KATA PENGANTAR. Kediri, April Penulis
|
|
|
- Benny Tedja
- 7 tahun lalu
- Tontonan:
Transkripsi

1

2
3 KATA PENGANTAR Puji syukur kehadirat Allah SWT, karena berkat rahmat, karunia dan hidayahnya, buku Dasar Statistik untuk Kesehatan ini dapat terselesaikan. Statistik merupakan salah satu cabang ilmu Pengetahuan yang sangat diperlukan dalam suatu kegiatan Penelitian. Usaha-usaha yang dilakukan dalam rangka pengambilan Keputusan dan menentukan kebijakan perlu di dukung oleh hasil penelitian yang akurat. Dalam Buku ini akan dipelajari tentang bagaimana cara menyelesaikan Masalah-Masalah probabilitas sebagai alat pengambil keputusan, alat-alat statistik yang dibutuhkan untuk melakukan pengkajian terhadap masalah yang dihadapi. Serta sebagai dasar berpikir selanjutnya dalam mencari terobosan baru (policy) guna memecahkan masalah yang dihadapi. Adapun isi dari Buku Dasar Statistik Untuk Kesehatan ini adalah sebagai berikut : Teori probabilitas, Distribusi Probabilitas Diskret, Teori Keputusan, Metode dan Distribusi Sampling, Hipotesa, Uji Chi Kuadrat, Korelasi, Analisis Regresi, Uji t, dan Anova.. Buku Dasar Statistika Untuk Kesehatan ini untuk membekali kompetensi mahasiswa, namun demikian. Dengan adanya buku ini di harapkan kepada mahasiswa agar lebih mudah dan mengerti didalam pemahaman materi - materi yang ada, karena di susun menggunakan bahasa yang sederhana, dan mudah mudahan dapat mengaplikasikan dalam kehidupan sehari hari. Ucapan Terima Kasih Penulis sampaikan kepada semua pihak yang telah membantu proses penyelesaian buku ini. Kritik dan saran bersifat membangun dalam penyempurnaan buku ini sangat penulis harapkan. Semoga Buku ini membawa manfaat kepada pembaca. Aamiin. Kediri, April 2016 Penulis
4 DAFTAR ISI Kata pengantar... Daftar isi... i ii BAB I KONSEP DASAR PROBABILITAS... 1 A. PENDAHULUAN Manfaat mempelajari Probabilitas Pengertian Probabilitas... 1 B. PENDEKATAN PROBABILITAS Pendekatan Klasik Pendekatan Relatif Pendekatan Subjektif... 3 BAB 2 KONSEP DASAR DAN HUKUM PROBABILITAS... 4 A. Hukum Penjumlahan Peristiwa atau kejadian bersama Kejadian Saling Lepas... 5 B. Hukum Perkalian Probabilitas Bersyarat Peristiwa Pelengkap... 6 C. Diagram Pohon Probabilitas... 6 BAB 3 TEOREMA BAYES... 8 A. Faktorial... 8 B. Permutasi... 8 C. Kombinasi... 9 BAB 4 KARAKTERISTIKDISTRIBUSI KURVA NORMAL a. Distribusi Probabilitas dan kurva normal dengan dan Simbol b. Distribusi Probabilitas dan kurva normal dengan berbeda dan sama c. Distribusi Probabilitas dan kurva normal dengan berbeda dan berbeda d. Distribusi Probabilitas Normal Baku e. Luas Dibawah Kurva Normal f. Pendekatan Normal Terhadap Binomial g. Faktor Koreksi Kontinuitas BAB 5 DISTRIBUSI PROBABILITAS NORMAL A. Pengertian Distribusi Probabilitas B. Variabel Acak/Random a. Variabel Acak b. Variabel Acak Diskret c. Variabel Acak Kontinu C. Rata-rata hitung, varians, dan standart deviasi a. Nilai Rata-rata Hitung b. Varians dan Standar Deviasi D. Distribusi Probabilitas Binomial BAB 6 TEORI KEPUTUSAN Elemen-elemen Keputusan Keputusan dalam Keadaan Beresiko A. Nilai yang diharapkan (Expected Value) B. Expected Opportunity Loss... 23
5 C. Expected Value of Perfect Information D. Pengambilan keputusan dalam kondisi ketidakpastian E. Analisis Pohon Keputusan BAB 7 MEETODE DAN DISTRIBUSI SAMPLING A. Metode Penarikan Sample Penarikan Sample Acak Sederhana Sistem Kocokan Menggunakan tabel Acak Penarikan Sampel Acak Terstuktur Penarikan sampel Cluster Penarikan Sample secara sistematis Penarikan Sampel kuota Penarikan sample purposive B. Kesalahan Penarikan Sample (Sampling Error) C. Distribusi Sampel Rata-rata dan proporsi D. Distribusi Sampel Selisih Rata-rata dan proporsi E. Faktor koreksi untuk populasi terbatas F. Penarikan sampel purposive (purposive sampling) BAB 8 HIPOTESIS A. Hipotesis B. Pengujian Hipotesis C. Prosedur Pengujian Hipotesis BAB 9 MENGUJI HIPOTESA RATA-RATA SAMPEL BESAR BAB 10 PENGUJIAN HIPOTESA SAMPEL KECIL BAB 11 UJI CHI KUADRAT A. Statistika Non Parametrik B. Chi Kuadrat untuk Uji Goodness of Fit C. Uji keselarasan D. Uji keselarasan dengan frekuensi harapan sama E. Uji Chi Kuadrat untuk uji kenormalan F. Uji Chi Kuadrat untuk uji Independensi BAB 12 DATA STATISTIK A. Pengertian Statistik B. Data Statistik C. Penyajian Data BAB 13 KORELASI BIVARIATE A. Pengertian Korelasi B. Koefisien Korelasi C. Interpretasi Dalam Korelasi D. Macam Korelasi dan Teknik Penghitungan a. Korelasi Pearson b. Tata Jenjang c. Phi d. Coefficient Contingency BAB 14 REGRESI LINIER SEDERHANA A. Definisi Regresi Linier... 58
6 B. Metode Regresi Linier Sederhana BAB 15 UJI BEDA BIVARIATE A. Paired Sample t-test B. Independent Sample t-test BAB 16 ANALYSIS OF VARIANCE (ANOVA) A. Anova Satu Arah B. Analisis Sesudah Anova DAFTAR PUSTAKA LAMPIRAN
7 A. PENDAHULUAN BAB 1 KONSEP DASAR PROBABILITAS Secara sederhana probabilitas dapat diartikan sebagai sebuah peluang untuk suatu kejadian. 1. Manfaat mempelajari probabilitas sangat berguna untuk pengambilan keputusan yang tepat, karena kehidupan di dunia tidak ada kepastian, sehingga diperlukan untuk mengetahui berapa besar probabilitas suatu peristiwa akan terjadi. Probabilitas dinyatakan dalam angka pecahan antara 0 sampai 1 atau dalam persentase. Contoh: Seluruh mahasiswa STIKes Surya Mitra Husada harus memiliki sertifikat Bahasa Inggris. Di kota Kediri sendiri banyak terdapat tempat kursus Bahasa Inggris diantaranya Mozaik, Mahesa, Elfas dll. Maka akan muncul kebingungan dalam memilih tempat kursus. Untuk menentukan pilihan biasanya mahasiswa akan bertanya kepada teman-teman, mereka kursus dimana? Dari ratusan mahasiswa mungkin anda bertanya hanya pada 20 orang mahasiswa. Yang paling banyak diminati anda akan memilih tempat tersebut untuk kursus. Dari contoh tersebut dapat dilihat bahwa keputusan diambil hanya dari beberapa contoh atau sampel dari populasi keseluruhan. 2. Pengertian Probabilitas Lind (2002) dalam mendefinisikan probabilitas sebagai : Suatu ukuran tentang kemungkinan suatu peristiwa (event) akan terjadi dimasa mendatang. Probabilitas dinyatakan anatara 0 sampai 1 atau dalam persentase Tiga Hal penting dalam membicarakan probabilitas : a. Percobaan (Experiment) Pengamatan terhadap beberapa aktivitas atau proses yang memungkinkan timbulnya paling sedikit dua peristiwa tanpa memperhatikan peristiwa mana yang akan terjadi. b. Hasil (Outcome) Suatu Hasil dari sebuah percobaan. Dalam Hasil ini semua Kejadian akan dicatat atau dalam artian seluruh peristiwa yang akan terjadi dalam sebuah percobaan. Misalnya dalam mengikuti ujian semester maka hasil yang akan diperoleh ada mahasiswa yang lulus dan ada yang tidak lulus. Ada yang lulus memuaskan ada yang tidak memuaskan. c. Peristiwa (Event)
8 Kumpulan dari satu atau lebih hasil yang terjadi pada sebuah percobaan atau kegiatan. Contoh : Percobaan Hasil Peristiwa Tabel 1.1 Tabel peristiwa Pertandingan Sepak Bola antara Prodi IKM dan Prodi IKP STIKes SMH Prodi IKM menang, Prodi IKM kalah, Seri, tidak ada yang menang dan tidak ada yang kalah Prodi IKM Menang Probabilitas dinyatakan dalam bentuk pecahan dari 0 sampai 1. probabilitas 0 menunjukan sesuatu yang tidak mungkin terjadi, sedangkan probabilitas 1 menunjukkan peristiwa pasti terjadi. Contoh penulisan probabilitas dalam desimal atau persentase : 1. Pada hari jumat adalah penutupan bursa saham, maka kebanyakan investor berusaha meraih keuntungan melalui penjualan saham atau yang biasanya diistilahkan profit taking, sehingga probabilitas menjual mencapai 0.7 sedangkan membeli 0,3. 2. melihat kondisi kesiapan mahasiswa yang mengikuti ujian Statistika Inferensial, maka mahasiswa yang mempunyai probabilitas untuk lulus 70 % dan kalah 30 % Probabilitas kejadian dengan nilai 0 berati peristiwa yang tidak mungkin terjadi, seperti seorang anak balita melahirkan seorang bayi. Sedangkan probabilitas dengan nilai 1 adalah peristiwa yang terjadi, seperti semua manusia pasti akan meninggal. B. PENDEKATAN PROBABILITAS Untuk menentukan tingkat probabilitas suatu kejadian, maka ada tiga pendekatan yaitu pendekatan klasik, pendekatan relatif dan pendekatan subjektif. 1. Pendekatan Klasik Diasumsikan bahwa semua peristiwa mempunyai kesempatan yang sama untuk terjadi (equally likely). Probabilitas suatu peristiwa kemudian dinyatakan sebagai rasio antara jumlah kemungkinan hasil dengan total kemungkinan hasil (rasio peristiwa terhadap hasil). Probabilitas = Contoh : Pada kegiatan mahasiswa belajar semua hasil ada yang sangat memuaskan, memuaskan dan terpuji. Jumlah hasil ada 3 dan hanya 1 peristiwa yang terjadi, maka probabilitas setiap peristiwa 1/3.
9 Pada suatu percobaan hanya 1 peristiwa yang terjadi, dan peristiwa lain tidak mungkin terjadi pada waktu yang bersamaan maka dikenal sebagai peristiwa saling lepas. Peristiwa saling lepas (mutually exclusive) adalah terjadinya suatu peristiwa sehingga peristiwa yang lain tidak terjadi pada waktu yang bersamaan Pada suatu percobaan atau kegiatan semua hasil mempunyai probabilitas yang sama, dan hanya satu peristiwa yang terjadi maka peristiwa ini dikenal dengan lengkap terbatas kolektif (collectio exhaustive). lengkap terbatas kolektif (collection exhaustive) adalah sedikitnya satu dari seluruh hasil yang ada pasti terjadi pada setiap percobaan atau kegiatan yang dilakukan 2. Pendekatan Relatif Probabilitas suatu keadian tidak dianggap sama, tergantung dari beberapa banyak suatu kejadian terjadi, yang dinyatakan sebagai berikut : Contoh : Dari Kegiatan belajar mahasiswa dapat dilihat hasilnya pada Wisuda Sarjana Sarjana STIKes SMH tahun 2015 sebanyak 800 orang mahasiswa. 500 orang lulus dengan memuaskan, 200 orang dengan sangat memuaskan dan 100 orang dengan predikat terpuji. Maka probabilitas lulus memuaskan adalah 500/800 = 0.625; lulus dengan sangat memuaskan 200/800 = 0.25 dan lulus dengan terpuji 100/800 = Pendekatan Subjektif Yang dimaksud dengan pendekatan subjektif adalah menentukan besarnya probabilitas suatu peristiwa didasarkan pada penilaian pribadi dan dinyatakan dalam derajat kepercayaan. Contoh : Menurut pengamat politik, Jokowi akan menang dalam Pemilu Indonesia tahun 2019.
10 BAB 2 KONSEP DASAR DAN HUKUM PROBABILITAS Dalam Teori probabilitas, probabilitas kejadian dilambangkan dengan P, apabila kejadian jual saham dilambagkan dengan huruf A, Maka probabilitas jual saham dilambagkan dengan P A. Sebaliknya apabila kejadian beli saham dilambangkan dengan B, Maka probabilitas beli saham dilambangkan dengan P (B). A. Hukum Penjumlahan Hukum penjumlahan menghendaki peristiwa yang saling lepas (mutually exclusive) yaitu apabila suatu peristiwa terjadi, maka peristiwa lain tidak dapat terjadi pada saat bersamaan. Hukum ini dilambangkan sebagai : P (A ATAU B) = P(A) + P(B) Untuk Kejadian yang lebih banyak dilambangkan sampai n yaitu: P (A atau... n) = P (A) + P (B) P (n) Contoh : Berikut adalah kegiatan unit mahasiswa untuk tiga sekolah tinggi kesehatan di xediri dengan jumlah total sebanyak 200 kegiatan. Tabel 2.1 Jenis transaksi Jenis Transaksi Volume Transaksi Kegiatan A 120 Kegiatan B 80 Jumlah Total kegiatan 200 Penyelesaian : Dari data diatas diketahui bahwa : Probabilitas Kegiatan A = P (A) = 120/200 = 0.60 Probabilitas Kegiatan B = P (B) = 80/200 = 0.40 Sehingga Probabilitas A atau B, P (A atau B) = P (A) + P(B) = = Peristiwa atau Kejadian Bersama Pada peristiwa bersama dua atau lebih peristiwa dapat terjadi secara bersamasama, peristiwa bersama tersebut dapat lebih mudah dilihat dengan diagram Venn seperti berikut A AD D
11 Gambar 2.1 Kejadian bersama Penjumlahan probabilitas dengan adanya unsur kegiatan bersama, maka rumus penjumlahan dirumuskan kembali menjadi sebagai berikut : P (A atau D) = P(A) + P(D) P(AD) Dimana : P (A atau D) : probabilitas terjadinya A atau D atau A dan D bersma-sama P (A) : probabilitas terjadinya A P (D) : probabilitas terjadinya D P (AD) : probabilitas terjadinya A dan D bersama-sama 2. Kejadian saling lepas (mutually exclusive) Kejadian saling lepas terjadi apabila hanya satu dari dua atau lebih peristiwa yang dapat terjadi. Dapat digambarkan dengan diagram Venn: A B Gambar 2.2 Kejadian saling lepas Oleh sebab itu, untuk peristiwa yang saling lepas, probabilitas kejadian A atau B yang Dinyatakan P (A atau B) P(A atau b) = P (A) P (B) P (AB) Karena P (AB) = 0 maka P (A atau B) = P (A) + P (B) 0 Sehingga : P (A atau B) = P (A) + P (B) Contoh : Cobalah hitung beberapa probabilitas kegiatan mahasiswa yang meliputi kegiatan A dan kegiatan B disebut P(AB) dan probabilitas kejadian untuk sekolah kesehatan X, Y, dan Z di sebut P(CDE) Tabel 2.1 Probabilitas Kegiatan di Sekolah kesehatan Kegiatan Sekolah Tinggi Kesehatan X (C) Y (D) Z (E) Jumlah Kegiatan ( A ) Kegiatan ( B ) Jumlah Penyelesaian : Probabilitas kejadian A dan B adalah kejadian yang saling lepas, maka P(AB) = 0. maka hukum penjumlahan untuk peristiwa saling lepas adalah : P (A atau B) = P(A) + P(B) P(AB) = = 1.0
12 probabilitas kejadian ketiga Sekolah Tinggi Kesehatan juga merupakan kejadian saling lepas, maka hukum penjumlahannya adalah : P (C atau D atau E) = P (C) + P (D) + P (E) P(CDE) = = 1.0 probabilitas P(C atau D atau E) = P(C) + P (D) + P(E) P(CDE) = = 1.0 probabilitas P(C atau D) P (C atau D) B. Hukum Perkalian = P (C) + P(D) P(CD) = = 0.75 Dalam hukum perkalian dikehendaki setiap peristiwa independent yaitu suatu peristiwa yang terjadi tanpa harus menghalangi peristiwa lain terjadi. Peristiwa Independent adalah terjadinya peristiwa atau kejadian tidak mempengaruhi probabilitas terjadinya peristiwa lain. Dapat dinyatakan dalam bentuk : P(A dan B) = P(A) x P(B) 1. Probabilitas bersyarat (Condicional Probability) Probabilitas bersyarat adalah suatu peristiwa akan terjadi, dengan kektentuan perstiwa lain telah terjadi. Hukum perkalian untuk probabilitas bersyarat bahwa peristiwa B terjadi dengan syarat peristiwa A telah terjadi dinyatakan sebagai berikut : P (A dan B) = P(A) x P(B) 2. Peristiwa Pelengkap (Complementary Event) Peristiwa pelengkap menunjukan bahwa aabila ada dua peristiwa A dan B yang saling melengkapi, sehingga jika peristiwa A tidak terjadi, maka peristiwa B pasti terjadi. Maka probabilitas keduanya dapat dirumuskan sebagai berikut : P (A) + P (B) =1 atau P(A) = 1 P(B ) Dalam bentuk diagram Venn dapat digambarkan sebagai berikut : A B Gambar 2.3 Diagram Venn
13 C. Diagram Pohon Probabilitas Tahapan dalam menyusun diagram pohon : 1. Tahap 1 adalah langkah awal kegiatan, kita mulai dengan tanda titik atau bulatan dengan angka, tahap 1 diumpamakan sebagai pohonnya dengan pohon utamanya berupa kegiatan dibursa saham. Nilai probabilitas pada tahap 1 adalah Tahap 2, membuat cabang. Kegiatan di sekolah kesehatan ada 2 yaitu kegiatan A dan kegiatan B dengan probabilitas kegiatan A = 0,6 dan probabilitas kegiatan B = 0,4. Nilai probabilitas pada cabang = 0,6 + 0,4 = 1,0 3. Tahap 3 membuat ranting. Pada setiap cabang baik kegiatan A maupun kegiatan B ada 3 ranting jenis saham. Ranting jenis sekolah kesehatan yaitu X, Y dan Z. Nilai probabilitas setiap ranting = 0,35 + 0,40 + 0,25 = 1 4. Tahap 4, menghitung probabilitas bersama (joint probability) antara kejadian pertama A dan B dengan kejadian kedua C,D dan E. kita bisa menghitung probabilitas P(C A) atau P(D B)Secara langsung. Nilai probabilitas keseluruhan pada tahap empat juga harus sama dengan 1. Contoh : Hasil penelitian di jakarta menunjukkan bahwa 60 % dari usaha kecil dan menengah (UKM) tidak berbadan hukum, sedang sisanya berbadan hukum. Bank sebagai lembaga pembiayaan dengan memperhatikan aspek kehati-hatian memberikan probabilitas 80 % kepada UKM berbadan hukum masih mempunyai kesempatan sebesar 20 % untuk mendapatkan kredit. Hitunglah beberapa persen probabilitas UKM mendapat kredit dari Bank? Penyelesaian : X Kegiatan B (0,4) Y Z 1 X Kegiatan A (0,6) Y Z Gambar 2.4 Diagram pohon
14 BAB 3 TEOREMA BAYES Teorema ini dikembangkan oleh Thomas Bayes pada abad ke-18. Bayes seorang pendeta, bertanya apakah Tuhan ada dengan memperhatikan fakta-fakta yang ada di bumi. Jadi bila Tuhan ada, maka ada fakta sebagai ciptaan Tuhan. Apabila fakta dilambangkan P(A 1 ) untuk suatu fakta dan P(A 2 ) untuk fakta lain, sedang keberadaan Tuhan dinyatakan dengan P(B), maka teorema Bayes dinyatakan sebagai : ( ) Rumus diataas merupakan probabilitas bersyarat, suatu kejadian terjadi setelah kejadian lain ada. P( B) menyatakan bahwa fakta-fakta di bumi akan ada apabila Tuhan ada. Karena banyak fakta tersebut maka rumus Bayes diperluas : ( ) ( ) BEBERAPA PRINSIP MENGHITUNG A. FAKTORIAL Faktorial digunakan untuk mengetahui berapa banyak cara yang mungkin dalam mengatur sesuatu kelompok. Contoh konvensional, apabila kita mempunyai tiga sekolah kesehatan yaitu SMH, Karya dan Bhakti ada berapa cara menyusun urutan ketiga bank tersebut? Secara sederhana dapat kita lakukan dengan mengurut ketiga bank sebagai berikut: SMH, Karya, Bhakti Karya, SMH, Bhakti SMH, Bhakti, Karya Karya, Bhakti, SMH Bhakti, SMH, Karya Bhakti, Karya, SMH Dari uraian diatas dapata kita ketahui bahwa terdapat 6 cara mengurutkan nama sekolah kesehatan tersebut tersebut, namun apabila jumlah sekolah kesehatan tersebut tersebut 50 buah sekolah kesehatan, tentu kita akan kewalahan dalam mengurutkan. Maka dapat dilakukan dekat pendekatan faktorial, Apabila sekolah kesehatan berjumlah tigas maka cara mengurutkan nama Sekolah Kesehatan Tersebut : 3! = 3 X 2 X 1 = 6 B. PERMUTASI Digunakan untuk mengetahui sejumlah kemungkinan susunan (arrangement) jika terdapat satu kelompok objek. Pada permutasi ini kita berkepentingan dengan susunan atau urutan dari objek, permutasi dirumuskan sebagai berikut:
15 dimana : P : Jumlah permutasi atau cara Objek disusun n : Jumlah total objek yang disusun r : Jumlah objek yang digunakan pada saat bersamaan, jumlah r dapat sama dengan n atau lebih lebih! : tanda dari faktorial Contoh : Dari 20 Kelas di STIKes Surya Mitra Husada, ingin dikelompokkan menjadi beberapa kelompok. Jika satu kelompok terdiri dari 5 kelas, ada berapa susunan kelompok yang dapat dibuat? Jabab : C. COMBINASI Kombinasi digunakan apabila kita tertarik pada berapa cara sesuatu diambil dari keseluruhan objek tanpa memerhatikan urutannya. Misalnya ada 10 Sekolah Kesehatan dan kita hanya akan mengambil 3 Sekolah Kesehatan, maka ada beberapa kombinasi bank yang dapat diambil tanpa memperhatikan urutan atau susunannya. Dirumuskan sebagai berikut : Contoh : Ada 5 orang siswa mendaftar sebagai pembawa acara dalam suatu kegiatan hiburan. Pihak penyelenggara hanya akan memilih 2 orang yang dapat dijadikan pasangan. Ada berapa kombinasi pasangan yang dapat dipilih oleh panitia?
16 BAB 4 KARAKTERISTIK DISTRIBUSI KURVA NORMAL Kurva normal bentuk simetris, masing-masing sisi sama Gambar 4.1 Kurva normal 1. Kurva berbentuk genta (=Md=Mo) 2. Kurva berbentuk simetris 3. Kurva normal berbentuk asimptotis 4. Kurva mencapai puncak pada saat X= 5. Luas daerah di bawah kurva adalah 1 ; di sisi kanan nilai tengah dan di sisi kiri. Distribusi probabilitas dan kurva mempunyai persamaan matematika yang sangat tergantung pada nilai tengah () dan standar defiasi (). Distribusi probabilitas dan kurva normal dari suatu variable acak (X) yang nilainya terletak - sampai dinyatakan dengan lambang X ~ N (X;,). Bila X suatu pengubah acak normal dengan nilai tengah, dan standar deviasi, maka persamaan kurva normalnya adalah :
17 -1/2(x-)/ 2, untuk -< X < Jenis-Jenis Probabilitas Normal Jenis-jenis probabilitas normal sangat dipengaruhi oleh nilai rata-rata hitung dan standar deviasinya, maka distribusi probabilitas kurva normal diantaranya. a. Distribusi probabilitas dan kurva Normal dengan dan berbeda. Gambar 4.2 kurva normal dengan dan berbeda 1. Mesokurtik Kurva normal ini mempunyai = Md dan Mo yang sama, namun berbeda 2. Platykurtik Nilai semakin tinggi dan kurva semakin pendek. Nilai tinggi menunjukkan bahwa nilai data semakin menyebar dari nilai tengahnya (). 3. Leptokurtik Nilai semakin rendah dan kurva semakin runcing. Nilai rendah ini menunjukan data semakin mengelompokkan pad nilai tengahnya () b. Distribusi probabilitas dan kurva Normal dengan Berbeda dan sama Bentuk distribusi probabilitas dan kurva normal dengan berbeda dan sama mempunyai jarak antara kurva yang berbeda, namun bentuk kurva tetap sama. Gambar diataas menunjukan nilai rata-rata berbeda dengan standar daviasi yang sama. Pada contoh dapat dilihat mangga dikelompokkan menjadi mutu A dengan berat rata-rata 450 gram, mutu B dengan 300 gram dan mutu C dengan 150 gram.
18 Gambar 4.3 kurva Normal dengan Berbeda dan sama c. Distribusi probabilitas dan Kurva normal dengan Berbeda dan berbeda Kurva dengan berbeda dan berbeda mempunyai titik pusat yang berbeda pada sumbu mendatar dan bentuk kurva berbeda karena mempunyai standar deviasi yang berbeda. Kurva seperti ini relatif sering terjadi karena antara populasi terdapat perbedaan atau setiap populasi juga mempunyai keragaman yang berbeda. Gambar 4.4 Kurva normal dengan Berbeda dan berbeda d. Distribusi probabilitas Normal Baku Distribusi normal baku adalah distribusi probabilitas acak normal dengan nilai tengah nol dan simpangan baku 1. Beberapa hal yang perlu dlakukan dalam rangka distribusi probabilitas normal baku adalah mengubah atau membakukan distribusi aktual dalam bentuk distribusi normal baku yang dikenal dengan Z. atau skor Z. rumus nilai Z adalah : Dimana : Z = skor Z atau nilai normal baku X = NIlai dari suatu pengamaan atau pengukuran
19 μ σ = Nilai rata-rata hitung suatu Distribusi = stndar deviasi suatu distribusi e. Luas dibawah Kurva Normal Kurva Normal juga mengikuti hukum empirik. Untuk distribusi simetris, dengan distribusi frekuensi berbentuk lonceng seperti kurva normal diperkirakan 68,26% data akan berada pada kisaran rata-rata hitung ditambah dua kali standar deviasi, (X ± 1σ), (X ± 2σ) dan semua data atau 99,74 % akan berada pada kisaran rata-rata hitung ditambahtiga kali standar deviasi, (X ± 3σ). Gambar 4.5 kurva normal contoh soal Luas antara nilai Z (-1<Z<1) sebesar 68,26 % dari julah data Berapa LUas antara Z antara 0 dan sampai Z = 0,76 atau biasa ditulis P(0<Z<0, 76)? Dapat dicari dari table luas di bawah kurva Normal. Nilainya dihailkan = 0,2764 f. Pendekatan Normal Terhadap Binominal Pada distribusi probabilitas binomial, dengan semakin besarnya nilai n, maka semakin mendekati nilai distribusi normal. Gambar 4.6 Grafik normal terhadap binomial Apabila kita perhatikan suatu distribusi probabilitas binomial, dengan semakin besarnya nilai n, maka semakin mendekati nilai distribusi normal. Gambar berikut menunjukkan distribusi probabilitas binomial dengan n yang semakin membesar. Pada saat n = 20 terlihat bahwa distribusi probabilitas binomial mendekati distribusi probabilitas normal yaitu kurva berbentuk lonceng, memiliki puncak tunggal dan simetris. Dalil pendekatan normal terhadap Binomial.
20 Bila nilai X dalah distribusi acak Binomial dengan nilai tengah = np dan standar deviasi σ=, maka nilai Z untuk distribusi normal adalah: Dimana n dan nilai p mendekati 0,5 g. Faktor Koreksi Kontunuitas Untuk mengubah pendekatan dari binomial ke normal (menurut Lind 2002) diperlukan faktor koreksi selain syarat binomial terpenuhi yaitu : a. Hanya terdapat dua peristiwa b. Peristiwa bersifat independen c. Besar probabilitas sukses dan gagal sama setiap percobaan d. Data merupakan hasil perhitungan Apabila telah memenuhi syarat binomial, maka kita menggunakan faktor koreksi yang besarnya 0,5. Faktor koreksi ini diperlukn untuk mentransformasi dari binomial menuju normal yang merupakan variable acak kontinu. Contoh : Sudah merupakan pedagang buah di pusat pasar medan. Setiap hari membeli 300 kg jeruk. Probabilitas buah laku dijual adalah 80 % dan 20 % tidak laku atau busuk. Berapa probabilitas buah sebanyak 250 kg laku dan tidak busuk? Jawab : n = 300; probabilitas laku p = 0,8 dan q = 0,2 μ = np = 300 x 0,80 = 240 σ = = 6,93 diketahui X = 250, dikurang faktor koreksi 0,5 sehingga X = 250 0,5 = 249,5 dengan demikian nilai Z menjadi ; Z = (249,5 240)/6,93 =,37 dan P(Z <1,37) = 0,4147 Jadi probabilitas buah laku 250 kg adalah = 0,5 + 0,4147 = 0,9147 Jadi harapan buah laku 250 kg adalah 91,47%
21 BAB 5 DISTRIBUSI PROBABILITAS DISKRIT Untuk mempermudah mengetahui probabilitas banyak kejadian atau percobaan dapat dilakukan dengan bantuan distribusi probabilitas. Dimana distribusi probabilitas memberikan keseluruhan kemungkinan nilai yang mungkin muncul atau terjadi dari sebuah kejadian atau percobaan. A. Pengertian Distribusi Probabilitas Distribusi probabilitas menunjukan hasil yang diharapkan terjadi dari suatukegiatan dengan nilai probabilitas masing-masing hasil tersebut. Distribusi probabilitas adalah sebuah daftar dari keseluruhan hasil suatu percobaan kejadian yang disertai dengan nilai probabilitas masing-masing hasil(event). Contoh: Ada tiga orang mahasiswa yang akan memilih mata kuliah pada semester genap tahun 2015/2016. Mata kuliah tersebut adalah Biostasistika (BSTK) dan Aplikasi Komputer (Aplikom). Ketiga mahasiswa tersebut bebas memilih mata kuliah mana yang akan diikuti, bisa memilih BSTK semua, BSTK dan Aplikom atau Aplikom semua. Berikut adalah kemungkinan dari ketiga pilihan mahasiswa tersebut. Tabel 5.1 Tabel pilihan kegiatan Kemungkinan Pilihan Mahasiswa Jumlah Pilihan BSTK A B C 1 BSTK BSTK BSTK 3 2 BSTK BSTK Aplikom 2 3 BSTK Aplikom BSTK 2 4 BSTK Aplikom Aplikom 1 5 Aplikom BSTK BSTK 2 6 Aplikom BSTK Aplikom 1 7 Aplikom Aplikom BSTK 1 8 Aplikom Aplikom Aplikom 0 dari tabel dapat dilihat kemungkinan mahasiswa tidak memilih BSTK sama sekali ada satu kejadian, mahasiswa hanya satu yang memilih BSTK ada 3 kejadian, ada 2 mahasiswa yang memilih BSTK ada 3 kejadian. Mahasiswa ada 3 orang yang memilih BSTK ada 1 kejadian. Dari ke 8 kejadian tersebut kita dapat menyusun distribusi probabilitas sebagai berikut : Tabel 5.2 Tabel distribusi probabilitas Jumlah BSTK di Pilih Mahasiswa Jumlah Frekuensi Total Kemungkinan Distribusi Probabilitas Hasil P(r) /8 0, /8 0, /8 0, /8 0,125 Jumlah Total Distribusi Probabilitas 1,000

22 Dari tabel distribusi probabilitas kita dapat dengan mudah menentukan berapa probabilitas ketiga mahasiswa akan memilih mata kuliah Biostatistik yaitu 0,125. Dalam bentuk grafik poligon dapat digambarkan sebagai berikut: Gambar 5.1 Distribusi Probabilitas pilihan mahasiswa B. Variabel Acak/Random a. Variabel Acak Variabel acak didefenisikan sebagai sebuah ukuran atau besaran yang merupakan hasil suatu percobaan atau kejadian yang terjadi secara acak atau untung-untungan dan mempunyai nilai yang berbeda-beda. Contoh: Petani menimbang berat setiap semangka yang telah dipanen. Dari lima semangka beratnya berturut-turut 3.56; 3.80; 2.79; 3.60 dan 4.05 kg. Maka penimbangan berat adalah percobaan acak dan nilai berat setiap semangka adalah variabel acak. b. variabel acak diskret variabel acak diskret merupakan hasil dari percobaan yang bersifat acak dan mempunyai nilai tertentu yang terpisah dalam suatu interval. Variabel acak diskret ini biasanya berupa bilang bulat dan berasal dari hasil perhitungan. Contoh: jumlah mahasiswa 800 orang, jumlah buah jeruk 20 buah, jumlah telur 300 butir dan sebagainya. c. variabel acak kontinu variabel acak kontinu mempunyai nilai yang menempati pada seluruh interval hasil percobaan, biasanya dihasilkan dari hasil pengukuran dan bukan penjumlahan. Semua nilai yang dihasilkan dari kegiatan pengukuran baik bulat maupun pecahan merupakan variabel acak kontinu. Contoh: pada buah semangka jumlah buah semangka 10 buah adalah variabel acak diskret, tapi berat semangka misalnya 3,56 kg ini merupakan variabel acak kontinu. C. Rata-rata Hitung, Varians, dan Standar Deviasi a. Nilai Rata-rata Hitung
23 Nilai rata-rata hitung merupakan nilai harapan (expected value) yang dilambangkan E(x) Rumus nilai rata-rata hitung: μ = E(x) = (X). P(X) dimana: μ : Nilai rata-rata hitung distribusi pobabilitas E(x) : Nilai harapan (expected value) X : Kejadian P(X) : Probabilitas suatu kejadian : Lambang operasi penjumlahan b. Varians dan Standar deviasi Varian dan standar deviasi merupakan ukuran penyebaran yaitu mengukur seberapa besar data menyebar dari nilai tengahnya. Semakin kecil sebaran data, maka semakin baik, karena menunjukkan data mengelompok pada nilai rata-rata hitung. Varian dan standar deviasi dirumuskan sebagai berikut Dimana: 2 : Varians : Standar deviasi X : Nilai suatu kejadian : Nilai rata-rata hitung distribusi probabilitas P(X) : Probabilitas suatu kejadian X : Lambang operasi penjumlahan Contoh: Hitunglah nilai rata-rata hitung, Standar deviasi dan Varian pada kasus pilihan tiga mahasiswa pada mata kuliah Biostatistika pada contoh terdahulu? Penyelesaian : Tabel 5.3 tabel probabilitas X P(x) x.p(x) X-P (x-p) 2 (x-r) 2 P(x) 0 0,125 0,000-1,500 2,250 0, ,375 0,375-0,500 0,250 0, ,375 0,750 0,500 0,250 0, ,125 0,375 1,500 2,250 0,281 1, ,750 Dari data diatas dapat dilihat bahwa : Rata-rata hitung adalah sebesar 1,500 menunjukan bahwa ada 1,5 mahasiswa yang mengambil mata kuliah Biostatistika. Namun karena orang tidak dalam bentuk pecahan, maka bisa didekatkan pada 1 atau 2 orang. Varians 2 = 0,75, maka standar deviasi = = = = 0,87. Ini menunjukan bahwa standar penyimpangan data dari nilai tengahnya adalah 0,87.
24 D. Distribusi Probabilitas Binomial Ini menggambarkan data yang dihasilkan oleh suatu percobaan yang dinamakan Bernoulli. Ciri-ciri Percobaan Bernouli: Setiap percobaan menghasilkan dua kejadian: (a) kelahiran anak: laki-laki-perempuan; (b) transaksi saham: jual- beli, (c) perkembangan suku bunga: naik turun dan lain-lain. Probabilitas suatu kejadian untuk sukses atau gagal adalah tetap untuk setiap kejadian. P(p), peluang sukses, P(q) peluang gagal, dan P(p) + P(q)= 1. Suatu percobaan dengan percobaan bersifat bebas. Data yang dihasilkan adalah data perhitungan. Pembentukan Distribusí Binomial Hal yang diperlukan dalam membentuk distribusí binomial: a. banyaknya atau jumlah dari percobaan atau kegiatan b. Probabilitas suatu kejadian baik sukses maupun gagal Dapat dinyatakan sebagai berikut: Dimana: P (r) : Nilai probabilitas binomial P : Probabilitas sukses suatu kejadian dalam setiap percobaan r : Banyaknya peristiwa sukses suatu kejadian untuk keseluruhan percobaan n : Jumlah total percobaan q : Probabilitas gagal suatu kejadian yang diperoleh dari q = 1 p! : Lambang faktorial Contoh: PT Sari Buah Lestari mengirim buah-buah segar setiap harinya kepada sebuah swalaya terkenal di kota Kediri. Dengan jaminan kualitas buah yang segar, 80% buah yang dikirim lolos seleksi oleh swalayan tersebut. PT Sari Buah Lestari mengirim 10 buah Melon setiap harinya Permintaan: a. Berapa probabilitas 10 buah diterima b. Berapa probabilitas 8 buah diterima c. Berapa probabilitas 7 buah diterima Penyelesaian: a. probabilitas 100 buah diterima semua n = 10 p = 0,8 r = 10 q = 0,2
25 E. Distribusi probabilitas Hipergeometrik Dalam distribusi binomial diasumsikan bahwa peluang suatu kejadian tetap atau konstan atau antar-kejadian saling lepas. Dalam dunia nyata, jarang terjadi hal demikian. Suatu kejadian sering terjadi tanpa pemulihan dan nilai setiap kejadian adalah berbeda atau tidak konstan. Distribusi dengan tanpa pemulihan dan probabilitas berbeda adalah Distribusi Hipergeometrik. Pada kasus dimana terjadi percobaan tanpa pengembalian pada populasi yang terbatas, dan jumlah sampel terhadap populasinya lebih 5%, distribusi hipergeometrik lebih tepat digunakan. Distribusi hipergeometrik dinyatakan sebagai berikut: Dimana: P (r) : Nilai probabilitas hipergeometrik dengan kejadian r sukses N : Jumlah populasi S : Jumlah sukses dalam populasi r : Jumlah sukses yang menjadi perhatian n : Jumlah sampel dari populasi C : Simbol kombinasi Contoh : Seorang penjual kelapa muda baru mendapat kiriman 20 buah kelapa yang 5 diantaranya sudah terlalu tua. Jika seseorang mengambil 2 buah kelapa secara acak, tentukanlah peluang bahwa : a. Kelapa yang terambil kedua-duanya adalah kelapa tua b. Kelapa yang terambil kedua-duanya adalah kelapa muda c. Kelapa yang terambil salah satunya adalah kelapa tua Jawab : Diketahui : N = 20 S = 15 n = 2 a. r = 2 b. S = 5 r = 2
26 c. r = 1 F. Distribusi Probabilitas Poisson Dikembangkan oleh Simon Poisson Distribusi Probabilitas Poisson adalah distribusi yang digunakan untuk pendekatan probabilitas binomial. Ciri utama dari distribusi poisson adalah untuk menghitung peluang jumlah kedatangan, kunjungan pada suatu tempat menurut satuan waktu. Seperti peluang penambahan orang cacat dari tahun ke tahun, peluang jumlah kendaraan yang lewat per jamnya sampai peluang jumlah penelpon sebuah operator per menitnya. Poisson memperhatikan bahwa distribusi binomial sangat bermanfaat dan dapat menjelaskan dengan baik, namun untuk n di atas 50 dan nilai P(p) sangat kecil akan sulit mendapatkan nilai binomialnya. Rumus: dimana P(X) : Nilai probabilitas distribusi poisson μ : Rata-rata hitung dari jumlah nilai sukses; dimana μ = n.p e : Bilangan konstan = 2,71828 X : Jumlah nilai sukses P : probabilitas sukses suatu kejadian! : Lambang faktorial Contoh soal : 1. Jumlah mobil yang memasuki gerbang jalan tol dalam setiap menit diketahui berdistribusi Poisson. Jika rata-rata jumlah mobil yang memasuki gerbang tol permenitnya adalah 3 buah mobil tentukan peluang bahwa antara jam sampai terdapat dua mobil yang memasuki gerbang tol tersebut. 2. Survei Komnas PA pada tahun 2015, menunjukkan bahwa dari siswa SMP berusia tahun, sebanyak 90% sudah terpapar iklan rokok dan 41% dari
27 yang sudah terpapar rokok tersebut akhirnya mencoba untuk merokok. Apabila diambil 20 siswa SMP di DKI Jakarta secara acak, maka hitunglah peluang: a. Tidak ada siswa yang tidak merokok b. Lebih dari 5 siswa yang merokok. 3. Pada tahun 2014, sebuah kota di pedalaman Watampone, diperoleh data bahwa rata-rata terdapat 2,5 orang albino per 175 orang. 525 orang diambil sebagai sampel percobaan. Dengan menggunakan pendekatan Possion, tentukanlah peluang: a. Didapat tidak ada yang albino. b. Terdapat ada albino.
28 BAB 6 TEORI KEPUTUSAN Setiap hari kita harus mengambil keputusan, baik keputusan yang sederhana maupun keputusan jangka panjang. Untuk membantu dalam pengambilan keputusan, ilmu statistika telah mengembangkan cabang statistika baru yaitu teori keputusan statistika. Ilmu ini berkembang sejak tahun 1950-an yang sebenarnya telah dipelopori sejak abad ke-18 oleh pendeta Thomas Bayes. Contoh: Keputusan yang diambil suatu perusahaan atau Universitas Swasta: Barang dan jasa apa yang akan diproduksi, Metode apa yang dipakai untuk memproduksi, Untuk siapa barang dan jasa di produksi, Bagaimana strategi pemasaran dan promosinya, Apakah perusahaan membutuhkan tenaga pemasaran, dan lain-lain. 1. Elemen-elemen Keputusan Kepastian (certainty): informasi untuk pengambilan keputusan tersedia dan valid. Risiko (risk): informasi untuk pengambilan keputusan tidak sempurna, dan ada probabilitas atas suatu kejadian. Ketidakpastian (uncertainty): suatu keputusan dengan kondisi informasi tidak empurna dan probabilitas suatu kejadian tidak ada. Konflik (conflict): keputusan di mana terdapat lebih dari dua kepentingan. Setiap keputusan dalam atatistika mempunyai tiga elemen atau komponen penting 1. Pilihan atau alternatif yang terjadi bagi setiap keputusan. 2. States of nature yaitu peristiwa atau kejadian yang tidak dapat dihindari atau dikendalikan oleh pengambil keputusan. 3. Hasil atau payoff dari setiap keputusan. Hubungan elemen keputusan menurut Lind (2002) Peristiwa Tindakan Ketidakpastian berkenaan dengan kondisi mendatang, Pengambil keputusan tidak mempunyai kendali terhadap kondisi mendatang Dua atau lebih alternatif dihadapi pengambil keputusan. Pengambil keputusan harus mengevaluasi alternatif dan memilih alternatif dengan kriteria tertentu Hasil/Payoff Laba, Impas, (Break even), rugi
29 2. Keputusan dalam Keadaan Beresiko Pengambilan keputusan dalam keadaan berisiko berarti bahwa terdapat informasi Namur tidak sempurna, dan ada probabilitas terhadap statu kejadian. Ada beberapa langkah yang diperlukan dalam pengambilan keputusan berisiko yaitu: 1. Mengidentifikasi berbagai macam alternatif yang ada dan layak bagi suatu keputusan. 2. Menduga probabilitas terhadap setiap alternatif yang ada. 3. Menyusun hasil/payoff untuk semua alternatif yang ada 4. Mengambil keputusan berdasarkan hasil yang baik Contoh: Kode Perusahaan Harga Saham Juml saham Kondisi baik Deviden/ lbr Total deviden Kondisi Buruk Deviden/ Total lbr deviden Aventis Kimia Farma Soho Ibrahim merupakan apoteker modern, dan menginvestasi sebagian keuntungan untuk membeli saham. Pada tahun 2015 ia berinvestasi sebesar Rp ,-. Ada tiga saham perusahaan yang sedang dipelajari yaitu saham Aventis, saham Kimia Farma dan Saham Soho. Beberapa metode dalam statistika yang digunakan untuk pengambilan keputusan dalam keadaan berisiko: SAHAM OL BAIK P= 0,5 OL BURUK P = 0,5 Perhitungan EV Nilai EV Aventis ( x0,5) + ( x0,5) A. Nilai yang diharapkan (Expected Value) EV = Payoff x Probabilitas Suatu Kejadian
30 Kimia Farma Soho B. Expected Opportunity Loss Metode lain dalam mengambil keputusan selain EV EOL mempunyai prinsip meminimumkan kerugian karena pemilihan bukan keputusan terbaik. Hasil yang terbaik dari setiap kejadian diberikan nilai 0, sedangkan untuk hasil yang lain adalah selisih antara nilai terbaik dengan nilai hasil pada peristiwa tersebut. EOL = Opportunity Loss x Probabilitas Suatu Peristiwa SAHAM OL BAIK OL P= 0,5 BURUK Perhitungan EV Nilai EV P = 0,5 Aventis ( x 0,5) (0 x 0,5) Kimia Farma Soho Nilai OL untuk alternatif terbaik adalah nol, maka kondisi baik adalah Soho = 0 dan kondisi terburuk Aventis = 0. nilai OL terendah adalah untuk Soho maka dapat direkomendasikan untuk dibeli oleh investor. 3. Ecpected value of Perfect Information Hasil yang diharapkan dalam informasi sempurna merupakan perbedaan antara hasilmaksimum dalam kondisi kepastian dan hasil maksimum dalam kondisi ketidak pastian Setiap keputusan tidak harus tetap setiap saat. Keputusan dapat berubah untukmengambil kesempatan yang terbaik. Pada kasus harga saham, pada kondisi baik, saham Aventis adalah pilihan terbaik, namun pada kondisi buruk, maka saham Kimia Farma lebih baik.apabila hanya membeli saham Soho maka EV = x 0, x 0,5 = Apabila keputusan berubah dengan adanya informasi yang sempurna denganmembeli harga saham Soho dan Kimia Farma EVif = x 0, x 0,5 = Nilai EVif lebih tinggi dari EV dengan selisih: = = Nilai ini mencerminkan harga dari sebuah informasi. Nilai informasi ini menunjukkan bahwa informasi yang tepat itu berharga dan menjadi peluang pekerjaan -- seperti pialang, analis pasar modal, dan lain-lain. 4. Pengambilan Keputusan dalam Kondisi Ketidakpastian Keputusan dalam ketidakpastian menunjukkan tidak adanya informasi yang sempurna,juga tidak adanya probabilitas atau informasi tentang probabilitas suatu kejadian. Ada beberapa kriteria yang telah dikembangkan dalam pengambilan keputusan untuk kondisi ketidakpastian: 1. Kriteria Laplace
31 Probabilitas semua kejadian diasumsikan sama, dan hasil perkalian antara hasil dengan probabilitas yang tertinggi tertinggi adalah keputusan terbaik. 2. Kriteria Maximin Keputusan didasarkan pada kondisi pesimis atau mencari Nilai maksimum pada kondisi pesimis (lakukan yang terbaik dalam situasi terburuk) 3. Kriteria Maximax Keputusan didasarkan pada kondisi optimis dan mencari nilai maksimumnya. 4. Kriteria Hurwicz Keputusan didasarkan pada perkalian hasil dan koefisien optimisme. Koefisien ini nilainya antara 0 sampai 1. nilai 0 untuk kondisi yang sangat pesimis dan nilai 1 untuk kondisi yang sangat optimis. Koefisien ini merupakan perpaduan antara optimis dan pesimis. Alternatif yang terbaik adalah nilai yang tertinggi dari hasil perkalian antara hasil atau payoff dengan koefisien optimisme. 5. Kriteria (Minimax) Regret Keputusan didasarkan pada nilai regret minimum. Nilai regret diperoleh dari nilai OL (opportunity Loss) pada setiap kondisi dan dipilih yang maksimum. Alternatif keputusan yang diambil adalah nilai regret yang Perusahaan Kondisi Perekonomian Boom Normal Krisis Aventis Kimia Farma Soho minimum Contoh : Berikut adalah deviden yang dibagikan oleh tiga perusahaan yang ada di BEJ yaitu Aventis, Kimia Farma dan Soho. Deviden dibedakan dalam krisis, normal dan Boom. a. Kriteria Laplace 1. EV (Aventis) = 1/3 X /3 X /3 X 250 = EV (Kimia Farma) = 1/3 X /3 X /3 X 300 = EV (Soho) = 1/3 X /3 x /3 x 185 = Berdasarkan kriteria Laplace, keputusan terbaik adalah membeli saham Soho. μ : Rata-rata hitung dari jumlah nilai sukses; dimana μ = n.p e : Bilangan konstsan = 2,71828 X : Jumlah nilai sukses P : probabilitas sukses suatu kejadian! : Lambang faktorial
32 5. Analisis Pohon Keputusan Keputusan EV PayOff Probabilitas 836 Boom (0,63) Membeli saham Aventis Krisis (0,37) Boom (0,63) 2000 Membeli saham kimia farma Krisis (0,37) Boom (0,63) 4463 Membeli Saham Soho Krisis (0,37) 185 BAB 7 METODE DAN DISTRIBUSI SAMPLING Populasi dan sampel merupakan aspek penting dalam mempelajari statistika induktif. Populasi adalah kumpulan dari semua kemungkinan orang-orang, benda-benda dan ukuran lain yang menjadi objek perhatian atau kumpulan seluruh objek yang menjadi perhatian. Sampel adalah suatu bagian dari populasi tertentu yang menjadi perhatian. Hubungan populasi dan sample dapat digambarkan sebagai berikut: Populasi Gambar 7.1 Populasi sampel Sampel Populasi dapat dikelompokkan menjadi dua, yaitu: a. Populasi terbatas (finite) yaitu populasi yang ukurannya terbatas berukuran N. Contoh: semua Sekolah Tinggi Kesehatan yang ada misalnya 140 Sekolah Tinggi Kesehatan. b. Populasi tidak terbatas (infinite) yaitu populasi yang mengalami proses secara terus menerus sehinga usuran N menjadi tidak terbatas perubahan nilainya.
33 Secara umum, sampel yang baik adalah yang dapat mewakili sebanyak mungkin karakteristik populasi. Dalam bahasa pengukuran, artinya sampel harus valid, yaitu bisa mengukur sesuatu yang seharusnya diukur. Kalau yang ingin diukur adalah masyarakat Sunda sedangkan yang dijadikan sampel adalah hanya orang Banten saja, maka sampel tersebut tidak valid, karena tidak mengukur sesuatu yang seharusnya diukur (orang Sunda). Sampel yang valid ditentukan oleh dua pertimbangan. a. Akurasi atau ketepatan, yaitu tingkat ketidakadaan bias (kekeliruan) dalam sample. Dengan kata lain makin sedikit tingkat kekeliruan yang ada dalam sampel, makin akurat sampel tersebut. Tolok ukur adanya bias atau kekeliruan adalah populasi. b. Presisi, Kriteria kedua sampel yang baik adalah memiliki tingkat presisi estimasi. Presisi mengacu pada persoalan sedekat mana estimasi kita dengan karakteristik populasi. Belum pernah ada sampel yang bisa mewakili karakteristik populasi sepenuhnya. Oleh karena itu dalam setiap penarikan sampel senantiasa melekat keasalahan-kesalahan, yang dikenal dengan nama sampling error Presisi diukur oleh simpangan baku (standard error). Makin kecil perbedaan di antara simpangan baku yang diperoleh dari sampel (S) dengan simpangan baku dari populasi (s), makin tinggi pula tingkat presisinya. Walau tidak selamanya, tingkat presisi mungkin bisa meningkat dengan cara menambahkan jumlah sampel, karena kesalahan mungkin bisa berkurang kalau jumlah sampelnya ditambah ( Kerlinger, 1973 ). Sampel dapat dibedakan menjadi dua yaitu: Sampel probabilitas Merupakan suatu sampel yang dipilih sedemikian rupa dari populasi sehingga masing-masing anggota populasi memiliki probabilitas atau peluang yang sama untuk dijadikan sampel. Sampel nonprobabilitas Merupakan suatu sampel yang dipilih sedemikian rupa dari populasi sehingga setiap anggota tidak memiliki probabilitas atau peluang yang sama untuk dijadikan sampel. A. Metode penarikan sample Metode Penarikan Sampel Sampel Probabilitas (Probability Sampling) Sampel Non Probabilitas (NonProbabilitas Sampling) 1. Penarikan sampel acak sederhana (Simple random sampling) 2. Penarikan sampel acak terstruktur (Stratified random sampling) 3. Penarikan sampel cluster (cluster sampling) 4. Penarikan sampel sistematika (Systematic random sampling) 1. Penarikan sampel sistematis 2. Penarikan sampel kuota 3. Penarikan sampel purposive (Purposive Sampling)
34 Sampel Probabilitas (Probability Sampling) 1. Penarikan sampel acak sederhana (simple random sampling) 2. Penarikan sampel acak terstruktur (stratified random sampling) 3. Penarikan sampel cluster (cluster sampling) 4. Penarikan sampel sistematika (Systematic Random Sampling) Sampel Nonprobabilitas (Nonprobability Sampling) 1. Penarikan sampel sistematis (systematic sampling) 2. Penarikan sampel kuota (kuota sampling) 3. Penarikan sampel purposive (purposive sampling) 1. Penarikan Sampel Acak Sederhana Merupakan pengambilan sampel dari populasi secara acak tanpa memperhatikan strata yang ada dalam populasi dan setiap anggota populasi memiliki kesempatan yang sama untuk dijadikan sampel. Ada dua cara pengambilan sampel acak sederhana 1. Sistem Kocokan Sistem sampel acak sederhana dengan cara sama sistem arisan. 2. Menggunakan tabel acak Memilih sampel dengan menggunakan suatu tabel. Dalam penggunaannya ditentukan terlebih dahulu titik awal (starting point). 2. Penarikan sampel acak terstruktur: Penarikan sampel acak terstruktur dilakukan dengan membagi anggota populasi dalam beberapa sub kelompok yang disebut strata, lalu suatu sampel dipilih dari masing-masing stratum. Dari table diatas terlihat bahwa jumlah sample setiap stratumnya didasarkan pada jumlah proporsi persentsae setiap stratum terhadap jumlah totalnya. Gambar 7.2 penarikan sampel terstruktur Sampel acak terstruktur terbagi menjadi dua, yaitu : a. Proporsional
 yang sama yang digunakan.")
35 Teknik sampling random strata proporsional digunakan apabila proporsi ukuran subpopulasi atau jumlah satuan elementer dalam setiap strata relatif seimbang atau relatif sama besar. Dalam sampel strata proporsional, dari setiap strata diambil sampel yang sebanding dengan besar setiap strata dengan berpatokan pada pecahan sampling (sampling fraction) yang sama yang digunakan. Pecahan sampling adalah angka yang menunjukkan persentase ukuran sampel yang akan diambil dari ukuran populasi tertentu. Cara pengambilan sample dilakukan dengan menyeleksi setiap unit sampling yang sesuai dengan ukuran unit sampling. Keuntungannya ialah aspek representatifnya lebih meyakinkan sesuai dengan sifat-sifat ynag membentuk dasar unit-unit yang mengklasifikasinya, sehingga mengurangi keanekaragamannya. Karakteristik-karakeristik masing-masing strata dapat diestimasikan sehingga dapat dibuat perbandingan. Kerugiannya ialah membutuhkan informasi yang akurat pada proporsi populasi untuk masingmasing strata. Jika hal tersebut diabaikan maka kesalahan akan muncul. b. Disproporsional Pada Sampel Strata Disproporsional, ukuran sampel yang diambil dari setiap subpopulasi (strata) sama besarnya, yang berbeda adalah pecahan samplingnya. Strategi pengambilan sample sama dengan proporsional. Perbedaanya ialah terletak pada ukuran sample yang tidak proporsional terhadap ukuran unit sampling karena untuk kepentingan pertimbangan analisa dan kesesuaian. 3. Penarikan sample Cluster (cluster sampling) Penarikan cluster adalah teknik memilih sampel dari kelompok unit-unit kecil (cluster) dari sebuah populasi yang relatif besar dan tersebar luas. Anggota dalam setiap cluster bersifat tidak homogen berbeda dengan penarikan sampel terstruktur. Pemilihan sampel pada metode ini adalah dengan metode acak sederhana, dengan harapan akan mengurangi biaya penarikan sampel populasi yang tersebar pada area geografis yang terlalu besar. Gambar 7.3 teknik sampling cluster
36 4. Penarikan sampel secara sistematis (systematic Random Sampling) Penarikan dikatakan sampel sistematis apabila setiap unsur atau anggota dalam populasi disusun dengan cara tertentu-secara alfabetis, dari besar kecil atau sebaliknya-kemudian dipilih titik awal secara acak lalu setiap anggota ke K dari populasi dipilih sebagai sampel. Sebagai contoh apabila akan dipilih 5 perusahaan reksadana, maka perusahaan mana yang akan menjadi sampel dengan menggunakan metode sistematis, beberapa langkah yang harus dilakukan adalah: a. memberikan nomor urutan misalnya dari aset terbesar sampai terkecil atau sebaliknya b. jumlah populasi misalnya 59, dan jumlah sampel 5, maka jarak antara sampel adalah 12 c. nomor sampel adalah 1, 13, 25, 37, dan 49 (setiap sampel berjarak secara sistematis yaitu 12) 5. Penarikan sampel Kuota (Kuota sampling) Penarikan sampel kuota adalah pengambilan sampel dari populasi yang mempunyai ciri-ciri tertentu sampai jumlah atau kuota yang diinginkan. Tujuan penarikan sampel kuota adalah untuk memperbaiki keterwakilan seluruh komponen dalam populasi. Sebagai contoh apabila akan dilakukan penelitian terhadap tingkat kehadiran mahasiswa yang mengambil matakuliah statistika dari populasi 150 orang ditentukan kuota 20 orang. Kalau pengumpulan data belum mencapai 20 orang maka penelitian belum dianggap selesai. 6. penarikan sampel purposive (purposive sampling) Penarikan sampel purposive adalah penarikan sampel dengan pertimbangan tertentu. Pertimbangan tersebut berdasarkan pada kepentingan atau tujuan penelitian. Penarikan sampel dengan purposive ada dua cara: a. convenience sampling yaitu penarikan sampel berdasarkan keinginan peneliti sesuai dengan tujuan penelitian. b. Judment sampling yaitu penarikan sampel berdasarkan penilaian terhadap karakteristik anggota sampel yang disesuaikan dengan tujuan penelitian. B. Cara Menentukan Ukuran Sampel 1. Dengan Tabel Salah satu cara menentukan ukuran sampel yang di kembangkan oleh Isaac dan Michael dengan menggunakan pendekatan statistic untuk tingkat Kesalahan 1%, 5%, dan 10% adalah sebagai berikut :

37 2. Dengan Rumus a. Dengan asumsi jumlah populasi diketahui Dimana : n : jumlah sampel minimal yang di perlukan
38 d : presisi absolut N : jumlah populasi Z 1-α/2 = nilai pada table Z sesuai dengan nilai d yang telah di tentukan b. Dengan asumsi jumlah populasi tidak di ketahui Dengan pendekatan rumus Lemeshow Dengan pendekatan kohort dan case control (retrospektif) c. Dengan pendekatan eksperimen Menurut Supranto J (2000) untuk penelitian eksperimen dengan rancangan acak lengkap, acak kelompok atau faktorial, secara sederhana dapat dirumuskan: (t-1) (r-1) > 15 dimana : t = banyaknya kelompok perlakuan j = jumlah replikasi Contohnya: Jika jumlah perlakuan ada 4 buah, maka jumlah ulangan untuk tiap perlakuan dapat dihitung: (4-1) (r-1) > 15 (r-1) > 15/3 r > 6 Untuk mengantisipasi hilangnya unit ekskperimen maka dilakukan koreksi dengan 1/(1-f) di mana f adalah proporsi unit eksperimen yang hilang atau mengundur diri atau drop out. C. Kesalahan penarikan sampel (sampling error)
39 Merupakan perbedaan antara nilai statistik sampel dengan nilai parameter dari populasi. Dalam pemilihan sampel, dimana jumlah sampel adalah sebagian dari populasi, mungkin akan terdapat perbedaan antara rata-rata hitung dan standar deviasi sampel terhadap rata-rata hitung dan standar deviasi populasi. Perbedaan nilai statistik ini yang dikenal dengan kesalahan penarikan sampel (sampling error). Dengan menggunakan sampel bisa ditemukan kesalahan penarikan sampel pada saat hasil sampel tersebut digunakan untuk menduga parameter suatu populasi. Untuk menentukan tingkat keyakinan akan hasil menggunakan sampel untuk menduga parameter dapat dipahami dengan mentusun distribusi sampel (sampling distribution) dan rata-rata hitung sampel (sampel means). D. Distribusi Sampel rata-rata dan proporsi Distribusi sampel dari rata-rata hitung sampel dan populasi adalah suatu distribusi probabilitas yang terdiri dari seluruh kemungkinan rata-rata hitung sampel dari suatu ukuran sampel tertentu yang dipilih dari populasi, dan probabilitas terjadinya dihubungkan dengan setiap rata-rata hitung sampel. a. Distribusi sampel rata-rata dan proporsi menpunyai nilai hitung rat-rata: b. Distribusi sampel rata-rata dan proporsi mempunyai standar deviasi c. Hubungan antara standar deviasi sampel x dan proporsi pada kondisi sampel terbatas d. Hubungan standar deviasi sampel x dan proporsi pada kondisi sampel tidak terbatas e. Distribusi sampel rata-rata dan porposi merupakan distribusi normal, sehingga dapat diketahui nilai Znya yaitu E. Distribusi Sampel Selisih rata-rata dan proporsi Distribusi sampel selisih apabila terdapat dua atau lebih populasi yang diambil sebagai sampel a. Distribusi sampel selisih rata-rata Distribusi sampling selisih rata-rata adalah distribusi probabilitas yang dapat terjadi dari selisih rata-rata dua sampel yang berbeda berdasarkan pada dua
40 sampel tertentu dari ukuran parameter dua populasinya. Untuk ukuran sampel n 1 dan n 2 yang cukup besar (n 1, n 2 > 30), maka distribusi sampling selisih rata-rata sangat mendekati distribusi normal, untuk mengubahnya ke dalam bentuk normal standart. 1. Nilai rata-rata 2. Nilai standar deviasi 3. Nilai Z F. Distribusi Sampel Selisih Proporsi Distribusi sampling selisih proporsi adalah distribusi probabilitas yang dapat terjadi dari selisih proporsi dua sampel ang berbeda berdasarkan pada dua sampel tertentu dari ukuran parameter dua populasinya. 1. Nilai Rata-rata 2. Nilai Standar Deviasi 3. Nilai Z G. Faktor Koreksi untuk populasi terbatas Faktor koreksi adalah usaha untuk memperbaiki hasil dugaan parameter dan diterapkan jika rasio n/n lebih besar dari 0,05. faktor koreksi terhadap standar deviasi dirumuskan sebagai berikut sedang untuk standar deviasi proporsi
41
42 BAB 8 HIPOTESIS A. Hipotesis Hipotesa adalah suatu pernyataan mengenai nilai suatu parameter populasi yang dimaksudkan untuk pengujian dan berguna untuk pengambilan keputusan. Hipotesa sebenarnya disusun berdasarkan data, akan tetapi karena data tersebut dihasilkan dari sample yang mempunyai probabilitas, sehingga hasilnya bisa saja benar dan mungkin saja salah. Oleh sebab itu sebuah hipotesa sebelum menjadi keputusan haruslah diuji terlebih dahulu dengan menggunakan data observasi. Menurut Nasir (1988) hipotesa yang baik mempunyai ciri-ciri: a. menyatakan hubungan b. sesuai dengan fakta c. sederhana dan dapat diuji d. dapat menerangkan fakta dengan baik B. Pengujian Hipotesis Pengujian hipotesa adalah prosedur yang didasarkan pada bukti sampel yang dipakai untuk menentukan apakah hipotesa merupakan suatu pernyataan yang wajar dan oleh karenanya tidak ditolak, atau hipotesa tersebut tidak wajar dan oleh karena itu harus ditolak. C. Jenis Kesalahan Dalam Hipotesis Ada dua jenis kesalahan yang bias terjadi di dalam pengujian hipotesis. Kesalahan bisa terjadi karena kita menolak hipotesis nol padahal hipotesis nol itu benar atau menerima hipotesis nol padahal hipotesis nol itu salah. Kesalahan yang disebabkan karena kita menolak hipotesis nol padahal hipotesis nol itu benar disebut kesalahan jenis pertama atau type 1 error. Sebaliknya kesalahan yang disebabkan karena kita menerima hipotesis nol padahal hipotesis itu salah disebut kesalahan jenis 2 atau type 2 error. Tabel 8.1 Jenis kesalahan hipotesis PENGERTIAN KESALAHAN JENIS I DAN II Situasi Keputusan H0 Benar H0 Salah Terima H 0 Keputusan tepat (1 α) Kesalahan Jenis II (β) Tolak H 0 Kesalahan Jenis I (α) Keputusan tepat (1 β)
43 D. Prosedur Pengujian Hipotesa Langkah 1. Merumuskan Hipotesa (Hipotesa nol (H 0 ) dan Hipotesa Alternatif (H 1 )) Langkah 2. Menentukan Taraf Nyata (Probabilitas menolak hipotesa) Langkah 3. Menentukan Uji statistik (Alat uji statistik, uji Z, t, F, χ 2 dan lain-lain) Langkah 4. Menentukan Daerah Keputusan (Daerah di mana hipotesa nol diterima atau ditolak)) Langkah 5. Mengambil Keputusan Menerima H 0 Menerima H 1, Menolak H 0 Langkah 1 Merumuskan Hipotesis Perumusan hipotesa dikembangkan oleh Fisher yang dikenal sebagai Bapak Stastistik, yang membedakan hipotesa menjadi nol dan hipotesa alternative. Hipotesa nol (H 0 ) Satu pernyataan mengenai nilai parameter populasi Hipotesa alternative (H 1 ) Suatu pernyataan yang diterima jika data sampel memberikan cukup bukti bahwa hipotesa nol adalah salah Contoh: 1. Rata-rata penyebaran penyakit flu singapura tidak sama dengan 13,17%, maka H 0 : μ = 13,17% H 1 : μ 13,17% 2. Rata-rata IPK mahasiswa diatas 3 H 0 : IPK = 3 H 1 : IPK > 3 Langkah 2. menentukan taraf nyata Taraf nyata adalah Probabilitas menolak hipotesa nol apabila hipotesa nol tersebut adalah benar. Taraf nyata adalah nilai kritis yang digunakan sebagai dasar untuk menerima atau menolak hipotesa nol. Taraf nyata dilambangkan dengan α, dimana α = 1 C. C adalah tingkat keyakinan, apabila C = 0,95 maka taraf nyata 0,05. semakin tinggi tingkat keyakinan maka semakin kecil taraf nyata. Kebiasaan yang sering digunakan untuk penelitian sosial dan ekonomi adalah taraf nyata 5% atau tingkat keyakinan 95%.
44 Langkah 3. menentukan Uji Statistik Suatu nilai yang diperoleh dari sampel dan digunakan untuk memutuskan apakah akan menerima atau menolak hipotesa. Pada bagain ini akan dibahas uji Z, yang diperoleh dari rumus berikut: dimana : z x μ = Nilai Z = Rata -rata hitung sampel = Rata - rata hitung populasi Langkah 4. Menentukan daerah Keputusan Gambar 8.1 Daerah keputusan Pengujian satu arah Adalah daerah penolakan H 0 hanya satu yaitu terletak di ekor sebelah kanan saja atau ekor sebelah kiri saja. Karena hanya satu daerah penolakan berarti luas daerah penolakan tersebut sebesar taraf nyata yaitu a, dan untuk nilai kritisnya biasa ditulis dengan Za. Sedangkan pengujian dua arah Adalah daerah penolakan Ho ada dua daerah yaitu terletak di ekor sebelah kanan dan kiri. Karena mempunyai dua daerah, maka masing-masing daerah mempunyai luas ½ dari taraf nyata yang dilambangkan dengan ½α, dan nilai kritisnya biasa dilambangkan dengan Z ½α.
45 Langkah 5. mengambil Keputusan Keputusan ditentukan dengan melihat nilai Z, apabila terletak pada daerah yang menerima H 0 maka hipotesa dapat diterima atau sebaliknya apabila nilai Z tidak terletak pada daerah penerimaan H 0 maka hipotesa ditolak Contoh : Waktu rata-rata yang diperlukan permahasiswa untuk mendaftar ulang pada semester ganjil di suatu perguruan tinggi adalah 20 menit dengan simpangan baku 5 menit. Suatu prosedur pendaftaran baru yang menggunakan mesin antrian sedang dicoba. Bila sample 12 mahasiswa memerlukan waktu pendaftaran rata-rata 8 menit dengan simpangan baku 3,2 menit dengan system baru tersebut, ujilah hipotesis yang menyatakan bahwa rata-ratanya sekarang tidak sama dengan 20 menit. Gunakan α = 5%.

46 BAB 9 MENGUJI HIPOTESA RATA-RATA SAMPEL BESAR CONTOH PENGUJIAN DUA ARAH 1. Ujilah nilai rata-rata sama dengan 15,17%. Maka hipotesanya dirumuskan sebagai berikut: H 0 : µ = 15,17%. H 1 : µ 15,17%. 2. Ujilah nilai koefisien untuk b sama dengan 0. Maka hipotesanya dirumuskan sebagai berikut: H 0 : β = 0 H 1 : β 0. Gambar 9.1 Daerah keputusan MENGUJI HIPOTESA RATA-RATA DAN PROPORSI SAMPLE BESAR Ada Tiga hal yang terkait dengan pengujian hipotesa rata-rata dan porposi sample besar yaitu: a. Proses pengujian hipotesa, dimana pengujiannya tetap mengikuti 5 langkah b. Yang diuji dalam hal ini adalah rata-rata populasi dan proporsi dari populasi c. Sample besar. Sample besar adalh sample yang berjumlah 30 atau lebih. Dengan menggunakan sample besar diharapkan akan mendekati distribusi normal sehingga dapat digunakan nilai dan uji Z. CONTOH MENGUJI HIPOTESA RATA-RATA SAMPEL BESAR Dinas Kesehatan menyatakan bahwa penyebaran penyakit flu singapura rata-rata mencapai 13,17% untuk setiap daerah di wilayah kerjanya. Untuk menguji apakah pernyataan tersebut benar, maka lembaga konsultan YESS mengadakan penelitian pada 36 daerah di wilayah kerja Dinas Kesehatan dan didapatkan hasil bahwa rata-rata penyebaran flu singapura tiap daerah adalah 11,39% dan standar deviasinya 2,09%. Ujilah apakah pernyataan Dinas Kesehatan tersebut benar dengan taraf nyata 5%. Langkah 1 Merumuskan hipotesa. Hipotesa yang menyatakan bahwa rata-rata penyebaran penyakit flu singapura sama dengan 13,17% merupakan hipotesa nol, dan hipotesa alternatifnya
47 adalah rata-rata penyebaran penyakit flu singapura tidak sama dengan 13,17%. Hipotesa tersebut dapat dirumuskan sebagai berikut: H 0 : µ = 13,17%. H 1 : µ 13,17%. Langkah 2 Menentukan taraf nyata. Taraf nyata sudah ditentukan sebesar 5%, apabila tidak ada ketentuan dapat digunakan taraf nyata lain. Taraf nyata 5% menunjukkan probabilitas menolak hipotesa yang benar 5%, sedang probabilitas menerima hipotesa yang benar 95%. Nilai kritis Z dapat diperoleh dengan cara mengetahui probabilitas daerah keputusan H0 yaitu Zα/2 = α/2 0,5/2 = 0,025 dan nilai kritis Z dari tabel normal adalah 1,96. Langkah 3 Melakukan uji statistik dengan menggunakan rumus Z. Dari soal diketahui bahwa ratarata populasi = 13,17%, rata-rata sampel 11,39% dan standar deviasi 2,09%. Mengingat bahwa standar deviasi populasi tidak diketahui maka diduga dengan standar deviasi sampel, dan standar error sampel adalah S x = s/ n sehingga nilai Z adalah Langkah 4 Menentukan daerah keputusan dengan nilai kritis Z=1,96 Langkah 5 Mengambil Keputusan. Nilai uji Z ternyata terletak pada daerah menolak H 0. Nilai uji Z = 5,11 terletak disebelah kiri 1,96. Oleh sebab itu dapat disimpulkan bahwa menolak H 0, dan menerima H 1, sehingga pernyataan bahwa hasil rata-rata investasi sama dengan 13,17% tidak memiliki bukti yang cukup kuat. Gambar 9.2 Daerah keputusan MENGUJI HIPOTESIS PROPORSI SAMPEL BESAR Rumus uji Z untuk proporsi adalah
48 dimana: Z = Nilai uji Z p = Proporsi sampel P = Proporsi populasi N = jumlah sampel MENGUJI HIPOTESIS SELISIH RATA-RATA SAMPEL BESAR Distribusi sampling dari selisih rata-rata proporsi memiliki distribusi normal dan mempunyai standar deviasi sebagai berikut: Di mana: x1-x2 : Standar deviasi selisih dua populasi 1 : Standar deviasi populasi 1 2 : Standar deviasi populasi 2 n1 : Jumlah sampel pada populasi 1 n2 :Jumlah sampel pada populasi 2 sedangkan untuk rumus Z adalah sebagai berikut: Z : Nilai uji statistik x1 -x 2 : Selisih dua rata-rata hitung sampel 1 dan sampel : Selisih dua rata-rata hitung populasi 1 dan populasi 2 S x1-x2 : Standar deviasi selisih dua populasi standar deviasi selisih dua sampel adalah: Di mana: S x1-x2 : Standar deviasi selisih dua populasi s1 : Standar deviasi populasi 1 s2 : Standar deviasi populasi 2 n1 : Jumlah sampel pada populasi 1 n2 :Jumlah sampel pada populasi 2 MENGUJI HIPOTESA SELISIH PROPORSI SAMPEL BESAR Untuk standar deviasi proporsi populasi dirumuskan sebagai berikut:
49 sedangkan nilai uji Z dirumuskan sebagai berikut: standar deviasi selisih dua sampel Contoh soal : 1. Manajer pemasaran suatu produk kesehatan menyatakan tidak ada perbedaan volume penjualan rata-rata setiap bulan antara Pasar I dan Pasar II. Untuk membuktikan pernyataan tersebut diambil sampel mengenai volume penjualan selama 12 bulan terakhir di kedua pasar tersebut dan diperoleh informasi bahwa volume penjualan setiap bulan di Pasar I adalah 236 unit dengan standar deviasi 20 unit. Sedangkan volume penjualan setiap bulan pada periode tersebut di Pasar II adalah 200 unit dengan standar deviasi 30 unit. Dengan menggunakan tingkat signifikansi 5%, apakah sampel mendukung pernyataan bahwa tidak terdapat perbedaan volume penjualan di kedua pasar tersebut. 2. Empat puluh karyawan di PT. A dan 36 karyawan di PT. B dipilih secara random sebagai sampel untuk menguji dugaan bahwa upah rata-rata per hari di PT. A lebih tinggi daripada upah rata-rata per hari di PT. B. Berdasarkan sampel tersebut diperoleh informasi bahwa besarnya upah rata-rata per hari di PT. A adalah $80,0 dengan standar deviasi $1,6 dan di PT. B adalah $78,2 dengan standar deviasi $2,1. Dengan = 5%, apakah sampel mendukung dugaan bahwa upah rata-rata per hari di PT. A lebih tinggi daripada upah rata-rata per hari di PT. B. 3. Manajer produksi suatu perusahaan menyatakan bahwa persentase barang yang rusak dari dua jalur produksi (production lines) adalah sama. Untuk menguji pernyataan tersebut diambil sampel sebanyak 200 barang yang dihasilkan jalur produksi pertama dan ternyata terdapat 20 barang yang rusak. Sedangkan dari jalur produksi ke dua diambil sampel sebanyak 300 barang, ternyata ter-dapat 45 barang yang rusak. Dengan = 5%, apakah sampel yang diperoleh dapat digunakan sebagai bukti membenarkan pernyataan tersebut?
50 BAB 10 PENGUJIAN HIPOTESA SAMPEL KECIL Pada sampel kecil yaitu kasus dimana jumlah sampel kurang dari 30, maka nilai standar deviasi (s) berfluktuasi relatif besar, sehingga nilai uji Z tidak bersifat normal. Oleh karena itu, untuk sebaran distribusi sampel kecil dikembangkan suatu distribusi khusus yang dikenal sebagai distribusi t atau t-student. Nilai distribusi t dinyatakan sebagai berikut dimana: t = Nilai distribusi t = nilai rata-rata populasi x = nilai rata-rata sampel s = standar deviasi sampel n = jumlah sampel CIRI-CIRI DISTRIBUSI t-student a. Distribusi t-student seperti distribusi Z merupakan sebuah distribusi kontinu, di mana nilainya dapat menempati semua titik pengamatan. b. Distribusi t-student seperti c. distribusi Z berbentuk genta atau lonceng dan simetris dengan nilai rata-rata sama dengan 0. d. Distribusi t-student bukan merupakan satu kurva seperti kurva Z, tetapi keluarga dari distribusi t. Setiap distribusi t mempunyai rata-rata hitung sama dengan nol, tetapi dengan standar deviasi yang berbeda-beda, sesuai dengan besarnya sampel (n). Ada distribusi t untuk sampel berukuran 2, yang berbeda dengan distribusi untuk sampel sebanyak 15, 25 dan sebagainya. Apabila sampel semakin besar maka distribusi t akan mendekati normal. Tahap menguji rata-rata hitung populasi dalam sampel kecil : a) Merumuskan hipotesa nol dan hipotesa alternatif (H 0 dan H 1 ), b) Menentukan taraf nyata apakah 1%, 5% atau pada taraf lainnya serta mengetahui titik kritis berdasarkan pada tabel t-student, c) Menentukan uji statistik dengan menggunakan rumus uji-t, d) menentukan daerah keputusan yaitu daerah tidak menolak H 0 dan daerah menolak H 0, dan e) Mengambil keputusan untuk menolak dan menerima dengan membandingkan nilai kritis taraf nyata dengan nilai uji-t. CIRI DISTRIBUSI F
 df(20,7) df(5,5) Pada gambar di atas terlihat bahwa distribusi dengan derajat bebas pembilang 5 dan penyebut 5 yang ditulis df(5,5) mempunyai distribusi F yang berbeda dengan distribusi")
51 1. Distribusi F lebih mirip dengan distribusi t, yaitu mempunyai keluarga distribusi F. df(29,28) df(20,7) df(5,5) Pada gambar di atas terlihat bahwa distribusi dengan derajat bebas pembilang 5 dan penyebut 5 yang ditulis df(5,5) mempunyai distribusi F yang berbeda dengan distribusi df(20,7) dan df(29,28). 2. Distribusi F tidak pernah mempunyai nilai negatif sebagaimana pada distribusi Z. Distribusi Z mempunyai nilai positif di sisi kanan dan negatif sisi kiri nilai tengahnya. Distribusi F seluruhnya adalah positif atau menjulur ke positif (positively skewed) dan merupakan distribusi kontinu yang menempati seluruh titik di kurva distribusinya. 3. Nilai distribusi F mempunyai rentang dari tidak terhingga sampai 0. Apabila nilai F meningkat, maka distribusi F mendekati sumbu X, namun tidak pernah menyentuh sumbu X tersebut. 4. Distribusi F juga memerlukan syarat yaitu: (a) populasi yang diteliti mempunyai distribusi yang normal, (b) populasi mempunyai standar deviasi yang sama, dan (c) sampel yang ditarik dari populasi bersifat bebas serta diambil secara acak. Contoh : 1. Seorang peneliti ingin mengetahui apakah dengan pemberian aspirin mampu meredakan rasa sakit dalam waktu rata-rata 15 menit. Sehingga dilakukan pengambilan sample pada 10 pasien. Ujilah apakah pendapat dari peneliti tersebut benar. No. Waktu No. Waktu
52 BAB 11 UJI CHI-KUADRAT A. Statistika nonparametrik: Statistik yang tidak memerlukan pembuatan asumsi tentang bentuk distribusi atau bebas distribusi, sehingga tidak memerlukan asumsi terhadap populasi yang akan diuji Kapan kita dapat menggunakan statistik nonparametrik? 1. Apabila ukuran sampel sedemikian kecil sehingga distribusi sampel atau populasi tidak mendekati normal, dan tidak ada asumsi yang dapat dibuat tentang bentuk distribusi populasi yang menjadi sumber populasi. 2. Apabila hasil pengukuran menggunakan data ordinal atau data berperingkat. Data ordinal hanya menyatakan lebih baik, lebih buruk atau sedang atau bentuk ukuran lainnya. Data ini sama sekali tidak menyatakan ukuran perbedaan. 3. Apabila hasil pengukuran menggunakan data nominal. Data nominal hanya merupakan kode dan tidak mempunyai implikasi atau konsekuensi apa-apa. Jenis kelamin diberikan kode laki-laki dan perempuan, pengkodean tersebut tidak berimplikasi lebih rendah atau lebih tinggi, hanya sekadar kode. B. Chi Kuadrat untuk Uji Goodness of Fit Uji goodness of fit dikembangkan oleh Karl Pearson pada tahun 1900 dan ada yang menyebutnya dengan uji keselarasan. Rumus yang dikembangkan oleh Pearson adalah: dimana: X 2 = nilai chi-kuadrat fo = Frekuensi yang diperoleh fe = frekuensi yang diharapkan distribusi Chi-kuadrat berbeda dengan distribusi t dan F. Distribusi t dan F mempunyai distribusi probabilitas tunggal. Distribusi Chi-kuadrat merupakan suatu keluarga dari kurva bermacam distribusi yang bentuknya ditentukan oleh derajat bebasnya (df), dimana df tergantung dari jumlah sampel (n) dan jumlah variabel (k), df = n-k. Semakin besar nilai n maka distribusi chi-kuadrat akan mendekati kurva normal. Pada gambar dapat dilihat semakin banyak jumlah sampel maka kurva semakin mendekati normal. C. Uji Keselarasan (Goodness of Fit) Uji keselarasan adalah untuk menguji seberapa tepatkah frekuensi yang teramati (observed frequencies, fo) cocok atau sesuai dengan frekuensi yang diharapkan (expected frequencies, fe). Uji keselarasan dimaksudkan apakah ada kecocokan atau kesesuaian antara harapan dengan kenyataan.pada uji ini ada dua hal penting a. frekuensi yang diharapkan sama, apabila setiap data pengamatan nilai frekuensi yang diharapkan sama b. frekuensi yang diharapkan tidak sama
53 D. Uji keselarasan dengan Frekuensi Harapan sama Hasil perdagangan saham perusahaan obat pada minggu pertama 2016 adalah sebagai berikut: Tabel 11.1 Saham perusahan obat No Perusahaan Prosentase Perubahan Harga 1 Abbot 4 2 Aventis 10 3 Afifarma 56 4 Actavis -3 5 BioFarma 3 6 Bintang toedjo 29 7 Combiphar -3 8 Dexa Medica 9 9 Henson Farma Darya Varia 7 Untuk melakukan pengujian memerlukan beberapa tahapan atau langkah yaitu: 1. Menentukan hipotesa Hipotesa yang disusun adalah hipotesa nol (H 0 ) dan hipotesa alternatif (H 1 ). Hipotesa nol, H 0, menyatakan bahwa tidak ada perbedaan antara nilai atau frekuensi observasi atau teramati dengan nilai atau frekuensi harapan. Sedangkan hipotesa alternatif, H 1, menyatakan bahwa ada perbedaan antara nilai atau frekuensi teramati dengan nilai atau frekuensi yang diharapkan. Hipotesa selanjutnya dinyatakan sebagai berikut: H0 : fo = fe H1 : fo fe 2. Menentukan Taraf Nyata dan Nilai Kritis Untuk kasus ini, nilai n adalah kategori atau sampel yaitu 10, sedang k adalah variabel, dimana k= 1, jadi derajat bebasnya adalah df= 10-1= 9. Setelah menemukan nilai df dan taraf nyata, maka dapat dicari nilai kritis chi-kuadrat dengan menggunakan tabel chi-kuadrat sebagai berikut:
54 Taraf Nyata Df 0,1 0, Menentukan Daerah Keputusan Tabel 11.2 perhitunngan chi-square fo fe (fo-fe) (fo-fe) 2 (fo-fe) 2 /fe 3, ,15 83,8 6,4 9, ,13 9,8 0,4 55, , , , ,17 261,6 20,6 2, ,33 106,8 8,2 28, ,57 242,5 18,7-3, ,08 258, , ,45 19,8 1,5 9, ,24 10,5 0,8 6, ,33 40,1 5,1
55 4. Menentukan Keputusan Gambar 11.1 Daerah Keputusan 5. Langkah kelima adalah Kesimpulan. Berdasarkan aturan pada langkah ke-4, diketahui nilai chi-kuadrat hitung adalah 219,5 dan nilai chi-kuadrat kritis 16,919 berarti nilai chi-kuadrat hitung > dari chi kuadrat kritis. Dengan demikian Ho ditolak dan H 1 diterima. Jadi terdapat cukup bukti untuk menolak Ho, sehingga antara kenyataan yang terjadi dengan harapan dari analisis adalah tidak sama. E. Uji Chi-Kuadrat untuk uji Kenormalan Beberapa tahapan untuk uji kenormalitasan: 1. Membuat distribusi frekuensi. 2. Menentukan nilai rata-rata hitung μ dan standar deviasi σ dengan menggunakan data berkelompok. 3. Menentukan nilai Z dari setiap kelas, dimana Z = (X - μ)/σ 4. Menentukan probabilitas setiap kelas dengan menggunakan nilai Z. 5. Menentukan nilai harapan dengan mengalikan nilai probabilitas dengan jumlah data. 6. Menentukan pengujian chi-kuadrat untuk menentukan apakah suatu distribusi bersifat normal atau tidak. F. Uji chi-kuadrat untuk uji Independensi Langkah-langkah yang harus dilakukan: 1. Menyusun hipotesa. Hipotesa H 0 biasanya menyatakan tidak ada hubungan antara dua variabel, sedangkan H 1 menyatakan ada hubungan antara dua variabel. 2. Mengetahui nilai 2 kritis dengan taraf nyata dan derajat bebas df=(r - 1) x (c - 1) 3. Menentukan frekuensi harapan (fe) dimana fe untuk setiap sel dirumuskan 4.
56 IPK Tingkat Penghasilan (jutaan) Total <0.8 0, ,5-3,5 >3.5 > < Menentukan nilai χ 2 dengan Rumus : 6. Menentukan daerah kritis yaitu daerah penerimaan H 0 dan penolakan H 0 7. Menentukan keputusan apakah menerima H 0 atau menolak H 0. Contoh Soal: Ada keyakinan bahwa apabila IPK tinggi. maka akan mendapatkan penghasilan tinggi. Berdasarkan keyakinan tersebut. Nani dari YESS tahun 2015 melakukan penelitian terhadap 751 sarjana dari berbagai Sekolah Tinggi Kesehatan yang bekerja disektor Kesehatan di Jawa Timur. Berikut adalah hasilnya Dari data tersebut. apakah keyakinan adanya hubungan antara IPK dengan tingkat penghasilan dapat dibenarkan? Fo Fe (fo-fe) 2 /fe , , , , , , , , , , , ,49 χ 2 = (fo - fe) 2 /fe 8,68 1. Hipotesa. H 0 : tidak ada hubungan antara acara tingkat penghasilan dengan IPK. H 1 ada hubungan antara tingkat penghasilan dengan IPK.
57 2. Menentukan nilai kritis. df= (c - 1)(r - 1)= (3-1)(4-1) = 6 dengan taraf nyata 5% adalah Nilai chi-kuadrat hitung = 8.68 < dari chi-kuadrat tabel , dengan demikian H 0 diterima dan H 1 ditolak. Jadi tidak ada hubungan antara tingkat penghasilan dengan IPK
58 BAB 12 DATA STATISTIK A. Pengertian Statistik Pada awal mulanya kata statistik di gunakan oleh Gottfriet Achmenwall ( ). Kemudian Dr. E.A.W. Zimmerman memperkenalkan kata statistic ke negeri Inggris, selanjutnya kata statistic itu di populerkan oleh Sir Jhon Sinclaer. Secara etimologi kata statistic berasal dari bahasa Italia statista yang berarti negarawan atau ahli kenegaraan. Karena sejak dahulu kala statistic hanya di gunakan untuk kepentingan Negara saja. Kita sering mendengar statistik dan statistika itu sama dalam artian pasti berhubungan dengan angka. Statistik adalah kumpulan data mengenai suatu permasalahan sehingga dapat memberikan suatu gambaran dari permasalahan tersebut. Statistika adalah suatu metode ilmiah yang mempelajari teknik pengumpulan data, penghitungan, penggambaran, pengaturan data di sertai pengaturan kesimpulan yang valid dari penganalisaan yang di lakukan serta pembuatan keputusan secara rasional. Berdasarkan tingkat atau tahapan kegiatan, statistic dapat di bagi menjadi dua golongan, yaitu : 1. Statistik Deskriptif atau statistik deduktif Yaitu kegiatan statistik yang di mulai dari menghimpun data, menyusun atau mengatur data, mengolah data, menyajikan dan mengolah data guna memberikan gambaran tentang suatu gejala, peristiwa atau keadaan. 2. Statistik Inferensial atau statistic induktif Yaitu statistic yang menyediakan aturan atau cara yang dapat di gunakan untuk menarik kesimpulan (conclusion), membuat ramalan (forecast) dan penaksiran (estimation) dsb. B. Data Statistik Data adalah segala fakta dan angka yang dapat dijadikan bahan untuk menyusun suatu informasi (Suharsimi Arikunto, 2002). Data merupakan materi mentah yang membentuk semua laporan penelitian (Dempsey dan Dempsey, 2002). Data berbentuk jamak sedangkan bentuk tunggalnya adalah datum. Jadi data sama dengan datum-datum. Data statistik ialah data yang berwujud angka, namun tidak semua angka di sebut data statistik. Suatu angka atau bilangan di sebut data statistik bila angka itu menunjukkan suatu ciri dari suatu penelitian yang bersifat agregatif yaitu pencatatan yang di lakukan lebih dari satu kali pada satu individu serta mencerminkan suatu kegiatan dalam bidang tertentu. Pengenalan jenis-jenis data statistic sangat penting, karena menyangkut pilihan instrument pengumpul data yang akan di gunakan dan menentukan pilihan teknik analisis yang akan digunakan. Dari sudut pandang statistic data dapat dibagi menjadi dua yaitu : 1. Data kualitatif Data yang dinyatakan bukan dalam bentuk angka. Contohnya adalah Jenis kelamin (laki-laki, perempuan), program studi (ilmu kesehatan masyarakat, ilmu pendidikan ners, kebidanan, analist, dsb). Data kualitatif dapat diolah dan dianalisis dengan statistik tetapi harus diubah kedalam data kuantitatif. 2. Data kuantitatif
59 Data kuantitatif adalah data yang dinyatakan dalam bentuk angka. Misalnya tinggi badan, kadar gula darah, kadar kolesterol, nilai ujian. Berdasarkan skala pengukurannya Data yang merupakan hasil pengukuran variabel memiliki jenis skala pengukuran sebagaimana yang terdapat pada variabel. Dengan demikian berdasarkan tinjauan ini, data dapat dibedakan menjadi : 1) data nominal Data nominal di sebut juga data deskrit atau data kategorik, yaitu data statistic yang cara penyusunannya di klasifikasikan dalam beberapa kategori saling lepas (mutual exlusive) dan tuntas (exhaustive). Masing-masing kategori memiliki kategori yang sama. Data nominal termasuk data yang memiliki tingkat yang paling rendah dibandingkan dengan jenis data statistik yang lain. Contoh : warna kulit, agama, jenis minuman 2) data ordinal Data ordinal adalah data statistik yang diurutkan dari jenjang yang paling rendah sampai ke jenjang yang paling tinggi atau sebaliknya dari jenjang yang paling tinggi sampai yang paling rendah, dan dalam bentuk kategori atau klasifikasi. Ciri data ordinal adalah : a. Dalam bentuk kategori b. Posisi data tidak setara atau bertingkat c. Tidak bisa dilakukan operasi matematika Contoh : pengetahuan (baik, cukup, kurang), Rangking (I, II, III, IV), Tingkat nyeri (Nyeri berat, Nyeri sedang, nyeri ringan, tidak nyeri) 3) data interval Data interval adalah data statistic yang mempunyai jarak yang sama diantara hal-hal yang sedang di selidiki. Ciri khas data interval adalah : a. satuan ukurannya mempunyai skala yang sama b. antar kategori data dapat ketahui selisihnya c. tidak memiliki nilai 0 (nol) mutlak d. Data interval tidak dapat di bandingkan Contoh : nilai skor yang didapatkan dari kuesioner, nilai ujian ( rentang nilai 0 100) atau (0 10). Pada contoh nilai ujian missal si A mendapat 50 dan si B mendapat nilai 100 tidak bisa di katakana bahwa si B dua lebih pandai dari si A. 4) data rasio Data ratio merupakan jenis data statistic yang menempati posisi tertinggi di bandingkan dengan jenis data statistic yang menempati posisi tertinggi di bandingkan dengan jenis data statistik yang lain. Ciri-ciri data ratio adalah: a. Data diperoleh merupakan hasil pengukuran, dimana jarak dua titik pada skala di ketahui dari alat ukurnya. b. Dapat di ketahui selisihnya c. Data dapat di bandingkan d. Memiliki nilai nol (0) mutlak Contoh : berat badan (50 kg, 75kg, 90 kg), tinggi badan (170 cm, 130 cm). Data pada skala ratio dapat di bandingkan. Misalnya A memiliki berat badan 60 kg, dan B memiliki berat badan 120 kg, maka dapat dikatakan bahwa berat badan B 2 kali daripada berat badan A.
60 Statistika Deskriptif dan Inferensia Statistika deskriptif melakukan proses pengumpulan data sampai dengan penyajiannya/presentasi. Statistika deskriptif berkaitan dengan pencatatan dan peringkasan data, dengan tujuan menggambarkan hal-hal penting pada sekelompok data. Contohnya menampilkan rata-rata, variansi, menampilkan dalam bentuk diagram atau tabel. Statistika inferentia melakukan proses pengumpulan data sampai dengan melakukan pendugaan terhadap populasi. Inferensia melakukan generalisasi terhadap populasi. Statistika inferensia berkaitan dengan pengambilan keputusan dari data yang telah dicatat dan diringkas tersebut. Adapun contoh statistika inferensia Diambil 15 sampel mahasiswa putri di sebuah sekolah tinggi kemudian diukur kadar hb-nya, diketahui rata-rata kadar Hb 10,1. Maka bisa disimpulkan bahwa rata-rata kadar Hb mahasiswa sekolah tinggi tersebut (sebagai populasi) adalah 10.5 Diambil sampel 180 laki-laki dan perempuan yang bekerja pada sebuah kantor yang memiliki 400 karyawan. Dari proses statitika inferentia pada 180 sampel tersebut didapatkan perbedaan antara laki-laki dan perempuan pada motivasi bekerja mereka. Maka bisa disimpulkan bahwa rata-rata motivasi kerja laki-laki dan perempuan dikator tersebut memang berbeda. Mungkin saja motivasi laki-laki dalam bekerja lebih tinggi dibandingkan perempuan atau sebaliknya. Dengan demikian, jika pengambilan sebuah sampel adalah salah,atau penggunaan metode statistic tertentu pada sebuah sampel adalah salah, maka akan berakibat kesalahan dalam pengambilan keputusan secara umum terhadap populasi. Beberapa kemungkinan bisa terjadi : Pengambilan sampel yang salah akan mengakibatkan keputusan yang bisa salah. Seperti mengambil 15 sampel pada mahasiswa yang kebetulan kadar hbnya kurang dari 10, akan mengakibatkan kesimpulan yang salah, jika kebanyakan isi populasi justru kadar hbnya diatas 10. Pengambilan sampel sudah benar, namun metode statistic inferenti yang diterapkan salah, keputusan yang diambil juga bisa salah. Seperti membandingkan motivasi laki-laki dan perempuan yang seharusnya kedua sampel tersebut independent satu sama lain, namun diperlakukan sebagai satu sampel saja, maka keputusan bisa saja salah. Statistika Parametrik dan Non Parametrik Analisa Statistika Parametrik adalah analisis statistika untuk jenis skala Data Interval (yang memenuhi asumsi normal) dan Ratio sedangkan analisa Statistika Non Parametrik adalah analisis statistika untuk Jenis Skala data Nominal dan Ordinal dan interval yang tidak normal. Adapun konsep kaidah penggunaan analisis statistika inferensia bisa dilihat pada gambar 14.1 Sumber data statistik dapat di peroleh dari manusia, hewan, tumbuh-tumbuhan, benda, dan gejala atau peristiwa yang terjadi di sekitar kita. Data dapat di kumpulkan langsung oleh peneliti dari pihak yang bersangkutan atau di sebut juga sumber primer, atau data di peroleh dari pihak lain (pihak kedua) atau di

61 sebut juga teknik sekunder. Metode-metode pengumpulan data yang sesuai dan banyak digunakan dalam penelitian social, keagamaan, dan lain-lain meliputi: observasi, wawancara, quesioner dan penggalian data dari sumber-sumber sekunder. 1. Observasi Gambar 14.1 Bagan Parametrik dan Non Parametrik Sumber data statistik dapat di peroleh dari manusia, hewan, tumbuh-tumbuhan, benda, dan gejala atau peristiwa yang terjadi di sekitar kita. Data dapat di kumpulkan langsung oleh peneliti dari pihak yang bersangkutan atau di sebut juga sumber primer, atau data di peroleh dari pihak lain (pihak kedua) atau di sebut juga teknik sekunder. Metode-metode pengumpulan data yang sesuai dan banyak digunakan dalam penelitian social, keagamaan, dan lain-lain meliputi: observasi, wawancara, quesioner dan penggalian data dari sumber-sumber sekunder. Observasi merupakan metode pengumpulan data yang palin galamiah dan paling banyak digunakan tidak hanya dalam dunia keilmuan, tetapi juga dalam berbagai aktivitas kehidupan. Secara umum, observasi berarti pengamatan, penglihatan. Sedangkan secara khusus, dalam dunia penelitian, observasi adalah mengamati dan mendengar dalam rangka memahami, mencari jawaban, mencari bukti terhadap fenomena sosial keagamaan (perilaku, kejadian-kejadian, keadaan, benda, dan simbol-simbol tertentu) selama beberapa waktu tanpa mempengaruhifenomena yang diobservasi, dengan mencatat, merekam, memotret fenomena tersebut guna penemuan data analisis. 2. Wawancara Pengertian dan macam-macam wawancara Wawancara adalah percakapan langsung dan tatap muka (face to face)dengan maksud tertentu. Percakapan itu dilakukan oleh dua pihak, yaitu pewawancara (interviewer)
62 yang mengajukan pertanyaan dan yang diwawancarai (interviewee) yang memberikan jawaban atas pertanyaan itu. Maksud mengadakan wawancara secara umum adalah untuk menggali struktur kognitif dan dunia makna dari perilaku subjek yang diteliti. Pembagian macam-macam wawancara yang dikemukakan oleh Patton (1980:197), yaitu: a. Wawancara pembicaraan informal Pada jenis wawancara ini pertanyaan yang diajukan sangat bergantung pewawancara itu sendiri, bergantung spontanitasnya dalam mengajukan pertanyaan kepada yang diwawancarai. b. Petunjuk umum menggunakan petunjuk wawancara Jenis wawancara ini mengharuskan pewawancara membuat kerangka dan garis besar pokok-pokok yang akan ditanyakan dalam proses wawancara. Petunjuk wawancara hanyalah berisi petunjuk secara garis besar tentang proses dan isi wawancara untuk menjaga agar pokok-pokok yang dibicarakan dapat tercakup seluruhnya. Petunjuk itu didasarkan atasanggapan bahwa ada jawaban yang secara umum akan sama diberikan oleh para responden. Pelaksanaan wawancara dan pengurutan pertanyaan disesuaikan dengan keadaan responden dan konteks wawancara yang sebenarnya. c. Wawancara Baku terbuka Jenis wawancara ini adalah wawancara yang menggunakan seperangkat pertanyaan baku. Dalam mengadakan pendalaman (probing) terbatas, dan hal itu bergantung situasi wawancara dan kecakapan wawancara. C. Penyajian Data Data yang di kumpulkan dengan menggunakan teknik pengumpulan data baik dari data sumber primer maupun sumber sekunder perlu di sajikan dalam bentuk yang jelas sehingga mudah untuk di baca dan dianalisis. Distribusi (distribution) memiliki arti pembagian atau pencaran. Frekuensi (frequency) berarti kekerapan atau keseringan. Jadi distribusi frekuensi berarti pembagian nilai menurut kelompok atau kategori masingmasing yang dimuat di dalam kolom dan lajur. Menurut bentuk datanya, distribusi frekuensi dibagi menjadi 2, yaitu distribusi untuk data tunggal dan distribusi untuk data kelompok. Ukuran gejala pusat adalah suatu ukuran yang digunakan untuk mengetahui kumpulan data mengenai sampel atau populasi yang disajikan dalam tabel dan diagram, yang dapat mewakili sampel atau populasi. Ada beberapa macam ukuran tendensi sentral,yaitu rata-rata (mean), median, modus. 1. Pada Data tunggal x a. Rata-rata dapat di hitung : x b. Varians dapat di hitung : c. Median dapat di hitung s 2 n x i x n 1 2
63 ( ) d. Modus : nilai yang paling sering muncul 2. Pada Data Kelompok (dalam distribusi frekuensi) Penyajian data statistic dalam bentuk distribusi frekuensi data kelompok dilakukan apabila penyebaran data atau nilai terlalu luas, atau nilai tertinggi dengan nilai terendah memiliki range yang terlalu besar. Langkah-langkah dalam membuat table frekuensi adalah sebagai berikut : a. Mencari nilai tertinggi (H) dan nilai terendah (L). b. Menetapkan nilai penyebarannya (Range = R) dengan rumus R = H L c. Menentukan banyak kelas interval yang diperlukan. Banyak kelas interval biasanya dipilih paling sedikit 5 dan paling banyak 15, atau sesuai dengan kebutuhan, atau dapat menggunakan aturan Sturges, yaitu : Banyak kelas = 1 + (3.3) log n d. Menentukan panjang kelas dengan rumus : e. Pilih Ujung Kelas Interval Pertama, untuk ini bisa diambil sama dengan data terkecil atau nilai data yang lebih kecil dari data terkecil tetapi selisihnya harus kurang dari panjang kelas yang telah di tentukan. Selanjutnya daftar diselesaikan dengan menggunakan harga-harga yang telah di hitung. a. Rata-rata dapat dihitung : f x i b. Varians dapat di hitung : c. Modus : Dimana : s 2 X f i i f i x i x n 1 banyakkela f 1 M b p o f f 1 2 a. b adalah batas bawah kelas modus, kelas interval dengan frekuensi terbanyak. b. p adalah panjang kelas modus c. f 1 frekuensi kelas modus frekuensi kelas interval dengan tanda kelas < sebelum tanda kelas modus d. f 2 frekuensi kelas modus frekuensi kelas interval dengan tanda kelas > sesudah tanda kelas modus 2 p R s e. Median M e b p 1 2 f n F med
64 F adalah jumlah semua frekuensi dengan tanda kelas < dari tanda kelas median f adalah frekuensi median f. Kuartil Letak K i K i datake in F 4 b p f i n 1 4 Contoh soal : 1. Data dibawah ini adalah nilai ujian Biostatistika 50 mahasiswa suatu Perguruan tinggi. Interval nilai Tentukan rata-rata, median, modus, dan kuartil f
65 BAB 13 KORELASI BIVARIATE A. Pengertian Korelasi Apa sebenarnya korelasi itu? Korelasi merupakan teknik analisis yang termasuk dalam salah satu teknik pengukuran asosiasi / hubungan (measures of association). Pengukuran asosiasi merupakan istilah umum yang mengacu pada sekelompok teknik dalam statistik bivariat yang digunakan untuk mengukur kekuatan hubungan antara dua variabel. Diantara sekian banyak teknik-teknik pengukuran asosiasi, terdapat dua teknik korelasi yang sangat populer sampai sekarang, yaitu Korelasi Pearson Product Moment dan Korelasi Rank Spearman. Pengukuran asosiasi mengenakan nilai numerik untuk mengetahui tingkatan asosiasi atau kekuatan hubungan antara variabel. Dua variabel dikatakan berasosiasi jika perilaku variabel yang satu mempengaruhi variabel yang lain. Jika tidak terjadi pengaruh, maka kedua variabel tersebut disebut independen. Korelasi (correlation) dalam ilmu statistic berarti hubungan antara dua variable atau lebih. Hubungan antara dua variable di sebut korelasi bivariate (bivariate correlation). Contohnya hubungan antara pengetahuan mengenai bahaya merokok dengan perilaku merokok. Korelasi lebih dari dua variable di sebut multivariate correlation. B. Koefisien Korelasi Dalam kehidupan sehari-hari sering kita menjumpai dua peubah atau lebih yang bergantung. Sebagai contoh, kita mungkin menemukan sesuatu hal yang memperlihatkan adanya suatu pertambahan pada peubah X yang dibarengi dengan pertambahan pada peubah Y. Bila dapat ditunjukkan perubahan pada satu peubah yang berhubungan dengan peubah lain, maka kedua peubah itu dapat dikatakan berkorelasi. Korelasi dikatakan positif apabila penambahan pada peubah X akan menyebabkan penambahan pada variable Y, sebaliknya korelasi dikatakan negatif jika penambahan pada peubah X menyebabkan berkurangnya variable Y. Korelasi erat antara dua peubah tidak harus berarti suatu sebab akibat. Korelasi yang berarti, mungkin menunjukkan kemungkinan semacam itu bagi peneliti, tetapi petunjuk atau fakta yang mendukung dari sumber lain harus diketemukan sebelum simpulan yang menyangkut sebab-akibat dijamin. Korelasi bermanfaat untuk mengukur kekuatan hubungan antara dua variabel (kadang lebih dari dua variabel) dengan skala-skala tertentu, misalnya Pearson data harus berskala interval atau rasio; Spearman dan Kendal menggunakan skala ordinal. Kuat lemah hubungan diukur menggunakan jarak (range) 0 sampai dengan 1. Korelasi mempunyai kemungkinan pengujian hipotesis dua arah (two tailed). Korelasi searah jika nilai koefesien korelasi diketemukan positif; sebaliknya jika nilai koefesien korelasi negatif, korelasi disebut tidak searah. Yang dimaksud dengan koefesien korelasi ialah suatu pengukuran statistik kovariasi atau asosiasi antara dua variabel. Jika koefesien korelasi diketemukan tidak sama dengan nol (0), maka terdapat hubungan antara dua variabel tersebut. Jika koefesien korelasi diketemukan +1. maka hubungan tersebut disebut sebagai korelasi sempurna atau hubungan linear sempurna dengan kemiringan (slope) positif. Sebaliknya. jika koefesien korelasi diketemukan -1. maka hubungan tersebut disebut sebagai korelasi
66 sempurna atau hubungan linear sempurna dengan kemiringan (slope) negatif. Dalam korelasi sempurna tidak diperlukan lagi pengujian hipotesis mengenai signifikansi antar variabel yang dikorelasikan, karena kedua variabel mempunyai hubungan linear yang sempurna. Artinya variabel X mempunyai hubungan sangat kuat dengan variabel Y. Jika korelasi sama dengan nol (0), maka tidak terdapat hubungan antara kedua variabel tersebut. Korelasi dinyatakan dengan koefisien (r) dan merentang dari 1 sampai +1. Koefisien 1, dengan tanda + atau -, menunjukkan korelasi sempurna antara dua peubah. Sebaliknya, koefisien nol berarti tidak ada korelasi sama sekali. Jika koefisien korelasi (r) dikuadratkan, didapat koefisien penentu (r 2 ). Nilai ini dapat digunakan sebagai taksiran untuk kekuatan antara kaitan antara dua peubah yang berkorelasi. Koefisien penentu khususnya menaksir persentase keragaman X yang berkaitan dengan (atau diterangkan oleh) keragaman Y atau sebaliknya. Misal diketahui korelasi sebesar menunjukkan suatu hubungan linier yang amat baik antara X dan Y. Karena r 2 = maka dapat dikatakan bahwa hampir 96% dari variasi dalam Y disebabkan oleh hubungan linier dengan X. Untuk memudahkan melakukan interpretasi mengenai kekuatan hubungan antara dua variabel penulis memberikan kriteria sebagai berikut (Sarwono : 2006): 0 : Tidak ada korelasi antara dua variabel >0 0,25: Korelasi sangat lemah >0,25 0,5: Korelasi cukup >0,5 0,75: Korelasi kuat >0,75 0,99: Korelasi sangat kuat 1: Korelasi sempurna C. Interpretasi dalam korelasi Apa sebenarnya signifikansi itu? Dalam bahasa Inggris umum, kata, "significant" mempunyai makna penting; sedang dalam pengertian statistik kata tersebut mempunyai makna benar tidak didasarkan secara kebetulan. Hasil riset dapat benar tapi tidak penting. Signifikansi / probabilitas / α memberikan gambaran mengenai bagaimana hasil riset itu mempunyai kesempatan untuk benar. Jika kita memilih signifikansi sebesar 0,01, maka artinya kita menentukan hasil riset nanti mempunyai kesempatan untuk benar sebesar 99% dan untuk salah sebesar 1%. 99% itu disebut tingkat kepentingan (confidence interval); sedang 1% disebut toleransi kesalahan. Secara umum kita menggunakan angka signifikansi sebesar 0,01; 0,05 dan 0,1. Pertimbangan penggunaan angka tersebut didasarkan pada tingkat kepercayaan (confidence interval) yang diinginkan oleh peneliti. Angka signifikansi sebesar 0,01 mempunyai pengertian bahwa tingkat kepercayaan atau bahasa umumnya keinginan kita untuk memperoleh kebenaran dalam riset kita adalah sebesar 99%. Jika angka signifikansi sebesar 0,05, maka tingkat kepercayaan adalah
67 sebesar 95%. Jika angka signifikansi sebesar 0,1, maka tingkat kepercayaan adalah sebesar 90%. Pertimbangan lain ialah menyangkut jumlah data (sample) yang akan digunakan dalam riset. Semakin kecil angka signifikansi, maka ukuran sample akan semakin besar. Sebaliknya semakin besar angka signifikansi, maka ukuran sample akan semakin kecil. Unutuk memperoleh angka signifikansi yang baik, biasanya diperlukan ukuran sample yang besar. Untuk pengujian dalam IBM SPSS digunakan kriteria sebagai berikut: Jika angka signifikansi hasil penelitian 0,05, maka hubungan kedua variabel signifikan. Jika angka signifikansi hasil penelitian > 0,05, maka hubungan kedua variabel tidak signifikan Atau jika pengujian menggunakan penghitungan secara manual maka dapat melihat table dengan kriteria sebagai berikut : Jika nilai hitung hasil penelitian nilai tabel, maka hubungan kedua variabel signifikan. Jika nilai hitung hasil penelitian < nilai tabel, maka hubungan kedua variabel tidak signifikan Ada tiga penafsiran hasil analisis korelasi, meliputi: pertama, melihat kekuatan hubungan dua variabel; kedua, melihat signifikansi hubungan; dan ketiga, melihat arah hubungan. Untuk melakukan interpretasi kekuatan hubungan antara dua variabel dilakukan dengan melihat angka koefesien korelasi hasil perhitungan dengan menggunakan kriteria sbb: a) Jika angka koefesien korelasi menunjukkan 0, maka kedua variabel tidak mempunyai hubungan; b) Jika angka koefesien korelasi mendekati 1, maka kedua variabel mempunyai hubungan semakin kuat; c) Jika angka koefesien korelasi mendekati 0, maka kedua variabel mempunyai hubungan semakin lemah; d) Jika angka koefesien korelasi sama dengan 1, maka kedua variabel mempunyai hubungan linier sempurna positif; e)jika angka koefesien korelasi sama dengan -1, maka kedua variabel mempunyai hubungan linier sempurna negatif. Interpretasi berikutnya melihat signifikansi hubungan dua variabel dengan didasarkan pada angka signifikansi yang dihasilkan dari penghitungan dengan ketentuan sebagaimana sudah dibahas di atas. Interpretasi ini akan membuktikan apakah hubungan kedua variabel tersebut signifikan atau tidak. Interpretasi ketiga melihat arah korelasi. Dalam korelasi ada dua arah korelasi, yaitu searah dan tidak searah. Pada IBM SPSS hal ini ditandai dengan pesan two tailed. Arah korelasi dilihat dari angka koefesien korelasi. Jika koefesien korelasi positif, maka hubungan kedua variabel searah. Searah artinya jika variabel X nilainya tinggi, maka variabel Y juga tinggi. Jika koefesien korelasi negatif, maka hubungan kedua variabel tidak searah. Tidak searah artinya jika variabel X nilainya tinggi, maka variabel Y akan rendah. Dalam kasus, misalnya hubungan antara kepuasan pelanggan dan loyalitas sebesar 0,86 dengan angka signifikansi sebesar 0,000 akan mempunyai makna bahwa hubungan antara variabel kepuasan pelanggan dan loyalitas sangat kuat, signifikan dan searah. Sebaliknya dalam kasus hubungan antara variabel pengetahuan dengan perilaku terhadap kebiasan merokok
68 sebesar -0,86, dengan angka signifikansi sebesar 0; maka hubungan kedua variabel sangat kuat, signifikan dan tidak searah. D. Macam Korelasi dan Teknik Penghitungan 1. Teknik Korelasi Pearson (Product Moment) Korelasi Pearson Product Moment, yang merupakan pengukuran parametrik, akan menghasilkan koefesien korelasi yang berfungsi untuk mengukur kekuatan hubungan linier antara dua variable. Jika hubungan dua variable tidak linier, maka koefesien korelasi Pearson tersebut tidak mencerminkan kekuatan hubungan dua variable yang sedang diteliti; meski kedua variable mempunyai hubungan kuat. Simbol untuk korelasi Pearson adalah "p" jika diukur dalam populasi dan "r" jika diukur dalam sampel. Korelasi Pearson mempunyai jarak antara -1 sampai dengan + 1. Jika koefesien korelasi adalah -1, maka kedua variable yang diteliti mempunyai hubungan linier sempurna negatif. Jika koefesien korelasi adalah +1, maka kedua variable yang diteliti mempunyai hubungan linier sempurna positif. Jika koefesien korelasi menunjukkan angka 0, maka tidak terdapat hubungan antara dua variable yang dikaji. Jika hubungan dua variable linier sempurna, maka sebaran data tersebut akan membentuk garis lurus. Sekalipun demikian pada kenyataannya kita akan sulit menemukan data yang dapat membentuk garis linier sempurna. Data yang digunakan dalam Korelasi Pearson sebaiknya memenuhi persyaratan, diantaranya ialah: a) Berskala interval / rasio, b) Variabel X dan Y harus bersifat independen satu dengan lainnya, c) Variabel harus kuantitatif simetris. Asumsi dalam Korelasi Pearson, diantaranya ialah: a) Terdapat hubungan linier antara X dan Y, b) Data berdistribusi normal, c) Variabel X dan Y simetris. Variabel X tidak berfungsi sebagai variabel bebas dan Y sebagai variable tergantung, d) Sampling representative, e) Varian kedua variable sama. Rumus yang bisa di gunakan untuk menghitung korelasi product moment adalah sebagai berikut : x x y y 1 r dimana n 1 S y y Y s x s n 1 y Sehingga untuk mencari nilai S x dapat menggunakan rumus yang sama dengan S y tetapi menggunakan variable X Contoh soal : Misalnya ingin diketahui apakah terdapat hubungan antara nilai statistika dengan nilai aplikasi komputer. Dengan hasil penelitian sebagai berikut : No X Y
69 Dimana Total = 19.2 Selanjutnya memberikan interpretasi dengan menyusun hipotesis dimana : H 0 : tidak ada hubungan antara nilai statistika dengan nilai aplikasi computer ( ) H 1 : ada hubungan antara nilai statistika dengan nilai aplikasi komputer ( ) Membandingkan nilai r hitung dengan nilai r table yang di dapatkan sebesar 0,754 (0,382 < 0,754) sehingga memberikan kesimpulan terima H 0, yang artinya tidak ada hubungan antara nilai biostatistika dengan nilai aplikasi computer. 2. Teknik Korelasi Tata Jenjang (Spearman) Korelasi Spearman merupakan pengukuran non-parametrik. Koefesien korelasi ini mempuyai simbol r (rho). Pengukuran dengan menggunakan koefesien korelasi Spearman digunakan untuk menilai adanya seberapa baik fungsi monotonik (suatu fungsi yang sesuai perintah) arbitrer digunakan untuk menggambarkan hubungan dua variabel dengan tanpa membuat asumsi distribusi frekuensi dari variabel-variabel yang diteliti. Nilai koefesien korelasi dan kriteria penilaian kekuatan hubungan dua variabel sama dengan yang digunakan dalam korelasi Pearson. Penghitungan dilakukan dengan cara yang sama dengan korelasi Pearson, perbedaan terletak pada pengubahan data kedalam bentuk ranking sebelum dihitung koefesien korelasinya. Itulah sebabnya korelasi ini disebut sebagai Korelasi Rank Spearman. Data yang digunakan untuk korelasi Spearman harus berskala ordinal. Berbeda dengan Korelasi Pearson, Korelasi Spearman tidak memerlukan asumsi adanya hubungan linier dalam variable-variabel yang diukur dan tidak perlu menggunakan data berskala interval, tetapi cukup dengan menggunakan data berskala ordinal. Asumsi yang digunakan dalam korelasi ini ialah tingkatan (rank) berikutnya harus menunjukkan posisi jarak yang sama pada variable-variabel yang diukur. Jika menggunakan skala Likert, maka jarak skala yang digunakan harus sama. Juga, data tidak harus berdistribusi normal. Rumus yang bisa di gunakan untuk menghitung korelasi tata jenjang adalah sebagai berikut: 2 6 X Y rs 1 dimana X dan Y adalah data yang sudah di rangking n n 2 1 Contoh soal : Suatu penelitian dilakukan untuk mengatahui apakah ada hubungan tingkat kelahiran hiperbilirubin dengan tingkat keteraturan ibu hamil dalam meminum obat. Untuk itu dilakukan pengambilan data pada sebagian ibu hamil trisemester 3 di puskesmas wilayah X. Kejadian hiperbilirubin dikategorikan menjadi 3 :
70 hiperbilirubin grade 1; 2 : hiperbilirubin grade 2; 1 : normal. Sedangkan tingkat keteraturan dikategorikan menjadi : 3 : teratur, 2: cukup, dan 1 : tidak teratur. Dan didapatkan data sebagai berikut : (x) (y) Rank (x) Rank (y) (x y) (x y) , , , , , , , , Total 374 Cara memberikan ranking pada variable a. Data diurutkan dari yang terkecil yang terbesar b. Cara memberikan ranking adalah dengan menjumlahkan banyaknya data yang sama di bagi dengan jumlah data yang sama sehingga pada variable x cara mendapatkan rangkingnya seperti : Gunakan cara yang sama untuk mendapatkan rangking selanjutnya Sehingga : Selanjutnya memberikan interpretasi dengan menyusun hipotesis dimana H 0 : tidak ada hubungan antara kejadian hiperbilirubin dengan keteraturan minum obat ( ) H 1 : ada hubungan antara kejadian hiperbilirubin dengan keteraturan minum obat ( ) Membandingkan nilai r hitung dengan nilai r table yang di dapatkan sebesar 0,618 (-0,700 > 0,618) sehingga memberikan kesimpulan tolak H 0, yang artinya ada hubungan antara kejadian hiperbilirubin dengan keteraturan minum obat. Dimana nilai korelasi nya bertanda ( -) sehingga dapat di simpulkan semakin teratur minum obat maka akan semakin normal dengan tingkat keeratan hubungannya adalah kuat. 3. Teknik korelasi Phi Teknik korelasi Phi digunakan bila data yang akan dikorelasikan adalah data yang terpisah secara tajam atau variable diskrit murni. Contohnya adalah lakilaki dan perempuan, lulus dan tidak lulus, ikut profesi dan tidak ikut profesi. Rumus korelasi phi adalah
71 ( ad bc ) ( a b )( a c )( b d )( c d ) Prestasi Contoh soal : Jenis kelamin Laki-laki Perempuan Jumlah Berhasil 100 (a) 72 (b) 172 Gagal 15 (c) 13 (d) 28 Jumlah Langkah-langkah menghitung korelasi phi adalah : a. Membuat table seperti contoh soal diatas dengan memberi tanda a,b,c, dan d dan memasukkan kedalam rumus b. Membuat hipotesis H 0 : tidak ada hubungan antara jenis kelamin dengan prestasi ( ) H 1 : ada hubungan antara jenis kelamin dengan prestasi ( ) c. Penarikan kesimpulan dilakukan dengan membandingkan antara nilai korelasi phi dengan table korelasi product moment.dengan n = 200 di dapatkan nilai table 1,38 sehingga terima H 0, yang artinya tidak ada hubungan antara jenis kelamin dengan prestasi belajar. 4. Teknik Korelasi Koefisient Kontingency (Coefficient Contingency) Teknik korelasi koefisien kontingensi digunakan apabila dua buah variable yang akan dikorelasikan berbentuk kategori (dua atau lebih) atau merupakan gejala ordinal. Rumus yang di gunakan untuk mencari coefficient contingency adalah : C 2 2 n rumus untuk mencari chi-kuadrat adalah : 2 2 f 0 f h f h Untuk memberikan interpretasi terhadap koefisien kontingensi maka harga koefisien kontingensi (C atau koreksi) harus diubah menjadi phi dengan menggunakan rumus dibawah ini : C 1 c 2 Contoh soal : Pemahaman agama Baik Cukup Kurang Jumlah Pelaksanaan sholat Baik Sedang
72 Kurang Jumlah Langkah pengerjaan korelasi coefficient contingency : a. Dengan cara penghitungan yang sama pada materi sebelumnya maka di dapatkan nilai. b. Langkah selanjutnya adalah mensubsitusikan dan di dapatkan nilai : Selanjutnya mengubah harga C menjadi phi yaitu : c. Membuat suatu hipotesis H 0 : tidak ada hubungan pemahaman agama dengan pelaksanaan sholat ( ) H 1 : ada hubungan antara pemahaman agama dengan pelaksanaan sholat ( ) d. Penarikan kesimpulan dilakukan dengan membandingkan antara nilai korelasi coefficient contingency dengan table korelasi product moment. Dengan n = 250 di dapatkan nilai table 1,38 (menggunakan pendekatan) sehingga tolak H 0, yang artinya ada hubungan antara pemahaman agama dengan pelaksanaan shola, dimana memiliki korelasi yang positif antara semakin baik pemahaman agama maka semakin baik pula pelaksanaan sholat, dan memiliki tingkat keeratan yang cukup kuat.
73 BAB 14 REGRESI LINIER SEDERHANA A. Definisi Regresi Linier Untuk mengukur besarnya pengaruh variabel bebas terhadap variabel tergantung dan memprediksi variabel tergantung dengan menggunakan variabel bebas. Gujarati (2006) mendefinisikan analisis regresi sebagai kajian terhadap hubungan satu variabel yang disebut sebagai variabel yang diterangkan (the explained variabel) dengan satu atau dua variabel yang menerangkan (the explanatory). Variabel pertama disebut juga sebagai variabel tergantung dan variabel kedua disebut juga sebagai variabel bebas. Jika variabel bebas lebih dari satu, maka analisis regresi disebut regresi linear berganda. Disebut berganda karena pengaruh beberapa variabel bebas akan dikenakan kepada variabel tergantung. Untuk mengetahui apakah variable-variabel yang akan di analisis tersebut sesuai menggunakan regresi linier atau regresi non linier ada beberapa metode yang dapat di gunakan, yaitu metode diagram pencar (scatter plot) dan metode kuadrat terkecil (least square). Metode scatter plot menggunakan diagram diagram pencar sebagai bahan pertimbangan untuk menentukan apakah data yang di miliki dapat menggunakan regresi linier atau tidak linier dan merupakan metode yang paling sederhana. Sedangkan metode least square untuk menentukan apakah data yang di miliki dapat menggunakan regresi linier atau tidak linier menggunakan rumus tertentu. Untuk dapat menggunakan regresi linier maka data pada variable independent dan variable dependent memiliki skala data interval dan ratio. B. Metode Regresi Linier Sederhana 1. Scatter Plot Metode diagram pencar merupakan cara untuk menentukan regresi dengan menggunakan grafik, dimana sebagai sumbu X adalah variable independent (X) dan sebagai sumbu Y adalah variable dependent (Y). Untuk menentukan apakah data yang di miliki dapat menggunakan analisis regresi linier atau tidak linier dengan mlihat letak titik-titik pada diagram pencar. Jika titik-titik tersebut berada di sekitar garis lurus maka dapat di duga bahwa regresi linier merupakan analisis yang tepat. Tetapi bila letak titik-titik data tersebut berada di sekitar garis lengkung maka dapat di duga bahwa analisis yang di gunakan adalah regresi nonlinier. Contoh soal Data berikut merupakanhasil penelitian yang dilakukan untuk menentukan hubungan antara usia dengan denyut jantung (banyaknya denyut jantung per menit) pada perempuan dari usia satu sampai 15. Tabel 14.1 Tabel Umur dengan Denyut Jantung No Umr DJ

74 Gambar 14.1 scatter plot Dari data pada table 14.1 dapat di buat diagram pencar yang dapat memperlihatkan apakah variable yang di teliti dapat di analisis menggunakan regresi linier atau tidak. Jika titik-titik point nya terletak atau membentuk garis lurus, maka dapat dianggap bahwa regresi linier merupakan analisis yang tepat yang dapat digunakan. Gambar 14.2 scatter plot umur dengan denyut jantung
75 Gambar diatas menunjukkan adanya gejala linieritas karena letk titik-titik yang cenderung mendekati garis lurus sehingga dapat di duga regresi yang dapat di gunakan adalah regresi linier. 2. Metode Least Square Metode kuadrat terkecil untuk regresi linier digunakan untuk menentukan dugaan bentuk regresi apakah linier atau tidak dimana terdapat perbedaan dugaan. Persoalan penting didalam pembuatan garis regresi sampel adalah begaimana kita bisa mendapatkan garis regresi yang baik. Garis regresi sampel yang baik ini terjadi jika nilai prediksinya sedekat mungkin dengan data aktualnya. Dengan kata lain kita mencari nilai β 0 dan β 1 yang menyebabkan residual sekecil mungkin, maka untuk menduga regresi liniernya perlu menaksir parameter-parameter regresinya sehingga di peroleh persamaan sebagai berikut : Dimana : Ŷ = variable terikat X = variable bebas a = parameter intercept b = parameter koefisien variable bebas Koefisien-koefisien regresi a dan b dapat di hitung dengan rumus sebagai berikut : a y b x No. Dengan menggunakan data pada table 14.1 maka : Umr DJ (X) (Y)
76 Total Sehingga di dapatkan : sehingga persamaan yang didapatkan adalah : Dari persamaan diatas di dapatkan nilai koefisien variable bebas memiliki tanda negative yang artinya semakin bertambah usia setiap satu satuan maka denyut nadi akan berkurang 2,04 satuan. Sehingga ketika seorang responden berusia 13 tahun maka denyut nadinya adalah :
77 BAB 15 UJI BEDA BIVARIATE (PARAMETRIK) Bila seorang peneliti ingin mengetahui apakah parameter dua populasi berbeda atau tidak, maka uji statistik yang digunakan disebut uji beda dua mean. Umumnya, pendekatan yang dilakukan bisa dengan distribusi Z (uji Z), ataupun distribusi t (uji t). Uji Z dapat digunakan bila (1) standar deviasi populasi (σ) diketahui, dan (2) jumlah sampelnya besar (> 30). Bila kedua syarat tersebut tidak terpenuhi, maka jenis uji yang digunakan adalah uji t dua sampel (two sample t-test). Tes t adalah salah satu uji statistik yang digunakan untuk mengetahui ada atau tidaknya perbedaan yang significant (menyakinkan) dari dua buah mean sample (dua buah variable yang dikomparatifkan). Tes t dikembangkan oleh William Seely Gosset seorang konsultan statistik Irlandia pada tahun Ia menggunakan samaran student dan huruf t pada istilah tes t sehingga tes t juga dikenal dengan istilah student t. Uji t pada satu populasi akan menguji apakah rata-rata populasi sama dengan suatu harga tertentu. Sedangkan uji t dua sample akan menguji apakah rata-rata dua populasi sama ataukah berbeda secara nyata. Berdasarkan hubungan antar populasinya, uji t dapat digolongkan kedalam dua jenis uji, yaitu Paired sample t-test, dan independent sample t-test. 1. Paired sample t-test (Uji t berpasangan) Dependent sample t-test atau sering diistilakan dengan Paired Sampel t-test, adalah jenis uji statistika yang bertujuan untuk membandingkan rata-rata dua grup yang saling berpasangan. Sampel berpasangan dapat diartikan sebagai sebuah sampel dengan subjek yang sama namun mengalami 2 perlakuan atau pengukuran yang berbeda, yaitu pengukuran sebelum dan sesudah dilakukan sebuah treatment. Syarat jenis uji ini adalah: (a) data berdistribusi normal; (b) kedua kelompok data adalah dependen (saling berhubungan/berpasangan); dan (c) jenis data yang digunakan adalah numeric. Sampel berpasangan (Paired sample) adalah sebuah sampel dengan subyek yangs ama namun mengalami dua perlakuan atau pengukuran yang berbeda. Seperti seorang detailer yang bekerja sebelumnya tanpa mendapat training, dengan sesudah ia mendapat training, bagaimana efektifitas training tersebut terhadap kemampuan menjualnya, apakah ada peningkatan atau tidak. Disini sampelnya tetap detailer yang sama, tapi mendapat dua perlakuan berbeda, yaitu kondisi sebelum dan kondisi sesudah training. Rumus yang di gunakan adalah a. Paired sample t test untuk n < 30 sample t d S d d n
78 Contoh soal : Untuk menghadapi persaingan dengan perusahaan Obat lain, Obat produksi DUTA FARMA yang selama ini dikemas secara sederhana, akan diubah kemasannya. Untuk itu, pada 15 daerah penjualan yang berbeda, dilakukan pengamatan dengan mencatat penjualan Obat dengan kemasan lama (kemasan1). Kemudian kemasan diganti dengan kemasan yang lebih atraktif (kemasan 2), dan kemudian mencatat tingkat penjualan Obat dengan kemasan baru pada 15 daerah yang sama. Tabel 15.1 Data penjualan kemasan 1 kemasan 2 d 23,00 26, ,00 26, ,00 29, ,00 28, ,00 30, ,00 31, ,00 32, ,00 27, ,00 22, ,00 25, ,00 24, ,00 26, ,00 29, ,00 28, ,00 23,00 3 = -0,87 Langkah-langkah untuk melakukan uji t berpasangan adalah sebagai berikut : 1. Menghitung nilai t hitung 2. Membuat hipotesis
79 H 0 : tidak ada perbedaan tingkat penjualan berdasarkan kemasan 1 dan kemasan 2 ( µ 1 = µ 2 ) H 1 : ada perbedaan tingkat penjualan berdasarkan kemasan 1 dan kemasan 2 (µ 1 µ 2 ) 3. Membandingkan t hitung dengan t table Mencari df (degree of freedom) atau derajat kebebasan = n-1 Df = 15 1 t tabel = 2,14 4. Memberikan kesimpulan Karena nilai t hitung < t tabel (tanpa memperhatikan tanda karena pengujian dua arah) maka H 0 di terima sehingga tidak ada perbedaan penjualan berdasarkan pergantian kemasan. b. Paired sample t test untuk n > 30 sample Rumus yang di gunakan untuk menghitung sample besar > 30 adalah sebagai berikut : ( ) ( ) = rata-rata sample 1 = rata-rata sample 2 = standart deviasi sample 1 = standart deviasi sample 2 Penghitungan paired sample t test > 30 dengan langkah yang sama seperti pada sample < Independent sample t-test (Uji t independen) Independent sample t-test adalah jenis uji statistika yang bertujuan untuk membandingkan rata-rata dua grup yang tidak saling berpasangan atau tidak saling berkaitan. Tidak saling berpasangan dapat diartikan bahwa penelitian dilakukan untuk dua subjek sampel yang berbeda. Prinsip pengujian uji ini adalah melihat perbedaan variasi kedua kelompok data, sehingga sebelum dilakukan pengujian, terlebih dahulu harus
80 diketahui apakah variannya sama (equal variance) atau variannya berbeda (unequal variance). Homogenitas varian diuji berdasarkan rumus: Data dinyatakan memiliki varian yang sama (equal variance) bila F-Hitung < F-Tabel, dan sebaliknya, varian data dinyatakan tidak sama (unequal variance) bila F-Hitung > F- Tabel. Bentuk varian kedua kelompok data akan berpengaruh pada nilai standar error yang akhirnya akan membedakan rumus pengujiannya. Uji t untuk varian yang sama (equal variance) menggunakan rumus Polled Varians: 2 s p s t s p 2 n s 1 n 2 s n 2 1 n 2 1 n 1 1 n s x 1 x dimana µ 1 dan µ 2 diasumsikan 0 Uji t untuk varian yang berbeda (unequal variance) menggunakan rumus Separated Varians: Contoh soal : Suatu penelitian dilakukan untuk mengetahui pengaruh pemberian lendir bekicot terhadap proses penyembuhan luka. Penelitian ini dilakukan terhadap tikus putih betina dengan cara tikus putih betina tersebut dibagi kedalam dua kelompok, yaitu kelompok perlakuan dan kontrol. Semua tikus diberikan luka sayatan sepanjang 7 mm. Dan didapatkan hasil penelitian setelah penelitian selama 2 hari sebagai berikut :
81 Tabel 15.2 tabel penyembuhan luka Perlakuan (dlm mm) Kontrol (mm) 4,3 5,6 4,9 5,0 3,6 6,1 3,7 5,7 3,5 4,8 4,0 5,3 4,2 5,1 3,9 6,5 3,8 Langkah-langkah dalam mengerjakan uji t-independent adalah 1. Menguji kehomogenan data = 0,431 = 0,580 = 0,186 = 0,336 Sehingga Selanjutnya nilai F hitung di bandingkan dengan F table dimana Hipotesisnya : H 0 : data homogen (σ 1 = σ 2 ) H 1 : data tidak homogen (σ 1 σ 2 ) F tabe l = 3,44 Dari hasil diatas F hitung < F tabel sehingga H 0 di terima data homogeny (equal varians assume) 2. Mencari t hitung Untuk mencari t hitung menggunakan rumus thitung pooled sehinggha t hitung = - 3,01 3. Menentukan hipotesis H 0 : tidak ada perbedaan penyembuhan luka karena pemberian lender bekicot (µ 1 = µ 2 ) H 1 : ada perbedaan penyembuhan luka karena pemberian lender bekicot (µ 1 µ 2 ) 4. Membandingkan dengan t tabel Mencari df (degree of freedom) atau derajat kebebasan = n 1 + n 2 2 Sehingga df = = 15 Di dapatkan t table = 2,13 5. Penarikan kesimpulan
82 Karena nilai thitung>besar dari ttabel (tanpa memperhatikan tanda karena merupakan pengujian dua arah) maka H0 ditolak, ada perbedaan penyembuhan luka karena pemberian lender bekicot sebesar 1,5 mm (selisish rata-rata antara kelompok control dan kelompok perlakuan) dalam waktu 2 hari.
83 BAB 16 Analysis Of Variance (ANOVA) Teknik analisis menggunakan uji t yaitu dengan mencari perbedaan yang signifikan dari 2 buah rata-rata hanya akan effektif bila jumlah variabelnya adalah dua. Apabila jumlah variabelnya lebih dari dua, maka penggunaan uji t tidak effektif lagi karena langkah pengujiannya akan dilakukan satu persatu. Kemungkinan terjadinya kesalahan juga sangat besar selain membutuhkan waktu yang lebih lama dan biaya yang besar. Untuk mengatasi hal tersebut ada teknik komparasi yang menggunakan variable lebih dari dua, yaitu Analysis of Variance atau ANOVA. Jenis data yang tepat untuk digunakan pada ANOVA adalah nominal dan ordinal pada variable independent nya atau variable bebasnya, sedangkan pada variable terikatnya adalah data interval atau ratio. Dalam menggunakan anova harus memenuhi asumsi dasarnya, agar kesimpulan yang diambil tidak menimbulkan kesalahan atau kurang akurat. Adapun asumsi dasar yang harus terpenuhi adalah : 1. distribusi data harus normal, agar data berdistribusi normal dapat ditempuh dengan cara memperbanyak jumlah sample dalam kelompok. 2. setiap kelompok hendaknya berasal dari populasi yang sama dengan variansi yang sama pula. Bila banyaknya sample sama pada setiap kelompok pada setiap kelompok maka kesamaan variansinya dapat diabaikan. Tapi bila banyaknya sample pada masing-masing kelompok tidak sama maka kesamaan variansi populasi sangat diperlukan. 3. Pengambilan sample dilakukan secara random. Anova pada dasarnya terdiri dari dari dua kelompok. Pengelompokan di tentukan dari jumlah variable bebasnya. Bila variable yang akan dianalisis terdiri dari satu variable terikat dan satu varaibel bebas maka di sebut Analysis of Variance (ANOVA) satu arah. Apabila variable yang akan dianalisis terdiri dari satu variable bebas dan lebih dari satu variable terikat maka disebut ANOVA dua arah. 1. ANOVA satu arah Analisis variance satu arah berarti kita ingin mengetahui apakah ada perbedaan rata-rata yang didasarkan pada satu kriteria tertentu. Ada hal yang harus diperhatikan yaitu tujuannya membandingkan rata-rata antar sampel dan sampel yang digunakan adalah berasal dari sampel yang berbeda. Misalkan kita memiliki k populasi. Masing-masing populasi diambil sampel sebanyak n. Dan k populasi yang diambil adalah bebas serta berdistribusi normal dengan nilai tengah 1, 2, 3,..., k dan ragam atau variansi sama 2. Misalkan x ij adalah pengamatan ke-j dari populasi ke-i, maka hasilnya dapat di lihat pada gambar Ada tiga bagian pengukuran variabilitas pada data yang akan dianalisis dengan ANOVA, yaitu : a. Variabilitas antar kelompok (between treatment variability) Variabilitas antar kelompok adalah variansi mean kelompok sampel terhadap rata-rata total, sehingga variansi lebih terpengaruh oleh adanya perbedaan perlakuan antar kelompok, Jumlah Kuadrat antar Kelompok (JKA). Rumusnya adalah :
 Variabilitas dalam kelompok adalah varians yang ada dalam masing-masing kelompok. Banyaknya variansi akan tergantung pada banyaknya kelompok.")
84 JKA n x 2 x k 2 Gambar 17.1 pengamatan ke j dari populasi ke-i b. Variabilitas dalam kelompok (Within treatmen variability) Variabilitas dalam kelompok adalah varians yang ada dalam masing-masing kelompok. Banyaknya variansi akan tergantung pada banyaknya kelompok. Variansi tidak terpengaruh oleh perbedaan perlakuan antar kelompok, atau Jumlah Kuadrat Dalam (JKD). Rumusnya adalah : JKT = JKA + JKD c. Jumlah Kuadrat penyimpangan total (total sum of squares) Jumlah Kuadrat penyimpangan total adalah jumlah kuadrat selisih antara skor individual dengan mean totalnya, atau JKT. Dengan rumusnya adalah : JKT x 2 N x 2 Langkah-langkah dalam melakukan analisis Anova adalah : 1. Menghitung JKA, JKD, dan JKT (jumlah kuadrat) 2. Membuat hipotesis, misalnya H 0 : Kelima tablet memiliki waktu yang sama dalam mengurangi rasa sakit. H 1 : Terdapat tablet yang tidak memiliki waktu sama dalam mengurangi rasa sakit.
85 3. Mencari Derajat Kebebasan dengan menggunakan Tabel F dimana dengan derajat kebebasan ke-1 : df1=k-1 dan derajat kebebasan k-2 : df2=n-k. 4. Membuat ringkasan table Anova Tabel 17.1 Ringkasan Anova Sumber variasi Jumlah Kuadrat Derajat Kebebasan Rataan Kuadrat Perlakuan JKA k-1 2 s 1 JKA Galat JKD k(n-1) Jumlah JKT nk-1 s 2 k 1 JKD k ( n 1) F hitungan s s Penarikan Kesimpulan dengan membandingkan F hitung dengan F tabel. Untuk mengambil keputusan maka : - Ho ditolak jika F-hitung > F-Tabel - Ho diterima jika F-hitung F-Tabel Gambar 17.2 Kurva F Contoh soal : Dari 5 tablet sakit kepala yang diberikan kepada 25 orang dicatat berapa lama tablet-tablet tersebut dapat mengurangi rasa sakit. Ke-25 orang itu dibagi secara acak ke dalam 5 kelompok dan masing-masing diberi satu jenis tablet yang berbeda yaitu tablet A, B, C, D dan E. Dalam pengujian ini ingin mengetahui apakah kelima tablet tersebut sama lamanya dalam mengurangi rasa sakit. Tabel 17.2 tabel waktu mengurangi rasa sakit


86 Penyelesaian : Tabel 17.3 penyelesaian Dari hasil perhitungan di dapatkan : 1. JKA = 79,440 JKT = 137,04 JKD = 137,04 79,440 = 57, H 0 : Kelima tablet memiliki waktu yang sama dalam mengurangi rasa sakit. H 1 : Terdapat tablet yang tidak memiliki waktu sama dalam mengurangi rasa sakit. 3. Df 1 = 4 Df 2 = 20 Sehingga Ftabel = 2,87 Tabel 17.4 Tabel Anova Sumber Jumlah Derajat Rataan F hitung variasi Kuadrat Kebebasan Kuadrat Perlakuan 79, ,860 6,896 Galat 57, ,880
87 Jumlah 137, Karena F hitung lebih besar dari F tabel maka H 0 di tolak ada tablet yang memiliki waktu yang tidak sama untuk meredakan sakit. 2. Analisis Sesudah ANOVA Analisis sesudah Anova atau pasca Anova (Post Hoc) dilakukan jika Hipotesis nol (H 0 ) di tolak. Apabila hipotesis nol di terima maka analisis post hoc tidak perlu dilakukan, karena tujuan analisis sesudah anova adalah untuk mencari kelompok mana yang berbeda hal ini dapat dilakukan bila F hitung nya berbeda. Ada beberapa teknik analisis yang dapat digunakan untuk melakukan analisis sesudah ANOVA, antara lain Tukey s HSD, Bonferroni, Sidak, Duncan, dll. Analisis sesudah anova yang popular dan sering di gunakan adalah Tukey s HSD dengan rumus sebagai berikut : a. Menghitung Tukey s HSD dengan rumus Dimana : q = the student range statistic. q di peroleh dengan melihat table student range statistic. kolom untuk jumlah kelompok atau perlakuan sehingga dalam hal ini k = 5. Df = n k sehingga 25 5 = 20. Sehingga dengan melihat table student range statistic q = 4,23 k = kelompok b. Mencari perbedaan rata-rata antar kelompok Menghitung rata-rata masing-masing kelompok dimana : Kelompok A = 5,2 Kelompok B = 7,8 Kelompok C = 4,0 Kelompok D = 2,8 Kelompok E = 6,6 Selanjutnya berdasarkan rata-rata masing-masing kelompok di buat table perbedaan antar kelompok sebagai berikut : Tabel 16.5 Tabel Post Hoc X A X B X C X D X E X A - -2,6 1,2 2,4-1,4 X B 2,6-3,8 5 1,2 X C -1,2-3,8-1,2-2,6 X D -2,4-5 -1,2-3,8 X E 1,4-1,2 2,6-3,8 -
88 Selanjutnya membandingkan perbedaan rata-rata antar kelompok dengan nilai HSD, bila perbedaan rata-rata lebih besar dari nilai HSD (tanpa memperhatikan tanda dan +) maka ada perbedaan yang significant. Tetapi bila lebih kecil dari nilai HSD berarti tidak ada perbedaan yang significant Dari table diatas dapat di simpilkan : X A = X B X B X C X C = X D X D X E X A = X C X B X D X C = X E X A = X D X B = X E X A = X E c. Interpretasi 1. Obat yang paling baik untuk meredakan sakit kepala adalah obat merk D karena menyembuhkan lebih cepat daripada yang lainnya. Sedangkan Obat merek B menyembuhkan yang paling lama di bandingkan obat merk lainnya. 2. Dari table 16.5 dapat diinterpretasikan sebagai berikut : Obat A dan obat B memberikan waktu penyembuhan yang sama Obat A dan obat C memberikan waktu penyembuhan yang sama Obat A dan obat D memberikan waktu penyembuhan yang sama Obat A dan obat E memberikan waktu penyembuhan yang sama Obat B dan obat C memberikan waktu penyembuhan yang tidak sama Obat B dan obat D membarikan waktu penyembuhan yang tidak sama Obat B dan obat E membarikan waktu penyembuhan yang sama Obat C dan obat D membarikan waktu penyembuhan yang sama Obat C dan obat E membarikan waktu penyembuhan yang sama Obat D dan obat E membarikan waktu penyembuhan yang tidak sama
89 DAFTAR PUSTAKA Arikunto, Suharsimi Prosedur Penelitian : Suatu Pendekatan Praktik. Edisi Revisi Jakarta : Rineka Cipta. Cohran, W.G Teknik Penarikan Sampel.Terj. Rudiansyah. Ed. 3. Jakarta : Penerbit UI Press Ghozali, Imam Aplikasi Analisis Multivariate Dengan Program SPSS. Semarang : BP Universitas Diponegoro Gudono, Analisis Data Multivariate. Yogyakarta : BPFE Gujarati, Damodar Dasar-Dasar Ekonometrika.Jakarta : Erlangga. Hartono Statistik Untuk Penelitian. Yaogjakarta : Pustaka Pelajar Jan Jonker, Bartjan J.W. Pennink, Sari Wahyunil Metodologi Penelitian. Panduan Untuk Master Ph.D di bidang Manajemen. Jakarta : Salemba Empat Neuman, W, L. (2006). Social Research Methods : Qualitative and Quantitative Approaches. Sixth Edition, New York : Pearson International, Inc Riduwan dan Sunarto Statistika untuk penelitian. Bandung : Alfabeta Santoso, Singgih Statistik dengan SPSS. Jakarta : Elex media Komputindo. Sarwono, Jonathan Metode Penelitian Kuantitatif dan Kualitatif. Yogyakarta : Graha Ilmu Sugiyono Metode Penelitian Kombinsasi. Bandung : Alfabeta Usman Husaini dan R. Purnomo Akbar, Pengantar Statistika, Jakarta, Bumi Aksara Walpole, E Ronald, Pengantar Statistika Edisi Ke-3. Jakarta : Gramedia Pustaka Utama

90
91
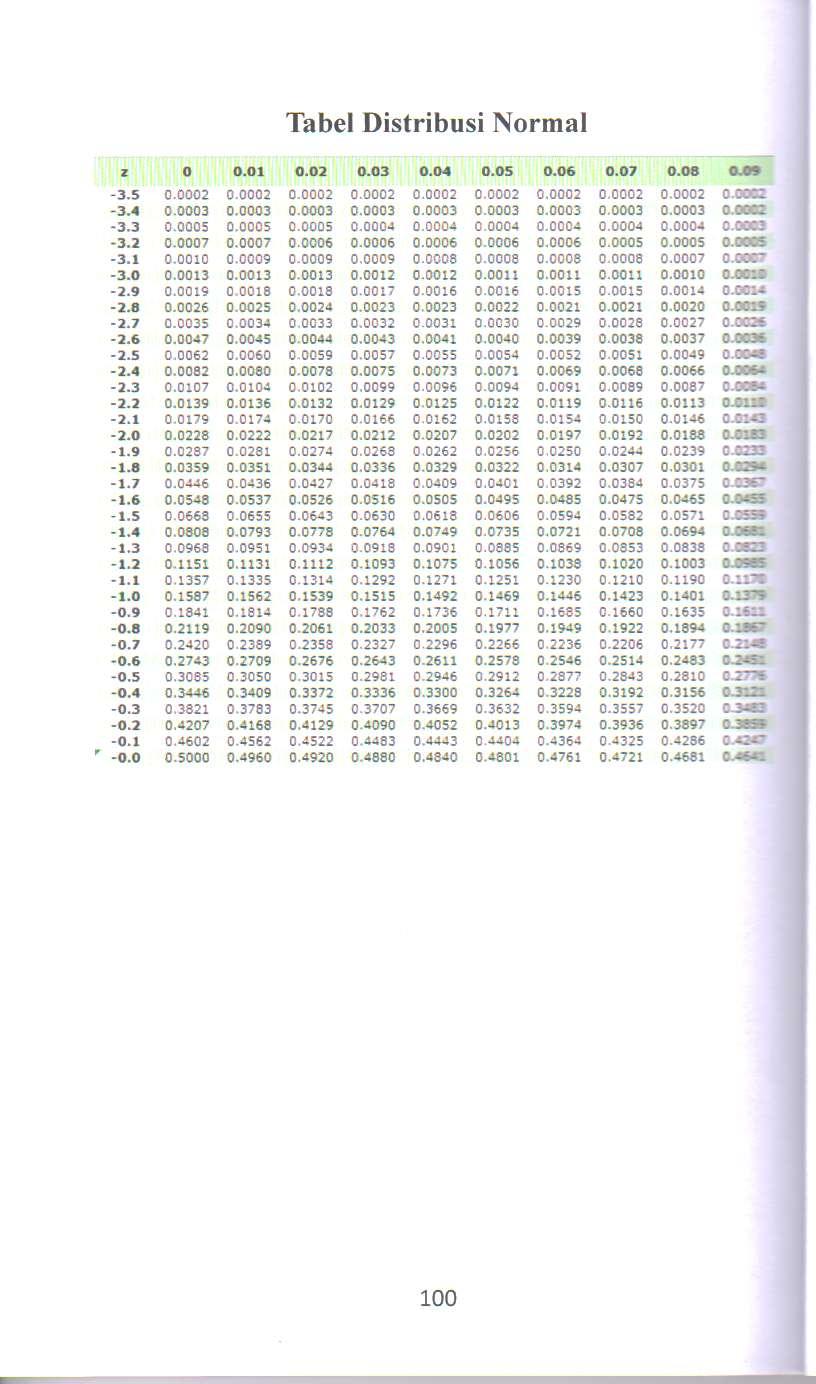
92
93
94

95

96
97

98
99

100

101
102
103
104
105
106
, S-1 pada Fakultas Sospol Unikad tahun 1996 dan Sarjana Kesehatan Masyarakat di STIKes Majapahit tahun 2013.")
107 Dr. H. Sandu Siyoto, S.Sos.,SKM.,M.Kes Dr. H. Sandu Siyoto, S.Sos.,SKM.,M.Kes, lahir di Desas Klagen Rejoso Nganjuk Jawa Timur 16 Februari Lulusan Pendidikan D-III Akademi Penilik Kesehatan Surabaya (Dep. Kesehatan RI), S-1 pada Fakultas Sospol Unikad tahun 1996 dan Sarjana Kesehatan Masyarakat di STIKes Majapahit tahun Program Magister Ilmu Kesehatan Masyarakat di Universitas Gadjah Mada Yogyakarta tahun 2001 dan Program Doktor Ilmu Kesehatan Masyarakat Universitas Airlangga Surabaya Tahun Beberapa pelatihan, workshop dan kursus baik sebagai peserta maupun pembicara yang berkaitan dengan aktifis prastis dan juga akademik telah diikuti oleh penulis baik yang bersifat lokal, regional, nasional serta Internasional (Singapura, Johor Malaysia, Melbounre, Hobart Tasmania,Taiwan, Philipina). Beberapa hasil penelitian penulis sudah dipublikasikan dalam forum regional, nasional bahkan internasional. Selain itu beberapa buku dan karya penulis juga telah diterbitkan, diantaranya Kesehatan Reproduksi (2013) yang ditulis bersama Dr. Hasdiana, M.Kes, Kledek Nganjuk (2014) yang ditulis bersama budayawan Dr. Purwadi, SS.,M.Hum, Dasar-dasar Riset Keperawatan ditulis bersama Dr. Hasdianah Hasan Rohan, M.Si, Dr. Indasah, M.Kes.

108 Ratna Wardani, SSi., MM Ratna Wardani, SSi., MM, lahir di Kediri, Jawa Timur 6 Desember Lulusan S-1 Statistika Institut 10 Nopember Surabaya tahun Program Magister Manajemen di Universitas Airlangga Surabaya tahun Beberapa pelatihan, workshop dan kursus baik sebagai peserta maupun pembicara yang berkaitan dengan aktifis prastis dan juga akademik telah diikuti oleh penulis. Beberapa hasil penelitian penulis sudah dipublikasikan dalam forum regional dan nasional. Selain itu beberapa buku dan karya penulis juga telah diterbitkan, diantaranya Dasar-dasar Riset Keperawatan ditulis bersama Dr. Hasdianah Hasan Rohan, M.Si, Dr. Indasah, M.Kes, Pengolahan dan Analisa Data di tulis bersama Niasari, SSi., M.Kes.
OUTLINE. BAGIAN II Probabilitas dan Teori Keputusan. Konsep-konsep Dasar Probabilitas. Distribusi Probabilitas Diskret.
 TEORI KEPUTUSAN OUTLINE BAGIAN II Probabilitas dan Teori Keputusan Konsep-konsep Dasar Probabilitas Distribusi Probabilitas Diskret Distribusi Normal Teori Keputusan Pengertian dan Elemen- Elemen Keputusan
TEORI KEPUTUSAN OUTLINE BAGIAN II Probabilitas dan Teori Keputusan Konsep-konsep Dasar Probabilitas Distribusi Probabilitas Diskret Distribusi Normal Teori Keputusan Pengertian dan Elemen- Elemen Keputusan
KATA PENGANTAR. Medan, April 2010. Nana Kartika, ST
 KATA PENGANTAR Puji syukur kehadirat Allah SWT, karena berkat rahmat, karunia dan hidayahnya, bahan ajar modul mata kuliah Statistik Probabilitas ini dapat terselesaikan. Modul yang di susun ini diharapkan
KATA PENGANTAR Puji syukur kehadirat Allah SWT, karena berkat rahmat, karunia dan hidayahnya, bahan ajar modul mata kuliah Statistik Probabilitas ini dapat terselesaikan. Modul yang di susun ini diharapkan
BAB 2 LANDASAN TEORI
 BAB 2 LANDASAN TEORI 2.1 Teori Probabilitas (Peluang) Probabilitas adalah suatu nilai untuk mengukur tingkat kemungkinan terjadinya suatu peristiwa (event) akan terjadi di masa mendatang yang hasilnya
BAB 2 LANDASAN TEORI 2.1 Teori Probabilitas (Peluang) Probabilitas adalah suatu nilai untuk mengukur tingkat kemungkinan terjadinya suatu peristiwa (event) akan terjadi di masa mendatang yang hasilnya
BAB 2 LANDASAN TEORI
 BAB 2 LANDASAN TEORI 2. Probabilitas Probabilitas adalah suatu nilai untuk mengukur tingkat kemungkinan terjadinya suatu peristiwa (event) akan terjadi di masa mendatang yang hasilnya tidak pasti (uncertain
BAB 2 LANDASAN TEORI 2. Probabilitas Probabilitas adalah suatu nilai untuk mengukur tingkat kemungkinan terjadinya suatu peristiwa (event) akan terjadi di masa mendatang yang hasilnya tidak pasti (uncertain
KONSEP DASAR PROBABILITAS OLEH : RIANDY SYARIF
 KONSEP DASAR PROBABILITAS OLEH : RIANDY SYARIF Definisi Probabilitas adalah suatu ukuran tentang kemungkinan suatu peristiwa (event) akan terjadi dimasa mendatang. Probabilitas dinyatakan antara 0 s/d
KONSEP DASAR PROBABILITAS OLEH : RIANDY SYARIF Definisi Probabilitas adalah suatu ukuran tentang kemungkinan suatu peristiwa (event) akan terjadi dimasa mendatang. Probabilitas dinyatakan antara 0 s/d
METODE DAN DISTRIBUSI SAMPLING. Oleh : Riandy Syarif
 METODE DAN DISTRIBUSI SAMPLING Oleh : Riandy Syarif HUBUNGAN SAMPEL DAN POPULASI Populasi Sampel DEFINISI Populasi kumpulan dari semua kemungkinan orang-orang, benda-benda, dan ukuran lain yang menjadi
METODE DAN DISTRIBUSI SAMPLING Oleh : Riandy Syarif HUBUNGAN SAMPEL DAN POPULASI Populasi Sampel DEFINISI Populasi kumpulan dari semua kemungkinan orang-orang, benda-benda, dan ukuran lain yang menjadi
BAB II TINJAUAN TEORITIS. Menurut Darnius, O (2006, Hal : 53) simulasi dapat diartikan sebagai suatu
 simulasi dapat diartikan sebagai suatu") BAB II TINJAUAN TEORITIS 2.1 Pendahulauan Menurut Darnius, O (2006, Hal : 53) simulasi dapat diartikan sebagai suatu rekayasa suatu model logika ilmiah untuk melihat kebenaran/kenyataan model tersebut.
BAB II TINJAUAN TEORITIS 2.1 Pendahulauan Menurut Darnius, O (2006, Hal : 53) simulasi dapat diartikan sebagai suatu rekayasa suatu model logika ilmiah untuk melihat kebenaran/kenyataan model tersebut.
LATIHAN SOAL TERJAWAB-BAB 10. Untuk mahasiswa, jawaban diberikan untuk soal ganjil.
 LATIHAN SOAL TERJAWAB-BAB 10 Untuk mahasiswa, jawaban diberikan untuk soal ganjil. 1. Berikut adalah tabel hasil (payoff) dari investasi di saham pertanian, industri dan perbankan untuk setiap lembar sahamnya.
LATIHAN SOAL TERJAWAB-BAB 10 Untuk mahasiswa, jawaban diberikan untuk soal ganjil. 1. Berikut adalah tabel hasil (payoff) dari investasi di saham pertanian, industri dan perbankan untuk setiap lembar sahamnya.
Keputusan Dalam Ketidakpastian dan Resiko
 Keputusan Dalam Ketidakpastian dan Resiko Suasana pengambilan keputusan : dalam pasti (certainty), dalam keadaan resiko (risk), dalam ketidakpastian (uncertainty), dalam suasana konflik (conflict). Analisis
Keputusan Dalam Ketidakpastian dan Resiko Suasana pengambilan keputusan : dalam pasti (certainty), dalam keadaan resiko (risk), dalam ketidakpastian (uncertainty), dalam suasana konflik (conflict). Analisis
DISTRIBUSI NORMAL. Fitri Yulianti
 DISTRIBUSI NORMAL Fitri Yulianti KARAKTERISTIK DISTRIBUSI KURVA NORMAL 1. Kurva berbentuk genta ( = Md= Mo) 2. Kurva berbentuk simetris 3. Kurva normal berbentuk asimptotis 4. Kurva mencapai puncak padaa
DISTRIBUSI NORMAL Fitri Yulianti KARAKTERISTIK DISTRIBUSI KURVA NORMAL 1. Kurva berbentuk genta ( = Md= Mo) 2. Kurva berbentuk simetris 3. Kurva normal berbentuk asimptotis 4. Kurva mencapai puncak padaa
BAB 1 PENDAHULUAN. Universitas Sumatera Utara
 BAB 1 PENDAHULUAN 1.1 Latar Belakang Dalam teori probabilitas dan statistika, distribusi binomial adalah distribusi probabilitas diskret jumlah keberhasilan dalam n percobaan ya/tidak (berhasil/gagal)
BAB 1 PENDAHULUAN 1.1 Latar Belakang Dalam teori probabilitas dan statistika, distribusi binomial adalah distribusi probabilitas diskret jumlah keberhasilan dalam n percobaan ya/tidak (berhasil/gagal)
STATISTIKA II IT
 STATISTIKA II IT-011227 Ummu Kalsum UNIVERSITAS GUNADARMA 2017 Keterlambatan : KONTRAK KULIAH MOHON KETERLAMBATAN TIDAK LEBIH 15 MENIT Sanksi atau hukuman, sebagai contoh: Menguraikan pengetahuan tentang
STATISTIKA II IT-011227 Ummu Kalsum UNIVERSITAS GUNADARMA 2017 Keterlambatan : KONTRAK KULIAH MOHON KETERLAMBATAN TIDAK LEBIH 15 MENIT Sanksi atau hukuman, sebagai contoh: Menguraikan pengetahuan tentang
Bagian 2. Probabilitas. Struktur Probabilitas. Probabilitas Subyektif. Metode Frekuensi Relatif Kejadian untuk Menentukan Probabilitas
 Probabilitas Bagian Probabilitas A) = peluang (probabilitas) bahwa kejadian A terjadi 0 < A) < 1 A) = 0 artinya A pasti terjadi A) = 1 artinya A tidak mungkin terjadi Penentuan nilai probabilitas: Metode
Probabilitas Bagian Probabilitas A) = peluang (probabilitas) bahwa kejadian A terjadi 0 < A) < 1 A) = 0 artinya A pasti terjadi A) = 1 artinya A tidak mungkin terjadi Penentuan nilai probabilitas: Metode
BAB 5 PENENTUAN POPULASI DAN SAMPEL PENELITIAN. Populasi adalah wilayah generalisasi yang terdiri atas obyek atau
 BAB 5 PENENTUAN POPULASI DAN SAMPEL PENELITIAN 5.1. Populasi dan Sampel Populasi adalah wilayah generalisasi yang terdiri atas obyek atau subyek yang memiliki kuantitas atau kualitas tertentu yang ditentukan
BAB 5 PENENTUAN POPULASI DAN SAMPEL PENELITIAN 5.1. Populasi dan Sampel Populasi adalah wilayah generalisasi yang terdiri atas obyek atau subyek yang memiliki kuantitas atau kualitas tertentu yang ditentukan
15Ilmu. Uji t-student dan Uji Z (Distribusi Normal)
") Modul ke: Fakultas 15Ilmu Komunikasi Uji t-student dan Uji Z (Distribusi Normal) Untuk sebaran distribusi sampel kecil, dikembangkan suatu distribusi khusus yang disebut distribusi t atau t-student Dra.
Modul ke: Fakultas 15Ilmu Komunikasi Uji t-student dan Uji Z (Distribusi Normal) Untuk sebaran distribusi sampel kecil, dikembangkan suatu distribusi khusus yang disebut distribusi t atau t-student Dra.
KARAKTERISTIK DISTRIBUSI KURVA NORMAL
 DISTRIBUSI PROBABILITAS NORMAL 1 KARAKTERISTIK DISTRIBUSI KURVA NORMAL 1. Kurva berbentuk genta ( = Md= Mo) 2. Kurva berbentuk simetris 3. Kurva mencapai puncak pada saat X= 4. Luas daerah di bawah kurva
DISTRIBUSI PROBABILITAS NORMAL 1 KARAKTERISTIK DISTRIBUSI KURVA NORMAL 1. Kurva berbentuk genta ( = Md= Mo) 2. Kurva berbentuk simetris 3. Kurva mencapai puncak pada saat X= 4. Luas daerah di bawah kurva
Bab 2 DISTRIBUSI PELUANG
 Bab 2 DISTRIBUSI PELUANG PENDAHULUAN Setiap peristiwa akan mempunyai peluangnya masingmasing, dan peluang terjadinya peristiwa itu akan mempunyai penyebaran yang mengikuti suatu pola tertentu yang di sebut
Bab 2 DISTRIBUSI PELUANG PENDAHULUAN Setiap peristiwa akan mempunyai peluangnya masingmasing, dan peluang terjadinya peristiwa itu akan mempunyai penyebaran yang mengikuti suatu pola tertentu yang di sebut
PENDAHULUAN Definisi: Contoh Kasus:
 DISTRIBUSI PROBABILITAS 1 PENDAHULUAN Definisi: Distribusi probabilitas adalah sebuah susunan distribusi yang mempermudah mengetahui probabilitas sebuah peristiwa. Merupakan hasil dari setiap peluang peristiwa.
DISTRIBUSI PROBABILITAS 1 PENDAHULUAN Definisi: Distribusi probabilitas adalah sebuah susunan distribusi yang mempermudah mengetahui probabilitas sebuah peristiwa. Merupakan hasil dari setiap peluang peristiwa.
Pengambilan Keputusan dalam Ketidakpastian
 Bab 13 : Pengambilan Keputusan dalam Ketidakpastian 1 Ekonomi manajerial Manajemen 2 Pokok Bahasan Pengantar Keputusan Dalam Ketidakpastian Kriteria Maximin, Kriteria Maximax, Kriteria Minimax (Kroteria
Bab 13 : Pengambilan Keputusan dalam Ketidakpastian 1 Ekonomi manajerial Manajemen 2 Pokok Bahasan Pengantar Keputusan Dalam Ketidakpastian Kriteria Maximin, Kriteria Maximax, Kriteria Minimax (Kroteria
DISTRIBUSI TEORITIS. P(M) = p = probabilitas untuk mendapat bola merah (sukses) 30
 = p = probabilitas untuk mendapat bola merah (sukses) 30") DISTRIBUSI TEORITIS Distribusi teoritis merupakan alat bagi kita untuk menentukan apa yang dapat kita harapkan, apabila asumsi-asumsi yang kita buat benar. Distribusi teoritis memungkinkan para pembuat
DISTRIBUSI TEORITIS Distribusi teoritis merupakan alat bagi kita untuk menentukan apa yang dapat kita harapkan, apabila asumsi-asumsi yang kita buat benar. Distribusi teoritis memungkinkan para pembuat
KONSEP DASAR PROBABILITAS
 KONSEP DASAR PROBABILITAS 1 OUTLINE BAGIAN II Probabilitas dan Teori Keputusan Konsep-Konsep Dasar Probabilitas Distribusi Probabilitas Diskrit Pengertian Probabilitas dan Manfaat Probabilitas Pendekatan
KONSEP DASAR PROBABILITAS 1 OUTLINE BAGIAN II Probabilitas dan Teori Keputusan Konsep-Konsep Dasar Probabilitas Distribusi Probabilitas Diskrit Pengertian Probabilitas dan Manfaat Probabilitas Pendekatan
Teknik Sampling. Materi ke 4 Statistika I. Kelas 2 EB, EA dan DD Semester PTA 2007/2008
 Teknik Sampling Materi ke 4 Statistika I Kelas 2 EB, EA dan DD Semester PTA 2007/2008 Alasan menggunakan sampel : (a) (b) (c) (d) populasi demikian banyaknya sehingga dalam prakteknya tidak mungkin seluruh
Teknik Sampling Materi ke 4 Statistika I Kelas 2 EB, EA dan DD Semester PTA 2007/2008 Alasan menggunakan sampel : (a) (b) (c) (d) populasi demikian banyaknya sehingga dalam prakteknya tidak mungkin seluruh
DISTRIBUSI PROBABILITAS NORMAL
 DISTRIBUSI PROBABILITAS NORMAL 1 KARAKTERISTIK DISTRIBUSI KURVA NORMAL 1. Kurva berbentuk genta ( = Md= Mo) 2. Kurva berbentuk simetris 3. Kurva normal berbentuk asimptotis 4. Kurva mencapai puncak pada
DISTRIBUSI PROBABILITAS NORMAL 1 KARAKTERISTIK DISTRIBUSI KURVA NORMAL 1. Kurva berbentuk genta ( = Md= Mo) 2. Kurva berbentuk simetris 3. Kurva normal berbentuk asimptotis 4. Kurva mencapai puncak pada
STATISTIK PERTEMUAN III
 STATISTIK PERTEMUAN III OUTLINE PERTEMUAN III BAGIAN II Probabilitas dan Teori Keputusan Konsep-Konsep Dasar Probabilitas Distribusi Probabilitas Diskrit Pengertian Probabilitas dan Manfaat Probabilitas
STATISTIK PERTEMUAN III OUTLINE PERTEMUAN III BAGIAN II Probabilitas dan Teori Keputusan Konsep-Konsep Dasar Probabilitas Distribusi Probabilitas Diskrit Pengertian Probabilitas dan Manfaat Probabilitas
DISTRIBUSI TEORITIS. Variabel Acak Distribusi Teoritis Binomial Normal
 DISTRIBUSI TEORITIS DISTRIBUSI TEORITIS Variabel Acak Distribusi Teoritis Binomial Normal Variabel acak adalah sebuah besaran yang merupakan hasil dari percobaan acak yang secara untung-untungan, dapat
DISTRIBUSI TEORITIS DISTRIBUSI TEORITIS Variabel Acak Distribusi Teoritis Binomial Normal Variabel acak adalah sebuah besaran yang merupakan hasil dari percobaan acak yang secara untung-untungan, dapat
OUT LINE. Distribusi Probabilitas Normal. Pengertian Distribusi Probabilitas Normal. Distribusi Probabilitas Normal Standar
 3 OUT LINE Pengertian Distribusi Probabilitas Normal Distribusi Probabilitas Normal Distribusi Probabilitas Normal Standar Penerapan Distribusi Probabilitas Normal Standar Pendekatan Normal Terhadap Binomial
3 OUT LINE Pengertian Distribusi Probabilitas Normal Distribusi Probabilitas Normal Distribusi Probabilitas Normal Standar Penerapan Distribusi Probabilitas Normal Standar Pendekatan Normal Terhadap Binomial
Makalah Statistika Distribusi Normal
 Makalah Statistika Distribusi Normal Disusun Oleh: Dwi Kartika Sari 23214297 2EB16 Fakultas Ekonomi Jurusan Akuntansi Universitas Gunadarma 2015 Kata Pengantar Puji syukur kehadirat Tuhan Yang Maha Esa
Makalah Statistika Distribusi Normal Disusun Oleh: Dwi Kartika Sari 23214297 2EB16 Fakultas Ekonomi Jurusan Akuntansi Universitas Gunadarma 2015 Kata Pengantar Puji syukur kehadirat Tuhan Yang Maha Esa
BAB II DISTRIBUSI PROBABILITAS
 BAB II DISTRIBUSI PROBABILITAS.1. VARIABEL RANDOM Definisi 1: Variabel random adalah suatu fungsi yang memetakan ruang sampel (S) ke himpunan bilangan Real (R), dan ditulis X : S R Contoh (Variabel random)
BAB II DISTRIBUSI PROBABILITAS.1. VARIABEL RANDOM Definisi 1: Variabel random adalah suatu fungsi yang memetakan ruang sampel (S) ke himpunan bilangan Real (R), dan ditulis X : S R Contoh (Variabel random)
METODE SAMPLING. Met. Sampling-T.Parulian
 METODE SAMPLING Dari populasi hingga sampel Proses pengambilan sampel (sampling) dari populasi merupakan proses utama dalam statistika induktif. Sampling dilakukan karena seorang peneliti tidak mungkin
METODE SAMPLING Dari populasi hingga sampel Proses pengambilan sampel (sampling) dari populasi merupakan proses utama dalam statistika induktif. Sampling dilakukan karena seorang peneliti tidak mungkin
DISTRIBUSI PROBABILITAS DISKRET
 DISTRIBUSI PROBABILITAS DISKRET 1 OUTLINE BAGIAN II Probabilitas dan Teori Keputusan Konsep-konsep Dasar Probabilitas Diskret Distribusi Normal Teori Keputusan Pengertian Distribusi Probabilitas Binomial
DISTRIBUSI PROBABILITAS DISKRET 1 OUTLINE BAGIAN II Probabilitas dan Teori Keputusan Konsep-konsep Dasar Probabilitas Diskret Distribusi Normal Teori Keputusan Pengertian Distribusi Probabilitas Binomial
PENGENALAN SISTEM OPTIMASI. Oleh : Zuriman Anthony, ST. MT
 PENGENALAN SISTEM OPTIMASI Oleh : Zuriman Anthony, ST. MT PENILAIAN 1. KEHADIRAN (25%) 2. TUGAS + KUIS (25%) 3. UTS (25%) 4. UAS (25%) 5. Terlambat maksimal 15 menit 6. Kehadiran minimal 10 kali di kelas
PENGENALAN SISTEM OPTIMASI Oleh : Zuriman Anthony, ST. MT PENILAIAN 1. KEHADIRAN (25%) 2. TUGAS + KUIS (25%) 3. UTS (25%) 4. UAS (25%) 5. Terlambat maksimal 15 menit 6. Kehadiran minimal 10 kali di kelas
DISTRIBUSI NORMAL. Pertemuan 3. Distribusi Normal_M. Jainuri, M.Pd 1
 DISTRIBUSI NORMAL Pertemuan 3 1 Distribusi Normal Pertama kali diperkenalkan oleh Abraham de Moivre (1733). De Moivre menemukan persamaan matematika untuk kurva normal yang menjadi dasar dalam banyak teori
DISTRIBUSI NORMAL Pertemuan 3 1 Distribusi Normal Pertama kali diperkenalkan oleh Abraham de Moivre (1733). De Moivre menemukan persamaan matematika untuk kurva normal yang menjadi dasar dalam banyak teori
KONSEP DASAR PROBABILITAS DAN DISTRIBUSI PROBABILITAS LELY RIAWATI, ST, MT.
 KONSEP DASAR PROBABILITAS DAN DISTRIBUSI PROBABILITAS LELY RIAWATI, ST, MT. EKSPERIMEN suatu percobaan yang dapat diulang-ulang dengan kondisi yang sama CONTOH : Eksperimen : melempar dadu 1 kali Hasilnya
KONSEP DASAR PROBABILITAS DAN DISTRIBUSI PROBABILITAS LELY RIAWATI, ST, MT. EKSPERIMEN suatu percobaan yang dapat diulang-ulang dengan kondisi yang sama CONTOH : Eksperimen : melempar dadu 1 kali Hasilnya
Distribusi Normal Distribusi normal, disebut pula distribusi Gauss, adalah distribusi probabilitas yang paling banyak digunakan dalam berbagai
 Distribusi Normal Distribusi normal, disebut pula distribusi Gauss, adalah distribusi probabilitas yang paling banyak digunakan dalam berbagai analisis statistika. Distribusi normal baku adalah distribusi
Distribusi Normal Distribusi normal, disebut pula distribusi Gauss, adalah distribusi probabilitas yang paling banyak digunakan dalam berbagai analisis statistika. Distribusi normal baku adalah distribusi
DISTRIBUSI SAMPLING besar
 DISTRIBUSI SAMPLING besar Distribusi Sampling Sampling = pendataan sebagian anggota populasi = penarikan contoh / pengambilan sampel Sampel yang baik Sampel yang representatif, yaitu diperoleh dengan memperhatikan
DISTRIBUSI SAMPLING besar Distribusi Sampling Sampling = pendataan sebagian anggota populasi = penarikan contoh / pengambilan sampel Sampel yang baik Sampel yang representatif, yaitu diperoleh dengan memperhatikan
BAB 6 PENAKSIRAN PARAMETER
 BAB 6 PENAKSIRAN PARAMETER Bab 6 PENAKSIRAN PARAMETER Standar Kompetensi : Setelah mengikuti kuliah ini, mahasiswa dapat memahami hubungan nilai sampel dan populasi dan menentukan distribusi sampling yang
BAB 6 PENAKSIRAN PARAMETER Bab 6 PENAKSIRAN PARAMETER Standar Kompetensi : Setelah mengikuti kuliah ini, mahasiswa dapat memahami hubungan nilai sampel dan populasi dan menentukan distribusi sampling yang
Muhammad Arif Rahman https://arifelzainblog.lecture.ub.ac.id/
 Muhammad Arif Rahman arifelzain@ub.ac.id Populasi Keseluruhan objek penelitian atau keseluruhan elemen yang akan diteliti. Sampel Sebagian dari populasi Representatif dapat memberi gambaran yang tepat
Muhammad Arif Rahman arifelzain@ub.ac.id Populasi Keseluruhan objek penelitian atau keseluruhan elemen yang akan diteliti. Sampel Sebagian dari populasi Representatif dapat memberi gambaran yang tepat
BAB 2 TINJAUAN PUSTAKA
 BAB 2 TINJAUAN PUSTAKA 2.1 Data Data adalah bentuk jamak dari datum, yang dapat diartikan sebagai informasi yang diterima yang bentuknya dapat berupa angka, kata-kata, atau dalam bentuk lisan dan tulisan
BAB 2 TINJAUAN PUSTAKA 2.1 Data Data adalah bentuk jamak dari datum, yang dapat diartikan sebagai informasi yang diterima yang bentuknya dapat berupa angka, kata-kata, atau dalam bentuk lisan dan tulisan
Bab 3 Pengantar teori Peluang
 Bab 3 Pengantar teori Peluang Istilah peluang atau kemungkinan, sering kali diucapkan atau didengar. Sebagai contoh ketika manajer dari sebuah klub sepak bola ditanya wartawan tentang hasil pertandingan
Bab 3 Pengantar teori Peluang Istilah peluang atau kemungkinan, sering kali diucapkan atau didengar. Sebagai contoh ketika manajer dari sebuah klub sepak bola ditanya wartawan tentang hasil pertandingan
Metoda Penelitian TEKNIK SAMPLING
 Metoda Penelitian TEKNIK SAMPLING Jika Cukup Sesendok Tak Perlu Semangkok Dasar pemikiran Data yang dipergunakan dalam suatu penelitian belum tentu merupakan keseluruhan dari suatu populasi karena beberapa
Metoda Penelitian TEKNIK SAMPLING Jika Cukup Sesendok Tak Perlu Semangkok Dasar pemikiran Data yang dipergunakan dalam suatu penelitian belum tentu merupakan keseluruhan dari suatu populasi karena beberapa
PROBABILITAS (PELUANG) PENGERTIAN PROBABILITAS
 PENGERTIAN PROBABILITAS") PROBABILITAS (PELUANG) PENGERTIAN PROBABILITAS Dalam kehidupan sehari-hari kita sering mendengar dan menggunakan kata probabilitas (peluang). Kata ini mengisyaratkan bahwa kita berhadapan dengan sesuatu
PROBABILITAS (PELUANG) PENGERTIAN PROBABILITAS Dalam kehidupan sehari-hari kita sering mendengar dan menggunakan kata probabilitas (peluang). Kata ini mengisyaratkan bahwa kita berhadapan dengan sesuatu
DECISION THEORY DAN GAMES THEORY
 DECISION THEORY DAN GAMES THEORY PENGANTAR Lingkungan di mana keputusan dibuat sering digolongkan kedalam empat keadaan: certainty, risk, uncertainty, dan conflict. Decision theory terutama berhubungan
DECISION THEORY DAN GAMES THEORY PENGANTAR Lingkungan di mana keputusan dibuat sering digolongkan kedalam empat keadaan: certainty, risk, uncertainty, dan conflict. Decision theory terutama berhubungan
BAB I. Pengertian Dasar dalam Statistika. A. Statistika, Statistik, Statistika Deskriptif
 BAB I Pengertian Dasar dalam Statistika A. Statistika, Statistik, Statistika Deskriptif 1. Pengertian Statistika Statistika adalah bagian dari matematika yang secara khusus membicarakan cara-cara pengumpulan,
BAB I Pengertian Dasar dalam Statistika A. Statistika, Statistik, Statistika Deskriptif 1. Pengertian Statistika Statistika adalah bagian dari matematika yang secara khusus membicarakan cara-cara pengumpulan,
1. PENGERTIAN. Manfaat Sampling :
 1. PENGERTIAN Sampel adalah sebagian dari anggota populasi yang dipilih dengan cara tertentu yang akan diteliti sifat-sifatnya dalam penelitian. Nilai-nilai yang berasal dari data sampel dinamakan dengan
1. PENGERTIAN Sampel adalah sebagian dari anggota populasi yang dipilih dengan cara tertentu yang akan diteliti sifat-sifatnya dalam penelitian. Nilai-nilai yang berasal dari data sampel dinamakan dengan
POPULASI DAN SAMPEL PENELITIAN. MYRNA SUKMARATRI
 POPULASI DAN SAMPEL PENELITIAN PENGERTIAN ALASAN MELAKUKAN SAMPLING PENENTUAN JUMLAH SAMPEL PENGAMBILAN DATA SAMPEL POPULASI Suatu wilayah generalisasi yang terdiri atas obyek/subyek yang mempunyai karakteristik
POPULASI DAN SAMPEL PENELITIAN PENGERTIAN ALASAN MELAKUKAN SAMPLING PENENTUAN JUMLAH SAMPEL PENGAMBILAN DATA SAMPEL POPULASI Suatu wilayah generalisasi yang terdiri atas obyek/subyek yang mempunyai karakteristik
CIRI-CIRI DISTRIBUSI NORMAL
 DISTRIBUSI NORMAL CIRI-CIRI DISTRIBUSI NORMAL Berbentuk lonceng simetris terhadap x = μ distribusi normal atau kurva normal disebut juga dengan nama distribusi Gauss, karena persamaan matematisnya ditemukan
DISTRIBUSI NORMAL CIRI-CIRI DISTRIBUSI NORMAL Berbentuk lonceng simetris terhadap x = μ distribusi normal atau kurva normal disebut juga dengan nama distribusi Gauss, karena persamaan matematisnya ditemukan
RISET AKUNTANSI. Materi RISET AKUNTANSI
 RISET AKUNTANSI Materi RISET AKUNTANSI Dr. Kartika Sari U niversitas G unadarma Materi 5-1 Satuan Acara Perkuliahan 1. Riset Ilmiah 2. Metode dan Desain Riset 3. Topologi Data 4. Teknik Sampling 5. Metode
RISET AKUNTANSI Materi RISET AKUNTANSI Dr. Kartika Sari U niversitas G unadarma Materi 5-1 Satuan Acara Perkuliahan 1. Riset Ilmiah 2. Metode dan Desain Riset 3. Topologi Data 4. Teknik Sampling 5. Metode
5/2/2017. Pertemuan 7 POPULASI DAN SAMPEL ALUR PEMIKIRAN POPULASI DAN SAMPEL SUBJEK, OBJEK DAN RESPONDEN PENELITIAN POPULASI SAMPEL
 POPULASI Pertemuan 7 POPULASI DAN SAMPEL wilayah generalisasi yang terdiri atas objek/subjek yang ditetapkan oleh peneliti untuk dipelajari dan kemudian ditarik kesimpulannya keseluruhan unsur yang akan
POPULASI Pertemuan 7 POPULASI DAN SAMPEL wilayah generalisasi yang terdiri atas objek/subjek yang ditetapkan oleh peneliti untuk dipelajari dan kemudian ditarik kesimpulannya keseluruhan unsur yang akan
STATISTIK PERTEMUAN IV
 STATISTIK PERTEMUAN IV PRINSIP DAN DISTRIBUSI PROBABILITAS A. PERANAN PROBABILITAS Pembuatan model, analisis matematis, simulasi komputer dan sebagainya, banyak didasarkan atas asumsi-asumsi yang diidealisir,
STATISTIK PERTEMUAN IV PRINSIP DAN DISTRIBUSI PROBABILITAS A. PERANAN PROBABILITAS Pembuatan model, analisis matematis, simulasi komputer dan sebagainya, banyak didasarkan atas asumsi-asumsi yang diidealisir,
BAB 2 LANDASAN TEORI
 BAB 2 LANDASAN TEORI 21 Teori Himpunan Fuzzy Pada himpunan tegas (crisp), nilai keanggotaan suatu item x dalam himpunan A, yang sering ditulis dengan memiliki dua kemungkinan, yaitu: 1 Nol (0), yang berarti
BAB 2 LANDASAN TEORI 21 Teori Himpunan Fuzzy Pada himpunan tegas (crisp), nilai keanggotaan suatu item x dalam himpunan A, yang sering ditulis dengan memiliki dua kemungkinan, yaitu: 1 Nol (0), yang berarti
Contoh: Aturan Penjumlahan. Independen. P(A dan B) = P(A) x P(B)
 = P(A) x P(B)") Aturan Penjumlahan Mutually Exclusive: Kemungkinan terjadi peristiwa A dan B: P(A atau B)= P(A)+P(B) Not Mutually Exclusive: Kemungkinan terjadi peristiwa A dan B: P(Aatau B): P(A)+P(B) P(A dan B) Contoh:
Aturan Penjumlahan Mutually Exclusive: Kemungkinan terjadi peristiwa A dan B: P(A atau B)= P(A)+P(B) Not Mutually Exclusive: Kemungkinan terjadi peristiwa A dan B: P(Aatau B): P(A)+P(B) P(A dan B) Contoh:
DISTRIBUSI TEORITIS DISTRIBUSI TEORITIS
 DISTRIBUSI TEORITIS DISTRIBUSI TEORITIS Variabel Acak Distribusi Teoritis Binomial Normal 1 Variabel acak adalah sebuah besaran yang merupakan hasil dari percobaan acak yang secara untung-untungan, dapat
DISTRIBUSI TEORITIS DISTRIBUSI TEORITIS Variabel Acak Distribusi Teoritis Binomial Normal 1 Variabel acak adalah sebuah besaran yang merupakan hasil dari percobaan acak yang secara untung-untungan, dapat
Modul ke: STATISTIK Probabilitas atau Peluang. 05Teknik. Fakultas. Bethriza Hanum ST., MT. Program Studi Teknik Mesin
 Modul ke: STATISTIK Probabilitas atau Peluang Fakultas 05Teknik Bethriza Hanum ST., MT Program Studi Teknik Mesin Pengertian dan Pendekatan Mempelajari probabilitas kejadian suatu peristiwa sangat bermanfaat
Modul ke: STATISTIK Probabilitas atau Peluang Fakultas 05Teknik Bethriza Hanum ST., MT Program Studi Teknik Mesin Pengertian dan Pendekatan Mempelajari probabilitas kejadian suatu peristiwa sangat bermanfaat
6.5 Pertimbangan penentuan ukuran sampel
 6.5 Pertimbangan penentuan ukuran sampel 1. Pertimbangan Ukuran Sampel Pertimbangan Penentuan Ukuran Sampel 4 hal yang harus dipertimbangkan dalam menentukan besarnya sampel dalam suatu penelitian : 1)
6.5 Pertimbangan penentuan ukuran sampel 1. Pertimbangan Ukuran Sampel Pertimbangan Penentuan Ukuran Sampel 4 hal yang harus dipertimbangkan dalam menentukan besarnya sampel dalam suatu penelitian : 1)
BAB IX PROSES KEPUTUSAN
 BAB IX PROSES KEPUTUSAN Lingkungan di mana keputusan dibuat sering digolongkan kedalam empat keadaan: certainty, risk, uncertainty, dan conflict. Decision theory terutama berhubungan dengan pengambilan
BAB IX PROSES KEPUTUSAN Lingkungan di mana keputusan dibuat sering digolongkan kedalam empat keadaan: certainty, risk, uncertainty, dan conflict. Decision theory terutama berhubungan dengan pengambilan
Hidup penuh dengan ketidakpastian
 BAB 2 Probabilitas Hidup penuh dengan ketidakpastian Tidak mungkin bagi kita untuk dapat mengatakan dengan pasti apa yang akan terjadi dalam 1 menit ke depan tapi Probabilitas akan memprediksikan masa
BAB 2 Probabilitas Hidup penuh dengan ketidakpastian Tidak mungkin bagi kita untuk dapat mengatakan dengan pasti apa yang akan terjadi dalam 1 menit ke depan tapi Probabilitas akan memprediksikan masa
DISTRIBUSI NORMAL. Pertemuan 3. 1 Pertemuan 3_Statistik Inferensial
 DISTRIBUSI NORMAL Pertemuan 3 1 Pertemuan 3_Statistik Inferensial Distribusi Normal Pertama kali diperkenalkan oleh Abraham de Moivre (1733). De Moivre menemukan persamaan matematika untuk kurva normal
DISTRIBUSI NORMAL Pertemuan 3 1 Pertemuan 3_Statistik Inferensial Distribusi Normal Pertama kali diperkenalkan oleh Abraham de Moivre (1733). De Moivre menemukan persamaan matematika untuk kurva normal
PENARIKAN SAMPEL & PENDUGAAN PARAMETER
 PENARIKAN SAMPEL & PENDUGAAN PARAMETER Arti Penarikan Sampel Populasi ( Universe) adalah totalitas dari semua objek atau individu yang memiliki karakteristik tertentu, jelas dan lengkap yang akan diteliti
PENARIKAN SAMPEL & PENDUGAAN PARAMETER Arti Penarikan Sampel Populasi ( Universe) adalah totalitas dari semua objek atau individu yang memiliki karakteristik tertentu, jelas dan lengkap yang akan diteliti
Dr. I Gusti Bagus Rai Utama, SE., M.MA., MA.
 Dr. I Gusti Bagus Rai Utama, SE., M.MA., MA. Populasi : totalitas dari semua objek/ individu yg memiliki karakteristik tertentu, jelas dan lengkap yang akan diteliti Sampel : bagian dari populasi yang
Dr. I Gusti Bagus Rai Utama, SE., M.MA., MA. Populasi : totalitas dari semua objek/ individu yg memiliki karakteristik tertentu, jelas dan lengkap yang akan diteliti Sampel : bagian dari populasi yang
BAB I PENDAHULUAN 1.1 LATAR BELAKANG
 BAB I PENDAHULUAN 1.1 LATAR BELAKANG Risiko adalah kerugian karena kejadian yang tidak diharapkan terjadi. Misalnya, kejadian sakit mengakibatkan kerugian sebesar biaya berobat dan upah yang hilang karena
BAB I PENDAHULUAN 1.1 LATAR BELAKANG Risiko adalah kerugian karena kejadian yang tidak diharapkan terjadi. Misalnya, kejadian sakit mengakibatkan kerugian sebesar biaya berobat dan upah yang hilang karena
Teori Pengambilan Keputusan
 Teori Pengambilan Keputusan Iman Murtono Soenhadji Jurusan Manajemen Fakultas Ekonomi Iman Murtono Soenhadji 1 Bab 1: Pendahuluan Pengertian Pengambilan Keputusan dikemukakan oleh, Ralp C. Davis; Mary
Teori Pengambilan Keputusan Iman Murtono Soenhadji Jurusan Manajemen Fakultas Ekonomi Iman Murtono Soenhadji 1 Bab 1: Pendahuluan Pengertian Pengambilan Keputusan dikemukakan oleh, Ralp C. Davis; Mary
STATISTIKA LINGKUNGAN
 STATISTIKA LINGKUNGAN TEORI PROBABILITAS Probabilitas -pendahuluan Statistika deskriptif : menggambarkan data Statistik inferensi kesimpulan valid dan perkiraan akurat ttg populasi dengan mengobservasi
STATISTIKA LINGKUNGAN TEORI PROBABILITAS Probabilitas -pendahuluan Statistika deskriptif : menggambarkan data Statistik inferensi kesimpulan valid dan perkiraan akurat ttg populasi dengan mengobservasi
Kasus di atas dapat diselesaikan menggunakan analisis breakeven.
 I. Analisis Break-Even Analisis break-even merupakan salah satu teknik analisis ekonomi yang berguna dalam menghubungkan biaya variabel total (TVC) dan biaya tetap total (TFC) terhadap output produksi
I. Analisis Break-Even Analisis break-even merupakan salah satu teknik analisis ekonomi yang berguna dalam menghubungkan biaya variabel total (TVC) dan biaya tetap total (TFC) terhadap output produksi
ESTIMASI. Arna Fariza PENDAHULUAN
 ESTIMASI Arna Fariza PENDAHULUAN MATERI LALU Karena adanya berbagai alasan seperti banyaknya individu dalam populasi amatan, maka penelitian keseluruhan terhadap populasi tersebut tidaklah ekonomis, baik
ESTIMASI Arna Fariza PENDAHULUAN MATERI LALU Karena adanya berbagai alasan seperti banyaknya individu dalam populasi amatan, maka penelitian keseluruhan terhadap populasi tersebut tidaklah ekonomis, baik
TATAP MUKA IV UKURAN PENYIMPANGAN SKEWNESS DAN KURTOSIS. Fitri Yulianti, SP. MSi.
 TATAP MUKA IV UKURAN PENYIMPANGAN SKEWNESS DAN KURTOSIS Fitri Yulianti, SP. MSi. UKURAN PENYIMPANGAN Pengukuran penyimpangan adalah suatu ukuran yang menunjukkan tinggi rendahnya perbedaan data yang diperoleh
TATAP MUKA IV UKURAN PENYIMPANGAN SKEWNESS DAN KURTOSIS Fitri Yulianti, SP. MSi. UKURAN PENYIMPANGAN Pengukuran penyimpangan adalah suatu ukuran yang menunjukkan tinggi rendahnya perbedaan data yang diperoleh
Jenis Distribusi. 1. Distribusi Probabilitas 2. Distribusi Binomial (Bernaulli) 3. Distribusi Multinomial 4. Distribusi Normal (Gauss)
 3. Distribusi Multinomial 4. Distribusi Normal (Gauss)") Ir Tito Adi Dewanto Jenis Distribusi 1. Distribusi Probabilitas 2. Distribusi Binomial (Bernaulli) 3. Distribusi Multinomial 4. Distribusi Normal (Gauss) Pengantar Kunci aplikasi probabilitas dalam statistik
Ir Tito Adi Dewanto Jenis Distribusi 1. Distribusi Probabilitas 2. Distribusi Binomial (Bernaulli) 3. Distribusi Multinomial 4. Distribusi Normal (Gauss) Pengantar Kunci aplikasi probabilitas dalam statistik
PENGERTIAN STATISTIK. NO Tahun Jumlah / / / APAKAH INI STATISTIK?
 PENGERTIAN STATISTIK NO Tahun Jumlah 1. 2. 3. 2000 /2001 2001/ 2002 2002 / 2003 15.556 29.008 34.825 APAKAH INI STATISTIK? PENGERTIAN STATISTIK DAN STATISTIKA Statistika Ilmu mengumpulkan, menata, menyajikan,
PENGERTIAN STATISTIK NO Tahun Jumlah 1. 2. 3. 2000 /2001 2001/ 2002 2002 / 2003 15.556 29.008 34.825 APAKAH INI STATISTIK? PENGERTIAN STATISTIK DAN STATISTIKA Statistika Ilmu mengumpulkan, menata, menyajikan,
DISTRIBUSI PROBABILITAS (PELUANG)
") DISTRIBUSI PROBABILITAS (PELUANG) Distribusi Probabilitas (Peluang) Distribusi? Probabilitas? Distribusi Probabilitas? JURUSAN PENDIDIKAN FISIKA FPMIPA UNIVERSITAS PENDIDIKAN INDONESIA Distribusi = sebaran,
DISTRIBUSI PROBABILITAS (PELUANG) Distribusi Probabilitas (Peluang) Distribusi? Probabilitas? Distribusi Probabilitas? JURUSAN PENDIDIKAN FISIKA FPMIPA UNIVERSITAS PENDIDIKAN INDONESIA Distribusi = sebaran,
PERTEMUAN 6 TEORI PENGAMBILAN KEPUTUSAN
 PERTEMUAN 6 TEORI PENGAMBILAN KEPUTUSAN Pertemuan 6 TEORI PENGAMBILAN KEPUTUSAN Objektif: 1. Mahasiswa dapat mencari penyelesaian masalah dengan model keputusan dalam kepastian 2. Mahasiswa dapat mencari
PERTEMUAN 6 TEORI PENGAMBILAN KEPUTUSAN Pertemuan 6 TEORI PENGAMBILAN KEPUTUSAN Objektif: 1. Mahasiswa dapat mencari penyelesaian masalah dengan model keputusan dalam kepastian 2. Mahasiswa dapat mencari
Pertemuan 6 TEORI PENGAMBILAN KEPUTUSAN
 Pertemuan 6 TEORI PENGAMBILAN KEPUTUSAN Objektif: 1. Mahasiswa dapat mencari penyelesaian masalah dengan model keputusan dalam kepastian 2. Mahasiswa dapat mencari penyelesaian masalah dengan model keputusan
Pertemuan 6 TEORI PENGAMBILAN KEPUTUSAN Objektif: 1. Mahasiswa dapat mencari penyelesaian masalah dengan model keputusan dalam kepastian 2. Mahasiswa dapat mencari penyelesaian masalah dengan model keputusan
PENGELOLAAN STATISTIK YANG MENYENANGKAN, oleh Muhammad Rusli Hak Cipta 2014 pada penulis
 PENGELOLAAN STATISTIK YANG MENYENANGKAN, oleh Muhammad Rusli Hak Cipta 2014 pada penulis GRAHA ILMU Ruko Jambusari 7A Yogyakarta 55283 Telp: 0274-889398; Fax: 0274-889057; E-mail: info@grahailmu.co.id
PENGELOLAAN STATISTIK YANG MENYENANGKAN, oleh Muhammad Rusli Hak Cipta 2014 pada penulis GRAHA ILMU Ruko Jambusari 7A Yogyakarta 55283 Telp: 0274-889398; Fax: 0274-889057; E-mail: info@grahailmu.co.id
ARUMEGA ZAREFAR, SE.,M.Ak.,Akt.,CA
 STATISTIK ARUMEGA ZAREFAR, SE.,M.Ak.,Akt.,CA http://arumega.staff.unri.ac.id/ arumegazarefar.ca@gmail.com Arti statistik Kumpulan data dalam bentuk angka maupun bukan angka yang disusun dalam bentuk tabel
STATISTIK ARUMEGA ZAREFAR, SE.,M.Ak.,Akt.,CA http://arumega.staff.unri.ac.id/ arumegazarefar.ca@gmail.com Arti statistik Kumpulan data dalam bentuk angka maupun bukan angka yang disusun dalam bentuk tabel
Probability and Random Process
 Program Pasca Sarjana Terapan Politeknik Elektronika Negeri Surabaya Probability and Random Process Topik 1. Review Teori Statistika Prima Kristalina Maret 2016 2 Outline Pengertian Statistika Populasi,
Program Pasca Sarjana Terapan Politeknik Elektronika Negeri Surabaya Probability and Random Process Topik 1. Review Teori Statistika Prima Kristalina Maret 2016 2 Outline Pengertian Statistika Populasi,
Resume Regresi Linear dan Korelasi
 Rendy Dwi Ardiansyah Putra 7410040018 / 2 D4 IT A Statistika Resume Regresi Linear dan Korelasi 1. Regresi Linear Regresi linear merupakan suatu metode analisis statistik yang mempelajari pola hubungan
Rendy Dwi Ardiansyah Putra 7410040018 / 2 D4 IT A Statistika Resume Regresi Linear dan Korelasi 1. Regresi Linear Regresi linear merupakan suatu metode analisis statistik yang mempelajari pola hubungan
BAB 2 LANDASAN TEORI. 2.1 Risiko, Manajemen Risiko, dan Manajemen Risiko Finansial
 BAB 2 LANDASAN TEORI 2.1 Risiko, Manajemen Risiko, dan Manajemen Risiko Finansial Risiko adalah kerugian akibat kejadian yang tidak dikehendaki muncul. Risiko diidentifikasikan berdasarkan faktor penyebabnya,
BAB 2 LANDASAN TEORI 2.1 Risiko, Manajemen Risiko, dan Manajemen Risiko Finansial Risiko adalah kerugian akibat kejadian yang tidak dikehendaki muncul. Risiko diidentifikasikan berdasarkan faktor penyebabnya,
BAB III METODE PENELITIAN. Penelitian ini menggunakan metode diskriptif kuantitattif. Penelitian ini
 BAB III METODE PENELITIAN 3.1 Jenis dan Pendekatan Penelitian Penelitian ini menggunakan metode diskriptif kuantitattif. Penelitian ini merupakan yang menggunakan kuesioner sebagai instrumen penelitian.
BAB III METODE PENELITIAN 3.1 Jenis dan Pendekatan Penelitian Penelitian ini menggunakan metode diskriptif kuantitattif. Penelitian ini merupakan yang menggunakan kuesioner sebagai instrumen penelitian.
Konsep Dasar Statistik dan Probabilitas
 Konsep Dasar Statistik dan Probabilitas Pengendalian Kualitas Statistika Ayundyah Kesumawati Prodi Statistika FMIPA-UII October 7, 2015 Ayundyah (UII) Konsep Dasar Statistik dan Probabilitas October 7,
Konsep Dasar Statistik dan Probabilitas Pengendalian Kualitas Statistika Ayundyah Kesumawati Prodi Statistika FMIPA-UII October 7, 2015 Ayundyah (UII) Konsep Dasar Statistik dan Probabilitas October 7,
Kompetens n i s : Mahasiswa mam a pu p menjel enj a el s a ka k n gejala ekonomi dengan meng guna k n a konsep probabil i i l t i as
 Kompetensi: Mahasiswa mampu menjelaskan gejala ekonomi dengan menggunakan konsep probabilitas Hal. 9- Penelitian itu Penuh Kemungkinan (tdk pasti) Mengubah Saya tidak yakin Menjadi Saya yakin akan sukses
Kompetensi: Mahasiswa mampu menjelaskan gejala ekonomi dengan menggunakan konsep probabilitas Hal. 9- Penelitian itu Penuh Kemungkinan (tdk pasti) Mengubah Saya tidak yakin Menjadi Saya yakin akan sukses
Statistika Psikologi 2
 Modul ke: Statistika Psikologi 2 Fakultas Psikologi Program Studi Psikologi Sampling, Sampling Distribution, Confidence Intervals, Effect Size, dan Statistical Power SAMPLING Teknik menentukan sampel dari
Modul ke: Statistika Psikologi 2 Fakultas Psikologi Program Studi Psikologi Sampling, Sampling Distribution, Confidence Intervals, Effect Size, dan Statistical Power SAMPLING Teknik menentukan sampel dari
PENGAMBILAN KEPUTUSAN MANAJEMEN
 PENGAMBILAN KEPUTUSAN MANAJEMEN BAB 6. KONDISI PENGAMBILAN KEPUTUSAN 1. Pendahuluan 2. Kondisi Pengambilan Keputusan dalam Kepastian 3. Kondisi Pengambilan Keputusan dalam Ketidakpastian 4. Kondisi Pengambilan
PENGAMBILAN KEPUTUSAN MANAJEMEN BAB 6. KONDISI PENGAMBILAN KEPUTUSAN 1. Pendahuluan 2. Kondisi Pengambilan Keputusan dalam Kepastian 3. Kondisi Pengambilan Keputusan dalam Ketidakpastian 4. Kondisi Pengambilan
BAB 2 LANDASAN TEORI
 BAB 2 LANDASAN TEORI 2.1 Regresi Linier Sederhana Dalam beberapa masalah terdapat dua atau lebih variabel yang hubungannya tidak dapat dipisahkan karena perubahan nilai suatu variabel tidak selalu terjadi
BAB 2 LANDASAN TEORI 2.1 Regresi Linier Sederhana Dalam beberapa masalah terdapat dua atau lebih variabel yang hubungannya tidak dapat dipisahkan karena perubahan nilai suatu variabel tidak selalu terjadi
Kumpulan pasangan nilai-nilai dari variabel acak X dengan probabilitas nilai-nilai variabel random X, yaitu P(X=x) disebut distribusi probabilitas X
 disebut distribusi probabilitas X") Kumpulan pasangan nilai-nilai dari variabel acak X dengan probabilitas nilai-nilai variabel random X, yaitu P(X=) disebut distribusi probabilitas X (distribusi X) Diskrit Seragam Binomial Hipergeometrik
Kumpulan pasangan nilai-nilai dari variabel acak X dengan probabilitas nilai-nilai variabel random X, yaitu P(X=) disebut distribusi probabilitas X (distribusi X) Diskrit Seragam Binomial Hipergeometrik
DISTRIBUSI PROBABILITAS
 BAB 7 DISTRIBUSI PROBABILITAS Kompetensi Menjelaskan distribusi probabilitas Indikator 1. Menjelaskan distribusi hipergeometris 2. Menjelaskan distribusi binomial 3. Menjelaskan distribusi multinomial
BAB 7 DISTRIBUSI PROBABILITAS Kompetensi Menjelaskan distribusi probabilitas Indikator 1. Menjelaskan distribusi hipergeometris 2. Menjelaskan distribusi binomial 3. Menjelaskan distribusi multinomial
D I S T R I B U S I P R O B A B I L I T A S
 D I S T R I B U S I P R O B A B I L I T A S Amiyella Endista Email : amiyella.endista@yahoo.com Website : www.berandakami.wordpress.com Distribusi Probabilitas Kunci aplikasi probabilitas dalam statistik
D I S T R I B U S I P R O B A B I L I T A S Amiyella Endista Email : amiyella.endista@yahoo.com Website : www.berandakami.wordpress.com Distribusi Probabilitas Kunci aplikasi probabilitas dalam statistik
Metode Statistika (STK 211) Pertemuan ke-5
 Pertemuan ke-5") Metode Statistika (STK 211) Pertemuan ke-5 rrahmaanisa@apps.ipb.ac.id Memahami definisi dan aplikasi peubah acak (peubah acak sebagai fungsi, peubah acak diskrit dan kontinu) Memahami sebaran peubah acak
Metode Statistika (STK 211) Pertemuan ke-5 rrahmaanisa@apps.ipb.ac.id Memahami definisi dan aplikasi peubah acak (peubah acak sebagai fungsi, peubah acak diskrit dan kontinu) Memahami sebaran peubah acak
BAB I PENDAHULUAN 1.1 Kegunaan Metode Sampling 1.2 Tahap-Tahap dalam Survei Sampel 1. Tujuan survei.
 BAB I PENDAHULUAN 1.1 Kegunaan Metode Sampling Pengambilan sampel dari suatu survei telah menjadi sesuatu yang besar kegunaannya dalam kehidupan. Sebuah sampel terdiri sejumlah bola lampu dalam satu periode
BAB I PENDAHULUAN 1.1 Kegunaan Metode Sampling Pengambilan sampel dari suatu survei telah menjadi sesuatu yang besar kegunaannya dalam kehidupan. Sebuah sampel terdiri sejumlah bola lampu dalam satu periode
STATISTIKA EKONOMI I Chapter 4 Distribusi Probabilitas Normal dan Binomial Chapter 5 Teori Sampling
 STATISTIKA EKONOMI I Chapter 4 Distribusi Probabilitas Normal dan Binomial Chapter 5 Teori Sampling Rengganis Banitya Rachmat rengganis.rachmat@gmail.com 4. Distribusi Probabilitas Normal dan Binomial
STATISTIKA EKONOMI I Chapter 4 Distribusi Probabilitas Normal dan Binomial Chapter 5 Teori Sampling Rengganis Banitya Rachmat rengganis.rachmat@gmail.com 4. Distribusi Probabilitas Normal dan Binomial
ANALISIS DATA SECARA RANDOM PADA APLIKASI MINITAB DENGAN MENGGUNAKAN DISTRIBUSI PELUANG
 LAPORAN RESMI PRAKTIKUM PENGANTAR METODE STATISTIKA MODUL 3 ANALISIS DATA SECARA RANDOM PADA APLIKASI MINITAB DENGAN MENGGUNAKAN DISTRIBUSI PELUANG Oleh : Diana Nafkiyah 1314030028 Nilamsari Farah Millatina
LAPORAN RESMI PRAKTIKUM PENGANTAR METODE STATISTIKA MODUL 3 ANALISIS DATA SECARA RANDOM PADA APLIKASI MINITAB DENGAN MENGGUNAKAN DISTRIBUSI PELUANG Oleh : Diana Nafkiyah 1314030028 Nilamsari Farah Millatina
Statistika (MMS-1001)
") Statistika (MMS-1001) Dr. Danardono, MPH danardono@ugm.ac.id Program Studi Statistika Jurusan Matematika FMIPA UGM Materi dan Jadual Tatap Muka Pokok Bahasan Sub Pokok Bahasan 1. Statistika Deskriptif
Statistika (MMS-1001) Dr. Danardono, MPH danardono@ugm.ac.id Program Studi Statistika Jurusan Matematika FMIPA UGM Materi dan Jadual Tatap Muka Pokok Bahasan Sub Pokok Bahasan 1. Statistika Deskriptif
STATISTIKA. Muhamad Nursalman Pendilkom/Ilkom UPI
 STATISTIKA Muhamad Nursalman Pendilkom/Ilkom UPI 1 Daftar Isi Bab 1 Peluang Bab Peubah Acak Bab 3 Distribusi Peluang Diskret Bab 4 Distribusi Peluang Kontinu Bab 5 Fungsi Peubah Acak Bab 6 Teori Penaksiran
STATISTIKA Muhamad Nursalman Pendilkom/Ilkom UPI 1 Daftar Isi Bab 1 Peluang Bab Peubah Acak Bab 3 Distribusi Peluang Diskret Bab 4 Distribusi Peluang Kontinu Bab 5 Fungsi Peubah Acak Bab 6 Teori Penaksiran
PENAKSIRAN RATAAN DAN VARIANSPOPULASI PADA SAMPEL ACAK TERSTRATIFIKA DENGAN AUXILIARY VARIABLE
 Vol. 12, No. 1, 9-18, Juli 2015 PENAKSIRAN RATAAN DAN VARIANSPOPULASI PADA SAMPEL ACAK TERSTRATIFIKA DENGAN AUXILIARY VARIABLE Raupong, M. Saleh AF, Hasruni Satya Taruma Abstrak Penaksiran rataan dan variansi
Vol. 12, No. 1, 9-18, Juli 2015 PENAKSIRAN RATAAN DAN VARIANSPOPULASI PADA SAMPEL ACAK TERSTRATIFIKA DENGAN AUXILIARY VARIABLE Raupong, M. Saleh AF, Hasruni Satya Taruma Abstrak Penaksiran rataan dan variansi
Metode kuantitatif: Randomisasi 12 O K TO BER 2016
 Metode kuantitatif: Randomisasi PANJI FO RTUNA H ADI SO EMARTO M ETO DE, AP LI K ASI DAN M ANAJEM EN P ENELI TIAN K ESM AS S2 I K M FK UP 12 O K TO BER 2016 Random selection vs random allocation Dua jenis
Metode kuantitatif: Randomisasi PANJI FO RTUNA H ADI SO EMARTO M ETO DE, AP LI K ASI DAN M ANAJEM EN P ENELI TIAN K ESM AS S2 I K M FK UP 12 O K TO BER 2016 Random selection vs random allocation Dua jenis
BAB III METODE PENELITIAN. yang dibuat oleh peneliti untuk membantu mengumpulkan dan menganalisis
 BAB III METODE PENELITIAN 1.1 Desain Penelitian Untuk mendapatkan hasil penelitian yang baik maka dibutuhkan suatu desain penelitian. Desain penelitian merupakan suatu rencana atau rancangan yang dibuat
BAB III METODE PENELITIAN 1.1 Desain Penelitian Untuk mendapatkan hasil penelitian yang baik maka dibutuhkan suatu desain penelitian. Desain penelitian merupakan suatu rencana atau rancangan yang dibuat
Tugas Kelompok. Mata Kuliah Metodologi Penelitian Kuantitatif. Judul Makalah Revisi DISTRIBUSI PELUANG
 Tugas Kelompok Mata Kuliah Metodologi Penelitian Kuantitatif Judul Makalah Revisi DISTRIBUSI PELUANG Kajian Buku Pengantar Statistika Pengarang Nana Sudjana Tugas dibuat untuk memenuhi tugas mata kuliah
Tugas Kelompok Mata Kuliah Metodologi Penelitian Kuantitatif Judul Makalah Revisi DISTRIBUSI PELUANG Kajian Buku Pengantar Statistika Pengarang Nana Sudjana Tugas dibuat untuk memenuhi tugas mata kuliah
Mendefinisikan arti dari terminologi-terminologi penting dalam statistika Memahami dan menjelaskan peranan statistik dan penerapannya di bidang
 Tujuan Pembelajaran Mendefinisikan arti dari terminologi-terminologi penting dalam statistika Memahami dan menjelaskan peranan statistik dan penerapannya di bidang teknik Menjelaskan langkah-langkah dasar
Tujuan Pembelajaran Mendefinisikan arti dari terminologi-terminologi penting dalam statistika Memahami dan menjelaskan peranan statistik dan penerapannya di bidang teknik Menjelaskan langkah-langkah dasar
BAB III METODE PENELITIAN
 BAB III METODE PENELITIAN A. Metode dan Desain Penelitian Definisi desain penelitian menurut Nasution (2009:23) adalah Desain penelitian merupakan rencana tentang cara mengumpulkan dan menganalisis data
BAB III METODE PENELITIAN A. Metode dan Desain Penelitian Definisi desain penelitian menurut Nasution (2009:23) adalah Desain penelitian merupakan rencana tentang cara mengumpulkan dan menganalisis data
LAB MANAJEMEN DASAR MODUL STATISTIKA 1
 LAB MANAJEMEN DASAR MODUL STATISTIKA 1 Nama : NPM/Kelas : Fakultas/Jurusan : Hari dan Shift Praktikum : Fakultas Ekonomi Universitas Gunadarma Kelapa dua E531 1 UKURAN STATISTIK Pendahuluan Ukuran statistik
LAB MANAJEMEN DASAR MODUL STATISTIKA 1 Nama : NPM/Kelas : Fakultas/Jurusan : Hari dan Shift Praktikum : Fakultas Ekonomi Universitas Gunadarma Kelapa dua E531 1 UKURAN STATISTIK Pendahuluan Ukuran statistik
MATERI STATISTIK II. Genrawan Hoendarto
 MATERI STATISTIK II Teori Probabilitas Variabel Acak dan Nilai Harapan Distribusi Teoritis Distribusi Sampling Pengujian Hipotesis Regresi dan Korelasi Linear Sederhana Statistik Nonparametrik Daftar Pustaka
MATERI STATISTIK II Teori Probabilitas Variabel Acak dan Nilai Harapan Distribusi Teoritis Distribusi Sampling Pengujian Hipotesis Regresi dan Korelasi Linear Sederhana Statistik Nonparametrik Daftar Pustaka
Materi #13 TKT101 PENGANTAR TEKNIK INDUSTRI T a u f i q u r R a c h m a n
 Materi #13 TKT101 PENGANTAR TEKNIK INDUSTRI Kemampuan Akhir Yang Diharapkan 2 Mampu membandingkan antara kondisi nyata dengan penerapan teori yang telah dipelajari. Indikator Penilaian Ketepatan dalam
Materi #13 TKT101 PENGANTAR TEKNIK INDUSTRI Kemampuan Akhir Yang Diharapkan 2 Mampu membandingkan antara kondisi nyata dengan penerapan teori yang telah dipelajari. Indikator Penilaian Ketepatan dalam
ALUR KERJA DENGAN SAMPLE SAMPEL POPULASI TEMUAN
 POPULASI DAN SAMPEL PENGERTIAN Populasi merupakan sekumpulan orang atau objek yang memiliki kesamaan dalam satu atau beberapa hal dan yang membentuk masalah pokok dalam suatu riset khusus. Populasi yang
POPULASI DAN SAMPEL PENGERTIAN Populasi merupakan sekumpulan orang atau objek yang memiliki kesamaan dalam satu atau beberapa hal dan yang membentuk masalah pokok dalam suatu riset khusus. Populasi yang