Bab III Studi Kasus III.1 Decline Rate
|
|
|
- Doddy Chandra
- 6 tahun lalu
- Tontonan:
Transkripsi
1 Bab III Studi Kasus III.1 Decline Rate Studi kasus akan difokuskan pada data penurunan laju produksi (decline rate) di 31 lokasi sumur reservoir panas bumi Kamojang, Garut. Persoalan mendasar dalam penilaian kinerja reservoir adalah menghitung umur produktif reservoir dan mengestimasi kapasitas produksi dalam t-jangka waktu ke depan. Parameter yang paling sederhana dalam penghitungan ini adalah laju produksi. Cara yang rasional dalam menjawab persoalan di atas dengan menggunakan perhitungan adalah memplot variabel laju produksi terhadap waktu atau terhadap produksi kumulatif. Perluasan kurva produksi terhadap waktu dapat menunjukkan umur ekonomi reservoir. Plot laju produksi terhadap waktu pada umumnya akan menunjukkan laju produksi yang cukup tinggi pada awal produksi dan terus menurun seiring pertambahan waktu. Decline curve analysis digunakan untuk estimasi perhitungan cadangan yang diamati di suatu lapangan, mencerminkan tingkat keekonomian lapangan tersebut dan memprediksi kinerja produksi suatu lapangan berdasarkan data historis. Perhitungan decline curve didasarkan pada penurunan laju produksi. Dengan menggunakan asumsi bahwa laju produksi secara kontinu mengikuti trend yang sudah ada, maka besarnya cadangan panas bumi dapat diperkirakan dari model trend laju penurunan produksi. Data yang digunakan adalah data produksi dari 31 sumur panas bumi yang berlokasi di Kamojang Jawa Barat yang di ambil dari tesis Isnani (005). Nilai decline rate setiap sumur diperoleh dari perhitungan logaritma normalisasi uji produksi yang diregresikan terhadap waktu. Lokasi sumur dinyatakan dengan koordinat easting dan Northing dengan satuan meter. Area pengamatan berkisar antara -500 sampai easting, dan 700 sampai 3700 northing. Laju penurunan produksi sumur dianalisis dengan menggunakan laju penurunan eksponensial. KMJ xx menyatakan sumur panas bumi Kamojang, KMJ 01 artinya sumur panas bumi kamojang nomor 1. 3
2 III. Penaksiran Model Semivariogram Tabel III.1 memperlihatkan koordinat dan laju penurunan pada 31 sumur produksi. Gambar III.1 menunjukkan lokasi sumur produksi. Sari numerik data decline rate memperlihatkan nilai skewness cukup besar yang menunjukkan bahwa distribusi data tidak simetris. Untuk itu dilakukan transformasi sedemikian sehingga distribusi data hasil transformasi lebih simetris. Dalam hal ini bentuk transformasi yang dipilih adalah z*( s) = 3 z( s ), dengan z() s adalah nilai decline rate di lokasi yang berkoordinat s = ( x, y ). Dengan bentuk distribusi yang simetris, penaksiran semivariogram menggunakan penaksir robust dapat dilakukan. No Sumur Tabel III.1 Lokasi dan nilai decline masing-masing sumur Koordinat Decline rate perbulan ( ) z Data transformasi ( z *) X (m) Y (m) 1 KMJ KMJ KMJ KMJ KMJ KMJ KMJ KMJ KMJ KMJ KMJ KMJ KMJ KMJ KMJ KMJ KMJ KMJ KMJ KMJ KMJ KMJ KMJ KMJ KMJ KMJ KMJ KMJ KMJ KMJ KMJ
3 north-south KMJ 44 KMJ 40 KMJ 36 KMJ 46 KMJ 7 KMJ 30 KMJ 4 KMJ 6 KMJ 35 KMJ 6 KMJ 41 KMJ KMJ 37 KMJ 5 KMJ 8 KMJ 31 KMJ 51 KMJ 34 KMJ 33 KMJ 4 KMJ 39 KMJ 5 KMJ 43 KMJ 11 KMJ 14 KMJ 1 KMJ 18 KMJ 17 KMJ 45 KMJ 38 KMJ east-west Gambar III.1. Lokasi sumur produksi Tabel III. Sari numerik data decline rate Univariate Statistics Decline Average Median Minimum Maximum Range Variance Skewness Kurtosis 1.37 Tabel III.3 Sari numerik data hasil transformasi Univariate Statistics data transformasi Average Median Minimum Maximum Range Standard Deviation Variance Skewness Kurtosis
4 Gambar III.. Histogram data decline rate Gambar III.3. Histogram data hasil transformasi Dari gambar histogram terlihat bahwa data hasil transformasi menunjukkan distribusi yang lebih simetris dan lebih mendekati distribusi normal dibandingkan dengan data sebelum transformasi. Selanjutnya data hasil teransformasi dijadikan input untuk menghitung semivariogram eksperimental robust. Semivariogram eksperimental dihitung dalam empat arah utama yaitu Barat-Timur (BT), Utara-Selatan (US), Timur 6
5 Laut-Barat Daya (TLBD), dan Barat Laut-Tenggara (BLTG). Toleransi azimut yang digunakan adalah 10 derajat. Dalam setiap arah, lokasi dibagi ke dalam beberapa kelas jarak, dengan lebar setiap kelas jarak adalah 90 m (toleransi yang digunakan adalah ± 145 m). Tabel berikut memperlihatkan nilai semivariogram eksperimental untuk keempat arah tersebut yang dihitung dengan menggunakan rumus pada persamaan.7. Tabel III.4 Semivariogram eksperimental untuk empat arah Barat-Timur (BT) kelas h ˆ( γ h) # pasangan lokasi Utara-Selatan (US) kelas h ˆ( γ h) #pasangan lokasi Timur Laut- Barat Daya (TLBD) kelas h ˆ( γ h) #pasangan lokasi Barat Laut-Tenggara (BLTG) kelas h ˆ( γ h) #pasangan lokasi
6 semivariogram eksperimental jarak pisah (m) B-T U-S TL-BD BL-TG Gambar III.4. Plot semivariogram eksperimental untuk keempat arah Nilai semivariogram eksperimental untuk keempat arah tidak terlalu jauh berbeda, sehingga dapat kita anggap semivariogram tersebut isotropik. Maka, semivariogram eksperimental dapat dihitung dengan hanya memperhatikan jarak pisah antar lokasi. Dengan demikian, diperoleh semivariogram eksperimental isotropik sebagai berikut Tabel III.5 Semivariogram eksperimental isotropik kelas h ˆ( γ h) semivariogram eksperimental lag (m) Gambar III.5. Plot semivariogram eksperimental isotropik 8
7 Selanjutnya akan dicari model semivariogram yang dapat memodelkan semivariogram eksperimental dengan menggunakan regresi median melaui kopula. Pertama-tama akan ditaksir fungsi distribusi dari h yang merupakan jarak pisah antara dua sumur dan fungsi distribusi dari T 1 Z*( s) Z*( s+ h) = deskriptif dari h sebagai berikut, dengan s, s + h D. Terlebih dahulu kita tinjau statistik Tabel III.6 Statistik deskriptif h Univariate Statistics h Count 160 Sum 179, Average 1, Median 1, Minimum.61 Maximum 1, Range 1, Standard Deviation Variance 14, Skewness Kurtosis th Percentile th Percentile 1, h Gambar III.6. Boxplot h 9
8 Distribusi dari h diasumsikan normal dengan mean dan variansi Asumsi ini diuji dengan uji Kolmogorov-Smirnov. Statistik uji bagi * uji Kolmogorov-Smirnov adalah S = sup Fi( ) Fi ( ) i h h, dengan F adalah fungsi distribusi kumulatif empirik dari h dan F* adalah fungsi distribusi yang dihipotesiskan, dalam hal ini normal dengan mean dan variansi seperti tersebut di atas. Hasil perhitungan menghasilkan S = Pada uji Kolmogorov-Smirnov, untuk tingkat keberartian 5% dan n > 40, hipotesis bahwa h berdistribusi normal dengan mean dan variansi ditolak jika S > 1.36 dengan n adalah banyaknya pasangan lokasi sumur yang diikutkan dalam penghitungan semivariogram. (dalam kasus ini n = 160). Didapatkan 1.36 n = Maka hipotesis bahwa h berdistribusi normal dengan mean dan variansi tidak ditolak. Dengan demikian, distribusi tersebut dapat digunakan untuk memodelkan distribusi dari h. n 1 Z*( s) Z*( s+ h) Selanjutnya akan diselidiki fungsi distribusi dari T = Statistik deskriptif dari T adalah sebagai berikut. Tabel III.7 Statistik deskriptif T Univariate Statistics Count 160 Sum Average Median Minimum Maximum Range Standard Deviation Variance Skewness Kurtosis th Percentile th Percentile
9 T Gambar III.7. Histogram T Fungsi distribusi dari T diasumsikan Weibull,yaitu GT ( ) = 1 e τ ( t / θ ),dengan parameter θ= dan τ = Parameter θ dan τ ditaksir dari data. Asumsi ini juga diuji dengan uji Kolmogorov-Smirnov. Perhitungan menghasilkan S = Dengan tingkat keberartian 5% didapatkan titik kritis yang sama seperti sebelumnya yaitu Maka hipotesis bahwa T berdistribusi Weibull dengan parameter θ = dan τ = tidak ditolak. Dengan demikian, distribusi tersebut dapat digunakan untuk memodelkan distribusi dari T. Selanjutnya kopula yang menggambarkan distribusi bivariat antara U = F ( h ) dan V = G( T) akan dimodelkan dengan salah satu dari kopula yang dikenal yaitu kopula Clayton. Parameter α dari kopula Clayton akan ditaksir dengan menggunakan metode maximum likelihood sebagai berikut: 1. hitung nilai CDF untuk masing-masing pasangan u = F ( h ) vi = G( T), dengan i = 1,,...,n, di mana n adalah banyaknya pasangan i lokasi yang diikutkan dalam penghitungan semivariogram yaitu n = 160,. selanjutnya bentuk fungsi n ( i i ) (3.1) ln L = ln c(u, v ) α i= 1 i i dan 31
10 C(u, v) dengan c(u, v) =, turunan kedua dari kopula C(u,v) (dalam hal uv ini kopula Clayton), 3. cari ˆα yang memaksimumkan fungsi (3.1), ˆα yang didapat adalah penaksir bagi α. Dari perhitungan yang dilakukan, didapatkan ˆα = Dengan demikian, kopula yang akan digunakan adalah C(u,v) = ( + ) u v. Selanjutnya, kecocokkan kopula ini akan diuji dengan menggunakan uji Khikuadrat. Pertama-tama, daerah domain kopula, yaitu persegi [0,1] [0,1] R, dipartisi menjadi 5 persegi yang luasnya sama. Untuk setiap persegi, frekuensi titik (ui, v i ) dihitung. Persegi dengan frekuensi yang kecil (kurang dari 5) digabung dengan persegi yang lain. Lalu terapkan uji khi-kuadrat. Dari hasil pengujian, didapatkan nilai p-value sebesar Dengan tingkat keberartian 0.05, hipotesis bahwa kopula dari u dan v adalah Clayton dengan parameter α= tidak ditolak. Maka, kopula ini dapat digunakan. Sekarang yang akan dilakukan adalah menentukan model semivariogram melalui regresi median kopula. Untuk kopula Clayton, persamaan (, ) = 0.5 u Cuv v yang merupakan solusi bagi adalah ( ) 1 /( + 1) = 1 + (0.5 1) v u α α α α. Dengan demikian, didapatkan model semivariogram isotropik yaitu γ ( h ) = atau, dengan u = F ( h ), GT ( ) = 1 e τ ( t / θ ) G 1 (), v h > 0 0, h = 0 di mana θ = dan τ=0.586, dan γ ( h ) = α=0.0571, model semivariogram tersebut dapat dituliskan sebagai , h = ln h > ( u ), 0 (3.) h 1 1 x u = F = exp dx π dengan ( h ) 3
11 Plot semivariogram eksperimental isotropik (garis putus-putus) bersama dengan model semivariogram (garis solid) yang diperoleh adalah sebagai berikut jarak pisah (m) Gambar III.8. Plot model semivariogram dan semivariogram eksperimental isotropik III.3 Validasi Silang Model semivariogram yang diperoleh harus diuji validitasnya. Untuk itu dilakukan uji validasi silang (Kitanidis, 1997). Hipotesis yang diuji adalah bahwa z* merupakan realisasi dari proses spasial intrinsik dengan semivariogram γ ( h ) seperti pada persamaan 3.. Pertama-tama lokasi sampel diberi nomor dari 1 sampai 31. Kemudian taksir nilai z* di s dengan hanya menggunakan nilai z* di s1 s 1 melalui ordinary kriging. Maka didapatkan ẑ*( ) = z*( s ) dan σ K( s) = γ( s s1 ). Hitung galat δ = z*( s ) z*( ˆ s ) dan galat standar δ ε =. Prosedur yang sama dilakukan untuk menghitung galat yang σ ( s ) K lainnya. Untuk lokasi sampel ke-i, estimasi nilai ẑ*( si) 1) data pertama, lalu hitung nilai galat dan galat standar δ dengan menggunakan (i- δ = z*( s ) z*( s ) dan ˆ i i i ε i =, untuk i = 1,,..., 31. Maka didapatkan nilai galat dan galat standar σ K( s i) seperti pada tabel berikut i 33
12 Tabel III.8 Galat dan galat standar ẑ* ˆσ K ε= (z*- ˆ z*) ˆ σ K no z* ẑ* z* ε m 1 Selanjutnya hitung statistik Q1 = εi dan m 1 i = 1 m Q1 = εi m 1 i =, dalam hal ini m = 31. Uji validasi dapat didasarkan pada atatistik Q 1 ataupun Q. Dari tabel di atas, kita peroleh nilai Q 1 = dan Q = Model semivariogram akan ditolak jika Q 1 > = = Dengan demikian, jika Q 1 yang m 1 30 digunakan sebagai statistik uji, model semivariogram tidak ditolak. Jika yang digunakan sebagai statistik uji adalah Q, model semivariogram ditolak jika Q > U atau Q < L, dengan nilai U dan L dapat dilihat pada tabel di lampiran H. Untuk 34
13 m = 30, didapatkan L = 0.56 dan U=1.57. Dengan demikian, jika Q yang digunakan sebagai statistik uji, model semivariogram juga tidak ditolak. Berdasarkan hasil uji validasi silang, model semivariogram dapat digunakan untuk memodelkan struktur dependensi data. Jadi hipotesis bahwa z* merupakan realisasi dari proses spasial intrinsik dengan semivariogram γ ( h persamaan 3. tidak ditolak. ) seperti pada III.4 Tinjauan Model Semivariogram Sekarang akan ditinjau sifat-sifat model semivariogram yang diperoleh pada persamaan 3.. Perhatikan bahwa h 1 1 x ( ) = = lim u lim F h lim exp dx = 1. h h h π Maka, ( ( )) ( h ) ( h ) ( ) lim γ = lim γ = lim ln u h u 1 u 1 = Dengan demikian, model semivariogram tersebut terbatas di atas. Menurut Armstrong (1998), model semivariogram yang terbatas di atas adalah model semivariogram dari proses spasial yang stasioner. Maka proses spasial {Z*(s), s D} bisa dianggap merupakan proses yang stasioner Karena ( h ) lim γ = , model semivariogram tersebut dikatakan h memiliki sill sebesar Sill merupakan batas atas bagi semivariogram. Berdasarkan persamaan.4, pada proses stasioner, sill adalah kovariogram pada h = 0 atau berlaku juga C(0). Dengan kata lain, sill adalah variansi dari Z*. Selain itu + h 0 ( h ) lim γ = 0.003, berarti terdapat nugget effect pada model semivariogram. Nugget effect mengindikasikan adanya ketidak kontinuan peubah acak regional, di mana Z *( s) dapat berbeda dengan Z *( s ') berapapun kecilnya jarak h = s s '. Nilai kovariogram turun dari pada h = 0 menjadi ketika h bergeser sedikit lebih besar dari 0. Nilai korelogram turun dari 35
14 1 pada h = 0 menjadi ketika nilai h bergeser sedikit lebih besar dari 0. Ini berarti korelasi antara Z *( s) dan Z *( s ') sudah cukup kecil walaupun lokasi s dan s berdekatan. Pada h = m, nilai semivariogram adalah yang merupakan 95% dari nilai sill. Pada jarak ini, nilai korelogram adalah Nilai korelogram pada h yang lebih besar dari lebih kecil dari karena korelogram adalah fungsi turun terhadap h. Maka dapat disimpulkan bahwa korelasi spasial antara dua lokasi sumur dengan jarak pisah ( h ) yang lebih besar atau sama dengan sudah sangat kecil. Jarak h = m ini disebut practical range. III.5 Penaksiran dengan Ordinary Kriging Setelah diperoleh model semivariogram, dilanjutkan dengan estimasi kriging pada sumur yang dekat dengan lokasi pengeboran, yaitu sumur yang lokasinya di koordinat x dan 1175 y 365. Berikut adalah lokasi yang diestimasi Utara-Selatan koordinat sumur lokasi yang ditaksir KMJ 40 KMJ 36 KMJ 51 KMJ 44 KMJ 46 KMJ 6 KMJ 30 KMJ 7 KMJ 35 KMJ 4 KMJ 6 KMJ 41 KMJ KMJ 37 KMJ 8 KMJ 5 KMJ 31 KMJ KMJ 39 KMJ 5 KMJ 43 KMJ 11 KMJ 14 KMJ KMJ 17 KMJ 0 KMJ KMJ 34 KMJ 33 KMJ 45 KMJ Barat-Timur Gambar III.9. Lokasi sumur beserta lokasi yang diestimasi 36
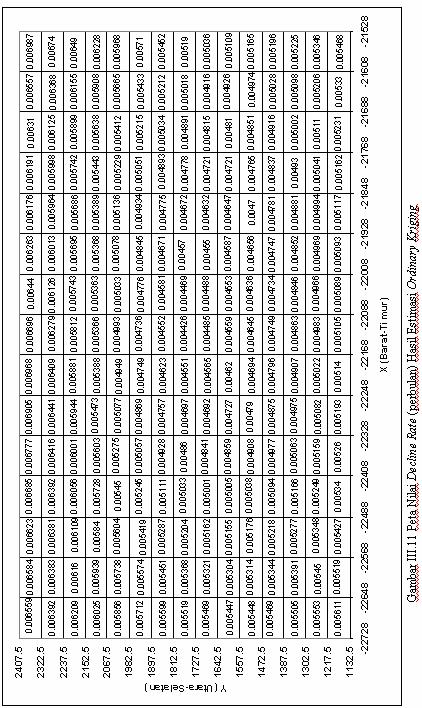
15 Utara-Selatan Lokasi yang Diestimasi Barat-Timur Gambar III.10. Penomoran kokasi yang diestimasi Banyaknya titik yang akan diestimasi adalah 5 titik. Penaksiran dilakukan dengan menggunakan ordinary kriging pada lokasi yang diestimasi untuk menaksir nilai Z*. Dari taksiran nilai Z* dapat diperoleh nilai taksiran decline rate ( Z( s) ) dilokasi tersebut dengan menggunakan persamaan.18 dan simpangan baku krigingnya dapat dihitung dengan menggunakan persamaan.19. Tabel nilai data hasil estimasi ordinary kriging dapat dilihat pada lampiran E. Pada halaman berikut akan ditampilkan peta hasil estimasi decline rate Z( s) dengan menggunakan ordinary kriging pada lokasi-lokasi yang diestimasi yang digambarkan dalam 5 grid. 37
16 38
17 Berikut ini adalah peta kontur nilai decline rate hasil estimasi ordinary kriging beserta peta kontur simpangan baku krigingnya x 10 4 Gambar III.1. Peta kontur nilai decline rate (perbulan) hasil estimasi ordinary kriging x 10 4 Gambar III.13. Peta kontur simpangan baku kriging hasil estimasi ordinary kriging 39
18 Berdasarkan peta nilai decline rate hasil estimasi maupun peta kontur terlihat bahwa nilai decline rate yang terendah berada pada koordinat.168 x dan 1685 y 1770 (di sekitar pusat daerah yang diestimasi). Nilai taksiran decline rate di daerah ini yaitu adalah sekitar /bulan. Semakin jauh titik estimasi dari pusat daerah yang diestimasi, semakin besar nilai taksiran decline rate di titik tersebut. Hasil kriging mean menunjukkan taksiran mean dari decline rate adalah /bulan. Selain itu, peta kontur simpangan baku kriging menunjukkan bahwa semakin jauh lokasi yang diestimasi dari lokasi sumur (lokasi sampel), semakin besar nilai simpangan baku kriging di lokasi itu. Hal ini menunjukkan bahwa semakin jauh lokasi yang diestimasi dari lokasi sampel, tingkat ketakpastian dalam penaksiran semakin tinggi. III.6 Penaksiran dengan Sequential Kriging Sebelum melakukan sequential kriging, data sampel terlebih dahulu diurutkan berdasarkan jarak lokasi sumur (lokasi observasi) terhadap tehadap titik yang akan diestimasi, sehingga akan terdapat sampel dengan urutan yang berbeda-beda untuk setiap titik yang akan diestimasi. Alasan pengurutan ini adalah karena lokasi observasi yang berada dekat dengan lokasi yang akan diestimasi mempunyai korelasi yang lebih tinggi dengan lokasi estimasi dibandingkan dengan lokasi observasi yang jauh dari lokasi estimasi tersebut. Artinya titik lokasi observasi yang berada jauh dari lokasi estimasi memberi pengaruh yang relatif kecil terhadap nilai decline rate di titik yang akan diestimasi. Titik-titik lokasi observasi yang jauh dari titik estimasi dan pengaruhnya kecil dapat disisihkan sehingga tidak diikutsertakan dalam estimasi. Lokasi estimasi masih sama dengan lokasi estimasi sebelumnya. Data sampel dibagi ke dalam 31 subset sehingga setiap subset merupakan datum tunggal. Berdasarkan persamaan.4 sequential kriging dilakukan untuk mengestimasi Z *( s 0 ) dalam 31 langkah sebagai berikut: 40
19 (1) ( s ) = ρ Z ( s ) Zˆ * * () (1) ( ) ( ) ( ) ( ) () 1 s = s + θ s s Zˆ* Zˆ* ( Z* Zˆ* ) 0 0 (3) () ( ) ( ) ( ) ( ) ( s = s + θ s s ) Zˆ* Zˆ* ( Z* Zˆ* ) ( s ) = ( s ) + θ ( s ) ( s ) Zˆ* Zˆ* ( Z* Zˆ* (30) (9) (9) ( s ) = ( s ) + θ ( s ) ( s ) Zˆ* Zˆ* ( Z* Zˆ* (31) (30) (30) ) ) (3.3).dengan jarak s s s s s s n, ( ) ( 1) k Z ˆ * s adalah estimasi Z *( s 0 ) dengan menggunakan (k-1) data, Z *( s i ) adalah data observasi dari lokasi sampel terdekat ke-i dari titik yang akan diestimasi, merupakan selisih antara nilai data terdekat ke-i dengan estimasi data ke-i 0 ( ) ( ) ( k s Zˆ s 1) ( Z* * ) menggunakan (k-1) data, dan θ i adalah bobot sequential kriging dari data subset ke-i. Bobot sequential kriging adalah : i i 1 θ = ( ρ ρ ρ ) ρ1 1 θ = ( ρ ρ ρ θ ( ρ ρ ρ )) ρ13 1 θ = ( ρ ρ ρ θ ( ρ ρ ρ ) θ ( ρ ρ ρ )) ρ14 1 θ = ( ρ ρ ρ θ ( ρ ρ ρ ) θ ( ρ ρ ρ ) θ ( ρ ρ ρ )) ρ15 k 1 1 θk = ρ 0k ρ01ρ1 k ρ θm( ρmk ρ mρ k) 1k m= 30 1 θ31 = 0, ,31 (,31 1 1,31) 1 ρ ρ ρ θm ρm ρ mρ ρ 1,31 m= (3.4) Kompleksitas komputasi sequential kriging jauh lebih kecil daripada kompleksitas komputasi ordinary kriging. Pada ordinary kriging, untuk menyelesaikan 41
20 persamaan.17 dengan metode eliminasi Gauss-Jordan diperlukan operasi tambah n+ 1 + n+ 1 n+ 1) dan operasi perkalian sebanyak sebanyak ( ) ( ) ( ( n + 1 ) + ( n + 1 ) ( n + 1 ), dengan n adalah ukuran sampel. Sehingga total 3 3 banyaknya operasi yang dilakukan dalam ordinary kriging adalah ( n+ 1) + ( n+ 1) ( n+ 1) operasi. Dalam kasus ini n sama dengan 31, 3 6 sehingga total banyaknya operasi pada jika menggunakan ordinary kriging adalah 3344 operasi. Sedangkan dalam sequential kriging, diperlukan sebanyak 1 1 n + n operasi perkalian dan sebanyak 1 1 n + n 1 operasi tambah pada persamaan 3.3, dan sebanyak n + n operasi perkalian serta sebanyak n n operasi tambah pada persamaan 3.4. Sehingga total banyaknya operasi pada agoritma sequential kriging adalah 3n + n 3 operasi. Untuk n = 31, total banyaknya operasi jika menggunakan sequential kriging adalah 911 operasi. Jadi, banyaknya operasi pada algoritma metode sequential kriging lebih sedikit dari banyaknya operasi pada algoritma ordinary kriging, sehingga kompleksitas komputasinya lebih kecil. Setelah diperoleh taksiran nilai Z * dengan sequential kriging, nilai taksiran decline rate ( Z ) dapat dihitung dengan menggunakan persamaan.37 dan standar deviasi krigingnya dapat dihitung dengan menggunakan persamaan.38. Nilai estimasi decline rate hasil estimasi sequential kriging dapat dilihat pada lampiran F. Pada halaman berikut akan ditampilkan peta hasil estimasi decline rate (ẑ) pada lokasi-lokasi yang diestimasi yang digambarkan dalam 5 grid. 4

21 43
22 Berikut ini adalah peta kontur hasil nilai decline rate hasil estimasi sequential kriging beserta peta kontur simpangan baku krigingnya x 10 4 Gambar III.15. Peta kontur nilai decline rate (perbulan) hasil estimasi sequential kriging x 10 4 Gambar III.16. Peta kontur simpangan baku kriging hasil estimasi sequential kriging 44
23 Berdasarkan gambar-gambar di atas, terlihat bahwa hasil estimasi dengan menggunakan sequential kriging tidak jauh berbeda dengan hasil estimasi dengan menggunakan ordinary kriging. Demikian juga kontur simpangan baku krigingnya menunjukkan pola yang sama yaitu semakin jauh lokasi yang diestimasi dari lokasi sumur (lokasi sampel), semakin besar nilai simpangan baku kriging di lokasi itu. Namun, penggunaan sequential kriging untuk mengestimasi nilai decline rate lebih menguntungkan karena kompleksitas komputasinya lebih kecil sehingga akan menghemat komputasi. Kompleksitas komputasi sequential kriging masih dapat dikurangi lagi. Sebagai ilustrasi, tinjau lokasi estimasi ke-136 di koordinat x = -1968, y = Nilai estimasi decline rate di titik tersebut dengan menggunakan ordinary kriging adalah 093/bulan, sedangkan jika menggunakan sequential kriging diperoleh nilai taksiran sebesar 0499/bulan yang tidak jauh berbeda dengan hasil ordinary kriging. Selanjutnya perhatikan gambar berikut bobot sequential kriging data subset Gambar III.17. Bobot sequential kriging subset data untuk titik estimasi dengan koordinat x = -1968, y = 1175 Dari gambar di atas, terlihat bahwa pada titik estimasi dengan koordinat x = dan y = 1175, bobot sequential kriging subset data pada taksiran nilai 45
24 Z* di titik tersebut cenderung semakin mendekati nol seiring dengan semakin besarnya indeks subset. Hal ini berarti data observasi yang lokasinya jauh dari titik yang diestimasi nilai bobotnya mendekati nol sehingga dapat diabaikan. Hal ini pun berlaku pada seluruh 5 titik estimasi. Sekarang tinjau gambar berikut Nilai taksiran Z*(s0) Iterasi Gambar III.18. Taksiran nilai Z* di titik estimasi dengan koordinat x = -1968, y = 1175 dengan menggunakan sequential kriging dalam 31 iterasi Gambar di atas adalah gambar taksiran sequential kriging dari nilai Z* di titik dengan koordinat x = dan y = 1175 dalam 31 iterasi. Terlihat bahwa mulai iterasi ke-15, taksiran nilai Z* sudah mulai stabil di sekitar suatu nilai tertentu. Hal ini pun berlaku pada seluruh 5 titik estimasi di mana taksiran nilai Z* mulai stabil setelah iterasi tertentu. Mengingat pada sequential kriging ini data observasi diurutkan berdasarkan jaraknya dari titik estimasi, maka kestabilan nilai taksiran Z* setelah iterasi tertentu disebabkan oleh kecilnya bobot data observasi yang lokasinya jauh dari titik estimasi. Hal ini sesuai dengan ilustrasi pada gambar III.17. Oleh karena itu kita bisa melakukan pemotongan iterasi pada algoritma sequential kriging, di mana ketika taksiran nilai Z* sudah mulai stabil di sekitar nilai tertentu iterasi akan dihentikan. Dengan demikian, data observasi yang 46
25 bobotnya kecil tidak diikutsertakan. Hal ini akan lebih mengurangi banyaknya operasi dalam sequential kriging. Sekarang akan dilakukan sequential kriging dengan pemotongan iterasi untuk menaksir nilai decline rate masih di lokasi estimasi yang sama seperti sebelumnya. Pada kasus ini, untuk setiap titik estimasi, iterasi dihentikan jika z*(s ˆ ) z*(s ˆ ) < 1 10 (i), dengan ẑ*(s ) adalah taksiran nilai Z* pada (i) (i 1) iterasi ke-i, dan yang diambil sebagai taksiran nilai Z* di titik tersebut adalah ẑ*(s ) 0 (i). Berikut adalah peta kontur hasil estimasi sequential kriging dengan pemotongan iterasi x 10 4 Gambar III.19. Peta kontur taksiran nilai decline rate menggunakan sequential kriging dengan pemotongan iterasi 47
26 x 10 4 Gambar III.0. Peta Kontur Taksiran Simpangan Baku Kriging Menggunakan Sequential Kriging dengan Pemotongan Iterasi Dari gambar III.19 terlihat bahwa peta kontur taksiran nilai decline rate menggunakan sequential kriging dengan pemotongan iterasi tidak berbeda secara signifikan dengan peta kontur nilai decline rate menggunakan sequential kriging yang biasa. Demikian juga dengan peta kontur simpangan baku krigingnya. Dengan demikian, kita dapat menggunakan sequential kriging dengan pemotongan iterasi karena hasilnya tidak jauh berbeda dan kompleksitas komputasinya lebih kecil. 48
BAB IV ANALISIS DATA. Data yang digunakan dalam tugas akhir ini adalah data eksplorasi
 BAB IV ANALISIS DATA 4. DATA Data yang digunakan dalam tugas akhir ini adalah data eksplorasi kandungan cadangan bauksit di daerah penambangan bauksit di Mempawah pada blok AIII-h5 sebanyak 8 titik eksplorasi.
BAB IV ANALISIS DATA 4. DATA Data yang digunakan dalam tugas akhir ini adalah data eksplorasi kandungan cadangan bauksit di daerah penambangan bauksit di Mempawah pada blok AIII-h5 sebanyak 8 titik eksplorasi.
MODEL SEMIVARIOGRAM KOPULA DAN REDUKSI KOMPUTASI PADA ALGORITMA SEQUENTIAL KRIGING TESIS. RIAN FEBRIAN UMBARA NIM : Program Studi Matematika
 MODEL SEMIVARIOGRAM KOPULA DAN REDUKSI KOMPUTASI PADA ALGORITMA SEQUENTIAL KRIGING TESIS Karya tulis sebagai salah satu syarat untuk memperoleh gelar Magister dari Institut Teknologi Bandung Oleh RIAN
MODEL SEMIVARIOGRAM KOPULA DAN REDUKSI KOMPUTASI PADA ALGORITMA SEQUENTIAL KRIGING TESIS Karya tulis sebagai salah satu syarat untuk memperoleh gelar Magister dari Institut Teknologi Bandung Oleh RIAN
GEOSTATISTIK MINERAL MATTER BATUBARA PADA TAMBANG AIR LAYA
 GEOSTATISTIK MINERAL MATTER BATUBARA PADA TAMBANG AIR LAYA 1 Surya Amami P a, Masagus Ahmad Azizi b a Program Studi Pendidikan Matematika FKIP UNSWAGATI Jl. Perjuangan No 1 Cirebon, amamisurya@gmail.com
GEOSTATISTIK MINERAL MATTER BATUBARA PADA TAMBANG AIR LAYA 1 Surya Amami P a, Masagus Ahmad Azizi b a Program Studi Pendidikan Matematika FKIP UNSWAGATI Jl. Perjuangan No 1 Cirebon, amamisurya@gmail.com
Kajian Pemilihan Model Semivariogram Terbaik Pada Data Spatial (Studi Kasus : Data Ketebalan Batubara Pada Lapangan Eksplorasi X)
") Jurnal Gradien Vol 8 No Januari 0: 756-76 Kajian Pemilihan Semivariogram Terbaik Pada Data Spatial (Studi Kasus : Data Ketebalan Batubara Pada Lapangan Eksplorasi X) Fachri Faisal dan Jose Rizal Jurusan
Jurnal Gradien Vol 8 No Januari 0: 756-76 Kajian Pemilihan Semivariogram Terbaik Pada Data Spatial (Studi Kasus : Data Ketebalan Batubara Pada Lapangan Eksplorasi X) Fachri Faisal dan Jose Rizal Jurusan
BAB III PEMBAHASAN. Metode kriging digunakan oleh G. Matheron pada tahun 1960-an, untuk
 BAB III PEMBAHASAN 3.1. Kriging Metode kriging digunakan oleh G. Matheron pada tahun 1960-an, untuk menonjolkan metode khusus dalam moving average terbobot (weighted moving average) yang meminimalkan variansi
BAB III PEMBAHASAN 3.1. Kriging Metode kriging digunakan oleh G. Matheron pada tahun 1960-an, untuk menonjolkan metode khusus dalam moving average terbobot (weighted moving average) yang meminimalkan variansi
BAB III SIMULASI PENGGUNAAN PERTIDAKSAMAAN PADA DISTRIBUSI
 BAB III SIMULASI PENGGUNAAN PERTIDAKSAMAAN PADA DISTRIBUSI 3.1 Pendahuluan Pada bab sebelumnya telah dibahas mengenai pertidaksamaan Chernoff dengan terlebih dahulu diberi pemaparan mengenai dua pertidaksamaan
BAB III SIMULASI PENGGUNAAN PERTIDAKSAMAAN PADA DISTRIBUSI 3.1 Pendahuluan Pada bab sebelumnya telah dibahas mengenai pertidaksamaan Chernoff dengan terlebih dahulu diberi pemaparan mengenai dua pertidaksamaan
Metode Ordinary Kriging Blok pada Penaksiran Ketebalan Cadangan Batubara (Studi Kasus : Data Ketebalan Batubara pada Lapangan Eksplorasi X)
") Kumpulan Makalah Seminar Semirata 2013 Fakultas MIPA Universitas Lampung Metode Ordinary Kriging Blok pada Penaksiran Ketebalan Cadangan Batubara (Studi Kasus : Data Ketebalan Batubara pada Lapangan Eksplorasi
Kumpulan Makalah Seminar Semirata 2013 Fakultas MIPA Universitas Lampung Metode Ordinary Kriging Blok pada Penaksiran Ketebalan Cadangan Batubara (Studi Kasus : Data Ketebalan Batubara pada Lapangan Eksplorasi
Bab IV Analisis Statistik dan Distribusi Lubang Bor
 Bab IV Analisis Statistik dan Distribusi Lubang Bor 4.1. Analisis Statistik Analisis statistik dan geostatistik dalam penelitian ini hanya dilakukan pada saprolit dan limonit dari profil nikel laterit.
Bab IV Analisis Statistik dan Distribusi Lubang Bor 4.1. Analisis Statistik Analisis statistik dan geostatistik dalam penelitian ini hanya dilakukan pada saprolit dan limonit dari profil nikel laterit.
MA5283 STATISTIKA Bab 7 Analisis Regresi
 MA5283 STATISTIKA Bab 7 Analisis Regresi Orang Cerdas Belajar Statistika Silabus Silabus dan Tujuan Perkuliahan Silabus Tujuan Peubah bebas dan terikat, konsep relation, model regresi linier, penaksir
MA5283 STATISTIKA Bab 7 Analisis Regresi Orang Cerdas Belajar Statistika Silabus Silabus dan Tujuan Perkuliahan Silabus Tujuan Peubah bebas dan terikat, konsep relation, model regresi linier, penaksir
ANALISIS DATA GEOSTATISTIK MENGGUNAKAN METODE ORDINARY KRIGING
 ANALISIS DATA GEOSTATISTIK MENGGUNAKAN METODE ORDINARY KRIGING Oleh: Wira Puspita (1) Dewi Rachmatin (2) Maman Suherman (2) ABSTRAK Geostatistika merupakan suatu jembatan antara statistika dan Geographic
ANALISIS DATA GEOSTATISTIK MENGGUNAKAN METODE ORDINARY KRIGING Oleh: Wira Puspita (1) Dewi Rachmatin (2) Maman Suherman (2) ABSTRAK Geostatistika merupakan suatu jembatan antara statistika dan Geographic
Statistik Deskriptif dengan Microsoft Office Excel
 Statistik Deskriptif dengan Microsoft Office Excel Junaidi, Junaidi I. Prosedur Statistik Deskriptif pada Excel Statistik deskriptif adalah statistik yang bertujuan untuk mendeskripsikan atau menggambarkan
Statistik Deskriptif dengan Microsoft Office Excel Junaidi, Junaidi I. Prosedur Statistik Deskriptif pada Excel Statistik deskriptif adalah statistik yang bertujuan untuk mendeskripsikan atau menggambarkan
Estimasi Produksi Minyak dan Gas Bumi di Kalimantan Utara Menggunakan Metode Cokriging
 D-426 JURNAL SAINS DAN SENI ITS Vol. 5 No. 2 (2016) 2337-3520 (2301-928X Print) Estimasi Produksi Minyak dan Gas Bumi di Kalimantan Utara Menggunakan Metode Cokriging Eka Oktaviana Romaji, I Nyoman Latra,
D-426 JURNAL SAINS DAN SENI ITS Vol. 5 No. 2 (2016) 2337-3520 (2301-928X Print) Estimasi Produksi Minyak dan Gas Bumi di Kalimantan Utara Menggunakan Metode Cokriging Eka Oktaviana Romaji, I Nyoman Latra,
BAB IV PEMBAHASAN. Gambar 4.1 nilai tukar kurs euro terhadap rupiah
 BAB IV PEMBAHASAN 4.1 Deskripsi Data Gambar 4.1 memperlihatkan bahwa data berfluktuasi dari waktu ke waktu. Hal ini mengindikasikan bahwa data tidak stasioner baik dalam rata-rata maupun variansi. Gambar
BAB IV PEMBAHASAN 4.1 Deskripsi Data Gambar 4.1 memperlihatkan bahwa data berfluktuasi dari waktu ke waktu. Hal ini mengindikasikan bahwa data tidak stasioner baik dalam rata-rata maupun variansi. Gambar
BAB III METODE PENELITIAN
 BAB III METODE PENELITIAN 3.1 Variabel Penelitian Penelitian ini menggunakan satu definisi variabel operasional yaitu ratarata temperatur bumi periode tahun 1880 sampai dengan tahun 2012. 3.2 Jenis dan
BAB III METODE PENELITIAN 3.1 Variabel Penelitian Penelitian ini menggunakan satu definisi variabel operasional yaitu ratarata temperatur bumi periode tahun 1880 sampai dengan tahun 2012. 3.2 Jenis dan
MA5182 Topik dalam Statistika I: Statistika Spasial. Utriweni Mukhaiyar
 Review 1: Statistika Deskriptif MA5182 Topik dalam Statistika I: Statistika Spasial 28 Agustus 2012 28 Agustus 2012 Utriweni Mukhaiyar Ilustrasi Berikut adalah data rata-rata curah hujan bulanan yang diamati
Review 1: Statistika Deskriptif MA5182 Topik dalam Statistika I: Statistika Spasial 28 Agustus 2012 28 Agustus 2012 Utriweni Mukhaiyar Ilustrasi Berikut adalah data rata-rata curah hujan bulanan yang diamati
BAB 2 LANDASAN TEORI. Ramalan pada dasarnya merupakan perkiraan mengenai terjadinya suatu yang akan
 BAB 2 LANDASAN TEORI 2.1 Pengertian Peramalan Ramalan pada dasarnya merupakan perkiraan mengenai terjadinya suatu yang akan datang. Peramalan adalah proses untuk memperkirakan kebutuhan di masa datang
BAB 2 LANDASAN TEORI 2.1 Pengertian Peramalan Ramalan pada dasarnya merupakan perkiraan mengenai terjadinya suatu yang akan datang. Peramalan adalah proses untuk memperkirakan kebutuhan di masa datang
Estimasi Parameter Copula Dan Aplikasinya Pada Klimatologi
 Estimasi Parameter Copula Dan Aplikasinya Pada Klimatologi Irwan Syahrir (309 20 00) Dosen Pembimbing: Dr. Ismaini Zaini, M.Si Dr.rer.pol. Heri Kuswanto, M.Si . PENDAHULUAN Latar belakang Analisis Statistik
Estimasi Parameter Copula Dan Aplikasinya Pada Klimatologi Irwan Syahrir (309 20 00) Dosen Pembimbing: Dr. Ismaini Zaini, M.Si Dr.rer.pol. Heri Kuswanto, M.Si . PENDAHULUAN Latar belakang Analisis Statistik
S - 4 IDENTIFIKASI DATA RATA-RATA CURAH HUJAN PER-JAM DI BEBERAPA LOKASI
 S - 4 IDENTIFIKASI DATA RATA-RATA CURAH HUJAN PER-JAM DI BEBERAPA LOKASI Astutik, S., Solimun, Widandi, Program Studi Statistika, Jurusan Matematika FMIPA, Universitas Brawiaya, Malang, Jurusan Teknik
S - 4 IDENTIFIKASI DATA RATA-RATA CURAH HUJAN PER-JAM DI BEBERAPA LOKASI Astutik, S., Solimun, Widandi, Program Studi Statistika, Jurusan Matematika FMIPA, Universitas Brawiaya, Malang, Jurusan Teknik
PENAKSIRAN KANDUNGAN CADANGAN BAUKSIT DI DAERAH MEMPAWAH MENGGUNAKAN ORDINARY KRIGING DENGAN SEMIVARIOGRAM ANISOTROPIK PUTU JAYA ADNYANA WIDHITA
 PENAKSIRAN KANDUNGAN CADANGAN BAUKSIT DI DAERAH MEMPAWAH MENGGUNAKAN ORDINARY KRIGING DENGAN SEMIVARIOGRAM ANISOTROPIK PUTU JAYA ADNYANA WIDHITA 0 3 0 3 0 1 0 3 0 3 UNIVERSITAS INDONESIA FAKULTAS MATEMATIKA
PENAKSIRAN KANDUNGAN CADANGAN BAUKSIT DI DAERAH MEMPAWAH MENGGUNAKAN ORDINARY KRIGING DENGAN SEMIVARIOGRAM ANISOTROPIK PUTU JAYA ADNYANA WIDHITA 0 3 0 3 0 1 0 3 0 3 UNIVERSITAS INDONESIA FAKULTAS MATEMATIKA
PENGANTAR & STATISTIKA DESKRIPTIF. Utriweni Mukhaiyar
 PENGANTAR & STATISTIKA DESKRIPTIF BI5106 Analisis Biostatistik Utriweni Mukhaiyar 2 Ilustrasi Berikut adalah data produksi panas bumi di 25 titik pengeboran (ton/jam): 77.71 44.24 60.00 89.54 85.64 60.00
PENGANTAR & STATISTIKA DESKRIPTIF BI5106 Analisis Biostatistik Utriweni Mukhaiyar 2 Ilustrasi Berikut adalah data produksi panas bumi di 25 titik pengeboran (ton/jam): 77.71 44.24 60.00 89.54 85.64 60.00
BAB III REGRESI TERSENSOR (TOBIT) Model regresi yang didasarkan pada variabel terikat tersensor disebut
 Model regresi yang didasarkan pada variabel terikat tersensor disebut") BAB III REGRESI TERSENSOR (TOBIT) 3.1 Model Regresi Tersensor (Tobit) Model regresi yang didasarkan pada variabel terikat tersensor disebut model regresi tersensor (tobit). Untuk variabel terikat yang
BAB III REGRESI TERSENSOR (TOBIT) 3.1 Model Regresi Tersensor (Tobit) Model regresi yang didasarkan pada variabel terikat tersensor disebut model regresi tersensor (tobit). Untuk variabel terikat yang
BAB II TINJAUAN PUSTAKA. level, model regresi tiga level, penduga koefisien korelasi intraclass, pendugaan
 6 BAB II TINJAUAN PUSTAKA Pada Bab II akan dibahas konsep-konsep yang menjadi dasar dalam penelitian ini yaitu analisis regresi, analisis regresi multilevel, model regresi dua level, model regresi tiga
6 BAB II TINJAUAN PUSTAKA Pada Bab II akan dibahas konsep-konsep yang menjadi dasar dalam penelitian ini yaitu analisis regresi, analisis regresi multilevel, model regresi dua level, model regresi tiga
Statistik dan Statistika Populasi dan Sampel Jenis-jenis Observasi Statistika Deskriptif
 1. 2 2. 3. 4. Statistik dan Statistika Populasi dan Sampel Jenis-jenis Observasi Statistika Deskriptif Sari Numerik Penyajian Data 2008 by USP & UM ; last edited Jan 11 MA 2081 Statistika Dasar 24 Januari
1. 2 2. 3. 4. Statistik dan Statistika Populasi dan Sampel Jenis-jenis Observasi Statistika Deskriptif Sari Numerik Penyajian Data 2008 by USP & UM ; last edited Jan 11 MA 2081 Statistika Dasar 24 Januari
BAB 1 PENDAHULUAN 1.1 LATAR BELAKANG
 BAB 1 PENDAHULUAN 1.1 LATAR BELAKANG Indonesia merupakan negara terluas didunia dengan total luas negara 5.193.250km 2 (mencakup daratan dan lautan). Hal ini menempatkan Indonesia sebagai negara terluas
BAB 1 PENDAHULUAN 1.1 LATAR BELAKANG Indonesia merupakan negara terluas didunia dengan total luas negara 5.193.250km 2 (mencakup daratan dan lautan). Hal ini menempatkan Indonesia sebagai negara terluas
BAB III PEMBAHARUAN PERAMALAN. Pada bab ini akan dibahas tentang proses pembaharuan peramalan.
 BAB III PEMBAHARUAN PERAMALAN Pada bab ini akan dibahas tentang proses pembaharuan peramalan. Sebelum dilakukan proses pembaharuan peramalan, terlebih dahulu dilakukan proses peramalan dan uji kestabilitasan
BAB III PEMBAHARUAN PERAMALAN Pada bab ini akan dibahas tentang proses pembaharuan peramalan. Sebelum dilakukan proses pembaharuan peramalan, terlebih dahulu dilakukan proses peramalan dan uji kestabilitasan
BAB 2 LANDASAN TEORI
 BAB 2 LANDASAN TEORI 2.1 Regresi Linier Sederhana Dalam beberapa masalah terdapat dua atau lebih variabel yang hubungannya tidak dapat dipisahkan karena perubahan nilai suatu variabel tidak selalu terjadi
BAB 2 LANDASAN TEORI 2.1 Regresi Linier Sederhana Dalam beberapa masalah terdapat dua atau lebih variabel yang hubungannya tidak dapat dipisahkan karena perubahan nilai suatu variabel tidak selalu terjadi
PENGGUNAAN ALGORITMA BOOTSTRAP UNTUK PENENTU SELANG KADAR EMAS DAN PERAK PADA LOKASI PENGGALIAN DENGAN METODE SIMPLE KRIGING
 PENGGUNAAN ALGORITMA BOOTSTRAP UNTUK PENENTU SELANG KADAR EMAS DAN PERAK PADA LOKASI PENGGALIAN DENGAN METODE SIMPLE KRIGING Siti Rahmah Madusari 1, Sri Suryani,S.Si.,M.Si. 2, Rian Febrian Umbara,S.Si.,M.Si.
PENGGUNAAN ALGORITMA BOOTSTRAP UNTUK PENENTU SELANG KADAR EMAS DAN PERAK PADA LOKASI PENGGALIAN DENGAN METODE SIMPLE KRIGING Siti Rahmah Madusari 1, Sri Suryani,S.Si.,M.Si. 2, Rian Febrian Umbara,S.Si.,M.Si.
PENGGUNAAN ALGORITMA BOOTSTRAP UNTUK PENENTU SELANG KADAR EMAS DAN PERAK PADA LOKASI PENGGALIAN DENGAN METODE SIMPLE KRIGING
 ISSN : 2355-9365 e-proceeding of Engineering : Vol.2, No.2 Agustus 2015 Page 6862 PENGGUNAAN ALGORITMA BOOTSTRAP UNTUK PENENTU SELANG KADAR EMAS DAN PERAK PADA LOKASI PENGGALIAN DENGAN METODE SIMPLE KRIGING
ISSN : 2355-9365 e-proceeding of Engineering : Vol.2, No.2 Agustus 2015 Page 6862 PENGGUNAAN ALGORITMA BOOTSTRAP UNTUK PENENTU SELANG KADAR EMAS DAN PERAK PADA LOKASI PENGGALIAN DENGAN METODE SIMPLE KRIGING
BAB 1 PENDAHULUAN 1.1 Latar Belakang
 xiii BAB 1 PENDAHULUAN 1.1 Latar Belakang Indonesia memiliki kekayaan alam yang luar biasa dalam hal bahan-bahan tambang seperti emas, batubara, nikel gas bumi dan lain lain. Batubara merupakan salah satu
xiii BAB 1 PENDAHULUAN 1.1 Latar Belakang Indonesia memiliki kekayaan alam yang luar biasa dalam hal bahan-bahan tambang seperti emas, batubara, nikel gas bumi dan lain lain. Batubara merupakan salah satu
PERTEMUAN 2 STATISTIKA DASAR MAT 130
 PERTEMUAN 2 STATISTIKA DASAR MAT 130 Data 1. Besaran Statistika berbicara tentang data dalam bentuk besaran (dimensi) Besaran adalah sesuatu yang dapat dipaparkan secara jelas dan pada prinsipnya dapat
PERTEMUAN 2 STATISTIKA DASAR MAT 130 Data 1. Besaran Statistika berbicara tentang data dalam bentuk besaran (dimensi) Besaran adalah sesuatu yang dapat dipaparkan secara jelas dan pada prinsipnya dapat
DAN ANALISIS DATA. Sari Numerik. MA 2181 Analisis Data 8 Agustus 2011 Utriweni Mukhaiyar. 1. Statistik dan Statistika. 2. Populasi dan Sampel
 PENGANTAR STATISIK DAN ANALISIS DATA 1. Statistik dan Statistika 2. Populasi dan Sampel 3. Jenis-jenis Observasi 4. STATISTIKA DESKRIPTIF Sari Numerik Penyajian Data MA 2181 Analisis Data 8 Agustus 2011
PENGANTAR STATISIK DAN ANALISIS DATA 1. Statistik dan Statistika 2. Populasi dan Sampel 3. Jenis-jenis Observasi 4. STATISTIKA DESKRIPTIF Sari Numerik Penyajian Data MA 2181 Analisis Data 8 Agustus 2011
terhadap kesehatan persalinan. Sehingga tak heran jika negara-negara maju di
 Nama: Ummi Fadilah NIM: 12/339683/PPA/3995 Teori Resiko Aktuaria PROSES PEMODELAN PENDAHULUAN Salah satu ciri dari negara maju adalah pemerintah dan masyarakat yang peduli terhadap kesehatan persalinan.
Nama: Ummi Fadilah NIM: 12/339683/PPA/3995 Teori Resiko Aktuaria PROSES PEMODELAN PENDAHULUAN Salah satu ciri dari negara maju adalah pemerintah dan masyarakat yang peduli terhadap kesehatan persalinan.
Prediksi Curah Hujan dengan Model Deret Waktu dan Prakiraan Krigging pada 12 Stasiun di Bogor Periode Januari Desember 2014.
 Jur. Ris. & Apl. Mat. Vol. 1 (2017), no. 1, 1-52 Jurnal Riset dan Aplikasi Matematika e-issn: 2581-0154 URL: journal.unesa.ac.id/index.php/jram Prediksi Curah Hujan dengan Model Deret Waktu dan Prakiraan
Jur. Ris. & Apl. Mat. Vol. 1 (2017), no. 1, 1-52 Jurnal Riset dan Aplikasi Matematika e-issn: 2581-0154 URL: journal.unesa.ac.id/index.php/jram Prediksi Curah Hujan dengan Model Deret Waktu dan Prakiraan
Analisis Regresi Nonlinear (I)
") 9 Oktober 2013 Topik Inferensi dalam Regresi Nonlinear Contoh Kasus Regresi linear berganda secara umum sesuai untuk kebanyakan kasus. Namun, banyak kasus peubah respons dan bebas berhubungan melalui fungsi
9 Oktober 2013 Topik Inferensi dalam Regresi Nonlinear Contoh Kasus Regresi linear berganda secara umum sesuai untuk kebanyakan kasus. Namun, banyak kasus peubah respons dan bebas berhubungan melalui fungsi
BAB II LANDASAN TEORI
 BAB II LANDASAN TEORI 2.1 Peramalan 2.1.1 Pengertian Peramalan Peramalan adalah kegiatan untuk memperkirakan apa yang akan terjadi pada masa yang akan datang (Sofjan Assauri,1984). Setiap kebijakan ekonomi
BAB II LANDASAN TEORI 2.1 Peramalan 2.1.1 Pengertian Peramalan Peramalan adalah kegiatan untuk memperkirakan apa yang akan terjadi pada masa yang akan datang (Sofjan Assauri,1984). Setiap kebijakan ekonomi
BAB 2 LANDASAN TEORI
 BAB 2 LANDASAN TEORI 2.1 Peramalan Peramalan digunakanan sebagai acuan pencegah yang mendasari suatu keputusan untuk yang akan datang dalam upaya meminimalis kendala atau memaksimalkan pengembangan baik
BAB 2 LANDASAN TEORI 2.1 Peramalan Peramalan digunakanan sebagai acuan pencegah yang mendasari suatu keputusan untuk yang akan datang dalam upaya meminimalis kendala atau memaksimalkan pengembangan baik
BAB II LANDASAN TEORI
 BAB II LANDASAN TEORI Bab ini terdiri dari dua bagian. Pada bagian pertama berisi tinjauan pustaka dari penelitian-penelitian sebelumnya dan beberapa teori penunjang berisi definisi-definisi yang digunakan
BAB II LANDASAN TEORI Bab ini terdiri dari dua bagian. Pada bagian pertama berisi tinjauan pustaka dari penelitian-penelitian sebelumnya dan beberapa teori penunjang berisi definisi-definisi yang digunakan
BAB IV STUDI KASUS. Indeks merupakan daftar harga sekarang dibandingkan dengan
 BAB IV STUDI KASUS 4.1 Indeks Harga Konsumen Indeks merupakan daftar harga sekarang dibandingkan dengan sebelumnya menurut persentase untuk mengetahui turun naiknya harga barang. Indeks Harga Konsumen
BAB IV STUDI KASUS 4.1 Indeks Harga Konsumen Indeks merupakan daftar harga sekarang dibandingkan dengan sebelumnya menurut persentase untuk mengetahui turun naiknya harga barang. Indeks Harga Konsumen
SIMULASI PENGUKURAN KETEPATAN MODEL VARIOGRAM PADA METODE ORDINARY KRIGING DENGAN TEKNIK JACKKNIFE
 ISSN: 2339-2541 JURNAL GAUSSIAN, Volume 3, Nomor 3, Tahun 2014, Halaman 333-342 Online di: http://ejournal-s1.undip.ac.id/index.php/gaussian SIMULASI PENGUKURAN KETEPATAN MODEL VARIOGRAM PADA METODE ORDINARY
ISSN: 2339-2541 JURNAL GAUSSIAN, Volume 3, Nomor 3, Tahun 2014, Halaman 333-342 Online di: http://ejournal-s1.undip.ac.id/index.php/gaussian SIMULASI PENGUKURAN KETEPATAN MODEL VARIOGRAM PADA METODE ORDINARY
SBAB III MODEL VARMAX. Pengamatan time series membentuk suatu deret data pada saat t 1, t 2,..., t n
 SBAB III MODEL VARMAX 3.1. Metode Analisis VARMAX Pengamatan time series membentuk suatu deret data pada saat t 1, t 2,..., t n dengan variabel random Z n yang dapat dipandang sebagai variabel random berdistribusi
SBAB III MODEL VARMAX 3.1. Metode Analisis VARMAX Pengamatan time series membentuk suatu deret data pada saat t 1, t 2,..., t n dengan variabel random Z n yang dapat dipandang sebagai variabel random berdistribusi
BAB 2 LANDASAN TEORI. Peramalan adalah kegiatan memperkirakan apa yang akan terjadi pada masa yang
 BAB 2 LANDASAN TEORI 2.1 Peramalan Peramalan adalah kegiatan memperkirakan apa yang akan terjadi pada masa yang akan datang. Ramalan adalah suatu situasi atau kondisi yang diperkirakan akan terjadi pada
BAB 2 LANDASAN TEORI 2.1 Peramalan Peramalan adalah kegiatan memperkirakan apa yang akan terjadi pada masa yang akan datang. Ramalan adalah suatu situasi atau kondisi yang diperkirakan akan terjadi pada
Mata Kuliah Pemodelan & Simulasi. Riani Lubis Program Studi Teknik Informatika Universitas Komputer Indonesia
 Mata Kuliah Pemodelan & Simulasi Riani Lubis Program Studi Teknik Informatika Universitas Komputer Indonesia Pokok Bahasan Variabel Acak Pola Distribusi Masukan Pendugaan Pola Distribusi Uji Distribusi
Mata Kuliah Pemodelan & Simulasi Riani Lubis Program Studi Teknik Informatika Universitas Komputer Indonesia Pokok Bahasan Variabel Acak Pola Distribusi Masukan Pendugaan Pola Distribusi Uji Distribusi
MA5283 STATISTIKA Bab 3 Inferensi Untuk Mean
 MA5283 STATISTIKA Bab 3 Inferensi Untuk Mean Orang Cerdas Belajar Statistika Silabus Silabus dan Tujuan Peubah acak kontinu, distribusi dan Tabel normal, penaksiran titik dan selang, uji hipotesis untuk
MA5283 STATISTIKA Bab 3 Inferensi Untuk Mean Orang Cerdas Belajar Statistika Silabus Silabus dan Tujuan Peubah acak kontinu, distribusi dan Tabel normal, penaksiran titik dan selang, uji hipotesis untuk
III. METODE PENELITIAN
 39 III. METODE PENELITIAN 3.1. Jenis dan Sumber Data Jenis data yang digunakan dalam penelitian ini adalah data sekunder. Data sekunder tersebut merupakan data cross section dari data sembilan indikator
39 III. METODE PENELITIAN 3.1. Jenis dan Sumber Data Jenis data yang digunakan dalam penelitian ini adalah data sekunder. Data sekunder tersebut merupakan data cross section dari data sembilan indikator
TINJAUAN PUSTAKA Spesifikasi Model Berbagai model dalam pemodelan persamaan struktural telah dikembangkan oleh banyak peneliti diantaranya Bollen
 4 TINJAUAN PUSTAKA Spesifikasi Model Berbagai model dalam pemodelan persamaan struktural telah dikembangkan oleh banyak peneliti diantaranya Bollen (1989). Namun demikian sebagian besar penerapannya menggunakan
4 TINJAUAN PUSTAKA Spesifikasi Model Berbagai model dalam pemodelan persamaan struktural telah dikembangkan oleh banyak peneliti diantaranya Bollen (1989). Namun demikian sebagian besar penerapannya menggunakan
BAB II TINJAUAN PUSTAKA. return, mean, standard deviation, skewness, kurtosis, ACF, korelasi, GPD, copula,
 BAB II TINJAUAN PUSTAKA Pada bab ini akan dibahas semua konsep yang mendasari penelitian ini yaitu return, mean, standard deviation, skewness, kurtosis, ACF, korelasi, GPD, copula, VaR, estimasi VaR dengan
BAB II TINJAUAN PUSTAKA Pada bab ini akan dibahas semua konsep yang mendasari penelitian ini yaitu return, mean, standard deviation, skewness, kurtosis, ACF, korelasi, GPD, copula, VaR, estimasi VaR dengan
BEBERAPA DISTRIBUSI PELUANG KONTINU. Normal, Gamma, Eksponensial, Khi-Kuadrat, Student dan F
 BEBERAPA DISTRIBUSI PELUANG KONTINU Normal, Gamma, Eksponensial, Khi-Kuadrat, Student dan F Distribusi Normal Distribusi yang terpenting dalam bidang statistika, penemu : DeMoivre (733) dan Gauss Bergantung
BEBERAPA DISTRIBUSI PELUANG KONTINU Normal, Gamma, Eksponensial, Khi-Kuadrat, Student dan F Distribusi Normal Distribusi yang terpenting dalam bidang statistika, penemu : DeMoivre (733) dan Gauss Bergantung
Statistik Deskriptif: Central Tendency & Variation
 Statistik Deskriptif: Central Tendency & Variation Widya Rahmawati Central Tendency (Ukuran Pemusatan) dan Variation (Ukuran Simpangan) 1) Ukuran pemusatan atau ukuran lokasi adalah beberapa ukuran yang
Statistik Deskriptif: Central Tendency & Variation Widya Rahmawati Central Tendency (Ukuran Pemusatan) dan Variation (Ukuran Simpangan) 1) Ukuran pemusatan atau ukuran lokasi adalah beberapa ukuran yang
TINJAUAN PUSTAKA. Analisis regresi adalah suatu metode analisis data yang menggambarkan
 II. TINJAUAN PUSTAKA 2.1 Analisis Regresi Analisis regresi adalah suatu metode analisis data yang menggambarkan hubungan fungsional antara variabel respon dengan satu atau beberapa variabel prediktor.
II. TINJAUAN PUSTAKA 2.1 Analisis Regresi Analisis regresi adalah suatu metode analisis data yang menggambarkan hubungan fungsional antara variabel respon dengan satu atau beberapa variabel prediktor.
BAB II KAJIAN PUSTAKA. dicatat, atau diobservasi sepanjang waktu secara berurutan. Periode waktu dapat
 BAB II KAJIAN PUSTAKA 2.1 Konsep Dasar Runtun Waktu Data runtun waktu (time series) merupakan data yang dikumpulkan, dicatat, atau diobservasi sepanjang waktu secara berurutan. Periode waktu dapat berupa
BAB II KAJIAN PUSTAKA 2.1 Konsep Dasar Runtun Waktu Data runtun waktu (time series) merupakan data yang dikumpulkan, dicatat, atau diobservasi sepanjang waktu secara berurutan. Periode waktu dapat berupa
IKG4A2 Kapita Selekta Dosen: Aniq A. Rohmawati, M.Si Data Deret Waktu dan i.i.d
 IKG4A2 Kapita Selekta Dosen: Aniq A. Rohmawati, M.Si Data Deret Waktu dan i.i.d Data merupakan kumpulan informasi yang diharapkan dapat dinterpretasikan dengan baik dan akurat. Terdapat beberapa jenis
IKG4A2 Kapita Selekta Dosen: Aniq A. Rohmawati, M.Si Data Deret Waktu dan i.i.d Data merupakan kumpulan informasi yang diharapkan dapat dinterpretasikan dengan baik dan akurat. Terdapat beberapa jenis
BAB 1 PENDAHULUAN. 1.1 Latar Belakang
 BAB 1 PENDAHULUAN 1.1 Latar Belakang Analisis Regresi adalah analisis statistik yang mempelajari bagaimana memodelkan sebuah model fungsional dari data untuk dapat menjelaskan ataupun meramalkan suatu
BAB 1 PENDAHULUAN 1.1 Latar Belakang Analisis Regresi adalah analisis statistik yang mempelajari bagaimana memodelkan sebuah model fungsional dari data untuk dapat menjelaskan ataupun meramalkan suatu
DISTRIBUSI PELUANG KONTINYU DISTRIBUSI PROBABILITAS
 DISTRIBUSI PROBABILITAS Berbeda dengan variabel random diskrit, sebuah variabel random kontinyu adalah variabel yang dapat mencakup nilai pecahan maupun mencakup range/ rentang nilai tertentu. Karena terdapat
DISTRIBUSI PROBABILITAS Berbeda dengan variabel random diskrit, sebuah variabel random kontinyu adalah variabel yang dapat mencakup nilai pecahan maupun mencakup range/ rentang nilai tertentu. Karena terdapat
Dr. I Gusti Bagus Rai Utama, SE., M.MA., MA.
 Dr. I Gusti Bagus Rai Utama, SE., M.MA., MA. Populasi : totalitas dari semua objek/ individu yg memiliki karakteristik tertentu, jelas dan lengkap yang akan diteliti Sampel : bagian dari populasi yang
Dr. I Gusti Bagus Rai Utama, SE., M.MA., MA. Populasi : totalitas dari semua objek/ individu yg memiliki karakteristik tertentu, jelas dan lengkap yang akan diteliti Sampel : bagian dari populasi yang
menggunakan analisis regresi dengan metode kuadrat terkecil. Model analisis data panel yang dievaluasi kemudian adalah model gabungan, model
 4 kurang dari 10, maka peubah bebas tersebut tidak mengalami masalah multikolinearitas dengan peubah bebas lainnya. Selanjutnya Uji ARCH atau White digunakan untuk menguji asumsi kehomogenan ragam sisaan.
4 kurang dari 10, maka peubah bebas tersebut tidak mengalami masalah multikolinearitas dengan peubah bebas lainnya. Selanjutnya Uji ARCH atau White digunakan untuk menguji asumsi kehomogenan ragam sisaan.
BAB IV PENGOLAHAN DATA
 BAB IV PENGOLAHAN DATA Data yang digunakan merupakan data dari PT. XYZ, berupa peta topografi dan data pemboran 86 titik. Dari data tersebut dilakukan pengolahan sebagai berikut : 4.1 Analisis Statistik
BAB IV PENGOLAHAN DATA Data yang digunakan merupakan data dari PT. XYZ, berupa peta topografi dan data pemboran 86 titik. Dari data tersebut dilakukan pengolahan sebagai berikut : 4.1 Analisis Statistik
ESTIMASI. A. Dasar Teori
 ESTIMASI A. Dasar Teori 1. Penaksiran atau Estimasi Penaksiran atau estimasi adalah metode untuk memperkirakan nilai populasi dengan menggunakan nilai sampel. Nilai penduga disebut estimator, estimator
ESTIMASI A. Dasar Teori 1. Penaksiran atau Estimasi Penaksiran atau estimasi adalah metode untuk memperkirakan nilai populasi dengan menggunakan nilai sampel. Nilai penduga disebut estimator, estimator
BAB 3 MODEL FUNGSI TRANSFER MULTIVARIAT
 BAB 3 MODEL FUNGSI TRANSFER MULTIVARIAT Model fungsi transfer multivariat merupakan gabungan dari model ARIMA univariat dan analisis regresi berganda, sehingga menjadi suatu model yang mencampurkan pendekatan
BAB 3 MODEL FUNGSI TRANSFER MULTIVARIAT Model fungsi transfer multivariat merupakan gabungan dari model ARIMA univariat dan analisis regresi berganda, sehingga menjadi suatu model yang mencampurkan pendekatan
BAB 2 LANDASAN TEORI
 19 BAB 2 LANDASAN TEORI 2.1. Metode Analisis Data 2.1.1. Uji Validitas Validitas adalah suatu ukuran yang membuktikan bahwa apa yang diamati peneliti sesuai dengan apa yang sesungguhnya ada dalam dunia
19 BAB 2 LANDASAN TEORI 2.1. Metode Analisis Data 2.1.1. Uji Validitas Validitas adalah suatu ukuran yang membuktikan bahwa apa yang diamati peneliti sesuai dengan apa yang sesungguhnya ada dalam dunia
MA2081 Statistika Dasar
 Catatan Kuliah MA2081 Statistika Dasar Orang Cerdas Belajar Statistika Dosen: Khreshna I.A. Syuhada, MSc. PhD. Kelompok Keilmuan Statistika - FMIPA Institut Teknologi Bandung 2015 1 Tentang MA2081 Statistika
Catatan Kuliah MA2081 Statistika Dasar Orang Cerdas Belajar Statistika Dosen: Khreshna I.A. Syuhada, MSc. PhD. Kelompok Keilmuan Statistika - FMIPA Institut Teknologi Bandung 2015 1 Tentang MA2081 Statistika
ANALISIS SPASIAL DATA TAHANAN KONUS MENGGUNAKAN METODE ORDINARY KRIGING (OK)
") Jurnal Fropil Vol 4 Nomor 1 Jan-Juni 016 ANALISIS SPASIAL DATA TAHANAN KONUS MENGGUNAKAN METODE ORDINARY KRIGING (OK) Ririn Amelia Email: rynamelia.babel@yahoo.com Jurusan Teknik Sipil Fakultas Teknik
Jurnal Fropil Vol 4 Nomor 1 Jan-Juni 016 ANALISIS SPASIAL DATA TAHANAN KONUS MENGGUNAKAN METODE ORDINARY KRIGING (OK) Ririn Amelia Email: rynamelia.babel@yahoo.com Jurusan Teknik Sipil Fakultas Teknik
BAB IV HASIL PENELITIAN DAN PEMBAHASAN. terdaftar di Bursa Efek Indonesia periode tahun Pengambilan sampel
 BAB IV HASIL PENELITIAN DAN PEMBAHASAN 4.1 Sampel Penelitian Populasi yang diambil dalam penelitian ini adalah perusahan LQ-45 yang terdaftar di Bursa Efek Indonesia periode tahun 2011-2015. Pengambilan
BAB IV HASIL PENELITIAN DAN PEMBAHASAN 4.1 Sampel Penelitian Populasi yang diambil dalam penelitian ini adalah perusahan LQ-45 yang terdaftar di Bursa Efek Indonesia periode tahun 2011-2015. Pengambilan
BAB 2 LANDASAN TEORI
 BAB 2 LANDASAN TEORI Pada bab ini akan dijelaskan teori-teori yang menjadi dasar dan landasan dalam penelitian sehingga membantu mempermudah pembahasan selanjutnya. Teori tersebut meliputi arti dan peranan
BAB 2 LANDASAN TEORI Pada bab ini akan dijelaskan teori-teori yang menjadi dasar dan landasan dalam penelitian sehingga membantu mempermudah pembahasan selanjutnya. Teori tersebut meliputi arti dan peranan
DISPERSI DATA. - Jangkauan (Range) - Simpangan/deviasi Rata-rata (Mean Deviation) - Variansi (Variance) - Standar Deviasi (Standart Deviation)
 - Simpangan/deviasi Rata-rata (Mean Deviation) - Variansi (Variance) - Standar Deviasi (Standart Deviation)") DISPERSI DISPERSI DATA Ukuran penyebaran suatu kelompok data terhadap pusat data. - Jangkauan (Range) - Simpangan/deviasi Rata-rata (Mean Deviation) - Variansi (Variance) - Standar Deviasi (Standart Deviation)
DISPERSI DISPERSI DATA Ukuran penyebaran suatu kelompok data terhadap pusat data. - Jangkauan (Range) - Simpangan/deviasi Rata-rata (Mean Deviation) - Variansi (Variance) - Standar Deviasi (Standart Deviation)
BAB II LANDASAN TEORI. Data merupakan bentuk jamak dari datum. Data merupakan sekumpulan
 BAB II LANDASAN TEORI 2.1 Data Data merupakan bentuk jamak dari datum. Data merupakan sekumpulan datum yang berisi fakta-fakta serta gambaran suatu fenomena yang dikumpulkan, dirangkum, dianalisis, dan
BAB II LANDASAN TEORI 2.1 Data Data merupakan bentuk jamak dari datum. Data merupakan sekumpulan datum yang berisi fakta-fakta serta gambaran suatu fenomena yang dikumpulkan, dirangkum, dianalisis, dan
statistika untuk penelitian
 statistika untuk penelitian Kelompok Ilmiah Remaja (KIR) Delayota Experiment Team (D Expert) 2013 Freeaninationwallpaper.blogspot.com Apa itu Statistika? Statistika adalah ilmu yang mempelajari cara pengumpulan,
statistika untuk penelitian Kelompok Ilmiah Remaja (KIR) Delayota Experiment Team (D Expert) 2013 Freeaninationwallpaper.blogspot.com Apa itu Statistika? Statistika adalah ilmu yang mempelajari cara pengumpulan,
REGRESI LINIER GANDA. Fitriani Agustina, Math, UPI
 REGRESI LINIER GANDA 1 Pengertian Regresi Linier Ganda Merupakan metode yang digunakan untuk memodelkan hubungan linear antara variabel terikat dengan dua/lebih variabel bebas. Regresi linier untuk memprediksi
REGRESI LINIER GANDA 1 Pengertian Regresi Linier Ganda Merupakan metode yang digunakan untuk memodelkan hubungan linear antara variabel terikat dengan dua/lebih variabel bebas. Regresi linier untuk memprediksi
Pengenalan Analisis Deret Waktu (Time Series Analysis) MA 2081 Statistika Dasar 30 April 2012
 MA 2081 Statistika Dasar 30 April 2012") Pengenalan Analisis Deret Waktu (Time Series Analysis) ) MA 208 Statistika Dasar 0 April 202 Utriweni Mukhaiyar Ilustrasi Berikut adalah data rata-rata curah hujan bulanan yang diamati dari Stasiun Padaherang
Pengenalan Analisis Deret Waktu (Time Series Analysis) ) MA 208 Statistika Dasar 0 April 202 Utriweni Mukhaiyar Ilustrasi Berikut adalah data rata-rata curah hujan bulanan yang diamati dari Stasiun Padaherang
BAB 2 LANDASAN TEORI Pengertian Data Deret Berkala
 BAB 2 LANDASAN TEORI 2.1. Pengertian Data Deret Berkala Suatu deret berkala adalah himpunan observasi yang terkumpul atau hasil observasi yang mengalami peningkatan waktu. Data deret berkala adalah serangkaian
BAB 2 LANDASAN TEORI 2.1. Pengertian Data Deret Berkala Suatu deret berkala adalah himpunan observasi yang terkumpul atau hasil observasi yang mengalami peningkatan waktu. Data deret berkala adalah serangkaian
TINJAUAN PUSTAKA. Dalam proses pengumpulan data, peneliti sering menemukan nilai pengamatan
 4 II. TINJAUAN PUSTAKA 2.1 Definisi Pencilan Dalam proses pengumpulan data, peneliti sering menemukan nilai pengamatan yang bervariasi (beragam). Keberagaman data ini, di satu sisi sangat dibutuhkan dalam
4 II. TINJAUAN PUSTAKA 2.1 Definisi Pencilan Dalam proses pengumpulan data, peneliti sering menemukan nilai pengamatan yang bervariasi (beragam). Keberagaman data ini, di satu sisi sangat dibutuhkan dalam
BAB IV ANALISA DAN PEMBAHASAN
 BAB IV ANALISA DAN PEMBAHASAN A. Statistik Deskriptif. Statistik deskriptif adalah ilmu statistik yang mempelajari cara-cara pengumpulan, penyusunan dan penyajian data suatu penilaian. Tujuannya adalah
BAB IV ANALISA DAN PEMBAHASAN A. Statistik Deskriptif. Statistik deskriptif adalah ilmu statistik yang mempelajari cara-cara pengumpulan, penyusunan dan penyajian data suatu penilaian. Tujuannya adalah
BAB ΙΙ LANDASAN TEORI
 7 BAB ΙΙ LANDASAN TEORI Berubahnya nilai suatu variabel tidak selalu terjadi dengan sendirinya, bisa saja berubahnya nilai suatu variabel disebabkan oleh adanya perubahan nilai pada variabel lain yang
7 BAB ΙΙ LANDASAN TEORI Berubahnya nilai suatu variabel tidak selalu terjadi dengan sendirinya, bisa saja berubahnya nilai suatu variabel disebabkan oleh adanya perubahan nilai pada variabel lain yang
ORDINARY KRIGING DALAM ESTIMASI CURAH HUJAN DI KOTA SEMARANG
 ISSN: 2339-2541 JURNAL GAUSSIAN, Volume 3, Nomor 2, Tahun 2014, Halaman 151-159 Online di: http://ejournal-s1.undip.ac.id/index.php/gaussian ORDINARY KRIGING DALAM ESTIMASI CURAH HUJAN DI KOTA SEMARANG
ISSN: 2339-2541 JURNAL GAUSSIAN, Volume 3, Nomor 2, Tahun 2014, Halaman 151-159 Online di: http://ejournal-s1.undip.ac.id/index.php/gaussian ORDINARY KRIGING DALAM ESTIMASI CURAH HUJAN DI KOTA SEMARANG
II. TINJAUAN PUSTAKA
 II. TINJAUAN PUSTAKA. Pendahuluan Uji perbandingan dua distribusi merupakan suatu tekhnik analisis ang dilakukan untuk mencari nilai parameter ang baik diantara dua distribusi. Tekhnik uji perbandingan
II. TINJAUAN PUSTAKA. Pendahuluan Uji perbandingan dua distribusi merupakan suatu tekhnik analisis ang dilakukan untuk mencari nilai parameter ang baik diantara dua distribusi. Tekhnik uji perbandingan
Bab 2. Teori Dasar. 2.1 Pendahuluan
 Bab 2 Teori Dasar 2.1 Pendahuluan Gagasan bagan kendali statistik pertama kali diperkenalkan oleh Walter A. Shewhart dari Bell Telephone laboratories pada tahun 1924 (Montgomery, 2001, hal 9). Tujuan dari
Bab 2 Teori Dasar 2.1 Pendahuluan Gagasan bagan kendali statistik pertama kali diperkenalkan oleh Walter A. Shewhart dari Bell Telephone laboratories pada tahun 1924 (Montgomery, 2001, hal 9). Tujuan dari
Distribusi Normal Distribusi normal, disebut pula distribusi Gauss, adalah distribusi probabilitas yang paling banyak digunakan dalam berbagai
 Distribusi Normal Distribusi normal, disebut pula distribusi Gauss, adalah distribusi probabilitas yang paling banyak digunakan dalam berbagai analisis statistika. Distribusi normal baku adalah distribusi
Distribusi Normal Distribusi normal, disebut pula distribusi Gauss, adalah distribusi probabilitas yang paling banyak digunakan dalam berbagai analisis statistika. Distribusi normal baku adalah distribusi
BAB IX ANALISIS REGRESI
 BAB IX ANALISIS REGRESI 1. Model Analisis Regresi-Linear Analisis regresi-linear adalah metode statistic yang dapat digunakan untuk mempelajari hubungan antarsifat permasalahan yang sedang diselidiki.
BAB IX ANALISIS REGRESI 1. Model Analisis Regresi-Linear Analisis regresi-linear adalah metode statistic yang dapat digunakan untuk mempelajari hubungan antarsifat permasalahan yang sedang diselidiki.
BAB IV HASIL PENELITIAN DAN PEMBAHASAN
 BAB IV HASIL PENELITIAN DAN PEMBAHASAN 4.1 Deskripsi Data 4.1.1 Layanan Bimbingan Kelompok Data variabel Layanan Bimbingan Kelompok menunjukkan bahwa skor tertinggi adalah 120 dan skor terendah adalah
BAB IV HASIL PENELITIAN DAN PEMBAHASAN 4.1 Deskripsi Data 4.1.1 Layanan Bimbingan Kelompok Data variabel Layanan Bimbingan Kelompok menunjukkan bahwa skor tertinggi adalah 120 dan skor terendah adalah
II TINJAUAN PUSTAKA. Geostatistik adalah metode statistik yang digunakan untuk melihat hubungan
 4 II TINJAUAN PUSTAKA 2.1 Geostatistik Geostatistik adalah metode statistik yang digunakan untuk melihat hubungan antar variabel yang diukur pada titik tertentu dengan variabel yang sama diukur pada titik
4 II TINJAUAN PUSTAKA 2.1 Geostatistik Geostatistik adalah metode statistik yang digunakan untuk melihat hubungan antar variabel yang diukur pada titik tertentu dengan variabel yang sama diukur pada titik
BAB IV ANALISIS HASIL DAN PEMBAHASAN
 42 BAB IV ANALISIS HASIL DAN PEMBAHASAN A. Statisitik Deskriptif Statistik deskriptif digunakan untuk gambaran secara umum data yang telah dikumpulkan dalam penelitian ini. Dari 34 perusahaan barang konsumsi
42 BAB IV ANALISIS HASIL DAN PEMBAHASAN A. Statisitik Deskriptif Statistik deskriptif digunakan untuk gambaran secara umum data yang telah dikumpulkan dalam penelitian ini. Dari 34 perusahaan barang konsumsi
BAB I PENDAHULUAN. 1.1 Latar Belakang Masalah
 BAB I PENDAHULUAN 1.1 Latar Belakang Masalah Perkembangan teori statistika telah mempengaruhi hampir semua aspek kehidupan. Hal ini disebabkan statistika merupakan salah satu disiplin ilmu yang berperan
BAB I PENDAHULUAN 1.1 Latar Belakang Masalah Perkembangan teori statistika telah mempengaruhi hampir semua aspek kehidupan. Hal ini disebabkan statistika merupakan salah satu disiplin ilmu yang berperan
Setiap karakteristik dari distribusi populasi disebut dengan parameter. Statistik adalah variabel random yang hanya tergantung pada harga observasi
 ESTIMASI TITIK Setiap karakteristik dari distribusi populasi disebut dengan parameter. Statistik adalah variabel random yang hanya tergantung pada harga observasi sampel. Statistik merupakan bentuk dari
ESTIMASI TITIK Setiap karakteristik dari distribusi populasi disebut dengan parameter. Statistik adalah variabel random yang hanya tergantung pada harga observasi sampel. Statistik merupakan bentuk dari
METODE ORDINARY KRIGING DENGAN SEMIVARIOGRAM LINIER PADA DUA LOKASI TERSAMPEL (Studi Kasus: Prediksi Data Inflasi Pada Lokasi Tak Tersampel)
") METODE ORDINARY KRIGING DENGAN SEMIVARIOGRAM LINIER PADA DUA LOKASI TERSAMPEL (Studi Kasus: Prediksi Data Inflasi Pada Lokasi Tak Tersampel) Deltha Airuzsh Lubis 1, Shailla Rustiana 1, I Gede Nyoman Mindra
METODE ORDINARY KRIGING DENGAN SEMIVARIOGRAM LINIER PADA DUA LOKASI TERSAMPEL (Studi Kasus: Prediksi Data Inflasi Pada Lokasi Tak Tersampel) Deltha Airuzsh Lubis 1, Shailla Rustiana 1, I Gede Nyoman Mindra
CIRI-CIRI DISTRIBUSI NORMAL
 DISTRIBUSI NORMAL CIRI-CIRI DISTRIBUSI NORMAL Berbentuk lonceng simetris terhadap x = μ distribusi normal atau kurva normal disebut juga dengan nama distribusi Gauss, karena persamaan matematisnya ditemukan
DISTRIBUSI NORMAL CIRI-CIRI DISTRIBUSI NORMAL Berbentuk lonceng simetris terhadap x = μ distribusi normal atau kurva normal disebut juga dengan nama distribusi Gauss, karena persamaan matematisnya ditemukan
1. Model Regresi Linear dan Penaksir Kuadrat Terkecil 2. Prediksi Nilai Respons 3. Inferensi Untuk Parameter-parameter Regresi 4.
 * 1. Model Regresi Linear dan Penaksir Kuadrat Terkecil 2. Prediksi Nilai Respons 3. Inferensi Untuk Parameter-parameter Regresi 4. Kecocokan Model Regresi 5. Korelasi Utriweni Mukhaiyar MA 2081 Statistika
* 1. Model Regresi Linear dan Penaksir Kuadrat Terkecil 2. Prediksi Nilai Respons 3. Inferensi Untuk Parameter-parameter Regresi 4. Kecocokan Model Regresi 5. Korelasi Utriweni Mukhaiyar MA 2081 Statistika
BAB II TINJAUAN PUSTAKA. satu peubah prediktor dengan satu peubah respon disebut analisis regresi linier
 BAB II TINJAUAN PUSTAKA 2.1 Analisis Regresi Linier Berganda Analisis regresi pertama kali dikembangkan oleh Sir Francis Galton pada abad ke-19. Analisis regresi dengan satu peubah prediktor dan satu peubah
BAB II TINJAUAN PUSTAKA 2.1 Analisis Regresi Linier Berganda Analisis regresi pertama kali dikembangkan oleh Sir Francis Galton pada abad ke-19. Analisis regresi dengan satu peubah prediktor dan satu peubah
Konsep Dasar Statistik dan Probabilitas
 Konsep Dasar Statistik dan Probabilitas Pengendalian Kualitas Statistika Ayundyah Kesumawati Prodi Statistika FMIPA-UII September 30, 2015 Ayundyah (UII) Konsep Dasar Statistik dan Probabilitas September
Konsep Dasar Statistik dan Probabilitas Pengendalian Kualitas Statistika Ayundyah Kesumawati Prodi Statistika FMIPA-UII September 30, 2015 Ayundyah (UII) Konsep Dasar Statistik dan Probabilitas September
MODUL TEORI ESTIMASI ATAU MENAKSIR TEORI ESTIMASI ATAU MENAKSIR
 TEORI ESTIMASI ATAU MENAKSIR MODUL 9 TEORI ESTIMASI ATAU MENAKSIR. Pendahuluan Untuk menginginkan mengumpulkan populasi kita lakukan dengan statistik berdasarkan data yang diambil secara sampling yang
TEORI ESTIMASI ATAU MENAKSIR MODUL 9 TEORI ESTIMASI ATAU MENAKSIR. Pendahuluan Untuk menginginkan mengumpulkan populasi kita lakukan dengan statistik berdasarkan data yang diambil secara sampling yang
Bab I Pendahuluan I.1 Latar Belakang Masalah
 I.1 Latar Belakang Masalah Pendidikan merupakan salah satu sektor penting dalam pembangunan di setiap negara. Menurut Undang-Undang No. 20 Tahun 2004 pendidikan merupakan usaha sadar dan terencana untuk
I.1 Latar Belakang Masalah Pendidikan merupakan salah satu sektor penting dalam pembangunan di setiap negara. Menurut Undang-Undang No. 20 Tahun 2004 pendidikan merupakan usaha sadar dan terencana untuk
4.1. Pengumpulan data Gambar 4.1. Contoh Peng b untuk Mean imputation
 4.1. Pengumpulan data Data trafik jaringan yang diunduh dari http://www.cacti.mipa.uns.ac.id:90 dapat diklasifikasikan berdasar download rata-rata, download maksimum, download minimum, upload rata-rata,
4.1. Pengumpulan data Data trafik jaringan yang diunduh dari http://www.cacti.mipa.uns.ac.id:90 dapat diklasifikasikan berdasar download rata-rata, download maksimum, download minimum, upload rata-rata,
BAB IV HASIL PENELITIAN DAN PEMBAHASAN
 BAB IV HASIL PENELITIAN DAN PEMBAHASAN Dalam pembahasan ini dikaji mengenai nilai ekspektasi saham pada jatuh tempo, persamaan nilai portofolio, penentuan model Black-Scholes harga opsi beli tipe Eropa,
BAB IV HASIL PENELITIAN DAN PEMBAHASAN Dalam pembahasan ini dikaji mengenai nilai ekspektasi saham pada jatuh tempo, persamaan nilai portofolio, penentuan model Black-Scholes harga opsi beli tipe Eropa,
Metode Penelitian Kuantitatif Aswad Analisis Deskriptif
 Analisis Deskriptif Tanpa mengurangi keterumuman, pembahasan analisis deskriptif kali ini difokuskan kepada pembahasan tentang Ukuran Pemusatan Data, dan Ukuran Penyebaran Data Terlebih dahulu penting
Analisis Deskriptif Tanpa mengurangi keterumuman, pembahasan analisis deskriptif kali ini difokuskan kepada pembahasan tentang Ukuran Pemusatan Data, dan Ukuran Penyebaran Data Terlebih dahulu penting
BAB IV PEMBAHASAN DAN HASIL PENELITIAN
 BAB IV PEMBAHASAN DAN HASIL PENELITIAN IV.1 Analisis Deskriptif IV.1.1 Gambaran Mengenai Return Saham Tabel IV.1 Descriptive Statistics N Range Minimum Maximum Mean Std. Deviation Return Saham 45 2.09-0.40
BAB IV PEMBAHASAN DAN HASIL PENELITIAN IV.1 Analisis Deskriptif IV.1.1 Gambaran Mengenai Return Saham Tabel IV.1 Descriptive Statistics N Range Minimum Maximum Mean Std. Deviation Return Saham 45 2.09-0.40
BAB 4 ANALISIS DAN PEMBAHASAN
 BAB 4 ANALISIS DAN PEMBAHASAN 4.1 Pergerakan Harga Saham Pergerakan harga harian indeks LQ45 dan lima saham perbankan yang termasuk dalam kelompok LQ45 selama periode penelitian ditampilkan dalam bentuk
BAB 4 ANALISIS DAN PEMBAHASAN 4.1 Pergerakan Harga Saham Pergerakan harga harian indeks LQ45 dan lima saham perbankan yang termasuk dalam kelompok LQ45 selama periode penelitian ditampilkan dalam bentuk
JURNAL GAUSSIAN, Volume 2, Nomor 1, Tahun 2013, Halaman 1-10 Online di:
 JURNAL GAUSSIAN, Volume 2, Nomor 1, Tahun 2013, Halaman 1-10 Online di: http://ejournal-s1.undip.ac.id/index.php/gaussian ESTIMASI KANDUNGAN HASIL TAMBANG MENGGUNAKAN ORDINARY INDICATOR KRIGING Aldila
JURNAL GAUSSIAN, Volume 2, Nomor 1, Tahun 2013, Halaman 1-10 Online di: http://ejournal-s1.undip.ac.id/index.php/gaussian ESTIMASI KANDUNGAN HASIL TAMBANG MENGGUNAKAN ORDINARY INDICATOR KRIGING Aldila
METODE PENELITIAN Sumber Data
 13 METODE PENELITIAN Sumber Data Data yang digunakan dalam penelitian ini merupakan hasil simulasi melalui pembangkitan dari komputer. Untuk membangkitkan data, digunakan desain model persamaan struktural
13 METODE PENELITIAN Sumber Data Data yang digunakan dalam penelitian ini merupakan hasil simulasi melalui pembangkitan dari komputer. Untuk membangkitkan data, digunakan desain model persamaan struktural
MODEL DISTRIBUSI TOTAL KERUGIAN AGGREGAT MANFAAT RAWAT JALAN BERDASARKAN SIMULASI
 MODEL DISTRIBUSI TOTAL KERUGIAN AGGREGAT MANFAAT RAWAT JALAN BERDASARKAN SIMULASI Puspitaningrum Rahmawati, Bambang Susanto, Leopoldus Ricky Sasongko Program Studi Matematika (Fakultas Sains dan Matematika,
MODEL DISTRIBUSI TOTAL KERUGIAN AGGREGAT MANFAAT RAWAT JALAN BERDASARKAN SIMULASI Puspitaningrum Rahmawati, Bambang Susanto, Leopoldus Ricky Sasongko Program Studi Matematika (Fakultas Sains dan Matematika,
BAB 4 HASIL DAN PEMBAHASAN. penentuan jumlah sampel minimum yang harus diambil. Tabel 4.1 Data Hasil Survei Pendahuluan. Jumlah Kepala Keluarga (Xi)
") BAB 4 HASIL DAN PEMBAHASAN 4.1. Hasil Pengumpulan Data Berdasarkan data jumlah kepala keluarga pada masing-masing perumahan yang didapatkan pada survei pendahuluan, maka dapat dilakukan penentuan jumlah
BAB 4 HASIL DAN PEMBAHASAN 4.1. Hasil Pengumpulan Data Berdasarkan data jumlah kepala keluarga pada masing-masing perumahan yang didapatkan pada survei pendahuluan, maka dapat dilakukan penentuan jumlah
TATAP MUKA IV UKURAN PENYIMPANGAN SKEWNESS DAN KURTOSIS. Fitri Yulianti, SP. MSi.
 TATAP MUKA IV UKURAN PENYIMPANGAN SKEWNESS DAN KURTOSIS Fitri Yulianti, SP. MSi. UKURAN PENYIMPANGAN Pengukuran penyimpangan adalah suatu ukuran yang menunjukkan tinggi rendahnya perbedaan data yang diperoleh
TATAP MUKA IV UKURAN PENYIMPANGAN SKEWNESS DAN KURTOSIS Fitri Yulianti, SP. MSi. UKURAN PENYIMPANGAN Pengukuran penyimpangan adalah suatu ukuran yang menunjukkan tinggi rendahnya perbedaan data yang diperoleh
BAB II LANDASAN TEORI. landasan pembahasan pada bab selanjutnya. Pengertian-pengertian dasar yang di
 5 BAB II LANDASAN TEORI Bab ini membahas pengertian-pengertian dasar yang digunakan sebagai landasan pembahasan pada bab selanjutnya. Pengertian-pengertian dasar yang di bahas adalah sebagai berikut: A.
5 BAB II LANDASAN TEORI Bab ini membahas pengertian-pengertian dasar yang digunakan sebagai landasan pembahasan pada bab selanjutnya. Pengertian-pengertian dasar yang di bahas adalah sebagai berikut: A.