1] = min((d[1-1,1]+1),(d[1,1-1]+1),(d[1-1,1-1]+cost)) = min((d[0,1]+1),(d[1,0]+1),(d[0,0] +1)) = min(2,2,1) = 1 d[1,2] = min((d[1-1,2]+1),(d[1,2-1]+1),(d[1-1,2-1]+cost)) = min((d[0,2]+1),(d[1,1]+1),(d[0,1]+1)) = min(3,2,2) = 2
35 KESIMPULAN Selama bunyi dan karakter pertama dari kata kunci sama dengan kata sumber maka efektivitas algoritma Soundex sedikit lebih baik dibandingkan dengan algoritma Damerau-Levenstein, dengan tingkat keberhasilan sebesar 74% sedangkan tingkat keberhasilan Damerau- Levenstein sebesar 70%, kombinasi dari algoritma Damerau Levenstein dan algoritma Soundex terbukti dapat meningkatkan tingkat akurasi koreksi ejaan untuk Istilah komputer,dengan tingkat akurasi sebesar 92% sedangkan 2% Damerau-Levenstein dan Soundex menyarankan kata atau istilah komputer yang tidak relevan.
36 ARSITEKTUR UNTUK APLIKASI DETEKSI KESAMAAN DOKUMEN BAHASA INDONESIA Anna Kurniawati, Kemal Ade Sekarwati, I wayan Simri Wicaksana Fakultas Ilmu komputer dan Teknologi Informasi Universitas Gunadarma Konferensi Nasional Sistem Informasi 2012,STMIK - STIKOM Bali, Pebruari 2012 Aef Saefulah
37 Tanpa aplikasi Latar Belakang Dengan aplikasi Mencari kesamaan kata pada judul Plagiat Hanya mencari pada kesamaan judulnya atau tema saja Plagiat Mencari kesamaan pada gabungan kata dan kalimat Mencari kesamaan pada arti dari keseluruhan kata paragraf dan dokumen


 Pembandingan dokumen")
38 Penelitian pengukuran kesamaan dokumen Peneliti : Didi Achjari Belum mempertimbangan struktur kalimat dan sinonim untuk membandingkan kalimat. Plagiat masih bisa dilakukan dan ditemukan pada hasil karya tulis mahasiswa. Aplikasi Tessy (Test of Text Similarity) Pembandingan dokumen menggunakan algoritma Swith Waterman Pembandingan dokumen menggunakan algoritma Rarp Kabin Peneliti : Sinta Agustina Peneliti : Audi Novanta

39 Peneliti : Saul Schleimer 2003, Noorzima 2005 Penelitian pengukuran kemiripan Menggunakan Metode Dokumen fingerprinting dengan algoritma Winnowing. Peneliti : Parvati Iyer, 2005 Menggunakan Metode Keyword Similarity dengan teknik DOT. Objek Penelitian yang digunakan adalah dokumen berbahasa Inggris. Dokumen yang digunakan sebanyak 20 data. Peneliti : Sinta Agustina 2008, Hari Bagus, Menggunakan metode String matching dengan algoritma Karp Rabin. Objek Penelitian yang digunakan adalah dokumen berbahasa Indonesia.

40 Metodologi penelitian

41 Arsitektur Deteksi Kesamaan Dokumen Kemiripan kalimat Rata-rata kemiripan kalimat Rata-rata maksimum kemiripan dokumen
42 Kesimpulan Dalam membangun arsitektur untuk aplikasi kesamaan dokumen terdiri dari 3 bagian penting, yaitu : 1. Penentuan Struktur Kalimat atau SPOK, 2. Kesamaan Dokumen 3. Analisis Sinonim Kata.
APLIKASI PREDICTIVE TEXT BERBAHASA INDONESIA DENGAN METODE N-GRAM
 APLIKASI PREDICTIVE TEXT BERBAHASA INDONESIA DENGAN METODE N-GRAM Silvia Rostianingsih 1), Sendy Andrian Sugianto 2), Liliana 3) 1, 2, 3) Program Studi Teknik Informatika Fakultas Teknologi Industri Universitas
APLIKASI PREDICTIVE TEXT BERBAHASA INDONESIA DENGAN METODE N-GRAM Silvia Rostianingsih 1), Sendy Andrian Sugianto 2), Liliana 3) 1, 2, 3) Program Studi Teknik Informatika Fakultas Teknologi Industri Universitas
ARSITEKTUR UNTUK APLIKASI DETEKSI KESAMAAN DOKUMEN BAHASA INDONESIA
 No Makalah : 073 ARSITEKTUR UNTUK APLIKASI DETEKSI KESAMAAN DOKUMEN BAHASA INDONESIA Anna Kurniawati 1, Kemal Ade Sekarwati 2, I wayan Simri Wicaksana 3 Jurusan Sistem Informasi Fakultas Ilmu komputer
No Makalah : 073 ARSITEKTUR UNTUK APLIKASI DETEKSI KESAMAAN DOKUMEN BAHASA INDONESIA Anna Kurniawati 1, Kemal Ade Sekarwati 2, I wayan Simri Wicaksana 3 Jurusan Sistem Informasi Fakultas Ilmu komputer
BAB I PENDAHULUAN 1.1 Latar Belakang
 BAB I PENDAHULUAN 1.1 Latar Belakang Dalam Era yang telah berkembang saat ini, banyak perkembangan perangkat lunak, adapun salah satu yang kita kenal adalah text editor. Seiring dengan perkembangan zaman
BAB I PENDAHULUAN 1.1 Latar Belakang Dalam Era yang telah berkembang saat ini, banyak perkembangan perangkat lunak, adapun salah satu yang kita kenal adalah text editor. Seiring dengan perkembangan zaman
Journal Speed Sentra Penelitian Engineering dan Edukasi Volume 8 No
 [Pick the date] Koreksi Ejaan Istilah Komputer Berbasis Kombinasi Algoritma Damerau- Levenshtein dan Algoritma Soundex Akhmad Pahdi STMIK Banjarbaru ahmadpahdi@gmail.com Abstrak Kesalahan penulisan ejaan
[Pick the date] Koreksi Ejaan Istilah Komputer Berbasis Kombinasi Algoritma Damerau- Levenshtein dan Algoritma Soundex Akhmad Pahdi STMIK Banjarbaru ahmadpahdi@gmail.com Abstrak Kesalahan penulisan ejaan
BAB I PENDAHULUAN 1.1 Latar Belakang
 BAB I PENDAHULUAN 1.1 Latar Belakang Berawal dari sebuah disiplin ilmu informatika yang mempelajari transformasi bantalan fakta bahwa data dan informasi tentang komputasi berbasis mesin. Disiplin ini mencakup
BAB I PENDAHULUAN 1.1 Latar Belakang Berawal dari sebuah disiplin ilmu informatika yang mempelajari transformasi bantalan fakta bahwa data dan informasi tentang komputasi berbasis mesin. Disiplin ini mencakup
used. Other than n-gram based method, setting of the weights for each scoring method also affect the process of word prediction.
 PEMBUATAN APLIKASI PREDICTIVE TEXT MENGGUNAKAN METODE N-GRAM-BASED Sendy Andrian Sugianto 1, Liliana 2, Silvia Rostianingsih 3 Program Studi Teknik Informatika Fakultas Teknologi Industri Universitas Kristen
PEMBUATAN APLIKASI PREDICTIVE TEXT MENGGUNAKAN METODE N-GRAM-BASED Sendy Andrian Sugianto 1, Liliana 2, Silvia Rostianingsih 3 Program Studi Teknik Informatika Fakultas Teknologi Industri Universitas Kristen
BAB 2 TINJAUAN PUSTAKA
 BAB 2 TINJAUAN PUSTAKA Pada bab ini, akan dibahas landasan teori mengenai pendeteksian kemiripan dokumen teks yang mengkhususkan pada pengertian dari keaslian dokumen, plagiarisme, kemiripan dokumen, dan
BAB 2 TINJAUAN PUSTAKA Pada bab ini, akan dibahas landasan teori mengenai pendeteksian kemiripan dokumen teks yang mengkhususkan pada pengertian dari keaslian dokumen, plagiarisme, kemiripan dokumen, dan
Perbaikan Ejaan Kata pada Dokumen Bahasa Indonesia dengan Metode Cosine Similarity
 Perbaikan Ejaan pada Bahasa Indonesia dengan Metode Cosine Similarity Muhammad Fachrurrozi 1, Anne Agustina Manik 2 1,2 Jurusan Teknik Informatika Universitas Sriwijaya Kampus Unsri Indralaya Ogan Ilir
Perbaikan Ejaan pada Bahasa Indonesia dengan Metode Cosine Similarity Muhammad Fachrurrozi 1, Anne Agustina Manik 2 1,2 Jurusan Teknik Informatika Universitas Sriwijaya Kampus Unsri Indralaya Ogan Ilir
BAB I PENDAHULUAN. penunjang Al-Quran untuk memudahkan untuk mempelajarinya, yang bisa
 BAB I PENDAHULUAN 1.1 Latar Belakang Masalah Dengan kemajuan teknologi yang sangat pesat ini sudah banyak aplikasi penunjang Al-Quran untuk memudahkan untuk mempelajarinya, yang bisa disebut atau di artikan
BAB I PENDAHULUAN 1.1 Latar Belakang Masalah Dengan kemajuan teknologi yang sangat pesat ini sudah banyak aplikasi penunjang Al-Quran untuk memudahkan untuk mempelajarinya, yang bisa disebut atau di artikan
BAB 1 PENDAHULUAN 1.1. Latar Belakang Masalah
 BAB 1 PENDAHULUAN 1.1. Latar Belakang Masalah Bahasa merupakan alat komunikasi lingual manusia baik secara lisan maupun tulisan. Dalam membuat suatu karya ilmiah, penggunaan Bahasa Indonesia harus sesuai
BAB 1 PENDAHULUAN 1.1. Latar Belakang Masalah Bahasa merupakan alat komunikasi lingual manusia baik secara lisan maupun tulisan. Dalam membuat suatu karya ilmiah, penggunaan Bahasa Indonesia harus sesuai
PENDAHULUAN. Latar belakang
 Latar belakang PEDAHULUA Kata kunci atau yang biasa disebut dengan query pada pencarian informasi dari sebuah search engine digunakan sebagai kriteria pencarian yang tepat dan sesuai dengan kebutuhan.
Latar belakang PEDAHULUA Kata kunci atau yang biasa disebut dengan query pada pencarian informasi dari sebuah search engine digunakan sebagai kriteria pencarian yang tepat dan sesuai dengan kebutuhan.
Bab 1 PENDAHULUAN Latar Belakang Masalah
 Bab 1 PENDAHULUAN Latar Belakang Masalah Pada masa sekarang ini perkembangan dalam dunia komputer terutama dalam bidang software telah maju dengan pesat dan mempengaruhi berbagai sektor kehidupan manusia,
Bab 1 PENDAHULUAN Latar Belakang Masalah Pada masa sekarang ini perkembangan dalam dunia komputer terutama dalam bidang software telah maju dengan pesat dan mempengaruhi berbagai sektor kehidupan manusia,
PERANCANGAN APLIKASI PENCARIAN ISI FILE YANG SAMA PADA HARDISK DRIVE DENGAN ALGORITMA STRING MATCHING
 Jurnal INFOTEK, Vol 1, No 1, Februari 2016 ISSN 2502-6968 (Media Cetak) PERANCANGAN APLIKASI PENCARIAN ISI FILE YANG SAMA PADA HARDISK DRIVE DENGAN ALGORITMA STRING MATCHING Bobby Anggara Mahasiswa Program
Jurnal INFOTEK, Vol 1, No 1, Februari 2016 ISSN 2502-6968 (Media Cetak) PERANCANGAN APLIKASI PENCARIAN ISI FILE YANG SAMA PADA HARDISK DRIVE DENGAN ALGORITMA STRING MATCHING Bobby Anggara Mahasiswa Program
APLIKASI PENDETEKSI KEMIRIPANPADA DOKUMEN MENGGUNAKAN ALGORITMA RABIN KARP
 APLIKASI PENDETEKSI KEMIRIPANPADA DOKUMEN MENGGUNAKAN ALGORITMA RABIN KARP Inta Widiastuti 1, Cahya Rahmad 2, Yuri Ariyanto 3 1,2 Jurusan Elektro, Program Studi Teknik Informatika, Politeknik Negeri Malang
APLIKASI PENDETEKSI KEMIRIPANPADA DOKUMEN MENGGUNAKAN ALGORITMA RABIN KARP Inta Widiastuti 1, Cahya Rahmad 2, Yuri Ariyanto 3 1,2 Jurusan Elektro, Program Studi Teknik Informatika, Politeknik Negeri Malang
KAKAS BANTU PENDETEKSI KESALAHAN TANDA BACA PADA KARYA TULIS ILMIAH
 KAKAS BANTU PENDETEKSI KESALAHAN TANDA BACA PADA KARYA TULIS ILMIAH Ratih Nur Esti Anggraini 1), Mohammad Ahmaluddin Zinni 2), dan Siti Rochimah 3) Jurusan Teknik Informatika, Institut Teknologi Sepuluh
KAKAS BANTU PENDETEKSI KESALAHAN TANDA BACA PADA KARYA TULIS ILMIAH Ratih Nur Esti Anggraini 1), Mohammad Ahmaluddin Zinni 2), dan Siti Rochimah 3) Jurusan Teknik Informatika, Institut Teknologi Sepuluh
PROGRAM STUDI INFORMATIKA FAKULTAS KOMUNIKASI DAN INFORMATIKA UNIVERSITAS MUHAMMADIYAH SURAKARTA
 PERBANDINGAN HASIL DETEKSI KEMIRIPAN TOPIK SKRIPSI DENGAN MENGGUNAKAN METODE N-GRAM DAN EKSPANSI KUERI Disusun oleh : Dwi iswanto L200100014 Pembimbing : Husni Thamrin PROGRAM STUDI INFORMATIKA FAKULTAS
PERBANDINGAN HASIL DETEKSI KEMIRIPAN TOPIK SKRIPSI DENGAN MENGGUNAKAN METODE N-GRAM DAN EKSPANSI KUERI Disusun oleh : Dwi iswanto L200100014 Pembimbing : Husni Thamrin PROGRAM STUDI INFORMATIKA FAKULTAS
BAB 1 PENDAHULUAN Latar Belakang Masalah
 BAB 1 PENDAHULUAN 1.1. Latar Belakang Masalah Komputer adalah sebuah alat yang dipakai untuk mengolah informasi menurut prosedur yang telah dirumuskan (Wikipedia, 2007: Komputer). Komputer berkembang mulai
BAB 1 PENDAHULUAN 1.1. Latar Belakang Masalah Komputer adalah sebuah alat yang dipakai untuk mengolah informasi menurut prosedur yang telah dirumuskan (Wikipedia, 2007: Komputer). Komputer berkembang mulai
BAB I PENDAHULUAN. penjiplakan suatu tulisan. Neville (2010) dalam buku The Complete Guide to
 dalam buku The Complete Guide to") BAB I PENDAHULUAN 1.1 Latar Belakang Masalah Perkembangan teknologi dari tahun ke tahun selalu berkembang secara signifikan. Jumlah pengguna internet yang besar dan semakin berkembang mempunyai pengaruh
BAB I PENDAHULUAN 1.1 Latar Belakang Masalah Perkembangan teknologi dari tahun ke tahun selalu berkembang secara signifikan. Jumlah pengguna internet yang besar dan semakin berkembang mempunyai pengaruh
BAB II TINJAUAN PUSTAKA. seolah-olah karya orang lain tersebut adalah karya kita dan mengakui hasil
 BAB II TINJAUAN PUSTAKA 2.1. Landasan Teori 2.1.1. Plagiarisme Ada beberapa definisi menurut para ahli lainnya (dalam Novanta, 2009), yaitu : 1. Menurut Ir. Balza Achmad, M.Sc.E, plagiarisme adalah berbuat
BAB II TINJAUAN PUSTAKA 2.1. Landasan Teori 2.1.1. Plagiarisme Ada beberapa definisi menurut para ahli lainnya (dalam Novanta, 2009), yaitu : 1. Menurut Ir. Balza Achmad, M.Sc.E, plagiarisme adalah berbuat
APLIKASI PERBAIKAN EJAAN PADA KARYA TULIS ILMIAH DI PROGRAM STUDI TEKNIK INFORMATIKA DENGAN MENERAPKAN ALGORITMA LEVENSHTEIN DISTANCE
 APLIKASI PERBAIKAN EJAAN PADA KARYA TULIS ILMIAH DI PROGRAM STUDI TEKNIK INFORMATIKA DENGAN MENERAPKAN ALGORITMA LEVENSHTEIN DISTANCE SKRIPSI Diajukan Untuk Penulisan Skripsi Guna Memenuhi Salah Satu Syarat
APLIKASI PERBAIKAN EJAAN PADA KARYA TULIS ILMIAH DI PROGRAM STUDI TEKNIK INFORMATIKA DENGAN MENERAPKAN ALGORITMA LEVENSHTEIN DISTANCE SKRIPSI Diajukan Untuk Penulisan Skripsi Guna Memenuhi Salah Satu Syarat
BAB I PENDAHULUAN 1.1. Latar Belakang
 BAB I PENDAHULUAN 1.1. Latar Belakang Perkembangan teknologi sudah dirasakan penting oleh manusia dalam era globalisasi saat ini. Hal itu terjadi karena kemajuan teknologi yang ada tidak dapat dipisahkan
BAB I PENDAHULUAN 1.1. Latar Belakang Perkembangan teknologi sudah dirasakan penting oleh manusia dalam era globalisasi saat ini. Hal itu terjadi karena kemajuan teknologi yang ada tidak dapat dipisahkan
BAB 1 PENDAHULUAN. 1.1.Latar Belakang
 7 BAB 1 PENDAHULUAN 1.1.Latar Belakang Saat ini informasi sangat mudah didapatkan terutama melalui media internet. Dengan banyaknya informasi yang terkumpul atau tersimpan dalam jumlah yang banyak, user
7 BAB 1 PENDAHULUAN 1.1.Latar Belakang Saat ini informasi sangat mudah didapatkan terutama melalui media internet. Dengan banyaknya informasi yang terkumpul atau tersimpan dalam jumlah yang banyak, user
IMPLEMENTASI ALGORITMA BOYER MOORE DAN METODE N-GRAM UNTUK APLIKASI AUTOCOMPLETE DAN AUTOCORRECT
 IMPLEMENTASI ALGORITMA BOYER MOORE DAN METODE N-GRAM UNTUK APLIKASI AUTOCOMPLETE DAN AUTOCORRECT TUGAS AKHIR Diajukan Untuk Memenuhi Persyaratan Akademik Studi Strata Satu (S1) Teknik Informatika Universitas
IMPLEMENTASI ALGORITMA BOYER MOORE DAN METODE N-GRAM UNTUK APLIKASI AUTOCOMPLETE DAN AUTOCORRECT TUGAS AKHIR Diajukan Untuk Memenuhi Persyaratan Akademik Studi Strata Satu (S1) Teknik Informatika Universitas
BAB I PENDAHULUAN. berinovasi menciptakan suatu karya yang original. Dalam hal ini tindakan negatif
 1 BAB I PENDAHULUAN I.1 Latar Belakang Pada dasarnya manusia menginginkan kemudahan Dalam segala hal. Sifat tersebut akan memicu tindakan negatif apabila dilatarbelakangi oleh motivasi untuk berbuat curang
1 BAB I PENDAHULUAN I.1 Latar Belakang Pada dasarnya manusia menginginkan kemudahan Dalam segala hal. Sifat tersebut akan memicu tindakan negatif apabila dilatarbelakangi oleh motivasi untuk berbuat curang
BAB I PENDAHULUAN. karya tulis. Berbagai aplikasi seperti Ms. Word, Notepad, maupun Open Office
 BAB I PENDAHULUAN 1.1 Latar Belakang Seiring dengan perkembangan teknologi, maka kegunaan komputer dirasa makin besar. Komputer berperan penting dalam mempermudah pekerjaan sehari hari. Salah satu manfaat
BAB I PENDAHULUAN 1.1 Latar Belakang Seiring dengan perkembangan teknologi, maka kegunaan komputer dirasa makin besar. Komputer berperan penting dalam mempermudah pekerjaan sehari hari. Salah satu manfaat
BAB 2 LANDASAN TEORI
 BAB 2 LANDASAN TEORI Pada bab ini akan dibahas tentang teori-teori dan konsep dasar yang mendukung pembahasan dari sistem yang akan dibuat. 2.1 Anak Berkebutuhan Khusus (ABK) Menurut Alimin (2012) Anak
BAB 2 LANDASAN TEORI Pada bab ini akan dibahas tentang teori-teori dan konsep dasar yang mendukung pembahasan dari sistem yang akan dibuat. 2.1 Anak Berkebutuhan Khusus (ABK) Menurut Alimin (2012) Anak
BAB I PENDAHULUAN Latar Belakang
 1 BAB I PENDAHULUAN 1.1. Latar Belakang Perkembangan dunia IT (Information Technology) dengan hadirnya mesin pencarian (Search Engine) di dalam sistem komputer yang merupakan salah satu fasilitas internet
1 BAB I PENDAHULUAN 1.1. Latar Belakang Perkembangan dunia IT (Information Technology) dengan hadirnya mesin pencarian (Search Engine) di dalam sistem komputer yang merupakan salah satu fasilitas internet
BAB I PENDAHULUAN 1.1 Latar Belakang
 BAB I PENDAHULUAN 1.1 Latar Belakang Di dalam dunia pemrograman komputer, kode program (source code) adalah kumpulan deklarasi atau pernyataan dari bahasa pemrograman computer yang di tulis dan bisa dibaca
BAB I PENDAHULUAN 1.1 Latar Belakang Di dalam dunia pemrograman komputer, kode program (source code) adalah kumpulan deklarasi atau pernyataan dari bahasa pemrograman computer yang di tulis dan bisa dibaca
APLIKASI STATISTIK PENDETEKSIAN PLAGIARISME DOKUMENT TEXT DENGAN ALGORITMA RABIN KARP
 APLIKASI STATISTIK PENDETEKSIAN PLAGIARISME DOKUMENT TEXT DENGAN ALGORITMA RABIN KARP Dedi Leman 1, Gunadi Widi Nurcahyo 2, Sarjon Defit 3 Teknik Informasi, Magister Komputer, Universitas Putra Indonesia
APLIKASI STATISTIK PENDETEKSIAN PLAGIARISME DOKUMENT TEXT DENGAN ALGORITMA RABIN KARP Dedi Leman 1, Gunadi Widi Nurcahyo 2, Sarjon Defit 3 Teknik Informasi, Magister Komputer, Universitas Putra Indonesia
TUGAS AKHIR. Sebagai Persyaratan Guna Meraih Gelar Sarjana Strata 1 Teknik Informatika Universitas Muhammadiyah Malang. Oleh :
 APLIKASI PENDETEKSI DUPLIKASI DOKUMEN TEKS BAHASA INDONESIA MENGGUNAKAN ALGORITMA WINNOWING SERTA PENGELOMPOKAN DOKUMEN DENGAN MENGGUNAKAN ALGORITMA FUZZY C-MEANS TUGAS AKHIR Sebagai Persyaratan Guna Meraih
APLIKASI PENDETEKSI DUPLIKASI DOKUMEN TEKS BAHASA INDONESIA MENGGUNAKAN ALGORITMA WINNOWING SERTA PENGELOMPOKAN DOKUMEN DENGAN MENGGUNAKAN ALGORITMA FUZZY C-MEANS TUGAS AKHIR Sebagai Persyaratan Guna Meraih
Sistem Temu Kembali Informasi pada Dokumen Teks Menggunakan Metode Term Frequency Inverse Document Frequency (TF-IDF)
") Sistem Temu Kembali Informasi pada Dokumen Teks Menggunakan Metode Term Frequency Inverse Document Frequency (TF-IDF) 1 Dhony Syafe i Harjanto, 2 Sukmawati Nur Endah, dan 2 Nurdin Bahtiar 1 Jurusan Matematika,
Sistem Temu Kembali Informasi pada Dokumen Teks Menggunakan Metode Term Frequency Inverse Document Frequency (TF-IDF) 1 Dhony Syafe i Harjanto, 2 Sukmawati Nur Endah, dan 2 Nurdin Bahtiar 1 Jurusan Matematika,
II. TEORI DASAR. Kata Kunci levenshtein; program dinamis; edit distance; twitter
 Aplikasi Program Dinamis dalam Menoleransi Kata Kunci dengan Algoritma untuk Disposisi Tweets ke Dinas-Dinas dan Instansi di Bawah Pemerintah Kota Bandung Ade Yusuf Rahardian - 151079 Program Studi Teknik
Aplikasi Program Dinamis dalam Menoleransi Kata Kunci dengan Algoritma untuk Disposisi Tweets ke Dinas-Dinas dan Instansi di Bawah Pemerintah Kota Bandung Ade Yusuf Rahardian - 151079 Program Studi Teknik
BAB I PENDAHULUAN Latar belakang
 BAB I PENDAHULUAN Bab ini membahas mengenai garis besar Tugas Akhir yang meliputi latar belakang, tujuan, rumusan dan batasan masalah, metodologi pembuatan tugas akhir, dan sistematika penulisan laporan.
BAB I PENDAHULUAN Bab ini membahas mengenai garis besar Tugas Akhir yang meliputi latar belakang, tujuan, rumusan dan batasan masalah, metodologi pembuatan tugas akhir, dan sistematika penulisan laporan.
BAB 1 PENDAHULUAN 1.1. Latar belakang
 BAB 1 PENDAHULUAN 1.1. Latar belakang Dengan berkembangnya teknologi dewasa ini, segala sesuatu harus dilakukan secara cepat, begitu juga dengan pembaca yang ingin secara cepat mengetahui keseluruhan infomasi
BAB 1 PENDAHULUAN 1.1. Latar belakang Dengan berkembangnya teknologi dewasa ini, segala sesuatu harus dilakukan secara cepat, begitu juga dengan pembaca yang ingin secara cepat mengetahui keseluruhan infomasi
BAB III ANALISIS DAN PERANCANGAN SISTEM
 BAB III ANALISIS DAN PERANCANGAN SISTEM Pada pengembangan suatu sistem diperlukan analisis dan perancangan sistem yang tepat, sehingga proses pembuatan sistem dapat berjalan dengan lancar dan sesuai seperti
BAB III ANALISIS DAN PERANCANGAN SISTEM Pada pengembangan suatu sistem diperlukan analisis dan perancangan sistem yang tepat, sehingga proses pembuatan sistem dapat berjalan dengan lancar dan sesuai seperti
APLIKASI WORDNET INDONESIA BERDASARKAN KAMUS THESAURUS BAHASA INDONESIA MENGGUNAKAN ALGORITMA RULE BASED TEXT PARSING
 APLIKASI WORDNET INDONESIA BERDASARKAN KAMUS THESAURUS BAHASA INDONESIA MENGGUNAKAN ALGORITMA RULE BASED TEXT PARSING Dzulfie Zamzami 1, Dr.Eng.Faisal Rahutomo,ST.,M.Kom 2., Dwi Puspitasari, S.Kom., M.Kom.
APLIKASI WORDNET INDONESIA BERDASARKAN KAMUS THESAURUS BAHASA INDONESIA MENGGUNAKAN ALGORITMA RULE BASED TEXT PARSING Dzulfie Zamzami 1, Dr.Eng.Faisal Rahutomo,ST.,M.Kom 2., Dwi Puspitasari, S.Kom., M.Kom.
BAB I PENDAHULUAN 1.1 Tujuan 1.2 Latar Belakang
 BAB I PENDAHULUAN 1.1 Tujuan Merancang sebuah sistem yang dapat meringkas teks dokumen secara otomatis menggunakan metode generalized vector space model (GVSM). 1.2 Latar Belakang Dunia informasi yang
BAB I PENDAHULUAN 1.1 Tujuan Merancang sebuah sistem yang dapat meringkas teks dokumen secara otomatis menggunakan metode generalized vector space model (GVSM). 1.2 Latar Belakang Dunia informasi yang
IMPLEMENTASI ALGORITMA BRUTE FORCE DALAM PENCARIAN DATA KATALOG BUKU PERPUSTAKAAN
 IMPLEMENTASI ALGORITMA BRUTE FORCE DALAM PENCARIAN DATA KATALOG BUKU PERPUSTAKAAN Mesran Dosen Tetap Program Studi Teknik Informatika STMIK Budi Darma Medan Jl. Sisingamangaraja No.338 Simpang Limun Medan
IMPLEMENTASI ALGORITMA BRUTE FORCE DALAM PENCARIAN DATA KATALOG BUKU PERPUSTAKAAN Mesran Dosen Tetap Program Studi Teknik Informatika STMIK Budi Darma Medan Jl. Sisingamangaraja No.338 Simpang Limun Medan
Aplikasi String Matching Pada Fitur Auto-Correct dan Word-Suggestion
 Aplikasi String Matching Pada Fitur Auto-Correct dan Word-Suggestion Johan - 13514206 Program Studi Teknik Informatika Sekolah Teknik Elektro dan Informatika Institut Teknologi Bandung, Jl. Ganesha 10
Aplikasi String Matching Pada Fitur Auto-Correct dan Word-Suggestion Johan - 13514206 Program Studi Teknik Informatika Sekolah Teknik Elektro dan Informatika Institut Teknologi Bandung, Jl. Ganesha 10
OPTIMASI QUERY UNTUK PENCARIAN DATA MENGGUNAKAN PENGURAIAN KALIMAT DAN ALGORITME LEVENSHTEIN DISTANCE
 OPTIMASI QUERY UNTUK PENCARIAN DATA MENGGUNAKAN PENGURAIAN KALIMAT DAN ALGORITME LEVENSHTEIN DISTANCE M. El Bahar Conoras 1, Aprian Dwi Kurnawan 2 1,2 Magister Teknik Informatika, UNIVERSITAS AMIKOM YOGYAKARTA
OPTIMASI QUERY UNTUK PENCARIAN DATA MENGGUNAKAN PENGURAIAN KALIMAT DAN ALGORITME LEVENSHTEIN DISTANCE M. El Bahar Conoras 1, Aprian Dwi Kurnawan 2 1,2 Magister Teknik Informatika, UNIVERSITAS AMIKOM YOGYAKARTA
BAB 1 PENDAHULUAN. 1.1 Latar Belakang. Pemanfaatan teknologi pada era globalisasi telah menjadi satu hal yang
 BAB 1 PENDAHULUAN 1.1 Latar Belakang Pemanfaatan teknologi pada era globalisasi telah menjadi satu hal yang sangat penting dalam kehidupan sehari-hari. Beberapa pemanfaatan teknologi dalam kehidupan sehari-hari
BAB 1 PENDAHULUAN 1.1 Latar Belakang Pemanfaatan teknologi pada era globalisasi telah menjadi satu hal yang sangat penting dalam kehidupan sehari-hari. Beberapa pemanfaatan teknologi dalam kehidupan sehari-hari
PERBANDINGAN ALGORITMA WINNOWING DENGAN ALGORITMA RABIN KARP UNTUK MENDETEKSI PLAGIARISME PADA KEMIRIPAN TEKS JUDUL SKRIPSI
 Technologia Vol 8, No.3, Juli September 2017 124 PERBANDINGAN ALGORITMA WINNOWING DENGAN ALGORITMA RABIN KARP UNTUK MENDETEKSI PLAGIARISME PADA KEMIRIPAN TEKS JUDUL SKRIPSI Fakultas Teknologi Informasi
Technologia Vol 8, No.3, Juli September 2017 124 PERBANDINGAN ALGORITMA WINNOWING DENGAN ALGORITMA RABIN KARP UNTUK MENDETEKSI PLAGIARISME PADA KEMIRIPAN TEKS JUDUL SKRIPSI Fakultas Teknologi Informasi
BAB 1 PENDAHULUAN. 1.1 Latar Belakang
 BAB 1 PENDAHULUAN 1.1 Latar Belakang Seiring dengan perkembangan teknologi informasi, maka proses dan media penyimpanan data pun semakin berkembang. Dengan adanya personal computer (PC), orang dapat menyimpan,
BAB 1 PENDAHULUAN 1.1 Latar Belakang Seiring dengan perkembangan teknologi informasi, maka proses dan media penyimpanan data pun semakin berkembang. Dengan adanya personal computer (PC), orang dapat menyimpan,
Rancang Bangun Aplikasi Koreksi EyD dalam Tulisan Karya Ilmiah Berbahasa Indonesia
 Rancang Bangun Aplikasi Koreksi EyD dalam Tulisan Karya Ilmiah Berbahasa Indonesia Sunda Ariana 1, Andri 2, Margareta Andriani 3 1 Fakultas Ilmu Komputer, UniversitasBina Darma 515581 E-mail : andri@mail.binadarma.ac.id
Rancang Bangun Aplikasi Koreksi EyD dalam Tulisan Karya Ilmiah Berbahasa Indonesia Sunda Ariana 1, Andri 2, Margareta Andriani 3 1 Fakultas Ilmu Komputer, UniversitasBina Darma 515581 E-mail : andri@mail.binadarma.ac.id
DETEKSI PLAGIARISME DENGAN ALGORITMA RABIN KARP DAN ALGORITMA KLASTERISASI SUFFIX TREE PADA TEKS DOKUMEN TUGAS AKHIR
 DETEKSI PLAGIARISME DENGAN ALGORITMA RABIN KARP DAN ALGORITMA KLASTERISASI SUFFIX TREE PADA TEKS DOKUMEN TUGAS AKHIR Sebagai Persyaratan Guna Meraih Gelar Sarjana Strata 1 Teknik Informatika Universitas
DETEKSI PLAGIARISME DENGAN ALGORITMA RABIN KARP DAN ALGORITMA KLASTERISASI SUFFIX TREE PADA TEKS DOKUMEN TUGAS AKHIR Sebagai Persyaratan Guna Meraih Gelar Sarjana Strata 1 Teknik Informatika Universitas
PENERAPAN FUZZY STRING MATCHING
 PENERAPAN FUZZY STRING MATCHING PADA APLIKASI PENCARIAN TUGAS AKHIR MAHASISWA JURUSAN SISTEM INFORMASI BERBASIS WEB (Studi Kasus: Fakultas Sains dan Teknologi UIN Suska Riau) 1 Ardi Isbad Amar Gurning,
PENERAPAN FUZZY STRING MATCHING PADA APLIKASI PENCARIAN TUGAS AKHIR MAHASISWA JURUSAN SISTEM INFORMASI BERBASIS WEB (Studi Kasus: Fakultas Sains dan Teknologi UIN Suska Riau) 1 Ardi Isbad Amar Gurning,
BAB III METODOLOGI PENELITIAN
 BAB III METODOLOGI PENELITIAN Metodologi penelitian merupakan sistematika tahap-tahap yang dilaksanakan dalam pembuatan tugas akhir. Adapun tahapan yang dilalui dalam pelaksanaan penelitian ini adalah
BAB III METODOLOGI PENELITIAN Metodologi penelitian merupakan sistematika tahap-tahap yang dilaksanakan dalam pembuatan tugas akhir. Adapun tahapan yang dilalui dalam pelaksanaan penelitian ini adalah
ANALISIS PERBANDINGAN ALGORITMA BOYER-MOORE, KNUTH- MORRIS-PRATT, DAN RABIN-KARP MENGGUNAKAN METODE PERBANDINGAN EKSPONENSIAL
 ANALISIS PERBANDINGAN ALGORITMA BOYER-MOORE, KNUTH- MORRIS-PRATT, DAN RABIN-KARP MENGGUNAKAN METODE PERBANDINGAN EKSPONENSIAL Indra Saputra M. Arief Rahman Jurusan Teknik Informatika STMIK PalComTech Palembang
ANALISIS PERBANDINGAN ALGORITMA BOYER-MOORE, KNUTH- MORRIS-PRATT, DAN RABIN-KARP MENGGUNAKAN METODE PERBANDINGAN EKSPONENSIAL Indra Saputra M. Arief Rahman Jurusan Teknik Informatika STMIK PalComTech Palembang
BAB I PENDAHULUAN 1.1 Latar Belakang
 BAB I PENDAHULUAN 1.1 Latar Belakang Kemajuan teknologi informasi dan komunikasi tidak hanya membawa dampak positif, tetapi juga membawa dampak negatif, salah satunya adalah tindakan plagiarisme (Kharisman,
BAB I PENDAHULUAN 1.1 Latar Belakang Kemajuan teknologi informasi dan komunikasi tidak hanya membawa dampak positif, tetapi juga membawa dampak negatif, salah satunya adalah tindakan plagiarisme (Kharisman,
BAB 1 PENDAHULUAN Latar Belakang
 BAB 1 PENDAHULUAN 1.1. Latar Belakang Kemajuan teknologi pada masa sekarang sangat membantu serta memberi kemudahan bagi manusia dalam melakukan berbagai aktivitas, khususnya aktivitas yang berkaitan dengan
BAB 1 PENDAHULUAN 1.1. Latar Belakang Kemajuan teknologi pada masa sekarang sangat membantu serta memberi kemudahan bagi manusia dalam melakukan berbagai aktivitas, khususnya aktivitas yang berkaitan dengan
BAB II TINJAUAN PUSTAKA
 BAB II TINJAUAN PUSTAKA 2.1. Regular Expression Regular expression atau yang sering disebut sebagai Regex adalah sebuah formula untuk pencarian pola suatu kalimat/string (Kuchling,2002). Sering kali orang
BAB II TINJAUAN PUSTAKA 2.1. Regular Expression Regular expression atau yang sering disebut sebagai Regex adalah sebuah formula untuk pencarian pola suatu kalimat/string (Kuchling,2002). Sering kali orang
Jurnal Informatika dan Komputer PENS
 Jurnal Informatika dan Komputer PENS www.jurnalpa.eepis-its.edu Teknik Komputer Vol.2, No.2, 2015 Politeknik Elektronika Negeri Surabaya Aplikasi Pendeteksi Kemiripan Laporan Menggunakan Text Mining dan
Jurnal Informatika dan Komputer PENS www.jurnalpa.eepis-its.edu Teknik Komputer Vol.2, No.2, 2015 Politeknik Elektronika Negeri Surabaya Aplikasi Pendeteksi Kemiripan Laporan Menggunakan Text Mining dan
BAB 1 PENDAHULUAN. 1.1 Latar Belakang Masalah
 BAB 1 PENDAHULUAN 1.1 Latar Belakang Masalah Bahasa Inggris merupakan salah satu bahasa yang sering digunakan baik pada percakapan sehari-hari maupun pada dunia akademik. Penelitian mengenai pemeriksaan
BAB 1 PENDAHULUAN 1.1 Latar Belakang Masalah Bahasa Inggris merupakan salah satu bahasa yang sering digunakan baik pada percakapan sehari-hari maupun pada dunia akademik. Penelitian mengenai pemeriksaan
Rata-rata token unik tiap dokumen
 Percobaan Tujuan percobaan ini adalah untuk mengetahui kinerja algoritme pengoreksian ejaan Damerau Levenshtein. Akan dilihat apakah algoritme tersebut dapat memberikan usulan kata yang cukup baik untuk
Percobaan Tujuan percobaan ini adalah untuk mengetahui kinerja algoritme pengoreksian ejaan Damerau Levenshtein. Akan dilihat apakah algoritme tersebut dapat memberikan usulan kata yang cukup baik untuk
Penerapan String Matching pada Fitur Auto Correct dan Fitur Auto Text di Smart Phones
 Penerapan String Matching pada Fitur Auto Correct dan Fitur Auto Text di Smart Phones Fandi Pradhana/13510049 Program Studi Teknik Informatika Sekolah Teknik Elektro dan Informatika Institut Teknologi
Penerapan String Matching pada Fitur Auto Correct dan Fitur Auto Text di Smart Phones Fandi Pradhana/13510049 Program Studi Teknik Informatika Sekolah Teknik Elektro dan Informatika Institut Teknologi
TECHNICAL REPORT PENGGUNAAN ALGORITMA PENCOCOKAN STRING BOYER-MOORE DALAM MENDETEKSI PENGAKSESAN SITUS INTERNET TERLARANG
 TECHNICAL REPORT PENGGUNAAN ALGORITMA PENCOCOKAN STRING BOYER-MOORE DALAM MENDETEKSI PENGAKSESAN SITUS INTERNET TERLARANG Ario Yudo Husodo Sekolah Teknik Elektro dan Informatika Institut Teknologi Bandung
TECHNICAL REPORT PENGGUNAAN ALGORITMA PENCOCOKAN STRING BOYER-MOORE DALAM MENDETEKSI PENGAKSESAN SITUS INTERNET TERLARANG Ario Yudo Husodo Sekolah Teknik Elektro dan Informatika Institut Teknologi Bandung
Pemodelan Penilaian Essay Otomatis Secara Realtime Menggunakan Kombinasi Text Stemming Dan Cosine Similarity
 Konferensi Nasional Sistem & Informatika 2017 STMIK STIKOM Bali, 10 Agustus 2017 Pemodelan Penilaian Essay Otomatis Secara Realtime Menggunakan Kombinasi Text Stemming Dan Cosine Similarity Komang Rinartha
Konferensi Nasional Sistem & Informatika 2017 STMIK STIKOM Bali, 10 Agustus 2017 Pemodelan Penilaian Essay Otomatis Secara Realtime Menggunakan Kombinasi Text Stemming Dan Cosine Similarity Komang Rinartha
BAB 1 PENDAHULUAN Latar Belakang
 BAB 1 PENDAHULUAN 1.1. Latar Belakang Dalam ilmu kesehatan banyak terdapat istilah medis yang berasal dari bahasa Yunani atau Latin. Secara umum, istilah yang berkaitan dengan diagnosis dan operasi memiliki
BAB 1 PENDAHULUAN 1.1. Latar Belakang Dalam ilmu kesehatan banyak terdapat istilah medis yang berasal dari bahasa Yunani atau Latin. Secara umum, istilah yang berkaitan dengan diagnosis dan operasi memiliki
BAB 1 PENDAHULUAN. 1.1 Latar Belakang
 1 BAB 1 PENDAHULUAN 1.1 Latar Belakang Plagiarisme atau sering disebut plagiat adalah penjiplakan atau pengambilan karangan, pendapat, dan sebagainya dari orang lain dan menjadikannya seolah-olah karangan
1 BAB 1 PENDAHULUAN 1.1 Latar Belakang Plagiarisme atau sering disebut plagiat adalah penjiplakan atau pengambilan karangan, pendapat, dan sebagainya dari orang lain dan menjadikannya seolah-olah karangan
 BAB I PENDAHULUAN 1.1 Latar Belakang Perpustakaan merupakan faktor penting di dalam penunjang transformasi antara sumber ilmu (koleksi) dengan pencari ilmu (pengunjung). Perpustakaan juga sering disebut
BAB I PENDAHULUAN 1.1 Latar Belakang Perpustakaan merupakan faktor penting di dalam penunjang transformasi antara sumber ilmu (koleksi) dengan pencari ilmu (pengunjung). Perpustakaan juga sering disebut
BAB 1 PENDAHULUAN. Universitas Kristen Maranatha
 BAB 1 PENDAHULUAN 1.1 Latar Belakang Masalah Pengajaran mata kuliah pemrograman biasanya diikuti oleh banyak mahasiswa. Dengan semakin besarnya jumlah mahasiswa dan banyaknya tugas yang harus diperiksa,
BAB 1 PENDAHULUAN 1.1 Latar Belakang Masalah Pengajaran mata kuliah pemrograman biasanya diikuti oleh banyak mahasiswa. Dengan semakin besarnya jumlah mahasiswa dan banyaknya tugas yang harus diperiksa,
BAB I PENDAHULUAN I.1. Latar Belakang [1] [2] [3] [4] [5]
![BAB I PENDAHULUAN I.1. Latar Belakang [1] [2] [3] [4] [5]](/thumbs/69/61684316.jpg "BAB I PENDAHULUAN I.1. Latar Belakang [1] [2] [3] [4] [5]") BAB I PENDAHULUAN I.1. Latar Belakang Algoritma adalah prosedur komputasi yang terdefinisi dengan baik yang menggunakan beberapa nilai sebagai masukan dan menghasilkan beberapa nilai yang disebut keluaran.
BAB I PENDAHULUAN I.1. Latar Belakang Algoritma adalah prosedur komputasi yang terdefinisi dengan baik yang menggunakan beberapa nilai sebagai masukan dan menghasilkan beberapa nilai yang disebut keluaran.
Aplikasi Algoritma String Matching dan Regex untuk Validasi Formulir
 Aplikasi Algoritma String Matching dan Regex untuk Validasi Formulir Edmund Ophie - 13512095 Program Studi Teknik Informatika Sekolah Teknik Elektro dan Informatika Institut Teknologi Bandung, Jl. Ganesha
Aplikasi Algoritma String Matching dan Regex untuk Validasi Formulir Edmund Ophie - 13512095 Program Studi Teknik Informatika Sekolah Teknik Elektro dan Informatika Institut Teknologi Bandung, Jl. Ganesha
BAB I PENDAHULUAN. 1.1 Latar Belakang
 BAB I PENDAHULUAN 1.1 Latar Belakang Ketersediaan teknologi dewasa ini mempengaruhi pada proses pertukaran informasi menjadi mudah dan bebas. Kemajuan yang cukup besar di bidang komputer dan dunia internet
BAB I PENDAHULUAN 1.1 Latar Belakang Ketersediaan teknologi dewasa ini mempengaruhi pada proses pertukaran informasi menjadi mudah dan bebas. Kemajuan yang cukup besar di bidang komputer dan dunia internet
Implementasi Pencocokan String Tidak Eksak dengan Algoritma Program Dinamis
 Implementasi Pencocokan String Tidak Eksak dengan Algoritma Program Dinamis Samudra Harapan Bekti 13508075 Program Studi Teknik Informatika Sekolah Teknik Elektro dan Informatika Institut Teknologi Bandung,
Implementasi Pencocokan String Tidak Eksak dengan Algoritma Program Dinamis Samudra Harapan Bekti 13508075 Program Studi Teknik Informatika Sekolah Teknik Elektro dan Informatika Institut Teknologi Bandung,
Penerapan Metode Winnowing Fingerprint dan Naive Bayes untuk Pengelompokan Dokumen
 Penerapan Metode Winnowing Fingerprint dan Naive Bayes untuk Pengelompokan Dokumen Adi Radili 1, Suwanto Sanjaya 2 1,2 Teknik Informatika UIN Sultan Syarif Kasim Riau Jl. H.R. Soebrantas no. 155 KM. 18
Penerapan Metode Winnowing Fingerprint dan Naive Bayes untuk Pengelompokan Dokumen Adi Radili 1, Suwanto Sanjaya 2 1,2 Teknik Informatika UIN Sultan Syarif Kasim Riau Jl. H.R. Soebrantas no. 155 KM. 18
BAB IV HASIL DAN UJI COBA
 37 BAB IV HASIL DAN UJI COBA Dalam tahap implementasi sistem ada beberapa syarat yang harus disiapkan sebelumnya. Syarat-syarat tersebut meliputi perangkat keras (hardware) dan perangkat lunak (software).
37 BAB IV HASIL DAN UJI COBA Dalam tahap implementasi sistem ada beberapa syarat yang harus disiapkan sebelumnya. Syarat-syarat tersebut meliputi perangkat keras (hardware) dan perangkat lunak (software).
BAB I PENDAHULUAN 1.1 Latar Belakang
 BAB I PENDAHULUAN 1.1 Latar Belakang Informasi saat ini berkembang sangat pesat, hal ini sangat mendukung terhadap kebutuhan manusia yang ingin serba cepat dan mudah dalam mendapatkan suatu informasi.
BAB I PENDAHULUAN 1.1 Latar Belakang Informasi saat ini berkembang sangat pesat, hal ini sangat mendukung terhadap kebutuhan manusia yang ingin serba cepat dan mudah dalam mendapatkan suatu informasi.
Jurnal Coding, Sistem Komputer Untan Volume 04, No.1 (2016), hal ISSN : x
, hal ISSN : x") APLIKASI PENDETEKSI PLAGIAT TERHADAP KARYA TULIS BERBASIS WEB MENGGUNAKAN NATURAL LANGUAGE PROCESSING DAN ALGORITMA KNUTH-MORRIS-PRATT [1] Rio Alamanda, [2] Cucu Suhery, [3] Yulrio Brianorman [1][2][3]
APLIKASI PENDETEKSI PLAGIAT TERHADAP KARYA TULIS BERBASIS WEB MENGGUNAKAN NATURAL LANGUAGE PROCESSING DAN ALGORITMA KNUTH-MORRIS-PRATT [1] Rio Alamanda, [2] Cucu Suhery, [3] Yulrio Brianorman [1][2][3]
BAB I PENDAHULUAN. sebagai sumber pertama dan utama yang banyak memuat ajaran-ajaran yang
 BAB I PENDAHULUAN 1.1 Latar Belakang Al-qur an dan hadits sebagai sumber pedoman hidup, sumber hukum dan ajaran dalam islam antara satu dengan yang lain tidak dapat dipisahkan. Al qur an sebagai sumber
BAB I PENDAHULUAN 1.1 Latar Belakang Al-qur an dan hadits sebagai sumber pedoman hidup, sumber hukum dan ajaran dalam islam antara satu dengan yang lain tidak dapat dipisahkan. Al qur an sebagai sumber
STMIK GI MDP. Program Studi Teknik Informatika Skripsi Sarjana Komputer Semester Ganjil Tahun 20010/2011
 STMIK GI MDP Program Studi Teknik Informatika Skripsi Sarjana Komputer Semester Ganjil Tahun 20010/2011 PENERAPAN METODE CLUSTERING HIRARKI AGGLOMERATIVE UNTUK KATEGORISASI DOKUMEN PADA WEBSITE SMA NEGERI
STMIK GI MDP Program Studi Teknik Informatika Skripsi Sarjana Komputer Semester Ganjil Tahun 20010/2011 PENERAPAN METODE CLUSTERING HIRARKI AGGLOMERATIVE UNTUK KATEGORISASI DOKUMEN PADA WEBSITE SMA NEGERI
BAB 1 PENDAHULUAN. 1.1 Latar Belakang
 BAB 1 PENDAHULUAN 1.1 Latar Belakang Berkomunikasi satu sama lain merupakan salah satu sifat dasar manusia. Komunikasi berfungsi sebagai sarana untuk saling berinteraksi satu sama lain. Manusia terkadang
BAB 1 PENDAHULUAN 1.1 Latar Belakang Berkomunikasi satu sama lain merupakan salah satu sifat dasar manusia. Komunikasi berfungsi sebagai sarana untuk saling berinteraksi satu sama lain. Manusia terkadang
BAB IV METODOLOGI PENELITIAN. Penelitian ini dilakukan dengan melalui empat tahap utama, dimana
 BAB IV METODOLOGI PENELITIAN Penelitian ini dilakukan dengan melalui empat tahap utama, dimana tahap pertama adalah proses pengumpulan dokumen teks yang akan digunakan data training dan data testing. Kemudian
BAB IV METODOLOGI PENELITIAN Penelitian ini dilakukan dengan melalui empat tahap utama, dimana tahap pertama adalah proses pengumpulan dokumen teks yang akan digunakan data training dan data testing. Kemudian
BAB I PENDAHULUAN. dengan mudah diduplikasi (Schleimer, Wilkerson, & Aiken, 2003). Dengan
. Dengan") BAB I PENDAHULUAN 1.1 Latar Belakang Semakin berkembangnya teknologi informasi saat ini, dokumen digital dapat dengan mudah diduplikasi (Schleimer, Wilkerson, & Aiken, 2003). Dengan mudahnya duplikasi
BAB I PENDAHULUAN 1.1 Latar Belakang Semakin berkembangnya teknologi informasi saat ini, dokumen digital dapat dengan mudah diduplikasi (Schleimer, Wilkerson, & Aiken, 2003). Dengan mudahnya duplikasi
BAB I PENDAHULUAN. yang cepat sangat berpengaruh terhadap gaya hidup manusia. Pertukaran
 BAB I PENDAHULUAN 1.1 Latar Belakang Dewasa ini, perkembangan teknologi yang pesat dan penyebaran internet yang cepat sangat berpengaruh terhadap gaya hidup manusia. Pertukaran informasi antara satu pihak
BAB I PENDAHULUAN 1.1 Latar Belakang Dewasa ini, perkembangan teknologi yang pesat dan penyebaran internet yang cepat sangat berpengaruh terhadap gaya hidup manusia. Pertukaran informasi antara satu pihak
Penerapan Algoritma Pattern Matching untuk Mengidentifikasi Musik Monophonic
 Penerapan Algoritma Pattern Matching untuk Mengidentifikasi Musik Monophonic Fahziar Riesad Wutono (13512012) 1 Program Studi Teknik Informatika Sekolah Teknik Elektro dan Informatika Institut Teknologi
Penerapan Algoritma Pattern Matching untuk Mengidentifikasi Musik Monophonic Fahziar Riesad Wutono (13512012) 1 Program Studi Teknik Informatika Sekolah Teknik Elektro dan Informatika Institut Teknologi
 Seminar Nasional Teknologi Informasi dan Multimedia 2013 STMIK AMIKOM Yogyakarta, 19 Januari 2013 ISSN: 1979 -.. RANCANG BANGUN REKOMENDASI PENGISIAN BORANG PROGRAM STUDI SARJANA DENGAN OBJECTIVE MATRIX
Seminar Nasional Teknologi Informasi dan Multimedia 2013 STMIK AMIKOM Yogyakarta, 19 Januari 2013 ISSN: 1979 -.. RANCANG BANGUN REKOMENDASI PENGISIAN BORANG PROGRAM STUDI SARJANA DENGAN OBJECTIVE MATRIX
BAB I PENDAHULUAN. Android merupakan salah satu mobile Operating System atau sistem
 BAB I PENDAHULUAN 1.1 Latar Belakang Masalah Android merupakan salah satu mobile Operating System atau sistem operasi untuk perangkat mobile yang berbasis linux, berupa software platform open source yang
BAB I PENDAHULUAN 1.1 Latar Belakang Masalah Android merupakan salah satu mobile Operating System atau sistem operasi untuk perangkat mobile yang berbasis linux, berupa software platform open source yang
BAB 2 LANDASAN TEORI
 BAB 2 LANDASAN TEORI Pada bab ini akan dibahas tentang teori-teori dan konsep dasar yang mendukung pembahasan dari sistem yang akan dibuat. 2.1. Katalog Perpustakaan Katalog perpustakaan merupakan suatu
BAB 2 LANDASAN TEORI Pada bab ini akan dibahas tentang teori-teori dan konsep dasar yang mendukung pembahasan dari sistem yang akan dibuat. 2.1. Katalog Perpustakaan Katalog perpustakaan merupakan suatu
BAB 1 PENDAHULUAN. Universitas Sumatera Utara
 BAB 1 PENDAHULUAN 1.1 Latar Belakang Dunia pendidikan dan ilmu pengetahuan pada saat ini semakin berkembang dengan pesat yang disertai dengan semakin banyaknya arus informasi dan ilmu pengetahuan ilmiah
BAB 1 PENDAHULUAN 1.1 Latar Belakang Dunia pendidikan dan ilmu pengetahuan pada saat ini semakin berkembang dengan pesat yang disertai dengan semakin banyaknya arus informasi dan ilmu pengetahuan ilmiah
DETEKSI SIMILARITAS DOKUMEN ABSTRAK TUGAS AKHIR MENGGUNAKAN METODE LEVENSHTEIN DISTANCE
 DETEKSI SIMILARITAS DOKUMEN ABSTRAK TUGAS AKHIR MENGGUNAKAN METODE LEVENSHTEIN DISTANCE Abdul Najib 1), Karyo Budi Utomo 2) 1), 2) Jurusan Teknologi Informasi, Politeknik Negeri Samarinda Email: abdulnajib@polnes.ac.id
DETEKSI SIMILARITAS DOKUMEN ABSTRAK TUGAS AKHIR MENGGUNAKAN METODE LEVENSHTEIN DISTANCE Abdul Najib 1), Karyo Budi Utomo 2) 1), 2) Jurusan Teknologi Informasi, Politeknik Negeri Samarinda Email: abdulnajib@polnes.ac.id
JURNAL TEKNIK ITS Vol. 5, No. 2, (2016) ISSN: ( Print)
 ISSN: ( Print)") A625 Evaluasi Sistem Pendeteksi Intrusi Berbasis Anomali dengan N-gram dan Incremental Learning I Made Agus Adi Wirawan, Royyana Muslim Ijtihadie, dan Baskoro Adi Pratomo Jurusan Teknik Informatika, Fakultas
A625 Evaluasi Sistem Pendeteksi Intrusi Berbasis Anomali dengan N-gram dan Incremental Learning I Made Agus Adi Wirawan, Royyana Muslim Ijtihadie, dan Baskoro Adi Pratomo Jurusan Teknik Informatika, Fakultas
Algoritme Pencocokan String (String Matching) Menurut Black (2016), string adalah susunan dari karakter-karakter (angka, alfabet, atau karakte
 Menurut Black (2016), string adalah susunan dari karakter-karakter (angka, alfabet, atau karakte") II KAJIAN PUSTAKA 2! KAJIAN PUSTAKA 2.1! Ejaan Bahasa Indonesia Ejaan menurut Kamus Besar Bahasa Indonesia (2016) adalah kaidah cara menggambarkan bunyi-bunyi (kata, kalimat, dan sebagainya) dalam tulisan
II KAJIAN PUSTAKA 2! KAJIAN PUSTAKA 2.1! Ejaan Bahasa Indonesia Ejaan menurut Kamus Besar Bahasa Indonesia (2016) adalah kaidah cara menggambarkan bunyi-bunyi (kata, kalimat, dan sebagainya) dalam tulisan
Pembuatan Kakas Bantu untuk Mendeteksi Ketidaksesuaian Diagram Urutan (Sequence Diagram) dengan Diagram Kasus Penggunaan (Use Case Diagram)
 dengan Diagram Kasus Penggunaan (Use Case Diagram)") JURNAL TEKNIK ITS Vol. 6, No. 1, (2017) ISSN: 2337-3539 (2301-9271 Print) A-71 Pembuatan Kakas Bantu untuk Mendeteksi Ketidaksesuaian Diagram Urutan (Sequence Diagram) dengan Diagram Kasus Penggunaan (Use
JURNAL TEKNIK ITS Vol. 6, No. 1, (2017) ISSN: 2337-3539 (2301-9271 Print) A-71 Pembuatan Kakas Bantu untuk Mendeteksi Ketidaksesuaian Diagram Urutan (Sequence Diagram) dengan Diagram Kasus Penggunaan (Use
JURNAL ANALISA PENGENALAN CITRA WAJAH MENGGUNAKAN BENTUK HIDUNG DENGAN METODE MINKOWSKI DISTANCE
 JURNAL ANALISA PENGENALAN CITRA WAJAH MENGGUNAKAN BENTUK HIDUNG DENGAN METODE MINKOWSKI DISTANCE Analysis of the facial image pattern recognition using the shape of the nose with the method minkowski distance
JURNAL ANALISA PENGENALAN CITRA WAJAH MENGGUNAKAN BENTUK HIDUNG DENGAN METODE MINKOWSKI DISTANCE Analysis of the facial image pattern recognition using the shape of the nose with the method minkowski distance
Jurnal Ilmiah Sains, Teknologi, Ekonomi, Sosial dan Budaya Vol. 1 No. 4 Desember 2017
 TEXT MINING DALAM PENENTUAN KLASIFIKASI DOKUMEN SKRIPSI DI PRODI TEKNIK INFORMATIKA FAKULTAS ILMU KOMPUTER BERBASIS WEB Teuku Muhammad Johan dan Riyadhul Fajri Program Studi Teknik Informatika Fakultas
TEXT MINING DALAM PENENTUAN KLASIFIKASI DOKUMEN SKRIPSI DI PRODI TEKNIK INFORMATIKA FAKULTAS ILMU KOMPUTER BERBASIS WEB Teuku Muhammad Johan dan Riyadhul Fajri Program Studi Teknik Informatika Fakultas
DETEKSI PLAGIARISME SOURCE CODE BERBASIS ABSTRACT SYNTAX TREE
 DETEKSI PLAGIARISME SOURCE CODE BERBASIS ABSTRACT SYNTAX TREE TUGAS AKHIR Sebagai Persyaratan Guna Meraih Gelar Sarjana Strata 1 Teknik Informatika Universitas Muhammadiyah Malang SETIYA PUTRA UTAMA 201210370311278
DETEKSI PLAGIARISME SOURCE CODE BERBASIS ABSTRACT SYNTAX TREE TUGAS AKHIR Sebagai Persyaratan Guna Meraih Gelar Sarjana Strata 1 Teknik Informatika Universitas Muhammadiyah Malang SETIYA PUTRA UTAMA 201210370311278
BAB I PENDAHULUAN. Dari tahun ke tahun sudah tidak dapat dipungkiri bahwa teknologi informasi
 BAB I PENDAHULUAN 1.1 Latar Belakang Masalah Dari tahun ke tahun sudah tidak dapat dipungkiri bahwa teknologi informasi mengalami kemajuan yang sangat pesat. Ini merupakan bukti bahwa manusia senantiasa
BAB I PENDAHULUAN 1.1 Latar Belakang Masalah Dari tahun ke tahun sudah tidak dapat dipungkiri bahwa teknologi informasi mengalami kemajuan yang sangat pesat. Ini merupakan bukti bahwa manusia senantiasa
BAB III ANALISIS DAN PERANCANGAN
 BAB III ANALISIS DAN PERANCANGAN 3.1 Analisis Analisis atau bisa juga disebut dengan Analisis sistem (systems analysis) dapat didefinisikan sebagai penguraian dari suatu sistem informasi yang utuh ke dalam
BAB III ANALISIS DAN PERANCANGAN 3.1 Analisis Analisis atau bisa juga disebut dengan Analisis sistem (systems analysis) dapat didefinisikan sebagai penguraian dari suatu sistem informasi yang utuh ke dalam
Klasifikasi Berita Lokal Radar Malang Menggunakan Metode Naïve Bayes Dengan Fitur N-Gram
 Jurnal Ilmiah Teknologi dan Informasia ASIA (JITIKA) Vol.10, No.1, Februari 2016 ISSN: 0852-730X Klasifikasi Berita Lokal Radar Malang Menggunakan Metode Naïve Bayes Dengan Fitur N-Gram Denny Nathaniel
Jurnal Ilmiah Teknologi dan Informasia ASIA (JITIKA) Vol.10, No.1, Februari 2016 ISSN: 0852-730X Klasifikasi Berita Lokal Radar Malang Menggunakan Metode Naïve Bayes Dengan Fitur N-Gram Denny Nathaniel
BAB I PENDAHULUAN. Tetapi dewasa ini banyak bahasa dari berbagai suku bangsa yang digunakan untuk
 BAB I PENDAHULUAN I.1. Latar Belakang Bahasa merupakan jembatan berkomunikasi. Dinegara ini banyak beragam bahasa yang berbeda. Salah satunya adalah bahasa Indonesia, bahasa persatuan. Tetapi dewasa ini
BAB I PENDAHULUAN I.1. Latar Belakang Bahasa merupakan jembatan berkomunikasi. Dinegara ini banyak beragam bahasa yang berbeda. Salah satunya adalah bahasa Indonesia, bahasa persatuan. Tetapi dewasa ini
BAB I PENDAHULUAN I-1
 BAB I PENDAHULUAN I.1 Latar Belakang Masalah Tugas Akhir atau Skripsi adalah salah satu syarat dari masa akhir perkuliahan. Tugas Akhir di beberapa prodi memiliki beberapa kategori, salah satunya di prodi
BAB I PENDAHULUAN I.1 Latar Belakang Masalah Tugas Akhir atau Skripsi adalah salah satu syarat dari masa akhir perkuliahan. Tugas Akhir di beberapa prodi memiliki beberapa kategori, salah satunya di prodi
KOMPARASI ALGORITMA C4.5 DENGAN NAÏVE BAYES DALAM PENGKLASIFIKASIAN TINGKAT PENDIDIKAN ANAK MISKIN. Andi Nurhayati 1, Andi Baso Kaswar 2
 KOMPARASI ALGORITMA C4.5 DENGAN NAÏVE BAYES DALAM PENGKLASIFIKASIAN TINGKAT PENDIDIKAN ANAK MISKIN Andi Nurhayati 1, Andi Baso Kaswar 2 1),2) Teknik Informatika Universitas Cokroaminoto Palopo Jl Latammacelling
KOMPARASI ALGORITMA C4.5 DENGAN NAÏVE BAYES DALAM PENGKLASIFIKASIAN TINGKAT PENDIDIKAN ANAK MISKIN Andi Nurhayati 1, Andi Baso Kaswar 2 1),2) Teknik Informatika Universitas Cokroaminoto Palopo Jl Latammacelling
UKDW. Bab 1 PENDAHULUAN
 Bab 1 PENDAHULUAN 1.1 Latar Belakang Skripsi merupakan tugas akhir mahasiswa S1 yang bersifat mandiri dan wajib untuk mendapatkan gelar sarjana. Seorang mahasiswa yang akan menulis tugas akhir harus mencari
Bab 1 PENDAHULUAN 1.1 Latar Belakang Skripsi merupakan tugas akhir mahasiswa S1 yang bersifat mandiri dan wajib untuk mendapatkan gelar sarjana. Seorang mahasiswa yang akan menulis tugas akhir harus mencari
BAB I PENDAHULUAN. 1.1 Latar Belakang Masalah
 BAB I PENDAHULUAN 1.1 Latar Belakang Masalah Kemajuan teknologi yang telah sampai pada pencapaian yang tinggi pada saat ini memungkinkan hal tersebut dapat berdampak positif maupun negatif. Dampak positif
BAB I PENDAHULUAN 1.1 Latar Belakang Masalah Kemajuan teknologi yang telah sampai pada pencapaian yang tinggi pada saat ini memungkinkan hal tersebut dapat berdampak positif maupun negatif. Dampak positif
Implementasi Algoritma Levenshtein Pada Sistem Pencarian Judul Skripsi/Tugas Akhir
 46 JURNAL SISTEM DAN INFORMATIKA Implementasi Algoritma Levenshtein Pada Sistem Pencarian Judul Skripsi/Tugas Akhir Ida Bagus Ketut Surya Arnawa STIKOM Bali Jl.Raya Puputan No. 86 Renon, Denpasar-Bali
46 JURNAL SISTEM DAN INFORMATIKA Implementasi Algoritma Levenshtein Pada Sistem Pencarian Judul Skripsi/Tugas Akhir Ida Bagus Ketut Surya Arnawa STIKOM Bali Jl.Raya Puputan No. 86 Renon, Denpasar-Bali
PENENTUAN KEMIRIPAN TOPIK PROYEK AKHIR BERDASARKAN ABSTRAK PADA JURUSAN TEKNIK INFORMATIKA MENGGUNAKAN METODE SINGLE LINKAGE HIERARCHICAL
 PENENTUAN KEMIRIPAN TOPIK PROYEK AKHIR BERDASARKAN ABSTRAK PADA JURUSAN TEKNIK INFORMATIKA MENGGUNAKAN METODE SINGLE LINKAGE HIERARCHICAL Nur Rosyid M, Entin Martiana, Damitha Vidyastana, Politeknik Elektronika
PENENTUAN KEMIRIPAN TOPIK PROYEK AKHIR BERDASARKAN ABSTRAK PADA JURUSAN TEKNIK INFORMATIKA MENGGUNAKAN METODE SINGLE LINKAGE HIERARCHICAL Nur Rosyid M, Entin Martiana, Damitha Vidyastana, Politeknik Elektronika
BAB 1 PENDAHULUAN. 1.1 Latar Belakang
 BAB 1 PENDAHULUAN Pada bab pendahuluan ini akan diuraikan penjelasan mengenai latar belakang penelitian, rumusan masalah, batasan masalah, tujuan penelitian, manfaat penelitian, metodologi penelitian dan
BAB 1 PENDAHULUAN Pada bab pendahuluan ini akan diuraikan penjelasan mengenai latar belakang penelitian, rumusan masalah, batasan masalah, tujuan penelitian, manfaat penelitian, metodologi penelitian dan
BAB 1 PENDAHULUAN. Seiring dengan perkembangan teknologi yang begitu pesat, manusia semakin
 BAB 1 PENDAHULUAN 1.1 Latar Belakang Masalah Seiring dengan perkembangan teknologi yang begitu pesat, manusia semakin dimudahkan untuk melakukan berbagai macam hal dengan menggunakan teknologi terutama
BAB 1 PENDAHULUAN 1.1 Latar Belakang Masalah Seiring dengan perkembangan teknologi yang begitu pesat, manusia semakin dimudahkan untuk melakukan berbagai macam hal dengan menggunakan teknologi terutama
BAB I PENDAHULUAN. Jiménez-Peris, dkk dalam paper-nya yang berjudul New Technologies in
 BAB I PENDAHULUAN 1.1 Latar Belakang Perkembangan Teknologi dan Informasi telah berkembang sedemikian hebatnya. Kemajuan di bidang komputer dan internet khususnya, semakin mempercepat terjadinya perubahan
BAB I PENDAHULUAN 1.1 Latar Belakang Perkembangan Teknologi dan Informasi telah berkembang sedemikian hebatnya. Kemajuan di bidang komputer dan internet khususnya, semakin mempercepat terjadinya perubahan