TUNING PARAMETER DALAM FUNGSI OKAPI BM25 PADA MESIN PENCARI TEKS BAHASA INDONESIA TEDY SAPUTRA
|
|
|
- Hendra Halim
- 7 tahun lalu
- Tontonan:
Transkripsi

1 TUNING PARAMETER DALAM FUNGSI OKAPI BM25 PADA MESIN PENCARI TEKS BAHASA INDONESIA TEDY SAPUTRA DEPARTEMEN ILMU KOMPUTER FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR BOGOR 2013
2
3 PERNYATAAN MENGENAI SKRIPSI DAN SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA Dengan ini saya menyatakan bahwa skripsi berjudul Tuning Parameter dalam Fungsi Okapi BM25 pada Mesin Pencari Teks Bahasa Indonesia adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini. Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor. Bogor, Juli 2013 Tedy Saputra NIM G
4 ABSTRAK TEDY SAPUTRA. Tuning Parameter dalam Fungsi Okapi BM25 pada Mesin Pencari Teks Bahasa Indonesia. Dibimbing oleh JULIO ADISANTOSO. Sistem temu-kembali informasi dikembangkan dalam beragam model, seperti model peluang, model bahasa, model boolean,model ruang vektor dan lainnya. Meskipun demikian, masih sulit menetukan model manakah yang paling baik dan efisien dalam setiap kondisi pencarian. Dalam penelitian ini, akan dibandingkan dua mesin pencari yang dibuat dengan menggunakan model peluang dan model ruang vektor sebagai pembandingnya. Pada model peluang, digunakan fungsi kesamaan Okapi BM25 yang memiliki suatu variabel yang dapat diubahubah nilainya, yang disebut dengan tuning parameter. Modifikasi nilai dari tuning parameter ini bertujuan untuk meningkatkan kinerja dari model peluang dan juga sekaligus membandingkan kinerjanya dengan model lain, seperti model ruang vektor. Modifikasi nilai dari tuning parameter meningkatkan nilai rata-rata presisi dari sistem, yang pada awalnya sebesar menjadi Selanjutnya, model peluang juga mengungguli model ruang vektor yang memiliki nilai ratarata presisi sebesar Kata kunci: model peluang, model ruang vektor, Okapi BM25, tuning parameter ABSTRACT TEDY SAPUTRA. Tuning Parameters in Okapi BM25 Function on Indonesian Text Search Engine. Supervised by JULIO ADISANTOSO. Information retrieval system was developed using various models, such as probabilistic models, language models, boolean models, vector-space models and many more. Thus, it s problematic to determine which models is the best and the most efficient in every search condition. In this study, two models were developed and compared: probabilistic model and vector-space model. The probabilistic model has Okapi BM25 similarity function with parameters that are subject to fine tuning to seek for better performance. Fine tuning the parameters has made the probabilistic model s average precision increases from to Further, this model also outperformed the vector-space model with average precision Keywords: Okapi BM25, probabilistic models, tuning parameters, vector space models
5 TUNING PARAMETER DALAM FUNGSI OKAPI BM25 PADA MESIN PENCARI TEKS BAHASA INDONESIA TEDY SAPUTRA Skripsi sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer pada Departemen Ilmu Komputer DEPARTEMEN ILMU KOMPUTER FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR BOGOR 2013
6 Penguji: 1. Ahmad Ridha, SKom MS 2. Dr Irman Hermadi, SKom MSc
7 Judul Skripsi : Tuning Parameter dalam Fungsi Okapi BM25 pada Mesin Pencari Teks Bahasa Indonesia Nama : Tedy Saputra NIM : G Disetujui oleh Ir Julio Adisantoso, MKom Pembimbing Diketahui oleh Dr Ir Agus Buono, MSi MKom Ketua Departemen Tanggal Lulus:
8 PRAKATA Puji dan syukur penulis panjatkan kepada Allah subhanahu wa ta ala atas segala karunia-nya sehingga karya ilmiah ini berhasil diselesaikan. Tema yang dipilih dalam penelitian yang dilaksanakan sejak bulan November 2012 ini ialah temu-kembali informasi, dengan judul Tuning Parameter dalam Fungsi Okapi BM25 pada Mesin Pencari Teks Bahasa Indonesia. Terima kasih penulis ucapkan kepada ayah, ibu, serta seluruh keluarga atas segala doa dan kasih sayangnya. Terima Kasih kepada Bapak Ir Julio Adisantoso MKom selaku pembimbing, Bapak Ahmad Ridha SKom MS dan Bapak Dr Irman Hermadi SKom MSc selaku penguji, juga teman-teman seperjuangan Edo Apriyadi, Achmad Manshur Zuhdi, Rahmatika Dewi, Fitria Rahmadina, Arini Daribti Putri, dan Damayanti Elisabeth Sibarani atas kebersamaannya selama ini. Ungkapan terima kasih juga disampaikan kepada Widya Retno Utami beserta keluarga atas semangat, doa, dan motivasinya selama ini. Semoga karya ilmiah ini bermanfaat. Bogor, Juli 2013 Tedy Saputra
9 DAFTAR ISI DAFTAR TABEL viii DAFTAR GAMBAR viii DAFTAR LAMPIRAN viii PENDAHULUAN 1 Latar Belakang 1 Perumusan Masalah 2 Tujuan Penelitian 2 Manfaat Penelitian 2 Ruang Lingkup Penelitian 3 METODE 3 Pengumpulan Dokumen 4 Tokenisasi 4 Pembuangan Stopwords 5 Pemilihan Fitur 5 Pembobotan 6 Similarity 7 Evaluasi 9 HASIL DAN PEMBAHASAN 10 Pemrosesan Dokumen 10 Praproses 11 Similarity 12 Evaluasi 14 Perbandingan Kinerja Model Peluang dengan Model Ruang Vektor 16 SIMPULAN DAN SARAN 18 Simpulan 18 Saran 18 DAFTAR PUSTAKA 18 LAMPIRAN 21
10 DAFTAR TABEL 1 Confusion Matrix 9 2 Nilai AVP BM25 sebelum dan sesudah tuning 15 3 Nilai AVP pada BM25 dan VSM 17 DAFTAR GAMBAR 1 Diagram metodologi 3 2 Contoh dokumen 4 3 Tabel document pada database 10 4 Tabel words pada database 11 5 Implementasi fungsi kesamaan Okapi BM Algoritme pada fungsi kesamaan Okapi BM Algoritme pada fungsi kesamaan cosine 14 8 Perbandingan grafik recall-precision BM Grafik recall-precision dari BM25 dan VSM 17 DAFTAR LAMPIRAN 1 Antarmuka implementasi 21 2 Gugus query dan jawaban 22 3 Nilai tuning parameter yang akan diujikan 31 4 Hasil tuning parameter yang diujikan beserta nilai AVP nya 32 5 Hasil perhitungan precision pada eleven standard recall 33 6 Precision setiap query pada BM Precision setiap query pada BM25 dengan tuning tertinggi 36 8 Precision setiap query pada vector space model 38
11 PENDAHULUAN Latar Belakang Penggunaan internet yang semakin populer saat ini mempengaruhi jumlah informasi yang semakin lama semakin besar keragamannya. Informasi dapat dicari dengan mudah apabila jumlahnya sedikit, akan tetapi sangat sulit untuk mencari banyak informasi yang dibutuhkan dengan waktu yang singkat secara manual. Oleh sebab itu dibutuhkan suatu sistem yang dapat membantu user untuk mendapatkan informasi yang dibutuhkan secara cepat dan mudah yang kemudian disebut dengan sistem temu-kembali informasi (information retrieval system). Sistem temu-kembali informasi (information retrieval system) adalah sistem pencarian informasi pada dokumen, pencarian untuk meta data di dalam database, baik relasi database yang stand-alone atau hypertext database yang terdapat pada jaringan seperti internet (Buckley et al. 1994). Sistem temu-kembali informasi berhubungan dengan pencarian dari informasi yang isinya tidak memiliki struktur. Begitu juga dengan dengan ekspresi dari kebutuhan pengguna yang disebut dengan query, juga tidak memiliki struktur. Hal inilah yang membedakan antara sistem temu-kembali informasi dengan sistem basis data. Penerapan aplikasi dari sistem temu-kembali informasi adalah search engine atau mesin pencari yang terdapat pada jaringan internet (Harman 1992). Mesin pencari (search engine) adalah salah satu sistem temu-kembali informasi yang mengolah informasi dan mengambil daftar, peringkat maupun urutan dari dokumen berdasarkan relevansi antara query dengan dokumen yang dibutuhkan dalam rangka memenuhi pencarian yang dilakukan oleh user. Suatu mesin pencarian harus mampu menggunakan kesamaan (similarity) antara kata pencarian yang diinputkan oleh user dengan setiap dokumen yang ada. Saat ini banyak model-model yang digunakan untuk suatu sistem temukembali informasi, salah satunya adalah model peluang. Sesuai dengan namanya, model peluang bertujuan untuk mengevaluasi setiap kata pencarian (query), berdasarkan peluang suatu dokumen relevan dengan kata pencarian yang diberikan. Model peluang pada sistem temu-kembali informasi menghitung koefisien kesamaan antara sebuah query dengan sebuah dokumen sebagai sebuah peluang bahwa dokumen tersebut akan relevan dengan suatu query. Model peluang akan memberikan nilai peluang pada setiap kata yang menjadi komponen dalam suatu query, dan kemudian menggunakan nilai-nilai tersebut untuk menghitung peluang akhir bahwa suatu dokumen relevan dengan suatu query. Pada model peluang, banyak terdapat fungsi-fungsi kesamaan yang digunakan, yaitu fungsi Best Match (BM) seperti BM1, BM11, BM15, BM25 dan lain sebagainya. Akan tetapi, fungsi OKAPI BM25 merupakan fungsi yang memiliki tingkat keberhasilan terbaik sampai saat ini. BM25 merupakan hasil dari percobaan beberapa variasi fungsi Best Match pada model peluang. BM25 memiliki fungsi yang sesuai dengan 3 prinsip pembobotan yang baik, yaitu memiliki inverse document frequecy (idf), term frequency (tf), dan memiliki fungsi normalisasi dari panjang dokumen (document length normalization) (Chen 2011).
12 2 Penelitian ini akan difokuskan menggunakan model peluang yang menggunakan fungsi kesamaan OKAPI BM25 dengan melakukan modifikasi pada nilai tuning parameter. Tuning parameter adalah suatu variabel yang dapat diubah-ubah nilainya sesuai dengan kebutuhan dengan tujuan untuk mendapatkan hasil pencarian yang lebih baik. Penelitian ini dilakukan untuk menguji apakah pencarian dengan model peluang dapat menghasilkan banyak dokumen yang relevan terutama untuk dokumen yang menggunakan Bahasa Indonesia. Selain itu akan dibuktikan juga pengaruh dari perubahan tuning parameter yang akan dimodifikasi sedemikian rupa untuk mendapatkan hasil pencarian dengan nilai yang lebih baik. Kemudian akan dibandingkan kinerja dari sistem yang menggunakan model peluang dengan sistem yang menggunakan model lain yaitu model ruang vektor. Perumusan Masalah Penelitian ini dilakukan untuk menjawab masalah-masalah sebagai berikut: 1 Apakah model peluang dapat mengukur relevansi secara akurat antara query masukan dengan dokumen yang dibutuhkan sehingga hasil pencarian sesuai dengan apa yang user inginkan? 2 Apakah modifikasi dari nilai tuning parameters dalam fungsi kesamaan OKAPI BM25 dapat menghasilkan pencarian dengan hasil evaluasi yang lebih baik? 3 Apakah model peluang lebih baik apabila dibandingkan dengan model ruang vektor? 4 Apakah model peluang cocok digunakan untuk melakukan pencarian pada dokumen yang menggunakan Bahasa Indonesia? Tujuan Penelitian Penelitian ini bertujuan untuk menguji seberapa besar pengaruh modifikasi nilai dari tuning parameter yang ada dalam fungsi kesamaan OKAPI BM25 terhadap evaluasi dari hasil pencarian. Selain itu juga akan dibandingkan kinerja antara model peluang dengan model lain yaitu model ruang vektor dalam pencarian dokumen yang menggunakan Bahasa Indonesia. Manfaat Penelitian Dengan dilakukannya penelitian ini, diharapkan dapat diketahui efektifitas dari modifikasi tuning parameter yang ada dalam fungsi OKAPI BM25 terhadap hasil pencarian. Selain itu, dapat ditentukannya model manakah yang lebih baik untuk melakukan pencarian dokumen teks Bahasa Indonesia sehingga mendapatkan hasil pencarian dengan tingkat relevansi yang cukup tinggi.
13 3 Ruang Lingkup Penelitian Fokus dari penelitian ini adalah menguji dua model sistem temu-kembali informasi, yaitu model peluang dan model ruang vektor. Fungsi kesamaan yang digunakan pada model peluang adalah fungsi kesamaan OKAPI BM25 dengan modifikasi nilai pada tuning parameter. Dokumen yang digunakan dalam penelitian ini adalah dokumen yang menggunakan Bahasa Indonesia. METODE Sistem temu-kembali informasi pada prinsipnya merupakan suatu sistem yang sederhana. Misalkan terdapat sekumpulan dokumen dan seorang user yang memformulasikan sebuah pertanyaan (query). Jawaban dari pertanyaan atau query tersebut adalah sekumpulan dokumen yang relevan dengan query dari user. Sistem temu-kembali informasi pada dasarnya dibagi menjadi dua komponen utama, yaitu sistem pengindeksan (indexing) yang menghasilkan basis data sistem dan temu-kembali yang merupakan gabungan dari user interface dan look-uptable (Sudirman dan Kodar 2012). Metode pada penelitian ini menggunakan model peluang yang merupakan salah satu model pada temu-kembali informasi. Model peluang tersebut akan dibandingkan dengan model lain yaitu model ruang vektor. Metode yang akan dilakukan pada penelitian ini dicantumkan pada Gambar 1. Gambar 1 Diagram metodologi

14 4 Tahapan dari metode diawali dengan pengumpulan dokumen, kemudian dilanjutkan dengan proses indexing. Indexing adalah sebuah proses dimana dilakukan pengindeksan pada sekumpulan dokumen yang nantinya akan menjadi informasi yang ditujukan untuk user. Indexing dapat dilakukan secara manual maupun secara otomatis. Adapun tahapan dari indexing terdiri dari tokenisasi, pembuangan stopwords, pemilihan fitur, dan pembobotan (term weighting). Selanjutnya adalah melihat similarity, yaitu kesamaan hasil yang didapatkan dari dokumen dengan query yang dimasukkan. Tahap akhir yang dilakuan adalah melakukan evaluasi dari kedua model tersebut. Pengumpulan Dokumen Tahapan awal yang dilakukan adalah melakukan pengumpulan dokumen yang akan dijadikan sebagai data uji dari penelitian ini. Dokumen yang digunakan adalah kumpulan dokumen (korpus) yang tersedia di Laboratorium Temu- Kembali Informasi hasil penelitian Adisantoso dan Ridha (2004). Di dalam korpus tersebut tersedia 1000 dokumen pertanian berbahasa Indonesia berikut dengan sejumlah query dan gugusan jawaban yang relevan dengan query tersebut. Query dan gugus jawaban yang relevan dicantumkan pada Lampiran 2. Selain itu ditambahkan juga dokumen lain yang didapatkan dari berbagai portal berita secara online yang berjumlah 300 dokumen. Total dokumen yang digunakan adalah 1300 dokumen yang memiliki format plain teks dengan struktur XML (Extensible Markup Language). Contoh dokumen yang digunakan dapat dilihat pada Gambar 2. Gambar 2 Contoh dokumen Tokenisasi Tokenisasi adalah proses memotong teks input menjadi unit-unit terkecil yang disebut token dan pada saat yang sama dimungkinkan untuk membuang karakter tertentu, seperti tanda baca (Manning et al. 2008). Token tersebut dapat berupa suatu kata, angka, atau suatu tanda baca. Proses ini bertujuan untuk mempermudah dalam mengetahui frekuensi kemunculan tiap token pada suatu dokumen. Pada umumnya token yang dipakai pada suatu teks input adalah kata
15 (term). Kata adalah sekumpulan karakter alfanumerik yang saling terhubung dan dipisahkan oleh whitespace, di antaranya adalah spasi, tab, dan newline. Proses tokenisasi dilakukan dengan bantuan Sphinx Search karena tokenisasi dengan Sphinx tergolong mudah dan cepat dalam prosesnya. Selain itu Sphinx juga mendukung pemrosesan dokumen yang berasal dari database. Sphinx Search digunakan hanya pada saat proses tokenisasi dan pada proses pembobotan yaitu mencari nilai dari Term Frequency (TF). 5 Pembuangan Stopwords Proses tokenisasi merupakan proses yang sangat penting dalam indexing. Setiap token didaftar dan dihitung frekuensi kemunculannya pada suatu dokumen. Dalam proses tokenisasi akan terlihat kata mana saja yang sering muncul dan kata mana saja yang jarang muncul dalam dokumen yang di tokenisasi. Untuk stopwords pada dokumen Bahasa Indonesia seperti dan, yang, tetapi, sedangkan, sebagaimana, selanjutnya dan lainnya dapat dipastikan bahwa kemunculan katakata tersebut akan banyak sekali ditemukan. Kata-kata tersebut juga bukanlah merupakan kata yang penting. Oleh sebab itu proses indexing selanjutnya adalah proses pembuangan kata-kata yang tidak dapat dijadikan sebagai penciri dari suatu dokumen yang disebut dengan stopwords. Stopwords yang terdapat di dalam Bahasa Indonesia sangat banyak jumlahnya. Stopwords tersebut bisa berasal dari kata hubung, kata awalan, kata penegasan dan lain sebagainya. Stopwords yang digunakan pada penelitian ini sudah merupakan satu package dengan korpus yang tersedia pada Laboratorium Temu Kembali Informasi Ilmu Komputer IPB. Stopwords yang digunakan tersebut berjumlah sekitar 732 kata. Pemilihan Fitur Berdasarkan pernyataan dari Luhn (1958) atau yang biasa dikenal sebagai Luhn Ideas, bahwa kata-kata yang paling umum dan paling tidak umum adalah tidak signifikan untuk indexing. Kata-kata yang tidak dapat dijadikan sebagai penciri dari suatu dokumen adalah kata-kata yang kemunculannya sangat sering dan juga kata-kata yang kemunculannya sangat jarang pada sebuah dokumen. Oleh sebab itu kata-kata dengan frekuensi kemunculan yang cukup merupakan kata-kata yang paling baik digunakan sebagai penciri dari suatu dokumen. Pemilihan fitur (feature selection) adalah tahapan dimana term yang didapatkan dari hasil tokenisasi dan telah melalui proses pembuangan stopwords diseleksi kembali berdasarkan frekuensi kemunculan dari kata-kata tersebut. Selain stopwords yang sudah jelas bukan merupakan kata yang penting, masih ada kata-kata lain yang bisa diseleksi kembali. Kata-kata tersebut adalah kata-kata yang bukan merupakan kata yang penting dan tidak dapat dijadikan sebagai ciri pada sebuah dokumen. Dengan dilakukannya pemilihan fitur maka kata yang akan diindeks menjadi lebih sedikit sehingga akan mengurangi beban perhitungan pada
16 6 pembobotan kata. Berkurangnya jumlah indeks juga mempengaruhi kecepatan dari proses information retrieval itu sendiri. Pembobotan Pembobotan merupakan proses pemberian bobot/nilai pada term yang ada pada dokumen. Tujuan dari pembobotan adalah untuk memberikan suatu nilai pada suatu term dimana nilai tersebut nantinya akan merepresentasikan kemiripan (similarity) dari suatu query dengan suatu dokumen. Metode pembobotan yang digunakan pada sistem temu-kembali informasi berbeda-beda dan sangat beragam. Metode pembobotan yang umum dan paling sering digunakan adalah metode pembobotan berdasarkan term frequency (TF) dan inverse document frequency (IDF). TF adalah teknik pembobotan dimana kemunculan dari suatu term diperhitungkan dalam suatu dokumen d. Dengan kata lain, bobot dari term tersebut adalah bergantung dari seberapa banyak term tersebut muncul dalam suatu dokumen d (Manning et al. 2008). Teknik pembobotan term frequency menjadi tidak konsisten ketika suatu dokumen memiliki panjang dokumen yang berbeda-beda. Dokumen dengan panjang dokumen yang lebih besar otomatis akan memiliki frekuensi kemunculan term yang lebih banyak dibandingkan dengan dokumen yang panjangnya lebih sedikit. Padahal belum tentu term yang sering muncul itu merupakan kata penciri dari dokumen tersebut. IDF merupakan suatu teknik pembobotan dengan memperhitungkan jumlah dokumen yang memiliki term t serta membandingkannya dengan jumlah dokumen yang ada secara keseluruhan. IDF dicari dengan menggunakan rumus sebagai berikut: Idf t = log N n t dengan Idf t adalah nilai IDF untuk term t, N adalah jumlah dokumen dalam koleksi, dan n t adalah jumlah dokumen yang memiliki term t. Dari kedua pembobotan tersebut, terbentuklah sistem pembobotan gabungan yang dikenal dengan pembobotan tf.idf, yaitu penggabungan antara TF dan IDF dengan mengalikan kedua rumusnnya sebagai berikut: (tf.idf) t,d = f d,t idf t dengan (tf.idf) t,d adalah nilai tf.idf dari term t pada dokumen d, f d,t adalah jumlah term t pada dokumen d, dan idf t adalah nilai idf dari term t. Dengan kata lain, (tf.idf) t,d menandakan bahwa term t pada dokumen d adalah : 1 Tertinggi ketika t muncul berkali-kali dalam sejumlah kecil dokumen. 2 Rendah ketika t muncul lebih sedikit dalam suatu dokumen atau muncul pada banyak dokumen. 3 Terendah ketika t muncul pada hampir setiap dokumen (Manning et al. 2008).
17 7 Similarity Proses selanjutnya setelah dilakukan pembobotan adalah similarity. Nilainilai yang didapatkan dari proses pembobotan akan digunakan kembali pada perhitungan dari similarity. Nilai-nilai dari perhitungan similarity tersebut akan membentuk suatu sistem ranking, yang akan mengurutkan dokumen-dokumen berdasarkan tingkat kemiripan tertinggi ke tingkat kemiripan terendah. Ranking adalah mekanisme pengurutan dokumen-dokumen berdasarkan tingkat relevansi antara dokumen dengan query yang diberikan oleh pengguna. Adanya proses similarity dan sistem ranking menyebabkan adanya kecenderungan dari sistem temu-kembali informasi untuk mengarah kepada suatu model information retrieval (IR). Penentuan ataupun perhitungan similarity dari suatu mesin pencari didasarkan pada suatu model IR tertentu. Model dari IR beragam jenisnya seperti model peluang, model ruang vektor, model boolean, model bahasa, dan modelmodel lainnya. Penelitian ini hanya akan membahas pada model peluang dan model ruang vektor. Model Ruang Vektor Model yang sering digunakan dalam temu-kembali informasi adalah model ruang vektor (vector space model). Model ruang vektor adalah model yang berbasis token. Pada model ruang vektor dimungkinkan adanya partial matching sehingga model ini juga dapat mengenali dokumen yang agak relevan dengan query. Selain itu, pada model ruang vektor juga telah mendukung adanya pemeringkatan dokumen berdasarkan kemiripannya. Model pemeringkatan yang dilakukan adalah dengan melakukan scoring pada dokumen. Dokumen diurutkan berdasarkan kerelevanannya dari yang paling relevan ke yang paling tidak relevan. Untuk dokumen yang memiliki score paling tinggi, dokumen itulah yang paling relevan dengan query yang diberikan, begitupun sebaliknya. Model ruang vektor menentukan kemiripan (similarity) antara dokumen dengan query dengan cara merepresentasikannya ke dalam bentuk vektor. Tiap kata yang ditemukan pada dokumen dan query diberi bobot dan disimpan sebagai elemen dari sebuah vektor. Model ruang vektor menggunakan ukuran kesamaan cosine (cosine similarity) yang digunakan untuk menghitung kemiripan antara dokumen dan query masukan yang terdiri atas beberapa term. Sebagai contoh terdapat query q dan dokumen d, maka ukuran kesamaan cosine antara query dan dokumen adalah: sim(q,d) = V q V d V q V d (1) dengan V q adalah nilai tf.idf untuk query, V d adalah nilai tf.idf untuk dokumen, V q adalah panjang Euclid query, dan V d adalah panjang Euclid dokumen. Nilai tf.idf untuk query dan dokumen dicari dan kedua nilai tersebut dikalikan. Hasil perkalian dari kedua nilai tersebut dinormalisasi dengan cara membaginya dengan hasil perkalian antara panjang Euclid untuk query dan
18 8 dokumen. Nilai terbesar dari perhitungan kesamaan cosine diatas menandakan bahwa query dekat dengan dokumen tersebut. Model Peluang Model peluang, sesuai dengan namanya bertujuan untuk mengevaluasi dari setiap kata pencarian (query), berapakah kemungkinan dokumen tersebut relevan dengan query yang diberikan. Model peluang menghitung kesamaan antara sebuah query dengan sebuah dokumen sebagai sebuah peluang bahwa dokumen tersebut akan relevan dengan query tersebut. Nilai peluang akan diberikan pada setiap kata yang menjadi komponen suatu query, kemudian menyatukan setiap nilai-nilai tersebut untuk menghitung suatu nilai peluang akhir yang akan menunjukkan besar atau kecilnya relevansi antara query dengan suatu dokumen. Semakin besar nilai peluang yang dihasilkan, semakin besar pula peluang dari query tersebut relevan dengan suatu dokumen. Penelitian ini difokuskan menggunakan model peluang yang menggunakan fungsi kesamaan OKAPI BM25 dengan melakukan modifikasi pada nilai Tuning parameter. Tuning parameter adalah suatu variabel yang dapat diubah-ubah nilainya sesuai dengan kebutuhan dengan tujuan untuk mendapatkan hasil pencarian yang lebih baik. Fungsi kesamaan OKAPI BM25 adalah sebagai berikut: dan BM25 = log (N-n t) tϵq n t (k 1+1)f d,t K + f d,t K = k 1 (1-b) + b.dl d avl (k 3 +1)f q,t k 3 + f q,t (2) (3) dengan Q adalah query, N adalah jumlah dokumen dalam korpus, n t adalah jumlah dokumen yang mengandung term t, f d,t adalah jumlah term t yang muncul pada dokumen d, f q,t adalah jumlah term t yang muncul pada query q, dl d adalah jumlah term dalam dokumen d, avl adalah panjang rata-rata seluruh dokumen dalam korpus, dan k 1, k 3, b adalah tuning parameter. Seperti terlihat dalam rumus OKAPI BM25 terdapat variabel yang disebut tuning parameter, yaitu k 1, k 3, dan b. Adapun nilai tuning parameter yang direkomendasikan oleh Robertson dan Walker (1999) yang telah terbukti efektif dan memberikan keakuratan yang baik yaitu: k 1 = 1,2; k 3 = 1000; b = 0,75. Nilai tersebut akan diubah-ubah sesuai dengan kebutuhan sehingga dapat menghasilkan pencarian dengan skor kesamaan yang lebih baik. Menurut Robertson dan Walker (1999), nilai k 1 dan b masing-masing di set default 1.2 dan 0.75, akan tetapi nilai dari b yang lebih kecil terkadang dapat menguntungkan. Oleh karena itu, nilai dari b yang akan di tuning mulai dari 0.75 sampai dengan yang paling kecil yaitu 0.15 dengan interval Untuk nilai dari k 1 yang awalnya bernilai 1.2, akan di tuning dengan nilai antara 1.0 sampai dengan 2.0 dengan interval 0.2.
19 Sementara itu, nilai k 3 untuk query yang panjang, Robertson dan Walker (1999) menyarankan dengan nilai 1000 atau 7. Oleh karena pencarian yang dilakukan dihitung berdasarkan dari jumlah kata dari query yang dimasukkan dan query yang digunakan merupakan query pendek, maka query masukkan tidak memungkinkan adanya kata yang berulang. Maka, nilai dari k 3 relatif konstan apabila di set dengan nilai 1000 maupun 7. Oleh karena hal tersebut, nilai dari k 3 dibiarkan menjadi 1000 tanpa dilakukan perubahan. Proses tuning yang akan dilakukan sebanyak 30 kali dan dicantumkan pada Lampiran 3. 9 Evaluasi Terdapat dua hal mendasar yang paling sering digunakan untuk mengukur kinerja temu-kembali secara efektif, yaitu recall dan precision (Manning et al. 2008). Precision (P) adalah bagian dari dokumen yang di retrieve adalah relevan, sedangkan recall (R) adalah bagian dari dokumen relevan yang di retrieve. Perhitungan dari recall (R) dan precision (P) ditunjukkan dalam Tabel 1. Tabel 1 Confusion Matrix Relevant Not Relevant Retrieved tp fp Not Retrieved fn tn Sehingga perhitungan dari Precision dan Recall adalah sebagai berikut: Precision = tp (tp + fp) Recall = tp (tp + fn) dengan tp adalah jumlah dokumen relevan yang di retrieve, fp adalah jumlah dokumen tidak relevan yang di retrieve, dan fn adalah jumlah dokumen relevan yang tidak di retrieve. Menurut Baeza-Yates dan Ribeiro-Neto (1999), temu-kembali yang dievaluasi menggunakan beberapa kueri berbeda akan menghasilkan nilai Recall dan Precision yang berbeda untuk masing-masing query. Average Precision (AVP) dengan interpolasi maksimum diperlukan untuk menghitung rata-rata precision pada berbagai 11 tingkat recall, yaitu dari tingkat recall 0 sampai dengan 1. Perhitungan AVP ditunjukkan oleh rumus sebagai berikut: N q P (r j ) = P i(r) i=1 dengan P (r j ) adalah nilai AVP pada tingkat recall r, N q adalah jumlah query yang digunakan, dan P i (r) adalah nilai precision pada level recall r untuk query ke-i. Dari setiap percobaan tuning yang dilakukan akan dilakukan evaluasi untuk setiap 30 query yang digunakan sehingga akan didapatkan perbandingan nilai N q

20 10 AVP. Dengan didapatkannya nilai AVP pada setiap nilai tuning, dapat diketahui berapakah nilai yang menghasilkan evaluasi dengan nilai AVP paling tinggi. HASIL DAN PEMBAHASAN Pemrosesan Dokumen Dokumen yang digunakan untuk pengujian berjumlah 1300 dokumen. Sebanyak 1000 dokumen pertanian berasal dari korpus yang tersedia di Laboratorium Temu-Kembali Informasi dan 300 dokumen lainnya yang ditambahkan berasal dari portal berita online. Dokumen yang digunakan berformat plain text dengan struktur XML (Extensible Markup Language). Dokumen dikelompokkan menjadi tag-tag sebagai berikut: <document_id= 1 ></document_id>, menunjukkan ID dari dokumen. <doc-no></doc-no>, menunjukkan nama file. <title></title>, menunjukkan judul dari dokumen. <content></content>, menunjukkan isi dari dokumen. Dokumen-dokumen tersebut kemudian dimasukkan ke dalam database MySql sehingga akan terbentuk sebuah tabel yang bernama document. Tabel document tersebut memiliki field sesuai dengan tag-tag yang ada pada dokumen, seperti terlihat pada Gambar 3. Pada tabel document terdapat field tambahan yaitu total_words dan euclid. Angka-angka tersebut akan digunakan selanjutnya pada proses similarity model peluang dan model ruang vektor. Gambar 3 Tabel document pada database

21 Selain dokumen yang telah disiapkan, pada 1000 dokumen pertanian tersebut juga telah tersedia 30 query yang akan digunakan dalam pencarian, berikut dengan daftar dokumen yang relevan dari query-query tersebut. Queryquery tersebut akan digunakan untuk melakukan pada proses similarity pada model peluang maupun model ruang vektor. 11 Praproses Tokenisasi Setelah dokumen dimasukkan ke dalam database, kemudian dilakukan tokenisasi. Proses tokenisasi dilakukan dengan bantuan Sphinx Search karena tokenisasi dengan Sphinx tergolong mudah dan cepat dalam prosesnya. Selain itu, Sphinx juga mendukung pemrosesan dokumen yang berasal dari database. Sebelum dilakukan proses indexing, terlebih dahulu dilakukan konfigurasi pada Sphinx. File konfigurasi untuk Sphinx yang digunakan adalah file sphinxmin.conf.in. Pada file konfigurasi ini terdapat pengaturan koneksi database dan pengaturan lainnya termasuk jumlah minimal huruf pada kata yang akan diindeks. Kata yang diindeks adalah kata yang memiliki jumlah minimal 3 huruf, sehingga untuk kata yang kurang dari 3 huruf tidak akan ikut terindeks. Setelah service dari Sphinx dibuat dan koneksi ke database untuk tabel document telah dibuat pada file konfigurasi Sphinx, proses indexing dapat dilakukan. Pada akhirnya didapatkan indeks kata yang berasal dari 1300 dokumen yang berada pada tabel document di dalam database. Setiap term yang telah diindeks akan dimasukkan ke dalam tabel words pada database. Pada tabel words terdapat seluruh kata yang terindeks, berikut id dan jumlah kemunculan term tersebut pada seluruh dokumen yang ada. Tabel words pada database dapat dilihat pada Gambar 4. Gambar 4 Tabel words pada database
22 12 Pembuangan Stopwords File yang berisi stopwords telah tersedia sebelumnya dan berjumlah 732 kata stopwords. Setiap kata stopwords tersebut dimasukkan ke dalam tabel bernama stopwords. Kemudian pada tabel words, akan dibuat 1 field baru dengan nama stopwords yang akan berisi angka 0 dan 1. Angka 0 menunjukkan bahwa kata tersebut merupakan kata stopwords yang terdapat pada tabel stopwords sedangkan angka 1 menunjukkan bahwa kata tersebut bukanlah suatu stopwords. Untuk kata yang memiliki angka 0 pada field stopwords akan dihapus sehingga kata yang tersisa sudah tidak ada lagi kata stopwords. Akan tetapi, masih terdapat kata-kata yang mengandung angka, seperti tahun, tanggal lahir, dan kata yang mengandung angka lainnya. Kata yang mengandung angka tersebut tidak diperlukan karena pada query yang digunakan, tidak ada query yang mengadung angka. Angka-angka yang ikut terindeks tersebut dihilangkan secara manual (di delete) dari dalam database satu per satu sehingga tidak ditemukan lagi kata yang memiliki unsur angka di dalam database. Pemilihan Fitur Pada penelitian ini, metode pemilihan fitur yang digunakan adalah dengan menggunakan Inverse Document Frequency (IDF). Nilai IDF dari sekumpulan indeks kata akan dicari, sehingga akan terlihat kata mana saja yang memiliki nilai IDF yang besar dan yang kecil. Dari nilai tersebut, akan ditentukan nilai batas (threshold) untuk kata yang memiliki nilai IDF yang kecil. Nilai threshold yang digunakan adalah Untuk kata dengan nilai IDF < 0.15 akan dibuang. Untuk nilai IDF yang melebihi nilai threshold akan dipertahankan untuk selanjutnya dilakukan proses pembobotan dan similarity. Pembobotan Pembobotan yang dilakukan adalah dengan menghitung tf, idf, dan tf.idf. untuk nilai dari tf dan idf dihitung dengan menggunakan bantuan Sphinx Search. Nilai dari tf dan idf tersebut selanjutnya digunakan untuk mencari nilai dari tf.idf. Nilai-nilai tersebut dimasukkan ke dalam database MySql untuk selanjutnya digunakan pada perhitungan berikutnya. Nilai dari tf dimasukkan ke dalam tabel bernama tf dan nilai idf dimasukkan ke dalam tabel dengan nama idf, sedangkan untuk nilai dari tf.idf ikut dimasukkan ke dalam tabel tf. Nilai yang didapatkan pada proses pembobotan ini selanjutnya akan digunakan pada proses similarity, baik pada model peluang maupun model ruang vektor. Nilai pembobotan sudah tersedia untuk semua term yang ada pada seluruh dokumen yang terindeks, oleh sebab itu, proses perhitungan pada bagian similarity dapat langsung dilakukan dengan query pengujian yang telah tersedia. Similarity Proses perhitungan similarity berbeda untuk tiap model. Pada model peluang, similarity dihitung dengan menggunakan fungsi kesamaan Okapi BM25, sedangkan untuk model ruang vektor dihitung dengan menggunakan fungsi kesamaan cosine (cosine similarity).
23 Similarity Model Peluang Implementasi dari fungsi kesamaan Okapi BM25 dilakukan dengan bantuan nilai-nilai yang telah ada pada database sebelumnya. Seperti dapat dilihat pada fungsi (2) tersebut terbagi atas 3 bagian. Bagian pertama sebenarnya merupakan rumus dari idf yang mengalami sedikit modifikasi. Nilai dari bagian pertama tersebut dihitung terlebih dahulu untuk setiap term, dan kemudian dimasukkan ke dalam database dengan field bernama idf_modif. Sementara itu, bagian kedua merupakan perhitungan yang berhubungan dengan dokumen, dan bagian ketiga merupakan perhitungan yang berhubungan dengan query. Nilai dari avl atau panjang rata-rata seluruh dokumen dalam korpus dapat dicari dengan menghitung keseluruhan jumlah kata pada korpus, kemudian membaginya dengan jumlah dari seluruh dokumen. Sedangkan untuk dl d atau jumlah term dalam dokumen dapat dicari terlebih dahulu. Pada tabel document akan ditambahkan field yang berisi jumlah kata dalam dokumen tersebut. Kemudian, fungsi kesamaan Okapi BM25 dapat dihitung dengan persamaan pada Gambar $K = $k1*((1-$b)+$b*$total_document_words->total_words/$avl); $part1 = $idf_modif->idf; $part2 = (($k1+1)*$t->tf)/($k+$t->tf); $part3 = (($k3+1)*1)/($k3+1); $bm25 = $part1*$part2*$part3; Gambar 5 Implementasi fungsi kesamaan Okapi BM25 Pada saat dimasukkan query yang tersedia, akan didapatkan skor kesamaan dari perhitungan tersebut untuk tiap-tiap dokumen yang dianggap relevan dengan query oleh sistem. Hasil pencarian pada setiap query ini akan dilakukan evaluasi pada tahap selanjutnya. Algoritme dari fungsi kesamaan Okapi BM25 secara garis besar ditunjukkan pada Gambar 6. 1 Input query q. 2 Pisahkan query q menjadi satu kata query q1, q2, q3, dst. 3 Proses q1 dengan mencari nilai IDF, TF dokumen, dan TF query nya sesuai dengan fungsi Okapi BM25. 4 Kalikan IDF, DF, dan TF yang didapatkan pada q1 tersebut sehingga didapatkan skor kesamaan untuk satu kata query. 5 Ulangi langkah 3 sampai 4 untuk q2, q3, dst. 6 Jumlahkan setiap hasil yang didapatkan dari q1, q2, q3 dst tergantung banyaknya jumlah kata pada query, sehingga didapatkan skor keseluruhan untuk 1 query pencarian. 7 Didapatkan skor kesamaan untuk suatu query, sehingga dapat ditentukan dokumen hasil pencarian yang dianggap relevan dengan query tersebut. 8 Urutkan dokumen hasil pencarian berdasarkan skor tertinggi ke skor terendah. 9 Dokumen yang telah diurutkan dapat ditampilkan pada sistem. Gambar 6 Algoritme pada fungsi kesamaan Okapi BM25
24 14 Algoritme pada Gambar 6 adalah algoritme untuk satu query. Proses tersebut harus dilakukan untuk ke 30 query yang diujikan, sehingga dapat dilakukan evaluasi untuk seluruh query berdasarkan hasil dari skor kesamaan yang didapatkan tersebut. Similarity Model Ruang Vektor Sesuai dengan fungsi (1), terlebih dahulu dilakukan perkalian antara nilai tf.idf dari query dengan tf.idf dari dokumen yang relevan dengan query masukan. Kemudian hitung panjang Euclid setiap dokumen yang relevan dan panjang Euclid dari query. Panjang Euclid dihitung dengan mengkuadratkan bobot (tf.idf) setiap term dalam setiap dokumen, kemudian dijumlahkan sesuai dengan document_id yang sama, dan terakhir nilai hasil penjumlahan tersebut diakarkan. Algoritme dari fungsi kesamaan cosine ditunjukkan pada Gambar 7. Nilai dari tf.idf kuadrat dapat dimasukkan ke dalam database, begitu juga dengan panjang Euclid untuk setiap dokumen. Dengan telah tersedianya nilai tf.idf kuadrat dan panjang Euclid pada database, diharapkan proses perhitungan pada cosine similarity dapat menjadi lebih cepat. Proses pada Gambar 7 dilakukan untuk semua dokumen yang diujikan, sehingga dari skor kesamaan tersebut, dapat memunculkan dokumen hasil pencarian yang kemudian akan dilakukan evaluasi untuk mengetahui kinerja dari sistem tersebut. 1 Input query q. 2 Pisahkan query q menjadi satu kata query q1, q2, q3, dst. 3 Proses q1 dengan melakukan perkalian skalar antara bobot q1 dengan bobot setiap dokumen yang dianggap relevan oleh sistem. 4 Lakukan langkah 3 untuk semua kata pada query kemudian jumlahkan hasil perkalian tiap kata query dengan dokumen. 5 Hitung panjang Euclid dari dokumen, termasuk panjang Euclid dari query yaitu dengan menguadratkan bobot setiap term dalam dokumen maupun query, dijumlahkan, kemudian terakhir diakarkan. 6 Lakukan perkalian dari panjang Euclid yang didapatkan pada query dan panjang Euclid dari dokumen. 7 Lakukan pembagian antara hasil pada langkah 4 dengan hasil yang didapatkan pada langkah 6. 8 Urutkan skor kesamaan yang didapatkan mulai dari skor yang tertinggi hingga terendah sehingga didapatkan urutan dokumen hasil pencarian. 9 Dokumen hasil pencarian dapat ditampilkan di sistem dengan memanggil id maupun judul dari dokumen tersebut. Gambar 7 Algoritme pada fungsi kesamaan cosine Evaluasi Setelah dilakukan proses similarity dan didapatkan skor kesamaan antara query dengan dokumen yang ada, selanjutnya dilakukan proses evaluasi. Proses evaluasi dilakukan dengan mencari nilai precision dan nilai recall. Pada model peluang, proses tuning dilakukan terhadap nilai dari k 1 dan b.
25 Setiap perubahan nilai dari k 1 dan b dilakukan proses evaluasi terhadap 30 query yang diujikan. Untuk setiap query, dihitung nilai precision pada setiap nilai recall standar (eleven standard recall), yaitu 0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, dan 1.0. Setelah didapatkan nilai precision pada sebelas nilai recall standar dengan interpolasi masksimum untuk setiap query, dilanjutkan dengan mencari nilai average precision (AVP). Nilai inilah yang digunakan untuk mengetahui kinerja dari setiap perubahan nilai k 1 dan b yang diujikan. Nilai AVP dari setiap pengujian nilai k 1 dan b akan dibandingkan untuk mencari nilai k 1 dan b yang manakah yang menghasilkan nilai yang paling tinggi. Untuk hasil evaluasi pada fungsi BM25 tanpa tuning yaitu dengan nilai k 1 = 1.2 dan b = 0.75 didapatkan nilai average precision (AVP) sebesar Nilai AVP untuk BM25 sebelum dan sesudah dilakukan tuning dicantumkan pada Tabel 2. BM25 Tuning tersebut adalah nilai tuning parameter yang menghasilkan nilai AVP paling besar dari yang lainnya. Nilai AVP dari seluruh tuning parameter yang diujikan dicantumkan pada Lampiran 4. Grafik perbandingan evaluasi BM25 sebelum dan sesudah dilakukan perubahan tuning parameter ditunjukkan pada Gambar 8. Tabel 2 Nilai AVP BM25 sebelum dan sesudah tuning Model AVP BM BM25 tuning Gambar 8 Perbandingan grafik recall-precision BM25 sebelum dan sesudah dilakukan tuning Tuning yang dilakukan pada saat k 1 = 1.0 dan b = 0.45 mempunyai nilai AVP yang paling besar dibandingkan dengan yang lainnya, yaitu sebesar Tuning yang dilakukan meningkatkan nilai sebesar dari nilai AVP semula. Nilai ini menunjukkan angka yang tidak terlalu jauh dari nilai AVP pada BM25
26 16 sebelum dilakukan tuning. Hal ini disebabkan oleh perubahan dari nilai k 1 dan b yang sangat berpengaruh terhadap panjang dokumen yang digunakan pada korpus. Seperti dapat dilihat pada rumus (2) dan rumus (3), nilai dari k 1 berhubungan langsung dengan fungsi dari frekuensi kemunculan suatu kata dalam dokumen sedangkan nilai dari b berhubungan langsung dengan rumus (2), yaitu fungsi normalisasi dari panjang dokumen. Nilai tuning terbesar adalah pada saat k 1 = 1.0 dan b = 0.45 yang mengartikan bahwa fungsi tersebut hanya menggunakan 0.45 atau sekitar setengah dari panjang dokumen yang ada pada korpus sebagai pengaruh terhadap hasil perhitungan. Apabila b mempunyai nilai 1, maka menandakan fungsi akan menggunakan keseluruhan pengaruh panjang dokumen yang ada pada korpus sebagai hasil perhitungan. Nilai k 1 = 1.0 menandakan fungsi tidak menambahkan pengaruh porsi term dalam suatu dokumen. Untuk nilai dari k 3 tidak diperhitungkan karena penelitian ini menggunakan query pendek yang tidak memungkinkan adanya kata yang berulang. Seperti diketahui, dokumen yang digunakan pada penelitian ini berjumlah 1300 dokumen yang seluruhnya merupakan dokumen berita yang ada di koran maupun yang ada di internet. Ini berarti dokumen dalam korpus memiliki jumlah kata untuk tiap dokumen yang tidak terlalu berbeda jauh, karena dokumen berita biasanya tidak akan terlalu panjang dan tidak juga terlalu pendek. Oleh karena dokumen yang digunakan relatif sama dalam hal panjang dokumennya, maka tuning yang dilakukan tidak akan memberikan peningkatan nilai AVP yang terlalu jauh dari nilai AVP awal. Perlu dilakukan tuning dengan menggunakan korpus yang lebih bervariasi untuk membuktikan pengaruh panjang dokumen terhadap hasil perubahan tuning parameter. Selain dari hal tersebut, tidak dapat dipungkiri bahwa nilai tuning parameter yang disarankan oleh Robertson dan Walker (1999) merupakan nilai tuning parameter yang sudah terbukti efektif pada beberapa kondisi pencarian, seperti panjang dokumen dan panjang query yang berbeda-beda. Oleh karena itu, tuning yang dilakukan pun memang semestinya tidak diubah terlalu jauh dari nilai yang disarankan tersebut. Meskipun demikian, proses modifikasi dari tuning parameter yang dilakukan sudah berhasil dilakukan karena terbukti mampu meningkatkan nilai AVP dari model peluang yang menggunakan fungsi kesamaan Okapi BM25. Nilai precision dari tiap query pada eleven standard recall untuk model peluang sebelum dan sesudah dilakukan tuning dapat dilihat pada Lampiran 6 dan Lampiran 7. Perbandingan Kinerja Model Peluang dengan Model Ruang Vektor Setelah didapatkan kinerja dari model peluang, langkah berikutnya adalah membandingkan kinerjanya dengan model lain, yaitu model ruang vektor. Perbandingan kinerja antara model peluang dan model ruang vektor ditunjukkan oleh nilai AVP pada Tabel 3 dan juga pada grafik recall-precision yang terdapat pada Gambar 9.
27 17 Tabel 3 Nilai AVP pada BM25 dan VSM Model AVP BM VSM Nilai AVP di atas menunjukkan bahwa model peluang memiliki kinerja yang lebih baik dibandingkan dengan model ruang vektor. Hal ini menunjukkan bahwa secara rata-rata pada tiap recall point, 59% hasil temu-kembali pada model peluang relevan dengan query. Hasil ini lebih unggul dibandingkan dengan model ruang vektor yang memiliki nilai 53%. Perhitungan setiap query pada eleven standard recall pada model ruang vektor dapat dilihat pada Lampiran 8. Selain itu, pada query yang kompleks (lebih dari 2 kata) maupun query yang sederhana (1-2 kata), model peluang juga menghasilkan lebih banyak dokumen yang relevan sehingga menghasilkan nilai AVP yang lebih tinggi dibandingkan dengan model ruang vektor. Perbandingan nilai AVP dari model peluang dengan model ruang vektor pada eleven standard recall dapat dilihat pada Lampiran 5. Karena secara garis besar hasil evaluasi pada model peluang lebih baik dibandingkan dengan model ruang vektor, maka dapat dikatakan pula bahwa model peluang cukup baik digunakan untuk melakukan pencarian dokumen yang menggunakan Bahasa Indonesia. Gambar 9 Grafik recall-precision dari BM25 dan VSM
28 18 SIMPULAN DAN SARAN Simpulan Hasil penelitian ini menunjukkan bahwa: 1 Telah dilakukannya proses modifikasi nilai dari tuning parameter yang ada pada fungsi kesamaan Okapi BM25 yang terdapat pada model peluang. Nilai AVP dari model peluang sebelum dilakukan tuning yaitu , sedangkan setelah dilakukan tuning nilai AVP yang terbesar yaitu Telah dilakukan perbandingan kinerja antara model peluang dengan model ruang vektor. Perbandingan kedua model ini ditunjukkan oleh nilai AVP dari model peluang standar adalah sebesar , sedangkan untuk model ruang vektor, nilai AVP yang didapat adalah sebesar Dari perbandingan nilai AVP tersebut, dapat disimpulkan bahwa model peluang memiliki kinerja yang lebih baik dibandingkan dengan model ruang vektor untuk pencarian dokumen yang menggunakan Bahasa Indonesia. Saran Terdapat beberapa hal yang dapat ditambahkan ataupun diperbaiki untuk penelitian-penelitian selanjutnya, diantaranya: 1 Mengembangkan sistem dengan menggunakan dokumen yang lebih beragam, contohnya seperti menggunakan korpus dengan dokumen yang memiliki panjang dokumen yang berbeda-beda. 2 Melakukan pengujian dengan query yang berbeda, lebih beragam, dan terdiri dari banyak kata. 3 Melakukan modifikasi dari tuning parameter dengan nilai k 1, k 3, dan b yang lebih beragam sehingga memungkinkan didapatkannya nilai AVP yang lebih baik. DAFTAR PUSTAKA Adisantoso J, Ridha A Korpus dokumen teks bahasa Indonesia untuk pengujian efektivitas temu-kembali informasi. Di dalam: Laporan Akhir Hibah Penelitian SP4. Bogor (ID): Institut Pertanian Bogor. Baeza-Yates R, Ribeiro-Neto B Modern Information Retrieval. England: Addison Wesley. Buckley C, Salton G, Allan J The effect of adding relevance information in a relevance feedback environment. Di dalam: Proceedings of the 17 th Annual International ACM-SIGIR Conference on Research and Development in Information Retrieval; 1994 Jul 3-6; Dublin, Irlandia. New York (US): Springer-Verlag. hlm Chen B Modeling in Information Retrieval. Department of Computer Science and Information Engineering, National Taiwan Normal University. Harman D Relevance feedback revisited. Di dalam: Proceedings of the 15 th Annual International ACM-SIGIR Conference on Research and Development
29 in Information Retrieval; 1992 Jun 21-24; Copenhagen, Denmark. New York (US): ACM. hlm Luhn HP The automatic of literature abstracts. IBM Journal of Research and Development. 2(2): Manning CD, Raghavan P, Schütze H An Introduction to Information Retrieval. Cambridge (UK): Cambridge Univ Pr. Robertson SE, Walker S Okapi/Keenbow at TREC-8. Di dalam: Proceedings of TREC-8; 1999 Nov 16-19; Maryland, United States of America. Maryland (US): NIST. hlm Sudirman S, Kodar A Penggunaan model probabilistik untuk sistem temu kembali informasi. Di dalam: Seminar Nasional Pengaplikasian Telematika (SINAPTIKA 2012); 2012 Jul 7; Jakarta, Indonesia. Jakarta (ID): SINAPTIKA. hlm
30 20

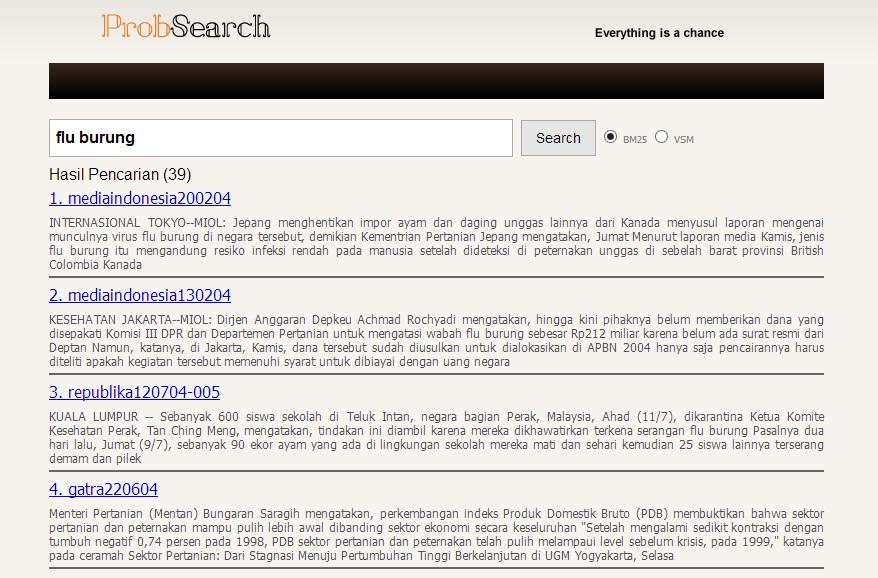
31 21 LAMPIRAN Lampiran 1 Antarmuka implementasi
32 22 Lampiran 2 Gugus query dan jawaban Kueri Bencana kekeringan Dukungan pemerintah pada pertanian Flu burung Gabah kering giling Gugus Jawaban gatra070203, gatra161002, gatra210704, gatra301002, indosiar010903, indosiar170603, indosiar220503, indosiar , indosiar310504, kompas210504, kompas250803, mediaindonesia , mediaindonesia110703, mediaindonesia160603, mediaindonesia240503, mediaindonesia260803, mediaindonesia270803, mediaindonesia310503, pikiranrakyat020704, republika , republika , republika , republika , republika , republika , republika , republika200603, republika , republika250604, republika270503, republika , situshijau , suarakarya , suarakarya , suaramerdeka130602, suaramerdeka190903, suarapembaruan150903, suarapembaruan180303, suarapembaruan indosiar070504, jurnal , kompas030401, kompas050303, kompas060503, kompas071100, kompas150201, kompas200802, kompas300402, mediaindonesia130204, mediaindonesia220303, pembaruan110903, poskota040804, republika100903, republika180303, republika210902, republika230903, republika , republika , republika , situshijau , situshijau , situshijau , situshijau , situshijau , suarakarya , suaramerdeka130902, wartapenelitian , wartapenelitian gatra220604, gatra , gatra , gatra300104, indosiar020304, indosiar240204, mediaindonesia090204, mediaindonesia140704, mediaindonesia200204, republika090604, republika , republika , republika , republika , republika , situshijau , suarakarya , suarakarya , suarakarya , suaramerdeka160204, suaramerdeka indosiar180603, indosiar240703, indosiar300304, kompas , kompas , kompas160704, kompas170903, mediaindonesia250304, pikiranrakyat300604, republika040303, republika , republika , republika100804, republika , republika , republika , republika , republika , republika , republika , republika , situshijau , suarakarya , suaramerdeka
33 Lampiran 2 Lanjutan Kueri Gagal panen Impor beras Indonesia Industri gula Gugus Jawaban gatra070203, gatra190802, gatra , gatra301002, indosiar010504, indosiar031203, indosiar040903, indosiar , indosiar070504, indosiar130504, indosiar140204, indosiar160304, indosiar170603, indosiar180304, indosiar240703, indosiar , indosiar , kompas030704, kompas031003, kompas170504, mediaindonesia030603, mediaindonesia , mediaindonesia110703, mediaindonesia140203, mediaindonesia160603, mediaindonesia240503, mediaindonesia310503, republika , republika , republika080703, republika , republika , republika , republika , republika200603, republika , republika , situshijau , situshijau , situshijau , situshijau , suarakarya , suarakarya , suaramerdeka120104, suaramerdeka130602, suarapembaruan120104, suarapembaruan , suarapembaruan gatra180103, gatra220802, indosiar180603, indosiar180703, indosiar200304, indosiar , kompas , kompas , kompas050602, kompas101002, kompas101004, kompas160704, kompas180504, kompas270401, kompas , kompas310702, mediaindonesia050104, mediaindonesia060803, mediaindonesia100203, mediaindonesia131003, mediaindonesia160603, mediaindonesia250304, republika , republika , republika090902, republika100703, republika , republika , republika , republika , republika , republika , republika , republika , situshijau , suarakarya , suarakarya , suaramerdeka120104, suaramerdeka130104, suaramerdeka , suaramerdeka270601, suarapembaruan100903, suarapembaruan gatra200103, kompas031003, kompas250901, mediaindonesia , pikiranrakyat , republika , republika020804, republika090902, republika100902, republika , republika , republika301002, situshijau , suarakarya , suarakarya , suarakarya , suaramerdeka130902, suarapembaruan100903, suarapembaruan
BAB I PENDAHULUAN Latar Belakang
 BAB I PENDAHULUAN 1.1. Latar Belakang Semakin canggihnya teknologi di bidang komputasi dan telekomunikasi pada masa kini, membuat informasi dapat dengan mudah didapatkan oleh banyak orang. Kemudahan ini
BAB I PENDAHULUAN 1.1. Latar Belakang Semakin canggihnya teknologi di bidang komputasi dan telekomunikasi pada masa kini, membuat informasi dapat dengan mudah didapatkan oleh banyak orang. Kemudahan ini
PENCARIAN TEKS BAHASA INDONESIA PADA MESIN PENCARI BERBASIS SOUNDEX EDO APRIYADI
 PENCARIAN TEKS BAHASA INDONESIA PADA MESIN PENCARI BERBASIS SOUNDEX EDO APRIYADI DEPARTEMEN ILMU KOMPUTER FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR BOGOR 2013 PERNYATAAN MENGENAI
PENCARIAN TEKS BAHASA INDONESIA PADA MESIN PENCARI BERBASIS SOUNDEX EDO APRIYADI DEPARTEMEN ILMU KOMPUTER FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR BOGOR 2013 PERNYATAAN MENGENAI
HASIL DAN PEMBAHASAN. Tabel 1 Perhitungan recall-precision. ) adalah peluang kata i dalam dokumen setelah q j. p( i q j
 adalah peluang kata i dalam dokumen setelah q j. p( i q j") 3 p( i j ) adalah peluang kata i dalam dokumen setelah j diketahui (Adisantoso 1996). Hitung Relevansi Kata Pada tahap ini, dilakukan proses perhitungan setiap kata yang dinilai relevan dan tidak relevan
3 p( i j ) adalah peluang kata i dalam dokumen setelah j diketahui (Adisantoso 1996). Hitung Relevansi Kata Pada tahap ini, dilakukan proses perhitungan setiap kata yang dinilai relevan dan tidak relevan
PENDAHULUAN. Latar belakang
 Latar belakang PENDAHULUAN Indonesia merupakan negara megabiodiversity yang memiliki kekayaan tumbuhan obat. Indonesia memiliki lebih dari 38.000 spesies tanaman (Bappenas 2003). Sampai tahun 2001 Laboratorium
Latar belakang PENDAHULUAN Indonesia merupakan negara megabiodiversity yang memiliki kekayaan tumbuhan obat. Indonesia memiliki lebih dari 38.000 spesies tanaman (Bappenas 2003). Sampai tahun 2001 Laboratorium
PSEUDO-RELEVANCE FEEDBACK PADA TEMU-KEMBALI MENGGUNAKAN SEGMENTASI DOKUMEN ELENUR DWI ANBIANA
 PSEUDO-RELEVANCE FEEDBACK PADA TEMU-KEMBALI MENGGUNAKAN SEGMENTASI DOKUMEN ELENUR DWI ANBIANA DEPARTEMEN ILMU KOMPUTER FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR BOGOR 2009
PSEUDO-RELEVANCE FEEDBACK PADA TEMU-KEMBALI MENGGUNAKAN SEGMENTASI DOKUMEN ELENUR DWI ANBIANA DEPARTEMEN ILMU KOMPUTER FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR BOGOR 2009
beberapa tag-tag lain yang lebih spesifik di dalamnya.
 metode mana yang lebih baik digunakan untuk memilih istilah ekspansi yang akan ditambahkan pada kueri awal. Lingkungan Implementasi Perangkat lunak yang digunakan untuk penelitian yaitu:. Windows Vista
metode mana yang lebih baik digunakan untuk memilih istilah ekspansi yang akan ditambahkan pada kueri awal. Lingkungan Implementasi Perangkat lunak yang digunakan untuk penelitian yaitu:. Windows Vista
HASIL DAN PEMBAHASAN. 4. Menghitung fungsi objektif pada iterasi ke-t, 5. Meng-update derajat keanggotaan. 6. Mengecek kondisi berhenti:
 2. v kj merupakan centroid term ke-j terhadap cluster ke-k 3. μ ik merupakan derajat keanggotaan dokumen ke-i terhadap cluster ke-k 4. i adalah indeks dokumen 5. j adalah indeks term 6. k adalah indeks
2. v kj merupakan centroid term ke-j terhadap cluster ke-k 3. μ ik merupakan derajat keanggotaan dokumen ke-i terhadap cluster ke-k 4. i adalah indeks dokumen 5. j adalah indeks term 6. k adalah indeks
Sistem Temu Kembali Informasi pada Dokumen Teks Menggunakan Metode Term Frequency Inverse Document Frequency (TF-IDF)
") Sistem Temu Kembali Informasi pada Dokumen Teks Menggunakan Metode Term Frequency Inverse Document Frequency (TF-IDF) 1 Dhony Syafe i Harjanto, 2 Sukmawati Nur Endah, dan 2 Nurdin Bahtiar 1 Jurusan Matematika,
Sistem Temu Kembali Informasi pada Dokumen Teks Menggunakan Metode Term Frequency Inverse Document Frequency (TF-IDF) 1 Dhony Syafe i Harjanto, 2 Sukmawati Nur Endah, dan 2 Nurdin Bahtiar 1 Jurusan Matematika,
HASIL DAN PEMBAHASAN. diformulasikan digunakan dalam proses temu kembali selanjutnya.
 beberapa kata. Menurut Baeza-Yates dan Ribeiro-Neto (1999), tidak semua kata dapat digunakan untuk merepresentasikan sebuah dokumen secara signifikan Pemrosesan teks yang dilakukan dalam penelitian ini
beberapa kata. Menurut Baeza-Yates dan Ribeiro-Neto (1999), tidak semua kata dapat digunakan untuk merepresentasikan sebuah dokumen secara signifikan Pemrosesan teks yang dilakukan dalam penelitian ini
Penerapan Model OKAPI BM25 Pada Sistem Temu Kembali Informasi
 Penerapan Model OKAPI BM25 Pada Sistem Temu Kembali Informasi Rizqa Raaiqa Bintana 1, Surya Agustian 2 1,2 Teknik Informatika, FST UIN Suska Riau Jl. HR Soeberantas km 11,5 Panam, Pekanbaru, Riau e-mail:
Penerapan Model OKAPI BM25 Pada Sistem Temu Kembali Informasi Rizqa Raaiqa Bintana 1, Surya Agustian 2 1,2 Teknik Informatika, FST UIN Suska Riau Jl. HR Soeberantas km 11,5 Panam, Pekanbaru, Riau e-mail:
Penerapan Algoritma Genetika pada Peringkasan Teks Dokumen Bahasa Indonesia
 Penerapan Algoritma Genetika pada Peringkasan Teks Dokumen Bahasa Indonesia Aristoteles Jurusan Ilmu Komputer FMIPA Universitas Lampung aristoteles@unila.ac.id Abstrak.Tujuan penelitian ini adalah meringkas
Penerapan Algoritma Genetika pada Peringkasan Teks Dokumen Bahasa Indonesia Aristoteles Jurusan Ilmu Komputer FMIPA Universitas Lampung aristoteles@unila.ac.id Abstrak.Tujuan penelitian ini adalah meringkas
PERBANDINGAN EFISIENSI MODEL RUANG VEKTOR PADA SISTEM TEMU KEMBALI INFORMASI ARI ALKAUTSAR
 PERBANDINGAN EFISIENSI MODEL RUANG VEKTOR PADA SISTEM TEMU KEMBALI INFORMASI ARI ALKAUTSAR DEPARTEMEN ILMU KOMPUTER FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR BOGOR 2012 1 PERBANDINGAN
PERBANDINGAN EFISIENSI MODEL RUANG VEKTOR PADA SISTEM TEMU KEMBALI INFORMASI ARI ALKAUTSAR DEPARTEMEN ILMU KOMPUTER FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR BOGOR 2012 1 PERBANDINGAN
KONTRAK PERKULIAHAN TEMU KEMBALI INFORMASI KOM431
 KONTRAK PERKULIAHAN TEMU KEMBALI INFORMASI KOM431 KOORDINATOR MATA AJARAN TEMU KEMBALI INFORMASI DEPARTEMEN ILMU KOMPUTER INSTITUT PERTANIAN BOGOR TAHUN 2011/2012 KONTRAK PERKULIAHAN Nama Matakuliah :
KONTRAK PERKULIAHAN TEMU KEMBALI INFORMASI KOM431 KOORDINATOR MATA AJARAN TEMU KEMBALI INFORMASI DEPARTEMEN ILMU KOMPUTER INSTITUT PERTANIAN BOGOR TAHUN 2011/2012 KONTRAK PERKULIAHAN Nama Matakuliah :
Sistem Rekomendasi Hasil Pencarian Artikel Menggunakan Metode Jaccard s Coefficient
 Jurnal Transistor Elektro dan Informatika (TRANSISTOR EI) Vol. 2, No. 1 1 Sistem Rekomendasi Hasil Pencarian Artikel Menggunakan Metode Jaccard s Coefficient Muhammad Fadelillah, Imam Much Ibnu Subroto,
Jurnal Transistor Elektro dan Informatika (TRANSISTOR EI) Vol. 2, No. 1 1 Sistem Rekomendasi Hasil Pencarian Artikel Menggunakan Metode Jaccard s Coefficient Muhammad Fadelillah, Imam Much Ibnu Subroto,
Analisis dan Pengujian Kinerja Korelasi Dokumen Pada Sistem Temu Kembali Informasi
 Jurnal Integrasi, vol. 6, no. 1, 2014, 21-25 ISSN: 2085-3858 (print version) Article History Received 10 February 2014 Accepted 11 March 2014 Analisis dan Pengujian Kinerja Korelasi Dokumen Pada Sistem
Jurnal Integrasi, vol. 6, no. 1, 2014, 21-25 ISSN: 2085-3858 (print version) Article History Received 10 February 2014 Accepted 11 March 2014 Analisis dan Pengujian Kinerja Korelasi Dokumen Pada Sistem
Pengujian Kerelevanan Sistem Temu Kembali Informasi
 Pengujian Kerelevanan Sistem Temu Kembali Informasi Ari Wibowo / 23509063 Jurusan Teknik Informatika, Politeknik Negeri Batam Jl. Parkway No 1 Batam Center, Batam wibowo@polibatam.ac.id Abstrak Sistem
Pengujian Kerelevanan Sistem Temu Kembali Informasi Ari Wibowo / 23509063 Jurusan Teknik Informatika, Politeknik Negeri Batam Jl. Parkway No 1 Batam Center, Batam wibowo@polibatam.ac.id Abstrak Sistem
BAB 1 PENDAHULUAN UKDW
 BAB 1 PENDAHULUAN 1.1 Latar Belakang Masalah Perkembangan ilmu pengetahuan yang pesat dewasa ini telah mendorong permintaan akan kebutuhan informasi ilmu pengetahuan itu sendiri. Cara pemenuhan kebutuhan
BAB 1 PENDAHULUAN 1.1 Latar Belakang Masalah Perkembangan ilmu pengetahuan yang pesat dewasa ini telah mendorong permintaan akan kebutuhan informasi ilmu pengetahuan itu sendiri. Cara pemenuhan kebutuhan
BAB II TINJAUAN PUSTAKA
 7 BAB II TINJAUAN PUSTAKA A. Tinjauan Pustaka Penelitian-penelitian yang pernah dilakukan di bidang information retrieval telah memunculkan berbagai metode pembobotan dan clustering untuk mengelompokkan
7 BAB II TINJAUAN PUSTAKA A. Tinjauan Pustaka Penelitian-penelitian yang pernah dilakukan di bidang information retrieval telah memunculkan berbagai metode pembobotan dan clustering untuk mengelompokkan
Analisis dan Pengujian Kinerja Korelasi Dokumen Pada Sistem Temu Kembali Informasi
 Analisis dan Pengujian Kinerja Korelasi Dokumen Pada Sistem emu Kembali Informasi Ari Wibowo Program Studi eknik Multimedia dan Jaringan, Politeknik Negeri Batam E-mail : wibowo@polibatam.ac.id Abstrak
Analisis dan Pengujian Kinerja Korelasi Dokumen Pada Sistem emu Kembali Informasi Ari Wibowo Program Studi eknik Multimedia dan Jaringan, Politeknik Negeri Batam E-mail : wibowo@polibatam.ac.id Abstrak
TEMU KEMBALI INFORMASI
 JULIO ADISANTOSO Departemen Ilmu Komputer IPB Pertemuan 3 MODEL IR Konsep IR Model IR Konsep Boolean Model Pemodelan IR Model IR Konsep Boolean Model Model IR didefinisikan sebagai empat komponen, yaitu:
JULIO ADISANTOSO Departemen Ilmu Komputer IPB Pertemuan 3 MODEL IR Konsep IR Model IR Konsep Boolean Model Pemodelan IR Model IR Konsep Boolean Model Model IR didefinisikan sebagai empat komponen, yaitu:
PENGGUNAAN OPERATOR BELIEF REVISION PADA TEMU KEMBALI DOKUMEN BAHASA INDONESIA MODEL BOOLEAN MERISKA DEFRIANI
 PENGGUNAAN OPERATOR BELIEF REVISION PADA TEMU KEMBALI DOKUMEN BAHASA INDONESIA MODEL BOOLEAN MERISKA DEFRIANI DEPARTEMEN ILMU KOMPUTER FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
PENGGUNAAN OPERATOR BELIEF REVISION PADA TEMU KEMBALI DOKUMEN BAHASA INDONESIA MODEL BOOLEAN MERISKA DEFRIANI DEPARTEMEN ILMU KOMPUTER FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
METODE PEMILIHAN FITUR DOKUMEN BAHASA INDONESIA YANG TERKELOMPOK PADA MESIN PENCARI FITRIA RAHMADINA
 METODE PEMILIHAN FITUR DOKUMEN BAHASA INDONESIA YANG TERKELOMPOK PADA MESIN PENCARI FITRIA RAHMADINA DEPARTEMEN ILMU KOMPUTER FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR BOGOR
METODE PEMILIHAN FITUR DOKUMEN BAHASA INDONESIA YANG TERKELOMPOK PADA MESIN PENCARI FITRIA RAHMADINA DEPARTEMEN ILMU KOMPUTER FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR BOGOR
Lampiran 1 Antarmuka implementasi
 LAMPIRAN 16 Lampiran 1 Antarmuka implementasi 17 17 Lampiran 2 Contoh dokumen XML dalam koleksi pengujian indosiar050704-001 SumKa Presiden Megawati Lakukan
LAMPIRAN 16 Lampiran 1 Antarmuka implementasi 17 17 Lampiran 2 Contoh dokumen XML dalam koleksi pengujian indosiar050704-001 SumKa Presiden Megawati Lakukan
STUDI KOMPARATIF PEMBOBOTAN KATA UNTUK TEMU KEMBALI INFORMASI DOKUMEN BAHASA INDONESIA HAFIZHIA DHIKRUL ANUGRAH
 STUDI KOMPARATIF PEMBOBOTAN KATA UNTUK TEMU KEMBALI INFORMASI DOKUMEN BAHASA INDONESIA HAFIZHIA DHIKRUL ANUGRAH DEPARTEMEN ILMU KOMPUTER FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN
STUDI KOMPARATIF PEMBOBOTAN KATA UNTUK TEMU KEMBALI INFORMASI DOKUMEN BAHASA INDONESIA HAFIZHIA DHIKRUL ANUGRAH DEPARTEMEN ILMU KOMPUTER FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN
BAB II DASAR TEORI Crawler Definisi Focused Crawler dengan Algoritma Genetik [2]
![BAB II DASAR TEORI Crawler Definisi Focused Crawler dengan Algoritma Genetik [2]](/thumbs/63/49389856.jpg "BAB II DASAR TEORI Crawler Definisi Focused Crawler dengan Algoritma Genetik [2]") BAB II DASAR TEORI Pada bab ini dibahas teori mengenai focused crawler dengan algoritma genetik, text mining, vector space model, dan generalized vector space model. 2.1. Focused Crawler 2.1.1. Definisi
BAB II DASAR TEORI Pada bab ini dibahas teori mengenai focused crawler dengan algoritma genetik, text mining, vector space model, dan generalized vector space model. 2.1. Focused Crawler 2.1.1. Definisi
RANCANG BANGUN SISTEM TEMU KEMBALI INFORMASI ABSTRAK TUGAS AKHIR MAHASISWA PRODI TEKNIK INFORMATIKA UNSOED Oleh : Lasmedi Afuan
 RANCANG BANGUN SISTEM TEMU KEMBALI INFORMASI ABSTRAK TUGAS AKHIR MAHASISWA PRODI TEKNIK INFORMATIKA UNSOED Oleh : Lasmedi Afuan Prodi Teknik Informatika, Fakultas Sains dan Teknik, Universitas Jenderal
RANCANG BANGUN SISTEM TEMU KEMBALI INFORMASI ABSTRAK TUGAS AKHIR MAHASISWA PRODI TEKNIK INFORMATIKA UNSOED Oleh : Lasmedi Afuan Prodi Teknik Informatika, Fakultas Sains dan Teknik, Universitas Jenderal
BAB I. Pendahuluan. 1. Latar Belakang Masalah
 BAB I Pendahuluan 1. Latar Belakang Masalah Semakin canggihnya teknologi di bidang komputasi dan telekomunikasi pada masa kini, membuat informasi dapat dengan mudah didapatkan oleh banyak orang. Kemudahan
BAB I Pendahuluan 1. Latar Belakang Masalah Semakin canggihnya teknologi di bidang komputasi dan telekomunikasi pada masa kini, membuat informasi dapat dengan mudah didapatkan oleh banyak orang. Kemudahan
INFORMATION RETRIEVAL SYSTEM PADA PENCARIAN FILE DOKUMEN BERBASIS TEKS DENGAN METODE VECTOR SPACE MODEL DAN ALGORITMA ECS STEMMER
 INFORMATION RETRIEVAL SSTEM PADA PENCARIAN FILE DOKUMEN BERBASIS TEKS DENGAN METODE VECTOR SPACE MODEL DAN ALGORITMA ECS STEMMER Muhammad asirzain 1), Suswati 2) 1,2 Teknik Informatika, Fakultas Teknik,
INFORMATION RETRIEVAL SSTEM PADA PENCARIAN FILE DOKUMEN BERBASIS TEKS DENGAN METODE VECTOR SPACE MODEL DAN ALGORITMA ECS STEMMER Muhammad asirzain 1), Suswati 2) 1,2 Teknik Informatika, Fakultas Teknik,
HASIL DAN PEMBAHASAN. sim(, )=
=") 4 untuk dianggap relevan dengan istilah-istilah kueri tertentu dibandingkan dokumendokumen yang lebih pendek. Sehinggavektor dokumen perlu dinormalisasi. Ukuran kesamaan antara kueri Q dan dokumen D i
4 untuk dianggap relevan dengan istilah-istilah kueri tertentu dibandingkan dokumendokumen yang lebih pendek. Sehinggavektor dokumen perlu dinormalisasi. Ukuran kesamaan antara kueri Q dan dokumen D i
EVALUASI PENGGUNAAN SIMILARITY THESAURUS TERHADAP EKSPANSI KUERI DALAM SISTEM TEMU KEMBALI INFORMASI BERBAHASA INDONESIA
 EVALUASI PENGGUNAAN SIMILARITY THESAURUS TERHADAP EKSPANSI KUERI DALAM SISTEM TEMU KEMBALI INFORMASI BERBAHASA INDONESIA Fridolin Febrianto Paiki Universitas Papua, Jl. Gunung Salju, Amban, Manokwari ff.paiki@unipa.ac.id
EVALUASI PENGGUNAAN SIMILARITY THESAURUS TERHADAP EKSPANSI KUERI DALAM SISTEM TEMU KEMBALI INFORMASI BERBAHASA INDONESIA Fridolin Febrianto Paiki Universitas Papua, Jl. Gunung Salju, Amban, Manokwari ff.paiki@unipa.ac.id
1. Pendahuluan 1.1 Latar belakang 1.2 Perumusan masalah
 1. Pendahuluan 1.1 Latar belakang Informasi telah menjadi kebutuhan primer pada kehidupan saat ini. Informasi seakan-akan menjadi mata uang baru yang membuat akurasi menjadi sangat penting ketika mencari
1. Pendahuluan 1.1 Latar belakang Informasi telah menjadi kebutuhan primer pada kehidupan saat ini. Informasi seakan-akan menjadi mata uang baru yang membuat akurasi menjadi sangat penting ketika mencari
BAB III METODOLOGI PENELITIAN
 BAB III METODOLOGI PENELITIAN Metodologi penelitian merupakan sistematika tahap-tahap yang dilaksanakan dalam pembuatan tugas akhir. Adapun tahapan yang dilalui dalam pelaksanaan penelitian ini adalah
BAB III METODOLOGI PENELITIAN Metodologi penelitian merupakan sistematika tahap-tahap yang dilaksanakan dalam pembuatan tugas akhir. Adapun tahapan yang dilalui dalam pelaksanaan penelitian ini adalah
BAB II TINJAUAN PUSTAKA
 BAB II TINJAUAN PUSTAKA 2.1 Sistem Rekomendasi Sistem rekomendasi adalah sebuah sistem yang dibangun untuk mengusulkan informasi dan menyediakan fasilitas yang diinginkan pengguna dalam membuat suatu keputusan
BAB II TINJAUAN PUSTAKA 2.1 Sistem Rekomendasi Sistem rekomendasi adalah sebuah sistem yang dibangun untuk mengusulkan informasi dan menyediakan fasilitas yang diinginkan pengguna dalam membuat suatu keputusan
APLIKASI MESIN PENCARI DOKUMEN CROSS LANGUAGE BAHASA INGGRIS BAHASA INDONESIA MENGGUNAKAN VECTOR SPACE MODEL
 APLIKASI MESIN PENCARI DOKUMEN CROSS LANGUAGE BAHASA INGGRIS BAHASA INDONESIA MENGGUNAKAN VECTOR SPACE MODEL SKRIPSI Disusun Sebagai Salah Satu Syarat untuk Memperoleh Gelar Sarjana Komputer pada Jurusan
APLIKASI MESIN PENCARI DOKUMEN CROSS LANGUAGE BAHASA INGGRIS BAHASA INDONESIA MENGGUNAKAN VECTOR SPACE MODEL SKRIPSI Disusun Sebagai Salah Satu Syarat untuk Memperoleh Gelar Sarjana Komputer pada Jurusan
BAB IV METODOLOGI PENELITIAN. Penelitian ini dilakukan dengan melalui empat tahap utama, dimana
 BAB IV METODOLOGI PENELITIAN Penelitian ini dilakukan dengan melalui empat tahap utama, dimana tahap pertama adalah proses pengumpulan dokumen teks yang akan digunakan data training dan data testing. Kemudian
BAB IV METODOLOGI PENELITIAN Penelitian ini dilakukan dengan melalui empat tahap utama, dimana tahap pertama adalah proses pengumpulan dokumen teks yang akan digunakan data training dan data testing. Kemudian
JULIO ADISANTOSO - ILKOM IPB 1
 KOM341 Temu Kembali Informasi KULIAH #3 Inverted Index Inverted index construction Kumpulan dokumen Token Modifikasi token Tokenizer Linguistic modules perkebunan, pertanian, dan kehutanan perkebunan pertanian
KOM341 Temu Kembali Informasi KULIAH #3 Inverted Index Inverted index construction Kumpulan dokumen Token Modifikasi token Tokenizer Linguistic modules perkebunan, pertanian, dan kehutanan perkebunan pertanian
PERANCANGAN DAN PEMBUATAN APLIKASI PENCARIAN INFORMASI BEASISWA DENGAN MENGGUNAKAN COSINE SIMILARITY
 Vol. 4, No. 2 Desember 2014 ISSN 2088-2130 PERANCANGAN DAN PEMBUATAN APLIKASI PENCARIAN INFORMASI BEASISWA DENGAN MENGGUNAKAN COSINE SIMILARITY Andry Kurniawan, Firdaus Solihin, Fika Hastarita Prodi Teknik
Vol. 4, No. 2 Desember 2014 ISSN 2088-2130 PERANCANGAN DAN PEMBUATAN APLIKASI PENCARIAN INFORMASI BEASISWA DENGAN MENGGUNAKAN COSINE SIMILARITY Andry Kurniawan, Firdaus Solihin, Fika Hastarita Prodi Teknik
QUERY-SENSITIVE SIMILARITY MEASURE DALAM TEMU KEMBALI DOKUMEN BERBAHASA INDONESIA ABSTRAK
 QUERY-SENSITIVE SIMILARITY MEASURE DALAM TEMU KEMBALI DOKUMEN BERBAHASA INDONESIA Sri Nurdiati 1, Julio Adisantoso 1, Adam Salnor Akbar 2 1 Staf Departemen Ilmu Komputer, Fakultas Matematika dan IPA, Institut
QUERY-SENSITIVE SIMILARITY MEASURE DALAM TEMU KEMBALI DOKUMEN BERBAHASA INDONESIA Sri Nurdiati 1, Julio Adisantoso 1, Adam Salnor Akbar 2 1 Staf Departemen Ilmu Komputer, Fakultas Matematika dan IPA, Institut
BAB II LANDASAN TEORI
 BAB II LANDASAN TEORI 2.1. Tinjauan Penelitian Terdahulu Penelitian sebelumnya dilakukan oleh Rahmatulloh (2016). Penelitian yang berjudul Rancang Bangun Sistem Informasi Pencarian Benda Hilang Lost &
BAB II LANDASAN TEORI 2.1. Tinjauan Penelitian Terdahulu Penelitian sebelumnya dilakukan oleh Rahmatulloh (2016). Penelitian yang berjudul Rancang Bangun Sistem Informasi Pencarian Benda Hilang Lost &
BAB 4 HASIL DAN BAHASAN. dengan melampirkan tabel data precision dan recall serta diagram-diagramnya Precision Recall Interpolasi
 67 BAB 4 HASIL DAN BAHASAN 4.1 Hasil Penelitian dan Evaluasi 4.1.1 Hasil Penelitian Berikut disajikan beberapa data hasil query dari penelitian yang dilakukan dengan melampirkan tabel data precision dan
67 BAB 4 HASIL DAN BAHASAN 4.1 Hasil Penelitian dan Evaluasi 4.1.1 Hasil Penelitian Berikut disajikan beberapa data hasil query dari penelitian yang dilakukan dengan melampirkan tabel data precision dan
PENDAHULUAN. Latar belakang
 Latar belakang PEDAHULUA Kata kunci atau yang biasa disebut dengan query pada pencarian informasi dari sebuah search engine digunakan sebagai kriteria pencarian yang tepat dan sesuai dengan kebutuhan.
Latar belakang PEDAHULUA Kata kunci atau yang biasa disebut dengan query pada pencarian informasi dari sebuah search engine digunakan sebagai kriteria pencarian yang tepat dan sesuai dengan kebutuhan.
Pemanfaatan Metode Vector Space Model dan Metode Cosine Similarity pada Fitur Deteksi Hama dan Penyakit Tanaman Padi
 Pemanfaatan Metode Vector Space Model dan Metode Cosine Similarity pada Fitur Deteksi Hama dan Penyakit Tanaman Padi Ana Triana Informatika, Fakultas MIPA, Universitas Sebelas Maret Surakarta Jl. Ir. Sutami
Pemanfaatan Metode Vector Space Model dan Metode Cosine Similarity pada Fitur Deteksi Hama dan Penyakit Tanaman Padi Ana Triana Informatika, Fakultas MIPA, Universitas Sebelas Maret Surakarta Jl. Ir. Sutami
SISTEM TEMU KEMBALI INFORMASI
 SISTEM TEMU KEMBALI INFORMASI ROCCHIO CLASSIFICATION Badrus Zaman, S.Si., M.Kom Doc. 1..???? Doc. 2..**** Doc. 3. #### Doc. 4..@@@ 081211633014 Emilia Fitria Fahma S1 Sistem Informasi Pengertian Teknik
SISTEM TEMU KEMBALI INFORMASI ROCCHIO CLASSIFICATION Badrus Zaman, S.Si., M.Kom Doc. 1..???? Doc. 2..**** Doc. 3. #### Doc. 4..@@@ 081211633014 Emilia Fitria Fahma S1 Sistem Informasi Pengertian Teknik
LAPORAN AKHIR HIBAH PENELITIAN dalam Rangka Kegiatan SP4 Departemen Ilmu Komputer
 LAPORAN AKHIR HIBAH PENELITIAN dalam Rangka Kegiatan SP4 Departemen Ilmu Komputer CORPUS DOKUMEN TEKS BAHASA INDONESIA UNTUK PENGUJIAN EFEKTIVITAS TEMU KEMBALI INFORMASI Oleh: Ir. Julio Adisantoso, M.Kom.
LAPORAN AKHIR HIBAH PENELITIAN dalam Rangka Kegiatan SP4 Departemen Ilmu Komputer CORPUS DOKUMEN TEKS BAHASA INDONESIA UNTUK PENGUJIAN EFEKTIVITAS TEMU KEMBALI INFORMASI Oleh: Ir. Julio Adisantoso, M.Kom.
Implementasi Metode Document Oriented Index Pruning pada Information Retrieval System
 Implementasi Metode Document Oriented Index Pruning pada Information Retrieval System Hendri Priyambowo 1, Yanuar Firdaus A.W. S.T, M.T 2, Siti Sa adah S.T. M.T 3 123 Program Studi S1 Teknik Informatika,
Implementasi Metode Document Oriented Index Pruning pada Information Retrieval System Hendri Priyambowo 1, Yanuar Firdaus A.W. S.T, M.T 2, Siti Sa adah S.T. M.T 3 123 Program Studi S1 Teknik Informatika,
Contoh Perhitungan Kemiripan Cosinus pada Model Ruang Vektor
 Contoh Perhitungan Kemiripan Cosinus pada Model Ruang Vektor Persoalan 1: Ada 4 dokumen (D1 s.d D4): D1: dolar naik harga naik penghasilan turun D2: harga naik harusnya gaji juga naik D3: Premium tidak
Contoh Perhitungan Kemiripan Cosinus pada Model Ruang Vektor Persoalan 1: Ada 4 dokumen (D1 s.d D4): D1: dolar naik harga naik penghasilan turun D2: harga naik harusnya gaji juga naik D3: Premium tidak
XML RETRIEVAL UNTUK DOKUMEN BAHASA INDONESIA MARYAM NOVIYANA BAHI
 XML RETRIEVAL UNTUK DOKUMEN BAHASA INDONESIA MARYAM NOVIYANA BAHI DEPARTEMEN ILMU KOMPUTER FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR BOGOR 2012 XML RETRIEVAL UNTUK DOKUMEN
XML RETRIEVAL UNTUK DOKUMEN BAHASA INDONESIA MARYAM NOVIYANA BAHI DEPARTEMEN ILMU KOMPUTER FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR BOGOR 2012 XML RETRIEVAL UNTUK DOKUMEN
RELEVANCE FEEDBACK PADA TEMU KEMBALI TEKS BERBAHASA INDONESIA DENGAN METODE IDE-DEC-HI DAN IDE-REGULAR
 RELEVANCE FEEDBACK PADA TEMU KEMBALI TEKS BERBAHASA INDONESIA DENGAN METODE IDE-DEC-HI DAN IDE-REGULAR Oleh: Andika Wahyu Agusetyawan G64101007 DEPARTEMEN ILMU KOMPUTER FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN
RELEVANCE FEEDBACK PADA TEMU KEMBALI TEKS BERBAHASA INDONESIA DENGAN METODE IDE-DEC-HI DAN IDE-REGULAR Oleh: Andika Wahyu Agusetyawan G64101007 DEPARTEMEN ILMU KOMPUTER FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN
BAB 1 PENDAHULUAN UKDW
 BAB 1 PENDAHULUAN 1.1 Latar Belakang Masalah Pada era ini perkembangan teknologi informasi sangat pesat. Hal ini ditandai dengan semakin populernya penggunaan internet dan perangkat lunak komputer sebagai
BAB 1 PENDAHULUAN 1.1 Latar Belakang Masalah Pada era ini perkembangan teknologi informasi sangat pesat. Hal ini ditandai dengan semakin populernya penggunaan internet dan perangkat lunak komputer sebagai
UKURAN KEMIRIPAN BM25 PADA MODEL ONTOLOGI MESIN PENCARI PRODUK ONLINE SHOP AMMAR IMRON MUHAMMAD
 UKURAN KEMIRIPAN BM25 PADA MODEL ONTOLOGI MESIN PENCARI PRODUK ONLINE SHOP AMMAR IMRON MUHAMMAD DEPARTEMEN ILMU KOMPUTER FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR BOGOR 2016
UKURAN KEMIRIPAN BM25 PADA MODEL ONTOLOGI MESIN PENCARI PRODUK ONLINE SHOP AMMAR IMRON MUHAMMAD DEPARTEMEN ILMU KOMPUTER FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR BOGOR 2016
PEMBENTUKAN PASSAGE DALAM QUESTION ANSWERING SYSTEM UNTUK DOKUMEN BAHASA INDONESIA SYAHRUL FATHI
 PEMBENTUKAN PASSAGE DALAM QUESTION ANSWERING SYSTEM UNTUK DOKUMEN BAHASA INDONESIA SYAHRUL FATHI DEPARTEMEN ILMU KOMPUTER FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR BOGOR 2012
PEMBENTUKAN PASSAGE DALAM QUESTION ANSWERING SYSTEM UNTUK DOKUMEN BAHASA INDONESIA SYAHRUL FATHI DEPARTEMEN ILMU KOMPUTER FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR BOGOR 2012
HASIL DAN PEMBAHASAN
 10 HASIL DAN PEMBAHASAN Pengumpulan Dokumen Tahapan awal yang dilakukan dalam penelitian adalah mengolah dokumen XML yang akan menjadi korpus. Terdapat 21578 dokumen berita yang terdiri atas 135 topik.
10 HASIL DAN PEMBAHASAN Pengumpulan Dokumen Tahapan awal yang dilakukan dalam penelitian adalah mengolah dokumen XML yang akan menjadi korpus. Terdapat 21578 dokumen berita yang terdiri atas 135 topik.
DIRECT TERM FEEDBACK UNTUK TEMU-KEMBALI INFORMASI BAHASA INDONESIA MENGGUNAKAN MODEL BAHASA ANITA
 DIRECT TERM FEEDBACK UNTUK TEMU-KEMBALI INFORMASI BAHASA INDONESIA MENGGUNAKAN MODEL BAHASA ANITA DEPARTEMEN ILMU KOMPUTER FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR BOGOR 2012
DIRECT TERM FEEDBACK UNTUK TEMU-KEMBALI INFORMASI BAHASA INDONESIA MENGGUNAKAN MODEL BAHASA ANITA DEPARTEMEN ILMU KOMPUTER FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR BOGOR 2012
TEMU KEMBALI INFORMASI
 JULIO ADISANTOSO Departemen Ilmu Komputer IPB Pertemuan 3 IR MODEL Mengapa Model? 1 Banyak pengembangan teknologi IR seperti web search, translator system, spam filter, dsb membutuhkan teori dan percobaan.
JULIO ADISANTOSO Departemen Ilmu Komputer IPB Pertemuan 3 IR MODEL Mengapa Model? 1 Banyak pengembangan teknologi IR seperti web search, translator system, spam filter, dsb membutuhkan teori dan percobaan.
PENERAPAN SISTEM TEMU KEMBALI INFORMASI PADA KUMPULAN DOKUMEN SKRIPSI
 18 PENERAPAN SISTEM TEMU KEMBALI INFORMASI PADA KUMPULAN DOKUMEN SKRIPSI Karter D. Putung, Arie Lumenta, Agustinus Jacobus Teknik Informatika Universitas Sam Ratulangi Manado, Indonesia. karterputung@gmail.com,
18 PENERAPAN SISTEM TEMU KEMBALI INFORMASI PADA KUMPULAN DOKUMEN SKRIPSI Karter D. Putung, Arie Lumenta, Agustinus Jacobus Teknik Informatika Universitas Sam Ratulangi Manado, Indonesia. karterputung@gmail.com,
MAXIMUM MARGINAL RELEVANCE UNTUK PERINGKASAN TEKS OTOMATIS SINOPSIS BUKU BERBAHASA INDONESIA
 MAXIMUM MARGINAL RELEVANCE UNTUK PERINGKASAN TEKS OTOMATIS SINOPSIS BUKU BERBAHASA INDONESIA Aida Indriani ) ) Teknik Informatika STMIK PPKIA Tarakanita Rahmawati Tarakan Jl Yos Sudarso 8, Tarakan 77 Email
MAXIMUM MARGINAL RELEVANCE UNTUK PERINGKASAN TEKS OTOMATIS SINOPSIS BUKU BERBAHASA INDONESIA Aida Indriani ) ) Teknik Informatika STMIK PPKIA Tarakanita Rahmawati Tarakan Jl Yos Sudarso 8, Tarakan 77 Email
INDEXING AND RETRIEVAL ENGINE UNTUK DOKUMEN BERBAHASA INDONESIA DENGAN MENGGUNAKAN INVERTED INDEX
 INDEXING AND RETRIEVAL ENGINE UNTUK DOKUMEN BERBAHASA INDONESIA DENGAN MENGGUNAKAN INVERTED INDEX Wahyu Hidayat 1 1 Departemen Teknologi Informasi, Fakultas Ilmu Terapan, Telkom University 1 wahyuhidayat@telkomuniversity.ac.id
INDEXING AND RETRIEVAL ENGINE UNTUK DOKUMEN BERBAHASA INDONESIA DENGAN MENGGUNAKAN INVERTED INDEX Wahyu Hidayat 1 1 Departemen Teknologi Informasi, Fakultas Ilmu Terapan, Telkom University 1 wahyuhidayat@telkomuniversity.ac.id
TEMU-KEMBALI MODEL EXTENDED BOOLEAN MENGGUNAKAN P-NORM MODEL DAN BELIEF REVISION DEVI DIAN PRAMANA PUTRA
 TEMU-KEMBALI MODEL EXTENDED BOOLEAN MENGGUNAKAN P-NORM MODEL DAN BELIEF REVISION DEVI DIAN PRAMANA PUTRA DEPARTEMEN ILMU KOMPUTER FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
TEMU-KEMBALI MODEL EXTENDED BOOLEAN MENGGUNAKAN P-NORM MODEL DAN BELIEF REVISION DEVI DIAN PRAMANA PUTRA DEPARTEMEN ILMU KOMPUTER FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
EVALUASI EFEKTIFITAS METODE MACHINE-LEARNING PADA SEARCH-ENGINE
 EVALUASI EFEKTIFITAS METODE MACHINE-LEARNING PADA SEARCH-ENGINE Rila Mandala Kelompok Keahlian Informatika, Sekolah Teknik Elektro dan Informatika, Institut Teknologi Bandung Jalan Ganesha 10 Bandung,
EVALUASI EFEKTIFITAS METODE MACHINE-LEARNING PADA SEARCH-ENGINE Rila Mandala Kelompok Keahlian Informatika, Sekolah Teknik Elektro dan Informatika, Institut Teknologi Bandung Jalan Ganesha 10 Bandung,
SISTEM REKOMENDASI DOSEN PEMBIMBING TUGAS AKHIR BERBASIS TEXT MINING MENGGUNAKAN VECTOR SPACE MODEL
 SISTEM REKOMENDASI DOSEN PEMBIMBING TUGAS AKHIR BERBASIS TEXT MINING MENGGUNAKAN VECTOR SPACE MODEL SKRIPSI Disusun Sebagai Salah Satu Syarat untuk Memperoleh Gelar Sarjana Komputer pada Departemen Ilmu
SISTEM REKOMENDASI DOSEN PEMBIMBING TUGAS AKHIR BERBASIS TEXT MINING MENGGUNAKAN VECTOR SPACE MODEL SKRIPSI Disusun Sebagai Salah Satu Syarat untuk Memperoleh Gelar Sarjana Komputer pada Departemen Ilmu
V HASIL DAN PEMBAHASAN
 22 V HASIL DAN PEMBAHASAN 5.1 Karakteristik Video dan Ektraksi Frame Video yang digunakan di dalam penelitian ini merupakan gabungan dari beberapa cuplikan video yang berbeda. Tujuan penggabungan beberapa
22 V HASIL DAN PEMBAHASAN 5.1 Karakteristik Video dan Ektraksi Frame Video yang digunakan di dalam penelitian ini merupakan gabungan dari beberapa cuplikan video yang berbeda. Tujuan penggabungan beberapa
Tugas Makalah. Sistem Temu Kembali Informasi (STKI) TI Implementasi Metode Generalized Vector Space Model Pada Information Retrieval System
 TI Implementasi Metode Generalized Vector Space Model Pada Information Retrieval System") Tugas Makalah Sistem Temu Kembali Informasi (STKI) TI029306 Implementasi Metode Generalized Vector Space Model Pada Information Retrieval System Oleh : I PUTU ANDREAS WARANU 1204505042 Dosen : I Putu Agus
Tugas Makalah Sistem Temu Kembali Informasi (STKI) TI029306 Implementasi Metode Generalized Vector Space Model Pada Information Retrieval System Oleh : I PUTU ANDREAS WARANU 1204505042 Dosen : I Putu Agus
Ekspansi Kueri pada Sistem Temu Kembali Informasi Berbahasa Indonesia Menggunakan Analisis Konteks Lokal
 Tersedia secara online di: http://journal.ipb.ac.id/index.php.jika Volume 1 Nomor 1 halaman 22-29 ISSN: 2089-6026 Ekspansi Kueri pada Sistem Temu Kembali Informasi Berbahasa Indonesia Menggunakan Analisis
Tersedia secara online di: http://journal.ipb.ac.id/index.php.jika Volume 1 Nomor 1 halaman 22-29 ISSN: 2089-6026 Ekspansi Kueri pada Sistem Temu Kembali Informasi Berbahasa Indonesia Menggunakan Analisis
BAB IV ANALISA DAN PERANCANGAN
 BAB IV ANALISA DAN PERANCANGAN Pada bab ini akan dibahas mengenai analisa proses information retrieval dengan menggunakan cosine similarity dan analisa proses rekomendasi buku dengan menggunakan jaccard
BAB IV ANALISA DAN PERANCANGAN Pada bab ini akan dibahas mengenai analisa proses information retrieval dengan menggunakan cosine similarity dan analisa proses rekomendasi buku dengan menggunakan jaccard
BAB III METODOLOGI PENELITIAN
 BAB III METODOLOGI PENELITIAN Metodologi penelitian merupakan rangkaian dari langkah-langkah yang diterapkan dalam penelitian, secara umum dan khusus langkah-langkah tersebut tertera pada Gambar flowchart
BAB III METODOLOGI PENELITIAN Metodologi penelitian merupakan rangkaian dari langkah-langkah yang diterapkan dalam penelitian, secara umum dan khusus langkah-langkah tersebut tertera pada Gambar flowchart
Bernadus Very Christioko Fakultas Teknologi Informasi dan Komunikasi, Universitas Semarang. Abstract
 IMPLEMENTASI SISTEM TEMU KEMBALI INFORMASI Studi Kasus: Dokumen Teks Berbahasa Indonesia (IMPLEMENTATION OF INFORMATION RETRIEVAL SYSTEM Case Study: Text Document in Indonesian Language) Bernadus Very
IMPLEMENTASI SISTEM TEMU KEMBALI INFORMASI Studi Kasus: Dokumen Teks Berbahasa Indonesia (IMPLEMENTATION OF INFORMATION RETRIEVAL SYSTEM Case Study: Text Document in Indonesian Language) Bernadus Very
PRESENTASI TUGAS AKHIR KI PERANCANGAN DAN PEMBANGUNAN MODUL REKOMENDASI SECTION PADA OPEN JOURNAL SYSTEM (OJS)
") PRESENTASI TUGAS AKHIR KI091391 PERANCANGAN DAN PEMBANGUNAN MODUL REKOMENDASI SECTION PADA OPEN JOURNAL SYSTEM (OJS) (Kata kunci: Jurnal, K-Nearest Neighbor, Karya Ilmiah, Klasifikasi Penyusun Tugas Akhir
PRESENTASI TUGAS AKHIR KI091391 PERANCANGAN DAN PEMBANGUNAN MODUL REKOMENDASI SECTION PADA OPEN JOURNAL SYSTEM (OJS) (Kata kunci: Jurnal, K-Nearest Neighbor, Karya Ilmiah, Klasifikasi Penyusun Tugas Akhir
PENCARIAN FULL TEXT PADA KOLEKSI SKRIPSI FAKULTAS TEKNIK UHAMKA MENGGUNAKAN METODE VECTOR SPACEMODEL
 Vol. 2, 2017 PENCARIAN FULL TEXT PADA KOLEKSI SKRIPSI FAKULTAS TEKNIK UHAMKA MENGGUNAKAN METODE VECTOR SPACEMODEL Miftahul Ari Kusuma 1*, Mia Kamayani 2, Arry Avorizano 3 Program Studi Teknik Informatika,
Vol. 2, 2017 PENCARIAN FULL TEXT PADA KOLEKSI SKRIPSI FAKULTAS TEKNIK UHAMKA MENGGUNAKAN METODE VECTOR SPACEMODEL Miftahul Ari Kusuma 1*, Mia Kamayani 2, Arry Avorizano 3 Program Studi Teknik Informatika,
Tugas Makalah. Sistem Temu Kembali Informasi (STKI) TI Implementasi Metode Generalized Vector Space Model Pada Information Retrieval System
 TI Implementasi Metode Generalized Vector Space Model Pada Information Retrieval System") Tugas Makalah Sistem Temu Kembali Informasi (STKI) TI029306 Implementasi Metode Generalized Vector Space Model Pada Information Retrieval System Oleh : I PUTU ANDREAS WARANU 1204505042 Dosen : I Putu Agus
Tugas Makalah Sistem Temu Kembali Informasi (STKI) TI029306 Implementasi Metode Generalized Vector Space Model Pada Information Retrieval System Oleh : I PUTU ANDREAS WARANU 1204505042 Dosen : I Putu Agus
JULIO ADISANTOSO - ILKOM IPB 1
 KOM341 Temu Kembali Informasi Proses Temu-Kembali KULIAH #5 Evaluasi IR query : sby query: flu burung Evaluasi IR Indikator yang dapat diukur: Seberapa cepat dia meng-indeks Banyaknya dokumen/jam Terkait
KOM341 Temu Kembali Informasi Proses Temu-Kembali KULIAH #5 Evaluasi IR query : sby query: flu burung Evaluasi IR Indikator yang dapat diukur: Seberapa cepat dia meng-indeks Banyaknya dokumen/jam Terkait
UNIVERSITAS MERCU BUANA FAKULTAS : ILMU KOMPUTER PROGRAM STUDI : SISTEM INFORMASI
 UNIVERSITAS MERCU BUANA FAKULTAS : ILMU KOMPUTER PROGRAM STUDI : SISTEM INFORMASI No. Dokumen 02-3.04.1.02 Distribusi Tgl. Efektif RENCANA PEMBELAJARAN SEMESTER Mata Kuliah Kode Rumpun MK Bobot (SKS) Semester
UNIVERSITAS MERCU BUANA FAKULTAS : ILMU KOMPUTER PROGRAM STUDI : SISTEM INFORMASI No. Dokumen 02-3.04.1.02 Distribusi Tgl. Efektif RENCANA PEMBELAJARAN SEMESTER Mata Kuliah Kode Rumpun MK Bobot (SKS) Semester
HASIL DAN PEMBAHASAN. Praproses
 5 4 MySQL sebagai database. 5 Mozilla Firefox sebagai web browser. 6 Microsoft Excel untuk perhitungan hasil penelitian dan pembuatan grafik. Perangkat keras: 1 Prosesor Intel Core i3. 2 RAM 2 GB. 3 Harddisk
5 4 MySQL sebagai database. 5 Mozilla Firefox sebagai web browser. 6 Microsoft Excel untuk perhitungan hasil penelitian dan pembuatan grafik. Perangkat keras: 1 Prosesor Intel Core i3. 2 RAM 2 GB. 3 Harddisk
BAB 2 TINJAUAN PUSTAKA
 BAB 2 TINJAUAN PUSTAKA 2.1 Tes Secara harfiah kata tes berasal dari kata bahasa prancis kuno: testum yang berarti piring untuk menyisihkan logam-logam mulia, dalam bahasa Indonesia diterjemahkan dengan
BAB 2 TINJAUAN PUSTAKA 2.1 Tes Secara harfiah kata tes berasal dari kata bahasa prancis kuno: testum yang berarti piring untuk menyisihkan logam-logam mulia, dalam bahasa Indonesia diterjemahkan dengan
BAB II LANDASAN TEORI
 BAB II LANDASAN TEORI 2.1. Information Retrieval Perkembangan teknologi internet yang sangat pesat membuat pengguna harus dapat menyaring informasi yang dibutuhkannya. Information retrieval atau sistem
BAB II LANDASAN TEORI 2.1. Information Retrieval Perkembangan teknologi internet yang sangat pesat membuat pengguna harus dapat menyaring informasi yang dibutuhkannya. Information retrieval atau sistem
Search Engines. Information Retrieval in Practice
 Search Engines Information Retrieval in Practice All slides Addison Wesley, 2008 Search Engine Architecture Arsitektur dari mesin pencari ditentukan oleh 2 persyaratan efektivitas (kualitas hasil) efisiensi
Search Engines Information Retrieval in Practice All slides Addison Wesley, 2008 Search Engine Architecture Arsitektur dari mesin pencari ditentukan oleh 2 persyaratan efektivitas (kualitas hasil) efisiensi
QUERY EXPANSION DENGAN MENGGABUNGKAN METODE RUANG VEKTOR DAN WORDNET PADA SISTEM INFORMATION RETRIEVAL
 QUERY EXPANSION DENGAN MENGGABUNGKAN METODE RUANG VEKTOR DAN WORDNET PADA SISTEM INFORMATION RETRIEVAL Susetyo Adi Nugroho () Abstrak: Salah satu metode yang sering digunakan dalam mengukur relevansi dokumen
QUERY EXPANSION DENGAN MENGGABUNGKAN METODE RUANG VEKTOR DAN WORDNET PADA SISTEM INFORMATION RETRIEVAL Susetyo Adi Nugroho () Abstrak: Salah satu metode yang sering digunakan dalam mengukur relevansi dokumen
RETRIEVAL STRATEGIES. Tujuan 4/9/13. Budi Susanto
 Text & Web Mining - Budi Susanto - TI UKDW 1 RETRIEVAL STRATEGIES Budi Susanto Text & Web Mining - Budi Susanto - TI UKDW 2 Tujuan Memahami model probabilitistic retrieval dengan metode Simple Term Weights.
Text & Web Mining - Budi Susanto - TI UKDW 1 RETRIEVAL STRATEGIES Budi Susanto Text & Web Mining - Budi Susanto - TI UKDW 2 Tujuan Memahami model probabilitistic retrieval dengan metode Simple Term Weights.
PEMBOBOTAN RIDF PADA MESIN PENCARI BAHASA INDONESIA UNTUK EKSPANSI KUERI MENGGUNAKAN ANALISIS KONTEKS LOKAL FANIA RAHMANAWATI KARIMAH
 PEMBOBOTAN RIDF PADA MESIN PENCARI BAHASA INDONESIA UNTUK EKSPANSI KUERI MENGGUNAKAN ANALISIS KONTEKS LOKAL FANIA RAHMANAWATI KARIMAH DEPARTEMEN ILMU KOMPUTER FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
PEMBOBOTAN RIDF PADA MESIN PENCARI BAHASA INDONESIA UNTUK EKSPANSI KUERI MENGGUNAKAN ANALISIS KONTEKS LOKAL FANIA RAHMANAWATI KARIMAH DEPARTEMEN ILMU KOMPUTER FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
BAB II TINJAUAN PUSTAKA
 BAB II TINJAUAN PUSTAKA 2.1. Sistem Temu Kembali Informasi Sistem Temu Kembali Informasi atau Information Retrieval (IR) adalah kegiatan untuk menemukan suatu material (dokumen) dari data yang tidak terstruktur
BAB II TINJAUAN PUSTAKA 2.1. Sistem Temu Kembali Informasi Sistem Temu Kembali Informasi atau Information Retrieval (IR) adalah kegiatan untuk menemukan suatu material (dokumen) dari data yang tidak terstruktur
Rata-rata token unik tiap dokumen
 Percobaan Tujuan percobaan ini adalah untuk mengetahui kinerja algoritme pengoreksian ejaan Damerau Levenshtein. Akan dilihat apakah algoritme tersebut dapat memberikan usulan kata yang cukup baik untuk
Percobaan Tujuan percobaan ini adalah untuk mengetahui kinerja algoritme pengoreksian ejaan Damerau Levenshtein. Akan dilihat apakah algoritme tersebut dapat memberikan usulan kata yang cukup baik untuk
PERINGKASAN DOKUMEN BAHASA INDONESIA MENGGUNAKAN METODE MAXIMUM MARGINAL RELEVANCE LUTFIA AFIFAH
 PERINGKASAN DOKUMEN BAHASA INDONESIA MENGGUNAKAN METODE MAXIMUM MARGINAL RELEVANCE LUTFIA AFIFAH DEPARTEMEN ILMU KOMPUTER FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR BOGOR 2015
PERINGKASAN DOKUMEN BAHASA INDONESIA MENGGUNAKAN METODE MAXIMUM MARGINAL RELEVANCE LUTFIA AFIFAH DEPARTEMEN ILMU KOMPUTER FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR BOGOR 2015
ABSTRAK. Kata kunci : Information Retrieval system, Generalized Vector Space Model. Universitas Kristen Maranatha
 ABSTRAK Information retrieval (IR) system adalah sistem yang secara otomatis melakukan pencarian atau penemuan kembali informasi yang relevan terhadap kebutuhan pengguna. Kebutuhan pengguna, diekspresikan
ABSTRAK Information retrieval (IR) system adalah sistem yang secara otomatis melakukan pencarian atau penemuan kembali informasi yang relevan terhadap kebutuhan pengguna. Kebutuhan pengguna, diekspresikan
Fatkhul Amin Dosen Fakultas Teknologi Informasi Universitas Stikubank Semarang
 45 Dinamika Teknik Januari IMPLEMENTASI SEARCH ENGINE (MESIN PENCARI) MENGGUNAKAN METODE VECTOR SPACE MODEL Dosen Fakultas Teknologi Informasi Universitas Stikubank Semarang Abstract Growth of Machine
45 Dinamika Teknik Januari IMPLEMENTASI SEARCH ENGINE (MESIN PENCARI) MENGGUNAKAN METODE VECTOR SPACE MODEL Dosen Fakultas Teknologi Informasi Universitas Stikubank Semarang Abstract Growth of Machine
MESIN PENCARI DOKUMEN BAHASA INDONESIA MENGGUNAKAN LATENT SEMANTIC INDEXING DENGAN PEMBOBOTAN GLOBAL SUSI HANDAYANI
 MESIN PENCARI DOKUMEN BAHASA INDONESIA MENGGUNAKAN LATENT SEMANTIC INDEXING DENGAN PEMBOBOTAN GLOBAL SUSI HANDAYANI DEPARTEMEN ILMU KOMPUTER FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN
MESIN PENCARI DOKUMEN BAHASA INDONESIA MENGGUNAKAN LATENT SEMANTIC INDEXING DENGAN PEMBOBOTAN GLOBAL SUSI HANDAYANI DEPARTEMEN ILMU KOMPUTER FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN
BAB III METODELOGI PENELITIAN
 BAB III METODELOGI PENELITIAN 3.1 Metode Penelitian Metode penelitian yang digunakan yaitu metode eksperimental dimana metode ini bekerja dengan memanipulasi dan melakukan kontrol pada objek penelitian
BAB III METODELOGI PENELITIAN 3.1 Metode Penelitian Metode penelitian yang digunakan yaitu metode eksperimental dimana metode ini bekerja dengan memanipulasi dan melakukan kontrol pada objek penelitian
RELEVANCE FEEDBACK PADA TEMU-KEMBALI TEKS BERBAHASA INDONESIA DENGAN METODE IDE-DEC-HI DAN IDE-REGULAR
 RELEVANCE FEEDBACK PADA TEMU-KEMBALI TEKS BERBAHASA INDONESIA DENGAN METODE IDE-DEC-HI DAN IDE-REGULAR Julio Adisantoso, Ahmad Ridha, Andika Wahyu Agusetyawan Staf Departemen Ilmu Komputer, Fakultas Matematika
RELEVANCE FEEDBACK PADA TEMU-KEMBALI TEKS BERBAHASA INDONESIA DENGAN METODE IDE-DEC-HI DAN IDE-REGULAR Julio Adisantoso, Ahmad Ridha, Andika Wahyu Agusetyawan Staf Departemen Ilmu Komputer, Fakultas Matematika
Sistem Informasi Tugas Akhir Menggunakan Model Ruang Vektor (Studi Kasus: Jurusan Sistem Informasi)
") Sistem Informasi Tugas Akhir Menggunakan Model Ruang Vektor (Studi Kasus: Jurusan Sistem Informasi) Wahyudi,MT Laboratorium Sistem Informasi Fakultas Sains dan Teknologi UINSUSKA RIAU Jl.HR.Subrantas KM.15
Sistem Informasi Tugas Akhir Menggunakan Model Ruang Vektor (Studi Kasus: Jurusan Sistem Informasi) Wahyudi,MT Laboratorium Sistem Informasi Fakultas Sains dan Teknologi UINSUSKA RIAU Jl.HR.Subrantas KM.15
TUGAS AKHIR PERANCANGAN DAN IMPLEMENTASI SISTEM PENCARIAN BUKU RUANG BACA ILMU KOMPUTER UDAYANA BERBASIS WEB DENGAN METODE BM25 KOMPETENSI RPL
 TUGAS AKHIR PERANCANGAN DAN IMPLEMENTASI SISTEM PENCARIAN BUKU RUANG BACA ILMU KOMPUTER UDAYANA BERBASIS WEB DENGAN METODE BM25 KOMPETENSI RPL MICHAEL SENNA SAPUTRA NIM. 1008605062 PROGRAM STUDI TEKNIK
TUGAS AKHIR PERANCANGAN DAN IMPLEMENTASI SISTEM PENCARIAN BUKU RUANG BACA ILMU KOMPUTER UDAYANA BERBASIS WEB DENGAN METODE BM25 KOMPETENSI RPL MICHAEL SENNA SAPUTRA NIM. 1008605062 PROGRAM STUDI TEKNIK
II TINJAUAN PUSTAKA. * adalah operasi konvolusi x dan y, adalah fungsi yang merepresentasikan citra output,
 5 II INJAUAN PUSAKA.1 Fitur Scale Invariant Feature ransform (SIF) Fitur lokal ditentukan berdasarkan pada kemunculan sebuah objek pada lokasi tertentu di dalam frame. Fitur yang dimaksudkan haruslah bersifat
5 II INJAUAN PUSAKA.1 Fitur Scale Invariant Feature ransform (SIF) Fitur lokal ditentukan berdasarkan pada kemunculan sebuah objek pada lokasi tertentu di dalam frame. Fitur yang dimaksudkan haruslah bersifat
BAB II TINJAUAN PUSTAKA
 BAB II TINJAUAN PUSTAKA 2.1. Penelitian Terkait 2.1.1. Implementasi Opinion Mining Pernah dilakukan penelitian tentang opinion mining membahas tentang ekstraksi data opini publik pada perguruan tinggi.
BAB II TINJAUAN PUSTAKA 2.1. Penelitian Terkait 2.1.1. Implementasi Opinion Mining Pernah dilakukan penelitian tentang opinion mining membahas tentang ekstraksi data opini publik pada perguruan tinggi.
PERSETUJUAI\ ARTIKEL ILMIAH. Mashar Eka Putra Dai. S1-Sistem Informasi. Teknik Informatika. Teknik. Penerapan Metode Document Frequency
 PERSETUJUAI\ ARTIKEL ILMIAH Artikel ilmiah hasil penelitian mahasiswa: Nama NIM Mashar Eka Putra Dai 53 1409036 Program Studi S1-Sistem Informasi Jurusan Teknik Informatika Fakultas Teknik Judul Karya
PERSETUJUAI\ ARTIKEL ILMIAH Artikel ilmiah hasil penelitian mahasiswa: Nama NIM Mashar Eka Putra Dai 53 1409036 Program Studi S1-Sistem Informasi Jurusan Teknik Informatika Fakultas Teknik Judul Karya
4 HASIL DAN PEMBAHASAN
 24 4 HASIL DAN PEMBAHASAN 4.1 Data Korpus Data korpus berisi berita-berita nasional berbahasa Indonesia dari tanggal 11 Maret 2002 sampai 11 April 2002. Berita tersebut berasal dari berita online harian
24 4 HASIL DAN PEMBAHASAN 4.1 Data Korpus Data korpus berisi berita-berita nasional berbahasa Indonesia dari tanggal 11 Maret 2002 sampai 11 April 2002. Berita tersebut berasal dari berita online harian
IMPLEMENTASI VECTOR SPACE MODEL DAN BEBERAPA NOTASI METODE TERM FREQUENCY INVERSE DOCUMENT FREQUENCY (TF-IDF) PADA SISTEM TEMU KEMBALI INFORMASI
 PADA SISTEM TEMU KEMBALI INFORMASI") IMPLEMENTASI VECTOR SPACE MODEL DAN BEBERAPA NOTASI METODE TERM FREQUENCY INVERSE DOCUMENT FREQUENCY (TF-IDF) PADA SISTEM TEMU KEMBALI INFORMASI Oka Karmayasa dan Ida Bagus Mahendra Program Studi Teknik
IMPLEMENTASI VECTOR SPACE MODEL DAN BEBERAPA NOTASI METODE TERM FREQUENCY INVERSE DOCUMENT FREQUENCY (TF-IDF) PADA SISTEM TEMU KEMBALI INFORMASI Oka Karmayasa dan Ida Bagus Mahendra Program Studi Teknik
BAB I PENDAHULUAN 1.1 Latar Belakang
 BAB I PENDAHULUAN 1.1 Latar Belakang Buku merupakan media informasi yang memiliki peran penting dalam perkembangan ilmu pengetahuan, karena dengan buku kita dapat memperoleh banyak informasi, pengetahuan
BAB I PENDAHULUAN 1.1 Latar Belakang Buku merupakan media informasi yang memiliki peran penting dalam perkembangan ilmu pengetahuan, karena dengan buku kita dapat memperoleh banyak informasi, pengetahuan
TEMU KEMBALI INFORMASI DOKUMEN XML DENGAN PEMBOBOTAN PER KONTEKS RINA KURNIAWATI
 TEMU KEMBALI INFORMASI DOKUMEN XML DENGAN PEMBOBOTAN PER KONTEKS RINA KURNIAWATI DEPARTEMEN ILMU KOMPUTER FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR BOGOR 2014 PERNYATAAN MENGENAI
TEMU KEMBALI INFORMASI DOKUMEN XML DENGAN PEMBOBOTAN PER KONTEKS RINA KURNIAWATI DEPARTEMEN ILMU KOMPUTER FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR BOGOR 2014 PERNYATAAN MENGENAI
PEMANFAATAN ASSOCIATION RULE MINING DALAM MEMBANTU PENCARIAN DOKUMEN-DOKUMEN BERITA YANG SALING BERKAITAN
 PEMANFAATAN ASSOCIATION RULE MINING DALAM MEMBANTU PENCARIAN DOKUMEN-DOKUMEN BERITA YANG SALING BERKAITAN Hermawan Andika Institut Informatika Indonesia andika@iii.ac.id Suhatati Tjandra Sekolah Tinggi
PEMANFAATAN ASSOCIATION RULE MINING DALAM MEMBANTU PENCARIAN DOKUMEN-DOKUMEN BERITA YANG SALING BERKAITAN Hermawan Andika Institut Informatika Indonesia andika@iii.ac.id Suhatati Tjandra Sekolah Tinggi
IMPLEMENTASI VECTOR SPACE MODEL UNTUK MENINGKATKAN KUALITAS PADA SISTEM PENCARIAN BUKU PERPUSTAKAAN
 Seminar Nasional Informatika 205 IMPLEMENTASI VECTOR SPACE MODEL UNTUK MENINGKATKAN KUALITAS PADA SISTEM PENCARIAN BUKU PERPUSTAKAAN Dedi Leman, Khusaeri Andesa 2 Teknik Informasi, Magister Komputer, Universitas
Seminar Nasional Informatika 205 IMPLEMENTASI VECTOR SPACE MODEL UNTUK MENINGKATKAN KUALITAS PADA SISTEM PENCARIAN BUKU PERPUSTAKAAN Dedi Leman, Khusaeri Andesa 2 Teknik Informasi, Magister Komputer, Universitas
KLASIFIKASI DOKUMEN BAHASA INDONESIA MENGGUNAKAN ADAPTIVE CLASSIFIER COMBINATION (ACC) MUTHIA AZIZA
 MUTHIA AZIZA") KLASIFIKASI DOKUMEN BAHASA INDONESIA MENGGUNAKAN ADAPTIVE CLASSIFIER COMBINATION (ACC) MUTHIA AZIZA DEPARTEMEN ILMU KOMPUTER FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR BOGOR
KLASIFIKASI DOKUMEN BAHASA INDONESIA MENGGUNAKAN ADAPTIVE CLASSIFIER COMBINATION (ACC) MUTHIA AZIZA DEPARTEMEN ILMU KOMPUTER FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR BOGOR
BAB 3 METODE PENELITIAN. pengelolaan dokumen yang efektif agar kita dapat me-retrieve informasi yang
 58 BAB 3 METODE PENELITIAN 3.1 Analisis Masalah Seiring dengan perkembangan zaman, jumlah informasi yang disimpan dalam betuk digital semakin bertambah, sehingga dibutuhkan cara pengorganisasian dan pengelolaan
58 BAB 3 METODE PENELITIAN 3.1 Analisis Masalah Seiring dengan perkembangan zaman, jumlah informasi yang disimpan dalam betuk digital semakin bertambah, sehingga dibutuhkan cara pengorganisasian dan pengelolaan
RANCANG BANGUN SISTEM PENCARIAN DOKUMEN JURNAL MENGGUNAKAN METODE BM25+
 RANCANG BANGUN SISTEM PENCARIAN DOKUMEN JURNAL MENGGUNAKAN METODE BM25+ LEMBAR JUDUL SKRIPSI DENI SUPRIAWAN NIM. 1108605001 PROGRAM STUDI TEKNIK INFORMATIKA JURUSAN ILMU KOMPUTER FAKULTAS MATEMATIKA DAN
RANCANG BANGUN SISTEM PENCARIAN DOKUMEN JURNAL MENGGUNAKAN METODE BM25+ LEMBAR JUDUL SKRIPSI DENI SUPRIAWAN NIM. 1108605001 PROGRAM STUDI TEKNIK INFORMATIKA JURUSAN ILMU KOMPUTER FAKULTAS MATEMATIKA DAN