Text Pre-Processing. M. Ali Fauzi
|
|
|
- Surya Sanjaya
- 7 tahun lalu
- Tontonan:
Transkripsi
1 Text Pre-Processing M. Ali Fauzi

2 Latar Belakang

3 Latar Belakang Dokumen-dokumen yang ada kebanyakan tidak memiliki struktur yang pasti sehingga informasi di dalamnya tidak bisa diekstrak secara langsung. Tidak semua kata mencerminkan makna/isi yang terkandung dalam sebuah dokumen.
4 Latar Belakang Dokumen-dokumen yang ada kebanyakan tidak memiliki struktur yang pasti sehingga informasi di dalamnya tidak bisa diekstrak secara langsung. Tidak semua kata mencerminkan makna/isi yang terkandung dalam sebuah dokumen.

5 Latar Belakang Preprocessing diperlukan untuk memilih kata yang akan digunakan sebagai indeks Indeks ini adalah kata-kata yang mewakili dokumen yang nantinya digunakan untuk membuat pemodelan untuk Information Retrieval maupun aplikasi teks mining lain.aaaaaaaaa

6 Latar Belakang Preprocessing diperlukan untuk memilih kata yang akan digunakan sebagai indeks Indeks ini adalah kata-kata yang mewakili dokumen yang nantinya digunakan untuk membuat pemodelan untuk Information Retrieval maupun aplikasi teks mining lain.

7 Definisi Definisi Pemrosesan Teks (Text Preprocessing) adalah suatu proses pengubahan bentuk data yang belum terstruktur menjadi data yang terstruktur sesuai dengan kebutuhan, untuk proses mining yang lebih lanjut (sentiment analysis, peringkasan, clustering dokumen, etc.).
8 Singkatnya Preprocessing adalah merubah teks menjadi term index Tujuan: menghasilkan sebuah set term index yang bisa mewakili dokumen

9 Singkatnya Preprocessing adalah merubah teks menjadi term index Tujuan: menghasilkan sebuah set term index yang bisa mewakili dokumen

10 Langkah-langkah Text Pre-processing Langkah-langkah umum dalam Text Pre-processing
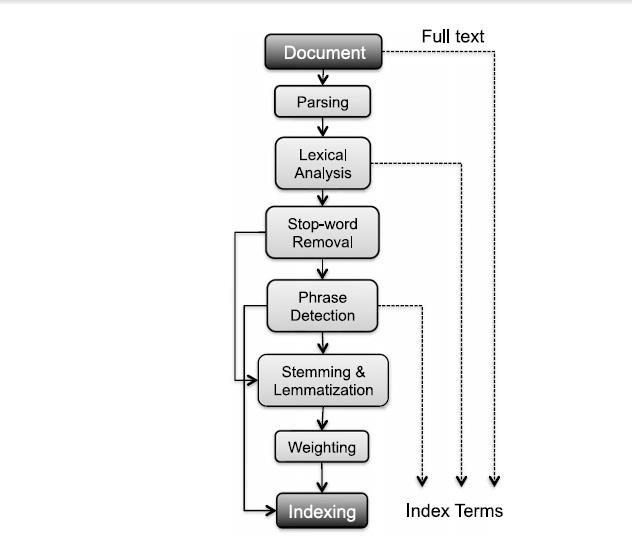
11

12 Langkah 1 : Parsing Tulisan dalam sebuah dokumen bisa jadi terdiri dari berbagai macam bahasa, character sets, dan format; Sering juga, dalam satu dokumen yang sama berisi tulisan dari beberapa bahasa. Misal, sebuah berbahasa Indonesia dengan lampiran PDF berbahasa Inggris.aa

13 Langkah 1 : Parsing Tulisan dalam sebuah dokumen bisa jadi terdiri dari berbagai macam bahasa, character sets, dan format; Sering juga, dalam satu dokumen yang sama berisi tulisan dari beberapa bahasa. Misal, sebuah berbahasa Indonesia dengan lampiran PDF berbahasa Inggris.

14 Langkah 1 : Parsing Parsing Dokumen berurusan dengan pengenalan dan pemecahan struktur dokumen menjadi komponen-komponen terpisah. Pada langkah preprocessing ini, kita menentukan mana yang dijadikan satu unit dokumen;
 dari email dan 4 dokumen dari masing-masing")
15 Langkah 1 : Parsing Contoh, dengan 4 lampiran bisa dipisah menjadi 5 dokumen : 1 dokumen yang merepresentasikan isi (body) dari dan 4 dokumen dari masing-masing lampiran
16 Langkah 1 : Parsing Contoh lain, buku dengan 100 halaman bisa dipisah menjadi 100 dokumen; masing-masing halaman menjadi 1 dokumen Satu tweet bisa dijadikan sebagai 1 dokumen. Begitu juga dengan sebuah koemntar pada forum atau review produk.

17 Langkah 1 : Parsing Contoh lain, buku dengan 100 halaman bisa dipisah menjadi 100 dokumen; masing-masing halaman menjadi 1 dokumen Satu tweet bisa dijadikan sebagai 1 dokumen. Begitu juga dengan sebuah komentar pada forum atau review produk.
18 Langkah 2 : Lexical Analysis Lebih populer disebut Lexing atau Tokenization / Tokenisasi

19 Langkah 2 : Lexical Analysis Tokenisasi adalah proses pemotongan string input berdasarkan tiap kata penyusunnya. Pada prinsipnya proses ini adalah memisahkan setiap kata yang menyusun suatu dokumen.
20 Langkah 2 : Lexical Analysis Tokenisasi adalah proses pemotongan string input berdasarkan tiap kata penyusunnya. Pada prinsipnya proses ini adalah memisahkan setiap kata yang menyusun suatu dokumen.
 dan tidak memiliki pengaruh terhadap pemrosesan")
21 Langkah 2 : Lexical Analysis Pada proses ini dilakukan penghilangan angka, tanda baca dan karakter selain huruf alfabet, karena karakter-karakter tersebut dianggap sebagai pemisah kata (delimiter) dan tidak memiliki pengaruh terhadap pemrosesan teks.

22 Langkah 2 : Lexical Analysis Pada tahapan ini juga dilakukan proses case folding, dimana semua huruf diubah menjadi huruf kecil.

23 Langkah 2 : Lexical Analysis Pada tahapan ini juga Cleaning Cleaning adalah proses membersihkan dokumen dari komponen-komponen yang tidak memiliki hubungan dengan informasi yang ada pada dokumen, seperti tag html, link, dan script

24 Langkah 2 : Lexical Analysis Pada tahapan ini juga Cleaning Cleaning adalah proses membersihkan dokumen dari komponen-komponen yang tidak memiliki hubungan dengan informasi yang ada pada dokumen, seperti tag html, link, dan script, dsb.
25 Tokens, Types, and Terms Text: apakah culo dan boyo bermain bola di depan rumah boyo? Token adalah kata-kata yang dipisahpisah dari teks aslinya tanpa mempertimbangkan adanya duplikasi Tokennya: culo, dan, boyo, bermain, bola, di, depan, rumah, boyo

26 Tokens, Types, and Terms Text: apakah culo dan boyo bermain bola di depan rumah boyo? Token adalah kata-kata yang dipisahpisah dari teks aslinya tanpa mempertimbangkan adanya duplikasi Tokennya: culo, dan, boyo, bermain, bola, di, depan, rumah, boyo
27 Tokens, Types, and Terms Text: apakah culo dan boyo bermain bola di depan rumah boyo? Token adalah kata-kata yang dipisahpisah dari teks aslinya tanpa mempertimbangkan adanya duplikasi Token: culo, dan, boyo, bermain, bola, di, depan, rumah, boyo
28 Tokens, Types, and Terms Text: apakah culo dan boyo bermain bola di depan rumah boyo? Type adalah token yang memperhatikan adanya duplikasi kata. Ketika ada duplikasi hanya dituliskan sekali saja. Type: culo, dan, boyo, bermain, bola, di, depan, rumah

29 Tokens, Types, and Terms Text: apakah culo dan boyo bermain bola di depan rumah boyo? Type adalah token yang memperhatikan adanya duplikasi kata. Ketika ada duplikasi hanya dituliskan sekali saja. Type: culo, dan, boyo, bermain, bola, di, depan, rumah

30 Tokens, Types, and Terms Text: apakah culo dan boyo bermain bola di depan rumah boyo? Token: culo, dan, boyo, bermain, bola, di, depan, rumah, boyo Type: culo, dan, boyo, bermain, bola, di, depan, rumah
31 Tokens, Types, and Terms Text: apakah culo dan boyo bermain bola di depan rumah boyo? Term adalah type yang sudah dinormalisasi (dilakukan stemming, filtering, dsb) Term : culo, boyo, main, bola, depan, rumah
 Term : culo, boyo, main,")
32 Tokens, Types, and Terms Text: apakah culo dan boyo bermain bola di depan rumah boyo? Term adalah type yang sudah dinormalisasi (dilakukan stemming, filtering, dsb) Term : culo, boyo, main, bola, depan, rumah

33 Tokens, Types, and Terms Text: apakah culo dan boyo bermain bola di depan rumah boyo? Token: culo, dan, boyo, bermain, bola, di, depan, rumah, boyo Type: culo, dan, boyo, bermain, bola, di, depan, rumah Term: culo, boyo, main, bola, depan, rumah
34 Contoh Tokenisasi Teks English Tokens They are applied to the words in the texts. they are applied to the words in the texts
35 Contoh Tokenisasi Teks Bahasa Tokens Namanya adalah Santiago. Santiago sudah memutuskan untuk mencari sang alkemis. namanya adalah santiago santiago sudah memutuskan untuk mencari sang alkemis
36 Langkah 3 : Stopword Removal Disebut juga Filtering Filtering adalah tahap pengambilan dari hasil token, yaitu kata-kata apa saja yang akan digunakan untuk merepresentasikan dokumen.
37 Langkah 3 : Stopword Removal Disebut juga Filtering Filtering adalah tahap pemilihan katakata penting dari hasil token, yaitu katakata apa saja yang akan digunakan untuk mewakili dokumen.
38 Stopword Removal : Metode Algoritma stoplist Stoplist atau stopword adalah katakata yang tidak deskriptif (tidak penting) yang dapat dibuang dengan pendekatan bag-of-words.
39 Stopword Removal : Metode Algoritma stoplist Stoplist atau stopword adalah katakata yang tidak deskriptif (tidak penting) yang dapat dibuang dengan pendekatan bag-of-words.

40 Stopword Removal : Metode Algoritma stoplist Kita memiliki database kumpulan katakata yang tidak deskriptif (tidak penting), kemudian kalau hasil tokenisasi itu ada yang merupakan kata tidak penting dalam database tersebut, maka hasil tokenisasi itu dibuang.
41 Stopword Removal : Metode Algoritma stoplist Contoh stopwords adalah i m, you, one, two, they, are, to, the, in, dst.
42 Stopword Removal : Metode Hasil Token Hasil Filtering they - are - applied applied to - the - words words in - the - texts texts
43 Stopword Removal : Metode Algoritma stoplist Contoh stopwords adalah untuk, sang, sudah, adalah, dst.
44 Stopword Removal : Metode Hasil Token Hasil Filtering namanya namanya adalah - santiago santiago santiago santiago sudah - memutuskan memutuskan untuk - mencari mencari sang - alkemis alkemis
 yang harus disimpan dan tidak dibuang dengan pendekatan")
45 Stopword Removal : Metode Algoritma wordlist Wordlist adalah kata-kata yang deskriptif (penting) yang harus disimpan dan tidak dibuang dengan pendekatan bag-of-words.
 yang harus disimpan dan tidak dibuang dengan pendekatan")
46 Stopword Removal : Metode Algoritma wordlist Wordlist adalah kata-kata yang deskriptif (penting) yang harus disimpan dan tidak dibuang dengan pendekatan bag-of-words.
47 Stopword Removal : Metode Algoritma wordlist Kita memiliki database kumpulan katakata yang deskriptif (penting), kemudian kalau hasil tokenisasi itu ada yang merupakan kata penting dalam database tersebut, maka hasil tokenisasi itu disimpan.

48 Stopword Removal : Metode Algoritma wordlist Contoh wordlist adalah applied, words, texts, dst.
49 Stopword Removal : Metode Hasil Token Hasil Filtering they - are - applied applied to - the - words words in - the - texts texts

50 Stopword Removal : Metode Algoritma wordlist Contoh wordlist adalah santiago, namanya, mencari, memutuskan, alkemis, dst.
51 Stopword Removal : Metode Hasil Token Hasil Filtering namanya namanya adalah - santiago santiago santiago santiago sudah - memutuskan memutuskan untuk - mencari mencari sang - alkemis alkemis

52 Using Stop Words or Not? Kebanyakan aplikasi text mining ataupun IR bisa ditingkatkan performanya dengan penghilangan stopword. Akan tetapi, secara umum Web search engines seperti google sebenarnya tidak menghilangkan stop word, karena algoritma yang mereka gunakan berhasil memanfaatkan stopword dengan baikaaa
53 Using Stop Words or Not? Kebanyakan aplikasi text mining ataupun IR bisa ditingkatkan performanya dengan penghilangan stopword. Akan tetapi, secara umum Web search engines seperti google sebenarnya tidak menghilangkan stop word, karena algoritma yang mereka gunakan berhasil memanfaatkan stopword dengan baik.

54 Langkah 4 : Phrase Detection Langkah ini bisa menangkap informasi dalam teks melebihi kemampuan dari metode tokenisasi / bag-of-word murni.

55 Langkah 4 : Phrase Detection Pada langkah ini tidak hanya dilakukan tokenisasi per kata, namun juga mendeteksi adanya 2 kata atau lebih yang menjadi frase.

56 Langkah 4 : Phrase Detection Contoh, dari dokumen ini : search engines are the most visible information retrieval applications Terdapat dua buah frase, yaitu search engines dan information retrieval.
57 Langkah 4 : Phrase Detection Phrase detection bisa dilakukan dengan beberapa cara : menggunakan rule/aturan (misal dengan menganggap dua kata yang sering muncul berurutan sebagai frase), bisa dengan syntactic analysis, and kombinasi keduanya.

58 Langkah 4 : Phrase Detection Metode umum yang diguakan adalah penggunaan thesauri untuk mendeteksi adanya frase. Contoh : Pada thesauri tersebut terdapat daftar frase-fase dalam bahasa tertentu, kemudia kita bandingkan kata-kata dalam teks apakah mengandung frasefrase dalam thesauri tersebut atau tidak.aaa

59 Langkah 4 : Phrase Detection Metode umum yang diguakan adalah penggunaan thesauri untuk mendeteksi adanya frase. Contoh : Pada thesauri tersebut terdapat daftar frase-fase dalam bahasa tertentu, kemudia kita bandingkan kata-kata dalam teks apakah mengandung frase-frase dalam thesauri tersebut atau tidak.

60 Langkah 4 : Phrase Detection Kelemahanya, tahap ini butuh komputasi yang cukup lama Kebanyakan aplikasi teks mining atau IR tidak menggunakan Phrase Detection Sudah cukup dengan Token per Kata Akan tetapi, sebenarnya pemanfaatan Phrase akan meningkatkan akurasi
61 Langkah 4 : Phrase Detection Kelemahanya, tahap ini butuh komputasi yang cukup lama Kebanyakan aplikasi teks mining atau IR tidak menggunakan Phrase Detection Sudah cukup dengan Token per Kata Akan tetapi, sebenarnya pemanfaatan Phrase akan meningkatkan akurasi

62 Langkah 5 : Stemming Stemming adalah proses pengubahan bentuk kata menjadi kata dasar atau tahap mencari root kata dari tiap kata hasil filtering.

63 Langkah 5 : Stemming Dengan dilakukanya proses stemming setiap kata berimbuhan akan berubah menjadi kata dasar, dengan demikian dapat lebih mengoptimalkan proses teks mining.
64 Langkah 5 : Stemming Hasil Token Hasil Filtering Hasil Stemming they - - are - - applied applied apply to - - the - - words words word in - - the - - texts texts text
65 Langkah 5 : Stemming Hasil Token Hasil Filtering Hasil Stemming namanya namanya nama adalah - - santiago santiago santiago santiago santiago santiago sudah - - memutuskan memutuskan putus untuk - - mencari mencari cari sang - - alkemis alkemis alkemis
 Stemming Arifin-Setiono (Indonesia) Stemming Nazief-Adriani")
66 Langkah 5 : Stemming Implementasi proses stemming sangat beragam, tergantung dengan bahasa dari dokumen. Beberapa metode untuk Stemming : Porter Stemmer (English & Indonesia) Stemming Arifin-Setiono (Indonesia) Stemming Nazief-Adriani (Indonesia) Khoja (Arabic)
67 Langkah 5 : Stemming Implementasi proses stemming sangat beragam, tergantung dengan bahasa dari dokumen. Beberapa metode untuk Stemming : Porter Stemmer (English & Indonesia) Stemming Arifin-Setiono (Indonesia) Stemming Nazief-Adriani (Indonesia) Khoja (Arabic)

68 Stemming : Metode Algorithmic: Membuat sebuah algoritma yang mendeteksi imbuhan. Jika ada awalan atau akhiran yang seperti imbuhan, maka akan dibuang.
69 Stemming : Metode Algorithmic
70 Stemming : Metode Metode Algorithmic Kelebihan : relatif cepat Kekurangan : beberapa algoritma terkadang salah mendeteksi imbuhan, sehingga ada beberapa kata yang bukan imbuhan tapi dihilangkan Contoh : makan -> mak; an dideteksi sebagai akhiran sehingga dibuang.

71 Stemming : Metode Metode Algorithmic Kelebihan : relatif cepat Kekurangan : beberapa algoritma terkadang salah mendeteksi imbuhan, sehingga ada beberapa kata yang bukan imbuhan tapi dihilangkan Contoh : makan -> mak; an dideteksi sebagai akhiran sehingga dibuang.
72 Stemming : Metode Metode Algorithmic Kelebihan : relatif cepat Kekurangan : beberapa algoritma terkadang salah mendeteksi imbuhan, sehingga ada beberapa kata yang bukan imbuhan tapi dihilangkan Contoh : makan -> mak; an dideteksi sebagai akhiran sehingga dibuang.

73 Stemming : Metode Metode Lemmatization Lemmatization : Stemming berdasarkan kamus Menggunakan vocabulary dan morphological analysis dari kata untuk menghilangkan imbuhan dan dikembalikan ke bentuk dasar dari kata.
74 Stemming : Metode Metode Lemmatization Lemmatization : Stemming berdasarkan kamus Menggunakan vocabulary dan morphological analysis dari kata untuk menghilangkan imbuhan dan dikembalikan ke bentuk dasar dari kata.
 Contoh : see -> see, saw, atau seen Jika ada kata see, saw, atau seen, bisa dikembalikan ke bentuk aslinya yaitu")
75 Stemming : Metode Metode Lemmatization Stemming ini bagus untuk kata-kata yang mengalami perubahan tidak beraturan (terutama dalam english) Contoh : see -> see, saw, atau seen Jika ada kata see, saw, atau seen, bisa dikembalikan ke bentuk aslinya yaitu see
 Contoh : see -> see, saw, atau seen Jika ada kata see, saw, atau seen, bisa dikembalikan ke bentuk aslinya yaitu")
76 Stemming : Metode Metode Lemmatization Stemming ini bagus untuk kata-kata yang mengalami perubahan tidak beraturan (terutama dalam english) Contoh : see -> see, saw, atau seen Jika ada kata see, saw, atau seen, bisa dikembalikan ke bentuk aslinya yaitu see

77 Stemming : Metode Algoritma Porter Stemming merupakan algoritma yang paling populer. Ditemukan oleh Martin Porter pada tahun Mekanisme algoritma tersebut dalam mencari kata dasar suatu kata berimbuhan, yaitu dengan membuang imbuhan imbuhan (atau lebih tepatnya akhiran pada kata kata bahasa Inggris karena dalam bahasa Inggris tidak mengenal awalan).
78 Langkah 5 : Stemming Hasil Token Hasil Filtering Hasil Stemming Type they are Term applied applied apply apply apply to the words words word word word in the texts texts text text text
79 Langkah 5 : Stemming Hasil Token Hasil Filtering Hasil Stemming Type Term namanya namanya nama nama nama adalah santiago santiago santiago santiago santiago santiago santiago santiago - - sudah memutusk an memutusk an putus putus putus untuk mencari mencari cari cari cari sang alkemis alkemis alkemis alkemis alkemis
80 Studi Kasus Dokumen Ke-i Isi Dokumen pembukaan daftar wisuda dan pelaksanaan nya lebih baik d umumkan di web ub tidak hanya di fakultas. sehingga memudahkan mahasiswa yang ada di luar kota. pelaksanaan wisuda sebaiknya terjadwal tidak tergantung pada kuota. sehingga lebih cepat mendapat ijazah. dalam setahun belakangan ini, pengaksesan KRS diganti ke SIAM (sebelumnya menggunakan SINERGI). saat menggunakan sinergi, fitur serta kecepatan akses sangat handal dan nyaman. tapi setelah diganti menggunakan SIAM, keadaan berbalik menjadi buruk (lambat loading dan bahkan sampai logout dengan sendirinya). *KRS tidak hanya berpengaruh bagi mahasiswa semester muda tapi juga keseluruhan mahasiswa Assalamualaikum Wr. Wb. yang menjadi salah satu syarat untuk bisa ujian kompre ada sertifikat TOEIC, sehingga jika belum lulus toeic maka tidak bisa melakukan ujian kompre. saya rasa ini sangat menghambat teman-teman yang memang lemah dibidang bahasa inggris (atau yang kurang beruntung dalam ujian toeic-nya). sehingga mereka tidak bisa fokus untuk ujian kompre-nya. terima kasih.. pak/bu dosen saya mau minta keringanan biaya proposional dan spp,soalnya ibu saya keberatan dengan biaya itu? terima kasih atas perhatiannya.

81 Studi Kasus Dokume n Ke-i Isi Dokumen Tokenisasi Filtering Stemming 1 pembukaan daftar wisuda dan pelaksanaan nya lebih baik d umumkan di web ub tidak hanya di fakultas. sehingga memudahkan mahasiswa yang ada di luar kota. pelaksanaan wisuda sebaiknya terjadwal tidak tergantung pada kuota. sehingga lebih cepat mendapat ijazah. pembukaan daftar wisuda dan pelaksanaan nya lebih baik d umumkan di web ub tidak hanya di fakultas sehingga memudahkan mahasiswa yang ada di luar kota pelaksanaan wisuda sebaiknya terjadwal tidak tergantung pada kuota sehingga lebih cepat mendapat ijazah pembukaan daftar wisuda pelaksanaan umumkan web ub fakultas memudahkan mahasiswa kota pelaksanaan wisuda sebaiknya terjadwal tergantung kuota cepat ijazah buka daftar wisuda laksana umum web ub fakultas mudah mahasiswa kota laksana wisuda baik jadwal gantung kuota cepat ijazah 2 dalam setahun belakangan ini, pengaksesan KRS diganti ke SIAM (sebelumnya menggunakan SINERGI). saat menggunakan sinergi, fitur serta kecepatan akses sangat handal dan nyaman. tapi setelah diganti menggunakan SIAM, keadaan berbalik menjadi buruk (lambat loading dan bahkan sampai logout dengan sendirinya). *KRS tidak hanya berpengaruh bagi mahasiswa semester muda tapi juga keseluruhan mahasiswa dalam setahun belakangan ini pengaksesan krs diganti ke siam sebelumnya menggunakan sinergi saat menggunakan sinergi fitur serta kecepatan akses sangat handal dan nyaman tapi setelah diganti menggunakan siam keadaan berbalik menjadi buruk lambat loading dan bahkan sampai logout dengan sendirinya krs tidak hanya berpengaruh bagi mahasiswa semester muda tapi juga keseluruhan mahasiswa setahun belakangan pengaksesan krs diganti siam sinergi sinergi fitur kecepatan akses handal nyaman diganti siam keadaan berbalik buruk lambat loading logout sendirinya krs berpengaruh mahasiswa semester muda keseluruhan mahasiswa tahun belakang akses krs ganti siam sinergi sinergi fitur cepat akses handal nyaman ganti siam ada balik buruk lambat loading logout sendiri krs pengaruh mahasiswa semester muda luruh mahasiswa 3 Assalamualaikum Wr. Wb. yang menjadi salah satu syarat untuk bisa ujian kompre ada sertifikat TOEIC, sehingga jika belum lulus toeic maka tidak bisa melakukan ujian kompre. saya rasa ini sangat menghambat teman-teman yang memang lemah dibidang bahasa inggris (atau yang kurang beruntung dalam ujian toeic-nya). sehingga mereka tidak bisa fokus untuk ujian komprenya. terima kasih.. assalamualaikum wr wb yang menjadi salah satu syarat untuk bisa ujian kompre ada sertifikat toeic sehingga jika belum lulus toeic maka tidak bisa melakukan ujian kompre saya rasa ini sangat menghambat teman teman yang memang lemah dibidang bahasa inggris atau yang kurang beruntung dalam ujian toeic nya sehingga mereka tidak bisa fokus untuk ujian kompre nya terima kasih assalamualaikum wr wb syarat ujian kompre sertifikat toeic lulus toeic ujian kompre menghambat lemah dibidang bahasa inggris kurang beruntung ujian toeic fokus ujian kompre terima kasih assalamualaikum wr wb syarat uji kompre sertifikat toeic lulus toeic uji kompre hambat lemah bidang bahasa inggris kurang untung uji toeic fokus uji kompre terima kasih 4 pak/bu dosen saya mau minta keringanan biaya proposional dan spp,soalnya ibu saya keberatan dengan biaya itu? terima kasih atas perhatiannya. pak bu dosen saya mau minta keringanan biaya proposional dan spp soalnya ibu saya keberatan dengan biaya itu terima kasih atas perhatiannya pak bu dosen minta keringanan biaya proposional spp soalnya ibu keberatan biaya terima kasih perhatiannya pak bu dosen minta ringan biaya proposional spp soal ibu berat biaya terima kasih hati
82 Latihan : Tentukan hasil Tokenisasi, Filtering dan Stemming setiap dokumen tersebut Dokumen (Doc) Doc 1 Doc 2 Doc 3 Doc 4 Isi (Content) elearning di PTIIK diatas jam 6 malam kok selalu gak bisa dibuka ya? ub tidak punya lahan parkir yang layak. Dan jalanan terlalu ramai karena di buka untuk umum. Seperti jalan tol saja. Brawijaya oh brawijaya Kelas Arsitektur dan Organisasi Komputer penuh, apakah tidak dibuka kelas lagi. Rugi kalo saya bisa ngambil 24 SKS tapi baru 18 SKS yg terpenuhi Informasi tata cara daftar ulang bagi mahasiswa baru PTIIK kurang jelas. Sehingga ketika tanggal terakhir syarat penyerahan berkas daftar ulang, banyak mahasiswa baru yang tidak membawa salah satu syarat daftar ulangnya.
BAB II LANDASAN TEORI
 BAB II LANDASAN TEORI II.1 Text Mining Text Mining merupakan penerapan konsep dan teknik data mining untuk mencari pola dalam teks, proses penganalisaan teks guna menemukan informasi yang bermanfaat untuk
BAB II LANDASAN TEORI II.1 Text Mining Text Mining merupakan penerapan konsep dan teknik data mining untuk mencari pola dalam teks, proses penganalisaan teks guna menemukan informasi yang bermanfaat untuk
BAB II LANDASAN TEORI
 BAB II LANDASAN TEORI 2.1 Klasifikasi Klasifikasi merupakan suatu pekerjaan menilai objek data untuk memasukkannya ke dalam kelas tertentu dari sejumlah kelas yang tersedia. Dalam klasifikasi ada dua pekerjaan
BAB II LANDASAN TEORI 2.1 Klasifikasi Klasifikasi merupakan suatu pekerjaan menilai objek data untuk memasukkannya ke dalam kelas tertentu dari sejumlah kelas yang tersedia. Dalam klasifikasi ada dua pekerjaan
PERBANDINGAN ALGORITMA STEMMING PADATEKS BAHASA INDONESIA
 PERBANDINGAN ALGORITMA STEMMING PADATEKS BAHASA INDONESIA Sigit Prasetyo Karisma Utomo 1, Ema Utami 2, Andi Sunyoto 3 1,2,3 Magister Teknik Informatika STMIK AmikomYogyakarta e-mail: 1 aku@sigitt.com,
PERBANDINGAN ALGORITMA STEMMING PADATEKS BAHASA INDONESIA Sigit Prasetyo Karisma Utomo 1, Ema Utami 2, Andi Sunyoto 3 1,2,3 Magister Teknik Informatika STMIK AmikomYogyakarta e-mail: 1 aku@sigitt.com,
Document Indexing dan Term Weighting. M. Ali Fauzi
 Document Indexing dan Term Weighting M. Ali Fauzi Document Indexing Setelah melakukan preprocessing, kita akan mendapatkan sebuah set term yang bisa kita jadikan sebagai indeks. Indeks adalah perwakilan
Document Indexing dan Term Weighting M. Ali Fauzi Document Indexing Setelah melakukan preprocessing, kita akan mendapatkan sebuah set term yang bisa kita jadikan sebagai indeks. Indeks adalah perwakilan
BAB III METODOLOGI PENELITIAN
 BAB III METODOLOGI PENELITIAN Metodologi penelitian merupakan rangkaian dari langkah-langkah yang diterapkan dalam penelitian, secara umum dan khusus langkah-langkah tersebut tertera pada Gambar flowchart
BAB III METODOLOGI PENELITIAN Metodologi penelitian merupakan rangkaian dari langkah-langkah yang diterapkan dalam penelitian, secara umum dan khusus langkah-langkah tersebut tertera pada Gambar flowchart
BAB II LANDASAN TEORI. 2.1 Peringkasan Teks Otomatis (Automatic Text Summarization) Peringkasan Teks Otomatis (Automatic Text Summarization) merupakan
 Peringkasan Teks Otomatis (Automatic Text Summarization) merupakan") BAB II LANDASAN TEORI 2.1 Peringkasan Teks Otomatis (Automatic Text Summarization) Peringkasan Teks Otomatis (Automatic Text Summarization) merupakan pembuatan rangkuman dari sebuah sumber teks secara
BAB II LANDASAN TEORI 2.1 Peringkasan Teks Otomatis (Automatic Text Summarization) Peringkasan Teks Otomatis (Automatic Text Summarization) merupakan pembuatan rangkuman dari sebuah sumber teks secara
BAB 3 ANALISIS MASALAH DAN PERANCANGAN
 BAB 3 ANALISIS MASALAH DAN PERANCANGAN 3.1 State of the Art Pada penelitian sebelumnya sudah ada yang menggunakan metode Stemming untuk preprocessing text dalam mengolah data pelatihan dan data uji untuk
BAB 3 ANALISIS MASALAH DAN PERANCANGAN 3.1 State of the Art Pada penelitian sebelumnya sudah ada yang menggunakan metode Stemming untuk preprocessing text dalam mengolah data pelatihan dan data uji untuk
BAB III METODOLOGI PENELITIAN
 BAB III METODOLOGI PENELITIAN Metodologi penelitian merupakan sistematika tahap-tahap yang dilaksanakan dalam pembuatan tugas akhir. Adapun tahapan yang dilalui dalam pelaksanaan penelitian ini adalah
BAB III METODOLOGI PENELITIAN Metodologi penelitian merupakan sistematika tahap-tahap yang dilaksanakan dalam pembuatan tugas akhir. Adapun tahapan yang dilalui dalam pelaksanaan penelitian ini adalah
BAB II LANDASAN TEORI
 BAB II LANDASAN TEORI 2.1 Peringkasan Teks Otomatis (Automatic Text Summarization) Peringkasan Teks Otomatis (Automatic Text Summarization) merupakan pembuatan rangkuman dari sebuah sumber teks secara
BAB II LANDASAN TEORI 2.1 Peringkasan Teks Otomatis (Automatic Text Summarization) Peringkasan Teks Otomatis (Automatic Text Summarization) merupakan pembuatan rangkuman dari sebuah sumber teks secara
BAB 3 LANDASAN TEORI
 BAB 3 LANDASAN TEORI 3.1 Twitter API Application Programming Interface (API) merupakan fungsi-fungsi/perintah-perintah untuk menggantikan bahasa yang digunakan dalam system calls dengan bahasa yang lebih
BAB 3 LANDASAN TEORI 3.1 Twitter API Application Programming Interface (API) merupakan fungsi-fungsi/perintah-perintah untuk menggantikan bahasa yang digunakan dalam system calls dengan bahasa yang lebih
Text Mining. Budi Susanto. Text dan Web Mining. Teknik Informatika UKDW Yogyakarta
 Text Mining Budi Susanto Materi Pengertian Text Mining Pemrosesan Text Tokenisasi Lemmatization Vector Document Pengertian Text Mining Text mining merupakan penerapan konsep dan teknik data mining untuk
Text Mining Budi Susanto Materi Pengertian Text Mining Pemrosesan Text Tokenisasi Lemmatization Vector Document Pengertian Text Mining Text mining merupakan penerapan konsep dan teknik data mining untuk
BAB III ANALISIS DAN PERANCANGAN
 BAB III ANALISIS DAN PERANCANGAN Dalam bab ini akan dijabarkan analisa, yang meliputi analisa masalah dan gambaran umum masalah yang sedang dibahas, perancangan sistem serta desain antarmuka (user interface)
BAB III ANALISIS DAN PERANCANGAN Dalam bab ini akan dijabarkan analisa, yang meliputi analisa masalah dan gambaran umum masalah yang sedang dibahas, perancangan sistem serta desain antarmuka (user interface)
ANALISA KOMPETENSI DOSEN DALAM PENENTUAN MATAKULIAH YANG DIAMPU MENGGUNAKAN METODE CF-IDF A B S T R A K
 ANALISA KOMPETENSI DOSEN DALAM PENENTUAN MATAKULIAH YANG DIAMPU MENGGUNAKAN METODE CF-IDF Oleh : Tacbir Hendro Pudjiantoro A B S T R A K Kompetensi dosen adalah salah satu bagian yang utama dalam penunjukan
ANALISA KOMPETENSI DOSEN DALAM PENENTUAN MATAKULIAH YANG DIAMPU MENGGUNAKAN METODE CF-IDF Oleh : Tacbir Hendro Pudjiantoro A B S T R A K Kompetensi dosen adalah salah satu bagian yang utama dalam penunjukan
BAB III METODOLOGI PENELITIAN
 BAB III METODOLOGI PENELITIAN Pada penelitian tugas akhir ini ada beberapa tahapan penelitian yang akan dilakukan seperti yang terlihat pada gambar 3.1: Identifikasi Masalah Rumusan Masalah Studi Pustaka
BAB III METODOLOGI PENELITIAN Pada penelitian tugas akhir ini ada beberapa tahapan penelitian yang akan dilakukan seperti yang terlihat pada gambar 3.1: Identifikasi Masalah Rumusan Masalah Studi Pustaka
BAB I PENDAHULUAN. informasi pada ruang lingkup besar (biasanya disimpan di komputer). Di era
. Di era") BAB I PENDAHULUAN 1.1 Latar Belakang Information retrieval atau disingkat dengan IR adalah menemukan bahan (dokumen) dari dokumen terstruktur (biasanya teks) yang memenuhi kebutuhan informasi pada ruang
BAB I PENDAHULUAN 1.1 Latar Belakang Information retrieval atau disingkat dengan IR adalah menemukan bahan (dokumen) dari dokumen terstruktur (biasanya teks) yang memenuhi kebutuhan informasi pada ruang
commit to user 5 BAB II TINJAUAN PUSTAKA 2.1 Dasar Teori Text mining
 BAB II TINJAUAN PUSTAKA 2.1 Dasar Teori 2.1.1 Text mining Text mining adalah proses menemukan hal baru, yang sebelumnya tidak diketahui, mengenai informasi yang berpotensi untuk diambil manfaatnya dari
BAB II TINJAUAN PUSTAKA 2.1 Dasar Teori 2.1.1 Text mining Text mining adalah proses menemukan hal baru, yang sebelumnya tidak diketahui, mengenai informasi yang berpotensi untuk diambil manfaatnya dari
Pemodelan Penilaian Essay Otomatis Secara Realtime Menggunakan Kombinasi Text Stemming Dan Cosine Similarity
 Konferensi Nasional Sistem & Informatika 2017 STMIK STIKOM Bali, 10 Agustus 2017 Pemodelan Penilaian Essay Otomatis Secara Realtime Menggunakan Kombinasi Text Stemming Dan Cosine Similarity Komang Rinartha
Konferensi Nasional Sistem & Informatika 2017 STMIK STIKOM Bali, 10 Agustus 2017 Pemodelan Penilaian Essay Otomatis Secara Realtime Menggunakan Kombinasi Text Stemming Dan Cosine Similarity Komang Rinartha
PEMANFAATAN TEKNIK STEMMING UNTUK APLIKASI TEXT PROCESSING BAHASA INDONESIA SKRIPSI. Oleh : SEPTIAN BAGUS WAHYONO NPM :
 PEMANFAATAN TEKNIK STEMMING UNTUK APLIKASI TEXT PROCESSING BAHASA INDONESIA SKRIPSI Oleh : SEPTIAN BAGUS WAHYONO NPM : 0734010126 PROGRAM STUDI TEKNIK INFORMATIKA FAKULTAS TEKNOLOGI INDUSTRI UNIVERSITAS
PEMANFAATAN TEKNIK STEMMING UNTUK APLIKASI TEXT PROCESSING BAHASA INDONESIA SKRIPSI Oleh : SEPTIAN BAGUS WAHYONO NPM : 0734010126 PROGRAM STUDI TEKNIK INFORMATIKA FAKULTAS TEKNOLOGI INDUSTRI UNIVERSITAS
BAB II TINJAUAN PUSTAKA
 BAB II TINJAUAN PUSTAKA 2.1 Sistem Rekomendasi Sistem rekomendasi adalah sebuah sistem yang dibangun untuk mengusulkan informasi dan menyediakan fasilitas yang diinginkan pengguna dalam membuat suatu keputusan
BAB II TINJAUAN PUSTAKA 2.1 Sistem Rekomendasi Sistem rekomendasi adalah sebuah sistem yang dibangun untuk mengusulkan informasi dan menyediakan fasilitas yang diinginkan pengguna dalam membuat suatu keputusan
Preprocessing Text Mining Pada Box Berbahasa Indonesia
 Konferensi Nasional Sistem & Informatika 2017 STMIK STIKOM Bali, 10 Agustus 2017 Preprocessing Text Mining Pada Email Box Berbahasa Indonesia Gusti Ngurah Mega Nata 1), Putu Pande Yudiastra 2) STMIK STIKOM
Konferensi Nasional Sistem & Informatika 2017 STMIK STIKOM Bali, 10 Agustus 2017 Preprocessing Text Mining Pada Email Box Berbahasa Indonesia Gusti Ngurah Mega Nata 1), Putu Pande Yudiastra 2) STMIK STIKOM
Sistem Temu Kembali Informasi/ Information Retrieval IRS VS SI LAIN
 Sistem Temu Kembali Informasi/ Information Retrieval IRS VS SI LAIN Dokumen Penyimpanan yang Terorganisasi Database Mahasiswa Database Buku ID Nama Buku Pengarang 001 Information Retrieval Ricardo baeza
Sistem Temu Kembali Informasi/ Information Retrieval IRS VS SI LAIN Dokumen Penyimpanan yang Terorganisasi Database Mahasiswa Database Buku ID Nama Buku Pengarang 001 Information Retrieval Ricardo baeza
BAB II LANDASAN TEORI
 BAB II LANDASAN TEORI 2.1 Klasifikasi Klasifikasi merupakan suatu pekerjaan menilai objek data untuk memasukkannya ke dalam kelas tertentu dari sejumlah kelas yang tersedia. Dalam klasifikasi ada dua pekerjaan
BAB II LANDASAN TEORI 2.1 Klasifikasi Klasifikasi merupakan suatu pekerjaan menilai objek data untuk memasukkannya ke dalam kelas tertentu dari sejumlah kelas yang tersedia. Dalam klasifikasi ada dua pekerjaan
BAB II LANDASAN TEORI
 BAB II LANDASAN TEORI 2.1. Information Retrieval Perkembangan teknologi internet yang sangat pesat membuat pengguna harus dapat menyaring informasi yang dibutuhkannya. Information retrieval atau sistem
BAB II LANDASAN TEORI 2.1. Information Retrieval Perkembangan teknologi internet yang sangat pesat membuat pengguna harus dapat menyaring informasi yang dibutuhkannya. Information retrieval atau sistem
Prosiding SENTIA 2015 Politeknik Negeri Malang Volume 7 ISSN:
 KLASIFIKASI TUGAS AKHIR UNTUK MENENTUKAN DOSEN PEMBIMBING MENGGUNAKAN NAÏVE BAYES CLASSIFIER (NBC) Putri Elfa Mas`udia 1 Politeknik Negeri Malang E-mail : putri.elfa@polinema.ac.id Abstrak Pemilihan dosen
KLASIFIKASI TUGAS AKHIR UNTUK MENENTUKAN DOSEN PEMBIMBING MENGGUNAKAN NAÏVE BAYES CLASSIFIER (NBC) Putri Elfa Mas`udia 1 Politeknik Negeri Malang E-mail : putri.elfa@polinema.ac.id Abstrak Pemilihan dosen
PENERAPAN VECTOR SPACE MODEL UNTUK PERINGKASAN KOMENTAR ANGKET MAHASISWA
 PENERAPAN VECTOR SPACE MODEL UNTUK PERINGKASAN KOMENTAR ANGKET MAHASISWA Suprianto 1), Sunardi 2), Abdul Fadlil 3) 1 Sistem Informasi STMIK PPKIA Tarakanita Rahmawati 2,3 Magister Teknik Informatika Universitas
PENERAPAN VECTOR SPACE MODEL UNTUK PERINGKASAN KOMENTAR ANGKET MAHASISWA Suprianto 1), Sunardi 2), Abdul Fadlil 3) 1 Sistem Informasi STMIK PPKIA Tarakanita Rahmawati 2,3 Magister Teknik Informatika Universitas
BAB I PENDAHULUAN. 1.1 Latar Belakang Masalah
 BAB I PENDAHULUAN 1.1 Latar Belakang Masalah Information Retrieval (pencarian Informasi) adalah proses pemisahan dokumen-dokumen dari sekumpulan dokumen yang ada untuk memenuhi kebutuhan pengguna. Jumlah
BAB I PENDAHULUAN 1.1 Latar Belakang Masalah Information Retrieval (pencarian Informasi) adalah proses pemisahan dokumen-dokumen dari sekumpulan dokumen yang ada untuk memenuhi kebutuhan pengguna. Jumlah
RANCANG BANGUN SISTEM TEMU KEMBALI INFORMASI ABSTRAK TUGAS AKHIR MAHASISWA PRODI TEKNIK INFORMATIKA UNSOED Oleh : Lasmedi Afuan
 RANCANG BANGUN SISTEM TEMU KEMBALI INFORMASI ABSTRAK TUGAS AKHIR MAHASISWA PRODI TEKNIK INFORMATIKA UNSOED Oleh : Lasmedi Afuan Prodi Teknik Informatika, Fakultas Sains dan Teknik, Universitas Jenderal
RANCANG BANGUN SISTEM TEMU KEMBALI INFORMASI ABSTRAK TUGAS AKHIR MAHASISWA PRODI TEKNIK INFORMATIKA UNSOED Oleh : Lasmedi Afuan Prodi Teknik Informatika, Fakultas Sains dan Teknik, Universitas Jenderal
JULIO ADISANTOSO - ILKOM IPB 1
 KOM341 Temu Kembali Informasi KULIAH #3 Inverted Index Inverted index construction Kumpulan dokumen Token Modifikasi token Tokenizer Linguistic modules perkebunan, pertanian, dan kehutanan perkebunan pertanian
KOM341 Temu Kembali Informasi KULIAH #3 Inverted Index Inverted index construction Kumpulan dokumen Token Modifikasi token Tokenizer Linguistic modules perkebunan, pertanian, dan kehutanan perkebunan pertanian
Gambar 1.1 Proses Text Mining [7]
![Gambar 1.1 Proses Text Mining [7]](/thumbs/64/52232326.jpg "Gambar 1.1 Proses Text Mining [7]") 1. BAB II LANDASAN TEORI 2.1 Text Mining Text mining memiliki definisi menambang data yang berupa teks dimana sumber data biasanya didapatkan dari dokumen, dan tujuannya adalah mencari kata-kata yang dapat
1. BAB II LANDASAN TEORI 2.1 Text Mining Text mining memiliki definisi menambang data yang berupa teks dimana sumber data biasanya didapatkan dari dokumen, dan tujuannya adalah mencari kata-kata yang dapat
BAB 1 PENDAHULUAN UKDW
 BAB 1 PENDAHULUAN 1.1 Latar Belakang Masalah Perkembangan ilmu pengetahuan yang pesat dewasa ini telah mendorong permintaan akan kebutuhan informasi ilmu pengetahuan itu sendiri. Cara pemenuhan kebutuhan
BAB 1 PENDAHULUAN 1.1 Latar Belakang Masalah Perkembangan ilmu pengetahuan yang pesat dewasa ini telah mendorong permintaan akan kebutuhan informasi ilmu pengetahuan itu sendiri. Cara pemenuhan kebutuhan
Nur Indah Pratiwi, Widodo Universitas Negeri Jakarta ABSTRAK
 Klasifikasi Dokumen Karya Akhir Mahasiswa Menggunakan Naïve Bayes Classifier (NBC) Berdasarkan Abstrak Karya Akhir Di Jurusan Teknik Elektro Universitas Negeri Jakarta Nur Indah Pratiwi, Widodo Universitas
Klasifikasi Dokumen Karya Akhir Mahasiswa Menggunakan Naïve Bayes Classifier (NBC) Berdasarkan Abstrak Karya Akhir Di Jurusan Teknik Elektro Universitas Negeri Jakarta Nur Indah Pratiwi, Widodo Universitas
IMPLEMENTASI VECTOR SPACE MODEL UNTUK MENINGKATKAN KUALITAS PADA SISTEM PENCARIAN BUKU PERPUSTAKAAN
 Seminar Nasional Informatika 205 IMPLEMENTASI VECTOR SPACE MODEL UNTUK MENINGKATKAN KUALITAS PADA SISTEM PENCARIAN BUKU PERPUSTAKAAN Dedi Leman, Khusaeri Andesa 2 Teknik Informasi, Magister Komputer, Universitas
Seminar Nasional Informatika 205 IMPLEMENTASI VECTOR SPACE MODEL UNTUK MENINGKATKAN KUALITAS PADA SISTEM PENCARIAN BUKU PERPUSTAKAAN Dedi Leman, Khusaeri Andesa 2 Teknik Informasi, Magister Komputer, Universitas
BAB III LANDASAN TEORI
 BAB III LANDASAN TEORI 1.1. Konsep Dasar Sistem Sistem adalah kumpulan elemen yang saling terkait dan bertanggung jawab memproses masukan (input) sehingga menghasilkan keluaran (output). Elemen-elemen
BAB III LANDASAN TEORI 1.1. Konsep Dasar Sistem Sistem adalah kumpulan elemen yang saling terkait dan bertanggung jawab memproses masukan (input) sehingga menghasilkan keluaran (output). Elemen-elemen
PENYUSUNAN STRONG S CONCORDANCE UNTUK ALKITAB PERJANJIAN BARU BAHASA INDONESIA.
 PENYUSUNAN STRONG S CONCORDANCE UNTUK ALKITAB PERJANJIAN BARU BAHASA INDONESIA Gunawan 1, Devi Dwi Purwanto, Herman Budianto, dan Indra Maryati 1 Jurusan Teknik Elektro, Fakultas Teknologi Industri, Institut
PENYUSUNAN STRONG S CONCORDANCE UNTUK ALKITAB PERJANJIAN BARU BAHASA INDONESIA Gunawan 1, Devi Dwi Purwanto, Herman Budianto, dan Indra Maryati 1 Jurusan Teknik Elektro, Fakultas Teknologi Industri, Institut
BAB 3 LANDASAN TEORI
 BAB 3 LANDASAN TEORI Pada bab ini akan dibahas mengenai beberapa landasan teori yang digunakan untuk perancangan dan pembuatan aplikasi rekomendasi informasi yang bisa dijadikan sebagai acuan. 3.1 Media
BAB 3 LANDASAN TEORI Pada bab ini akan dibahas mengenai beberapa landasan teori yang digunakan untuk perancangan dan pembuatan aplikasi rekomendasi informasi yang bisa dijadikan sebagai acuan. 3.1 Media
BAB III METODOLOGI PENELITIAN
 BAB III METODOLOGI PENELITIAN berikut. Tahapan penelitian yang dilakukan dalam penelitian adalah sebagai Indentifikasi Masalah Merumuskan Masalah Study Literatur Perancangan : 1. Flat Teks 2. Database
BAB III METODOLOGI PENELITIAN berikut. Tahapan penelitian yang dilakukan dalam penelitian adalah sebagai Indentifikasi Masalah Merumuskan Masalah Study Literatur Perancangan : 1. Flat Teks 2. Database
Penanganan Kasus Overstemming dan Understemming dengan Modifikasi Algoritma Stemming
 Penanganan Kasus Overstemming dan Understemming dengan Modifikasi Algoritma Stemming Stephanie Betha R.H Informatika, AMIK Purnama Niaga Indramayu Jl Ir.H.Djuanda No.256 Indramayu ntephbetha@gmail.com
Penanganan Kasus Overstemming dan Understemming dengan Modifikasi Algoritma Stemming Stephanie Betha R.H Informatika, AMIK Purnama Niaga Indramayu Jl Ir.H.Djuanda No.256 Indramayu ntephbetha@gmail.com
Implementasi Stemmer Tala pada Aplikasi Berbasis Web
 Mardi Siswo Utomo Program Studi Teknik Informatika, Universitas Stikubank email : mardiutomo@gmail.com Abstrak Stemming adalah proses untuk mencari kata dasar pada suatu kata. Pada analisa temu kembali
Mardi Siswo Utomo Program Studi Teknik Informatika, Universitas Stikubank email : mardiutomo@gmail.com Abstrak Stemming adalah proses untuk mencari kata dasar pada suatu kata. Pada analisa temu kembali
INFORMATION RETRIEVAL SYSTEM PADA PENCARIAN FILE DOKUMEN BERBASIS TEKS DENGAN METODE VECTOR SPACE MODEL DAN ALGORITMA ECS STEMMER
 INFORMATION RETRIEVAL SSTEM PADA PENCARIAN FILE DOKUMEN BERBASIS TEKS DENGAN METODE VECTOR SPACE MODEL DAN ALGORITMA ECS STEMMER Muhammad asirzain 1), Suswati 2) 1,2 Teknik Informatika, Fakultas Teknik,
INFORMATION RETRIEVAL SSTEM PADA PENCARIAN FILE DOKUMEN BERBASIS TEKS DENGAN METODE VECTOR SPACE MODEL DAN ALGORITMA ECS STEMMER Muhammad asirzain 1), Suswati 2) 1,2 Teknik Informatika, Fakultas Teknik,
Analisis Sentimen Pada Data Twitter dengan Menggunakan Text Mining terhadap Suatu Produk
 Analisis Sentimen Pada Data Twitter dengan Menggunakan Text Mining terhadap Suatu Produk Eka Retnawiyati 1, Fatoni, M.M.,M.Kom 2., Edi Surya Negara, M.Kom 3 1) Mahasiswa Informatika Universitas Bina Darma
Analisis Sentimen Pada Data Twitter dengan Menggunakan Text Mining terhadap Suatu Produk Eka Retnawiyati 1, Fatoni, M.M.,M.Kom 2., Edi Surya Negara, M.Kom 3 1) Mahasiswa Informatika Universitas Bina Darma
KLASIFIKASI DATA PENGADUAN MASYARAKAT PADA LAMAN PESDUK CIMAHI MENGGUNAKAN ROCCHIO
 F.15 KLASIFIKASI DATA PENGADUAN MASYARAKAT PADA LAMAN PESDUK CIMAHI MENGGUNAKAN ROCCHIO Khusnul Khuluqiyah *, Tacbir Hendro Pudjiantoro, Agung Wahana Program Studi Informatika, Fakultas Matematika dan
F.15 KLASIFIKASI DATA PENGADUAN MASYARAKAT PADA LAMAN PESDUK CIMAHI MENGGUNAKAN ROCCHIO Khusnul Khuluqiyah *, Tacbir Hendro Pudjiantoro, Agung Wahana Program Studi Informatika, Fakultas Matematika dan
SENTIMENT ANALYSIS TOKOH POLITIK PADA TWITTER
 SENTIMENT ANALYSIS TOKOH POLITIK PADA TWITTER Agung Pramono 1, Rini Indriati 2, Arie Nugroho 3, 1,2,3 Sistem Informasi, Fakultas Teknik, Universitas Nusantara PGRI Kediri E-mail: 1 pramonoagung0741@gmail.com,
SENTIMENT ANALYSIS TOKOH POLITIK PADA TWITTER Agung Pramono 1, Rini Indriati 2, Arie Nugroho 3, 1,2,3 Sistem Informasi, Fakultas Teknik, Universitas Nusantara PGRI Kediri E-mail: 1 pramonoagung0741@gmail.com,
Sistem Temu Kembali Informasi Menggunakan Model Ruang Vektor dan Inverted Index
 Vol 2, No 3 Juni 2012 ISSN 2088-2130 Sistem Temu Kembali Informasi Menggunakan Model Ruang Vektor dan Inverted Index Fika Hastarita Rachman Jurusan Teknik Informatika, Fakultas Teknik, Universitas Trunojoyo
Vol 2, No 3 Juni 2012 ISSN 2088-2130 Sistem Temu Kembali Informasi Menggunakan Model Ruang Vektor dan Inverted Index Fika Hastarita Rachman Jurusan Teknik Informatika, Fakultas Teknik, Universitas Trunojoyo
BAB II LANDASAN TEORI
 BAB II LANDASAN TEORI 2.1 Kata Pengertian kata secara sederhana adalah sekumpulan huruf yang mempunyai arti. Dalam kamus besar bahasa indonesia (KBBI) pengertian kata adalah unsur bahasa yang diucapkan
BAB II LANDASAN TEORI 2.1 Kata Pengertian kata secara sederhana adalah sekumpulan huruf yang mempunyai arti. Dalam kamus besar bahasa indonesia (KBBI) pengertian kata adalah unsur bahasa yang diucapkan
BAB IV ANALISA DAN PERANCANGAN
 BAB IV ANALISA DAN PERANCANGAN Pada bab ini akan dibahas mengenai analisa proses information retrieval dengan menggunakan cosine similarity dan analisa proses rekomendasi buku dengan menggunakan jaccard
BAB IV ANALISA DAN PERANCANGAN Pada bab ini akan dibahas mengenai analisa proses information retrieval dengan menggunakan cosine similarity dan analisa proses rekomendasi buku dengan menggunakan jaccard
BAB I PENDAHULUAN.
 BAB I PENDAHULUAN 1.1. Latar Belakang Saat ini smartphone telah berevolusi menjadi komputer pribadi kecil dan portabel yang memungkinkan pengguna untuk melakukan penjelajahan internet, mengirim e-mail
BAB I PENDAHULUAN 1.1. Latar Belakang Saat ini smartphone telah berevolusi menjadi komputer pribadi kecil dan portabel yang memungkinkan pengguna untuk melakukan penjelajahan internet, mengirim e-mail
dimana P(A B) artinya peluang A jika diketahui keadaan B. Kemudian dari persamaan 2.1 didapatkan persamaan 2.2.
 artinya peluang A jika diketahui keadaan B. Kemudian dari persamaan 2.1 didapatkan persamaan 2.2.") 1.1 Naive Bayes Classifier Naive bayes classifier merupakan salah satu metode machine learning yang dapat digunakan untuk klasifikasi suatu dokumen. Teorema bayes berawal dari persamaan 2.1, yaitu: (2.1)
1.1 Naive Bayes Classifier Naive bayes classifier merupakan salah satu metode machine learning yang dapat digunakan untuk klasifikasi suatu dokumen. Teorema bayes berawal dari persamaan 2.1, yaitu: (2.1)
Search Engines. Information Retrieval in Practice
 Search Engines Information Retrieval in Practice All slides Addison Wesley, 2008 Search Engine Architecture Arsitektur dari mesin pencari ditentukan oleh 2 persyaratan efektivitas (kualitas hasil) efisiensi
Search Engines Information Retrieval in Practice All slides Addison Wesley, 2008 Search Engine Architecture Arsitektur dari mesin pencari ditentukan oleh 2 persyaratan efektivitas (kualitas hasil) efisiensi
BAB II LANDASAN TEORI
 BAB II LANDASAN TEORI 2.1 Sentimen Analisis Analisis sentimen juga dapat dikatakan sebagai opinion mining. Analisis sentimen dapat digunakan dalam berbagai kemungkian domain, dari produk konsumen, jasa
BAB II LANDASAN TEORI 2.1 Sentimen Analisis Analisis sentimen juga dapat dikatakan sebagai opinion mining. Analisis sentimen dapat digunakan dalam berbagai kemungkian domain, dari produk konsumen, jasa
TEKNIK VECTOR SPACE MODEL (VSM) DALAM PENENTUAN PENANGANAN DAMPAK GAME ONLINE PADA ANAK
 DALAM PENENTUAN PENANGANAN DAMPAK GAME ONLINE PADA ANAK") F.13 TEKNIK VECTOR SPACE MODEL (VSM) DALAM PENENTUAN PENANGANAN DAMPAK GAME ONLINE PADA ANAK Bania Amburika 1*,Yulison Herry Chrisnanto 1, Wisnu Uriawan 2 1 Jurusan Informatika, Fakultas MIPA, Universitas
F.13 TEKNIK VECTOR SPACE MODEL (VSM) DALAM PENENTUAN PENANGANAN DAMPAK GAME ONLINE PADA ANAK Bania Amburika 1*,Yulison Herry Chrisnanto 1, Wisnu Uriawan 2 1 Jurusan Informatika, Fakultas MIPA, Universitas
BAB III ANALISIS PENYELESAIAN MASALAH
 BAB III ANALISIS PENYELESAIAN MASALAH Pada bab ini akan dipaparkan analisis yang dilakukan dalam pengerjaan Tugas Akhir ini. Analisis diawali dengan analisis terhadap konsep Bayesian network yang diperlukan
BAB III ANALISIS PENYELESAIAN MASALAH Pada bab ini akan dipaparkan analisis yang dilakukan dalam pengerjaan Tugas Akhir ini. Analisis diawali dengan analisis terhadap konsep Bayesian network yang diperlukan
BAB IV HASIL DAN PEMBAHASAN. jenis dokumen, yaitu dokumen training dan dokumen uji. Kemudian dua
 BAB IV HASIL DAN PEMBAHASAN 4.1. Dokumen yang digunakan Pada penelitian yang dilakukan oleh penulis ini menggunakan dua jenis dokumen, yaitu dokumen training dan dokumen uji. Kemudian dua jenis dokumen
BAB IV HASIL DAN PEMBAHASAN 4.1. Dokumen yang digunakan Pada penelitian yang dilakukan oleh penulis ini menggunakan dua jenis dokumen, yaitu dokumen training dan dokumen uji. Kemudian dua jenis dokumen
BAB I PENDAHULUAN 1.1 Latar Belakang
 BAB I PENDAHULUAN 1.1 Latar Belakang Menurut Liu opini merupakan pernyataan subyektif yang mencerminkan sentimen orang atau persepsi tentang entitas dan peristiwa [1]. Opini atau pendapat orang lain terhadap
BAB I PENDAHULUAN 1.1 Latar Belakang Menurut Liu opini merupakan pernyataan subyektif yang mencerminkan sentimen orang atau persepsi tentang entitas dan peristiwa [1]. Opini atau pendapat orang lain terhadap
BAB I PENDAHULUAN 1.1 Latar Belakang
 BAB I PENDAHULUAN 1.1 Latar Belakang Analisis sentimen merupakan proses dalam mengolah, memahami, dan mengekstrak data dalam bentuk teks terhadap suatu topik, kejadian ataupun individu untuk mendapatkan
BAB I PENDAHULUAN 1.1 Latar Belakang Analisis sentimen merupakan proses dalam mengolah, memahami, dan mengekstrak data dalam bentuk teks terhadap suatu topik, kejadian ataupun individu untuk mendapatkan
Jurnal String Vol.1 No.2 Tahun 2016 ISSN :
 PERBANDINGAN ALGORITMA STEMMING PORTER DENGANARIFIN SETIONO UNTUK MENENTUKAN TINGKAT KETEPATAN KATA DASAR Dian Novitasari Program Studi Teknik Informatika, Universitas Indraprasta PGRI Emai : diannovita.unindra@gmail.com
PERBANDINGAN ALGORITMA STEMMING PORTER DENGANARIFIN SETIONO UNTUK MENENTUKAN TINGKAT KETEPATAN KATA DASAR Dian Novitasari Program Studi Teknik Informatika, Universitas Indraprasta PGRI Emai : diannovita.unindra@gmail.com
BAB III METODOLOGI PENELITIAN
 BAB III METODOLOGI PENELITIAN Metodologi Penelitian adalah sekumpulan peraturan, kegiatan, dan prosedur yang digunakan oleh pelaku suatu disiplin ilmu. Metodologi juga merupakan analisis teoritis mengenai
BAB III METODOLOGI PENELITIAN Metodologi Penelitian adalah sekumpulan peraturan, kegiatan, dan prosedur yang digunakan oleh pelaku suatu disiplin ilmu. Metodologi juga merupakan analisis teoritis mengenai
BAB 3 ANALISIS DAN PERANCANGAN
 BAB 3 ANALISIS DAN PERANCANGAN 3.1 Analisis Masalah Penelitian yang sudah pernah membuat sistem ini berhasil menciptakan pembangkitan pertanyaan non-factoid secara otomatis dengan menggunakan tiga jenis
BAB 3 ANALISIS DAN PERANCANGAN 3.1 Analisis Masalah Penelitian yang sudah pernah membuat sistem ini berhasil menciptakan pembangkitan pertanyaan non-factoid secara otomatis dengan menggunakan tiga jenis
ISSN : e-proceeding of Engineering : Vol.2, No.2 Agustus 2015 Page 6665
 ISSN : 2355-9365 e-proceeding of Engineering : Vol.2, No.2 Agustus 2015 Page 6665 Analisis Efektifitas Pengukuran Keterkaitan Antar Teks Menggunakan Metode Salient Semantic Analysis Dengan TextRank for
ISSN : 2355-9365 e-proceeding of Engineering : Vol.2, No.2 Agustus 2015 Page 6665 Analisis Efektifitas Pengukuran Keterkaitan Antar Teks Menggunakan Metode Salient Semantic Analysis Dengan TextRank for
BAB 2 LANDASAN TEORI
 BAB 2 LANDASAN TEORI 2.1 Text Mining Text mining, yang juga disebut sebagai Teks Data Mining (TDM) atau Knowledge Discovery in Text (KDT), secara umum mengacu pada proses ekstraksi informasi dari dokumen-dokumen
BAB 2 LANDASAN TEORI 2.1 Text Mining Text mining, yang juga disebut sebagai Teks Data Mining (TDM) atau Knowledge Discovery in Text (KDT), secara umum mengacu pada proses ekstraksi informasi dari dokumen-dokumen
Tugas Makalah. Sistem Temu Kembali Informasi (STKI) TI Implementasi Metode Generalized Vector Space Model Pada Information Retrieval System
 TI Implementasi Metode Generalized Vector Space Model Pada Information Retrieval System") Tugas Makalah Sistem Temu Kembali Informasi (STKI) TI029306 Implementasi Metode Generalized Vector Space Model Pada Information Retrieval System Oleh : I PUTU ANDREAS WARANU 1204505042 Dosen : I Putu Agus
Tugas Makalah Sistem Temu Kembali Informasi (STKI) TI029306 Implementasi Metode Generalized Vector Space Model Pada Information Retrieval System Oleh : I PUTU ANDREAS WARANU 1204505042 Dosen : I Putu Agus
JURNAL SENTIMENT ANALYSIS TOKOH POLITIK PADA TWITTER SENTIMENT ANALYSIS POLITICAL LEADERS IN TWITTER
 JURNAL SENTIMENT ANALYSIS TOKOH POLITIK PADA TWITTER SENTIMENT ANALYSIS POLITICAL LEADERS IN TWITTER Oleh: AGUNG PRAMONO PUTRO 12.1.03.03.0276 Dibimbing oleh : 1. NURSALIM, S.Pd,. MH 2. ARIE NUGROHO, S.Kom.,
JURNAL SENTIMENT ANALYSIS TOKOH POLITIK PADA TWITTER SENTIMENT ANALYSIS POLITICAL LEADERS IN TWITTER Oleh: AGUNG PRAMONO PUTRO 12.1.03.03.0276 Dibimbing oleh : 1. NURSALIM, S.Pd,. MH 2. ARIE NUGROHO, S.Kom.,
Klasifikasi Berita Lokal Radar Malang Menggunakan Metode Naïve Bayes Dengan Fitur N-Gram
 Jurnal Ilmiah Teknologi dan Informasia ASIA (JITIKA) Vol.10, No.1, Februari 2016 ISSN: 0852-730X Klasifikasi Berita Lokal Radar Malang Menggunakan Metode Naïve Bayes Dengan Fitur N-Gram Denny Nathaniel
Jurnal Ilmiah Teknologi dan Informasia ASIA (JITIKA) Vol.10, No.1, Februari 2016 ISSN: 0852-730X Klasifikasi Berita Lokal Radar Malang Menggunakan Metode Naïve Bayes Dengan Fitur N-Gram Denny Nathaniel
PENCARIAN DOKUMEN MENGGUNAKAN METODE SINGLE PASS CLUSTERING (STUDI KASUS : ABSTRAKSI TA TEKNIK INFORMATIKA UNIV. MUHAMMADIYAH MALANG) TUGAS AKHIR
 TUGAS AKHIR") PENCARIAN DOKUMEN MENGGUNAKAN METODE SINGLE PASS CLUSTERING (STUDI KASUS : ABSTRAKSI TA TEKNIK INFORMATIKA UNIV. MUHAMMADIYAH MALANG) TUGAS AKHIR Sebagai Persyaratan Guna Meraih Gelar Sarjana Strata 1
PENCARIAN DOKUMEN MENGGUNAKAN METODE SINGLE PASS CLUSTERING (STUDI KASUS : ABSTRAKSI TA TEKNIK INFORMATIKA UNIV. MUHAMMADIYAH MALANG) TUGAS AKHIR Sebagai Persyaratan Guna Meraih Gelar Sarjana Strata 1
BAB 3 LANDASAN TEORI
 BAB 3 LANDASAN TEORI 3.1. Data Mining Data mining adalah proses menganalisa data dari perspektif yang berbeda dan menyimpulkannya menjadi informasi-informasi penting yang dapat dipakai untuk meningkatkan
BAB 3 LANDASAN TEORI 3.1. Data Mining Data mining adalah proses menganalisa data dari perspektif yang berbeda dan menyimpulkannya menjadi informasi-informasi penting yang dapat dipakai untuk meningkatkan
SISTEM PENCARIAN PASAL-PASAL PADA KITAB UNDANG-UNDANG HUKUM PIDANA DENGAN MENGGUNAKAN METODE TF-IDF. Abstrak
 SISTEM PENCARIAN PASAL-PASAL PADA KITAB UNDANG-UNDANG HUKUM PIDANA DENGAN MENGGUNAKAN METODE TF-IDF Muh. Alfarisi Ali¹, Moh. Hidayat Koniyo², Abd. Aziz Bouty³ ¹Mahasiswa Teknik Informatika Universitas
SISTEM PENCARIAN PASAL-PASAL PADA KITAB UNDANG-UNDANG HUKUM PIDANA DENGAN MENGGUNAKAN METODE TF-IDF Muh. Alfarisi Ali¹, Moh. Hidayat Koniyo², Abd. Aziz Bouty³ ¹Mahasiswa Teknik Informatika Universitas
commit to user BAB II TINJAUAN PUSTAKA
 BAB II TINJAUAN PUSTAKA 2.1 Dasar Teori 2.1.1 Cosine Similarity Secara umum, fungsi similarity adalah fungsi yang menerima dua buah objek dan mengembalikan nilai kemiripan (similarity) antara kedua objek
BAB II TINJAUAN PUSTAKA 2.1 Dasar Teori 2.1.1 Cosine Similarity Secara umum, fungsi similarity adalah fungsi yang menerima dua buah objek dan mengembalikan nilai kemiripan (similarity) antara kedua objek
PEMANFAATAN ALGORITMA TF/IDF UNTUK SISTEM INFORMASI e-complaint HANDLING
 PEMANFAATAN ALGORITMA TF/IDF UNTUK SISTEM INFORMASI e-complaint HANDLING Rudhi Ardi Sasmita Jurusan Sistem Informasi, Fakultas Ilmu Komputer, Universitas Narotama Surabaya rudhisasmito@gmail.com Abstrak
PEMANFAATAN ALGORITMA TF/IDF UNTUK SISTEM INFORMASI e-complaint HANDLING Rudhi Ardi Sasmita Jurusan Sistem Informasi, Fakultas Ilmu Komputer, Universitas Narotama Surabaya rudhisasmito@gmail.com Abstrak
BAB I PENDAHULUAN. Information retrieval (IR) adalah ilmu yang mempelajari pencarian
 adalah ilmu yang mempelajari pencarian") BAB I PENDAHULUAN 1.1 Latar Belakang Information retrieval (IR) adalah ilmu yang mempelajari pencarian dokumen untuk memenuhi kebutuhan informasi dari dalam koleksi besar media penyimpanan komputer (Manning,
BAB I PENDAHULUAN 1.1 Latar Belakang Information retrieval (IR) adalah ilmu yang mempelajari pencarian dokumen untuk memenuhi kebutuhan informasi dari dalam koleksi besar media penyimpanan komputer (Manning,
Tugas Makalah. Sistem Temu Kembali Informasi (STKI) TI Implementasi Metode Generalized Vector Space Model Pada Information Retrieval System
 TI Implementasi Metode Generalized Vector Space Model Pada Information Retrieval System") Tugas Makalah Sistem Temu Kembali Informasi (STKI) TI029306 Implementasi Metode Generalized Vector Space Model Pada Information Retrieval System Oleh : I PUTU ANDREAS WARANU 1204505042 Dosen : I Putu Agus
Tugas Makalah Sistem Temu Kembali Informasi (STKI) TI029306 Implementasi Metode Generalized Vector Space Model Pada Information Retrieval System Oleh : I PUTU ANDREAS WARANU 1204505042 Dosen : I Putu Agus
APLIKASI PENDETEKSI KEMIRIPANPADA DOKUMEN MENGGUNAKAN ALGORITMA RABIN KARP
 APLIKASI PENDETEKSI KEMIRIPANPADA DOKUMEN MENGGUNAKAN ALGORITMA RABIN KARP Inta Widiastuti 1, Cahya Rahmad 2, Yuri Ariyanto 3 1,2 Jurusan Elektro, Program Studi Teknik Informatika, Politeknik Negeri Malang
APLIKASI PENDETEKSI KEMIRIPANPADA DOKUMEN MENGGUNAKAN ALGORITMA RABIN KARP Inta Widiastuti 1, Cahya Rahmad 2, Yuri Ariyanto 3 1,2 Jurusan Elektro, Program Studi Teknik Informatika, Politeknik Negeri Malang
BAB 1 PENDAHULUAN. 1.1 Latar Belakang
 1 BAB 1 PENDAHULUAN 1.1 Latar Belakang Plagiarisme atau sering disebut plagiat adalah penjiplakan atau pengambilan karangan, pendapat, dan sebagainya dari orang lain dan menjadikannya seolah-olah karangan
1 BAB 1 PENDAHULUAN 1.1 Latar Belakang Plagiarisme atau sering disebut plagiat adalah penjiplakan atau pengambilan karangan, pendapat, dan sebagainya dari orang lain dan menjadikannya seolah-olah karangan
BAB 2 TINJAUAN PUSTAKA
 BAB 2 TINJAUAN PUSTAKA 2.1 Analisis sentimen Analisis sentimen atau opinion mining merupakan proses memahami, mengekstrak dan mengolah data tekstual secara otomatis untuk mendapatkan informasi sentimen
BAB 2 TINJAUAN PUSTAKA 2.1 Analisis sentimen Analisis sentimen atau opinion mining merupakan proses memahami, mengekstrak dan mengolah data tekstual secara otomatis untuk mendapatkan informasi sentimen
BAB I PERSYARATAN PRODUK
 BAB I PERSYARATAN PRODUK 1.1 PENDAHULUAN Pada saat kita melakukan pencarian melalui search engine (google.com, yahoo, dsb), kita bisa mendapatkan beberapa hasil, yang berupa dokumen - dokumen yang sama
BAB I PERSYARATAN PRODUK 1.1 PENDAHULUAN Pada saat kita melakukan pencarian melalui search engine (google.com, yahoo, dsb), kita bisa mendapatkan beberapa hasil, yang berupa dokumen - dokumen yang sama
BAB I PENDAHULUAN 1.1 Latar Belakang
 BAB I PENDAHULUAN 1.1 Latar Belakang Buku merupakan media informasi yang memiliki peran penting dalam perkembangan ilmu pengetahuan, karena dengan buku kita dapat memperoleh banyak informasi, pengetahuan
BAB I PENDAHULUAN 1.1 Latar Belakang Buku merupakan media informasi yang memiliki peran penting dalam perkembangan ilmu pengetahuan, karena dengan buku kita dapat memperoleh banyak informasi, pengetahuan
BAB II LANDASAN TEORI
 BAB II LANDASAN TEORI 2.1 Information Retrieval System Sistem temu kembali informasi ( information retrieval system) merupakan sistem yang dapat digunakan untuk menemukan informasi yang relevan dengan
BAB II LANDASAN TEORI 2.1 Information Retrieval System Sistem temu kembali informasi ( information retrieval system) merupakan sistem yang dapat digunakan untuk menemukan informasi yang relevan dengan
BAB I PENDAHULUAN 1.1 Latar Belakang
 BAB I PENDAHULUAN 1.1 Latar Belakang Meningkatnya perkembangan teknologi juga diikuti dengan berkembangnya penggunaan berbagai situs jejaring sosial. Salah satu jejaring sosial yang sangat marak digunakan
BAB I PENDAHULUAN 1.1 Latar Belakang Meningkatnya perkembangan teknologi juga diikuti dengan berkembangnya penggunaan berbagai situs jejaring sosial. Salah satu jejaring sosial yang sangat marak digunakan
Budi Susanto Versi /08/2012. Teknik Informatika UKDW Yogyakarta
 Budi Susanto Versi 1.0 29/08/2012 1 Memahami pengertian dari text mining dan web mining Memahami latar belakang perlunya pengolahan dokumen teks dan web Memahami arsitektur dasar aplikasi text dan web
Budi Susanto Versi 1.0 29/08/2012 1 Memahami pengertian dari text mining dan web mining Memahami latar belakang perlunya pengolahan dokumen teks dan web Memahami arsitektur dasar aplikasi text dan web
BAB IV IMPLEMENTASI DAN PENGUJIAN
 90 BAB IV IMPLEMENTASI DAN PENGUJIAN 4.1 Implementasi Sistem Tahap ini merupakan tahap dari implementasi program serta implementasi dari setiap proses tahap penelitian. 4.1.2 Persiapan Arsitektur Pada
90 BAB IV IMPLEMENTASI DAN PENGUJIAN 4.1 Implementasi Sistem Tahap ini merupakan tahap dari implementasi program serta implementasi dari setiap proses tahap penelitian. 4.1.2 Persiapan Arsitektur Pada
Pengklasifikasian Pengaduan Masyarakat pada Laman Kantor Pertanahan Kota Surabaya I dengan Metode Pohon Keputusan
 Pengklasifikasian Pengaduan Masyarakat pada Laman Kantor Pertanahan Kota Surabaya I dengan Metode Pohon Keputusan Penyusun Tugas Akhir : Yulia Sulistyaningsih 5208 100 113 Dosen Pembimbing : Prof. Ir.
Pengklasifikasian Pengaduan Masyarakat pada Laman Kantor Pertanahan Kota Surabaya I dengan Metode Pohon Keputusan Penyusun Tugas Akhir : Yulia Sulistyaningsih 5208 100 113 Dosen Pembimbing : Prof. Ir.
BAB I. Pendahuluan. 1. Latar Belakang Masalah
 BAB I Pendahuluan 1. Latar Belakang Masalah Semakin canggihnya teknologi di bidang komputasi dan telekomunikasi pada masa kini, membuat informasi dapat dengan mudah didapatkan oleh banyak orang. Kemudahan
BAB I Pendahuluan 1. Latar Belakang Masalah Semakin canggihnya teknologi di bidang komputasi dan telekomunikasi pada masa kini, membuat informasi dapat dengan mudah didapatkan oleh banyak orang. Kemudahan
Jurnal Ilmiah Sains, Teknologi, Ekonomi, Sosial dan Budaya Vol. 1 No. 4 Desember 2017
 TEXT MINING DALAM PENENTUAN KLASIFIKASI DOKUMEN SKRIPSI DI PRODI TEKNIK INFORMATIKA FAKULTAS ILMU KOMPUTER BERBASIS WEB Teuku Muhammad Johan dan Riyadhul Fajri Program Studi Teknik Informatika Fakultas
TEXT MINING DALAM PENENTUAN KLASIFIKASI DOKUMEN SKRIPSI DI PRODI TEKNIK INFORMATIKA FAKULTAS ILMU KOMPUTER BERBASIS WEB Teuku Muhammad Johan dan Riyadhul Fajri Program Studi Teknik Informatika Fakultas
BAB III METODE PENELITIAN
 BAB III BAB 3 METODE PENELITIAN 3.1. Tahap pengumpulan data Data awal dalam penelitian ini adalah dokumen berupa artikel teks berita online dalam bahasa Indonesia yang dikumpulkan secara acak dari portal
BAB III BAB 3 METODE PENELITIAN 3.1. Tahap pengumpulan data Data awal dalam penelitian ini adalah dokumen berupa artikel teks berita online dalam bahasa Indonesia yang dikumpulkan secara acak dari portal
BAB 3 ANALISA DAN PERANCANGAN
 BAB 3 ANALISA AN PERANCANGAN 3.1 Gambaran Umum Pada masa sekarang ini, proses pencarian dokumen dalam web seperti Google, Yahoo, dan sebagainya dilakukan dengan menginput query yang diinginkan pada kotak
BAB 3 ANALISA AN PERANCANGAN 3.1 Gambaran Umum Pada masa sekarang ini, proses pencarian dokumen dalam web seperti Google, Yahoo, dan sebagainya dilakukan dengan menginput query yang diinginkan pada kotak
STEMMING DOKUMEN TEKS BAHASA INDONESIA MENGGUNAKAN ALGORITMA PORTER ABSTRAK
 STEMMING DOKUMEN TEKS BAHASA INDONESIA MENGGUNAKAN ALGORITMA PORTER Oleh : Lasmedi Afuan Prodi Teknik Informatika, Fakultas Sains dan Teknik, Universitas Jenderal Soedirman Jl. Mayjen Sungkono Blater Km
STEMMING DOKUMEN TEKS BAHASA INDONESIA MENGGUNAKAN ALGORITMA PORTER Oleh : Lasmedi Afuan Prodi Teknik Informatika, Fakultas Sains dan Teknik, Universitas Jenderal Soedirman Jl. Mayjen Sungkono Blater Km
Jurnal Informatika Mulawarman Vol. 10 No. 1 Februari
 Jurnal Informatika Mulawarman Vol. 10 No. 1 Februari 2015 1 KLASIFIKASI DAN PENCARIAN BUKU REFERENSI AKADEMIK MENGGUNAKAN METODE NAÏVE BAYES CLASSIFIER (NBC) (STUDI KASUS: PERPUSTAKAAN DAERAH PROVINSI
Jurnal Informatika Mulawarman Vol. 10 No. 1 Februari 2015 1 KLASIFIKASI DAN PENCARIAN BUKU REFERENSI AKADEMIK MENGGUNAKAN METODE NAÏVE BAYES CLASSIFIER (NBC) (STUDI KASUS: PERPUSTAKAAN DAERAH PROVINSI
SISTEM TEMU BALIK INFORMASI
 SISTEM TEMU BALIK INFORMASI Algoritma Nazief dan Adriani Disusun Oleh: Dyan Keke Rian Chikita Agus Dwi Prayogo 11/323494/PA/14356 11/323813/PA/14362 11/323856/PA/14367 PRODI S1 ILMU KOMPUTER JURUSAN ILMU
SISTEM TEMU BALIK INFORMASI Algoritma Nazief dan Adriani Disusun Oleh: Dyan Keke Rian Chikita Agus Dwi Prayogo 11/323494/PA/14356 11/323813/PA/14362 11/323856/PA/14367 PRODI S1 ILMU KOMPUTER JURUSAN ILMU
Sistem Temu Kembali Informasi pada Dokumen Teks Menggunakan Metode Term Frequency Inverse Document Frequency (TF-IDF)
") Sistem Temu Kembali Informasi pada Dokumen Teks Menggunakan Metode Term Frequency Inverse Document Frequency (TF-IDF) 1 Dhony Syafe i Harjanto, 2 Sukmawati Nur Endah, dan 2 Nurdin Bahtiar 1 Jurusan Matematika,
Sistem Temu Kembali Informasi pada Dokumen Teks Menggunakan Metode Term Frequency Inverse Document Frequency (TF-IDF) 1 Dhony Syafe i Harjanto, 2 Sukmawati Nur Endah, dan 2 Nurdin Bahtiar 1 Jurusan Matematika,
BAB 1 PENDAHULUAN. 1.1.Latar Belakang
 7 BAB 1 PENDAHULUAN 1.1.Latar Belakang Saat ini informasi sangat mudah didapatkan terutama melalui media internet. Dengan banyaknya informasi yang terkumpul atau tersimpan dalam jumlah yang banyak, user
7 BAB 1 PENDAHULUAN 1.1.Latar Belakang Saat ini informasi sangat mudah didapatkan terutama melalui media internet. Dengan banyaknya informasi yang terkumpul atau tersimpan dalam jumlah yang banyak, user
IMPLEMENTASI N-GRAM DALAM PENCARIAN TEKS SEBAGAI PENUNJANG APLIKASI PERPUSTAKAAN KITAB BERBAHASA ARAB. Ahmad Najibullah ( )
") IMPLEMENTASI N-GRAM DALAM PENCARIAN TEKS SEBAGAI PENUNJANG APLIKASI PERPUSTAKAAN KITAB BERBAHASA ARAB Ahmad Najibullah (51016100803) Latar Belakang (1) Penerapan Information Retrieval pada teks Berbahasa
IMPLEMENTASI N-GRAM DALAM PENCARIAN TEKS SEBAGAI PENUNJANG APLIKASI PERPUSTAKAAN KITAB BERBAHASA ARAB Ahmad Najibullah (51016100803) Latar Belakang (1) Penerapan Information Retrieval pada teks Berbahasa
BAB IV ANALISA DAN PERANCANGAN
 BAB IV ANALISA DAN PERANCANGAN 4.1 Analisa Sistem Lama Pada sistem peringkasan dokumen sebelumnya sistem sudah bisa dijalankan namun masih adanya kekurangan pada sistem tersebut yaitu penginputan dokumen
BAB IV ANALISA DAN PERANCANGAN 4.1 Analisa Sistem Lama Pada sistem peringkasan dokumen sebelumnya sistem sudah bisa dijalankan namun masih adanya kekurangan pada sistem tersebut yaitu penginputan dokumen
BAB I PENDAHULUAN Latar Belakang
 BAB I PENDAHULUAN 1.1. Latar Belakang Semakin canggihnya teknologi di bidang komputasi dan telekomunikasi pada masa kini, membuat informasi dapat dengan mudah didapatkan oleh banyak orang. Kemudahan ini
BAB I PENDAHULUAN 1.1. Latar Belakang Semakin canggihnya teknologi di bidang komputasi dan telekomunikasi pada masa kini, membuat informasi dapat dengan mudah didapatkan oleh banyak orang. Kemudahan ini
BAB V EKSPERIMEN TEXT CLASSIFICATION
 BAB V EKSPERIMEN TEXT CLASSIFICATION Pada bab ini akan dibahas eksperimen untuk membandingkan akurasi hasil text classification dengan menggunakan algoritma Naïve Bayes dan SVM dengan berbagai pendekatan
BAB V EKSPERIMEN TEXT CLASSIFICATION Pada bab ini akan dibahas eksperimen untuk membandingkan akurasi hasil text classification dengan menggunakan algoritma Naïve Bayes dan SVM dengan berbagai pendekatan
ARTIKEL KLASIFIKASI KONTEN BERITA SURAT KABAR BERDASARKAN JUDUL DENGAN TEXT MINING MENGGUNAKAN METODE NAÏVE BAYES (STUDI KASUS : RADAR KEDIRI)
") ARTIKEL KLASIFIKASI KONTEN BERITA SURAT KABAR BERDASARKAN JUDUL DENGAN TEXT MINING MENGGUNAKAN METODE NAÏVE BAYES (STUDI KASUS : RADAR KEDIRI) Oleh: Enggal Suci Febriani 3..3..35 Dibimbing oleh :. Irwan
ARTIKEL KLASIFIKASI KONTEN BERITA SURAT KABAR BERDASARKAN JUDUL DENGAN TEXT MINING MENGGUNAKAN METODE NAÏVE BAYES (STUDI KASUS : RADAR KEDIRI) Oleh: Enggal Suci Febriani 3..3..35 Dibimbing oleh :. Irwan
BAB I PENDAHULUAN 1.1 Latar Belakang
 BAB I PENDAHULUAN 1.1 Latar Belakang Bahasa Indonesia adalah bahasa resmi dari negara Indonesia. Bahasa Indonesia memiliki sekitar 23 juta penutur asli pada tahun 2010, dan lebih dari 140.000.000 penutur
BAB I PENDAHULUAN 1.1 Latar Belakang Bahasa Indonesia adalah bahasa resmi dari negara Indonesia. Bahasa Indonesia memiliki sekitar 23 juta penutur asli pada tahun 2010, dan lebih dari 140.000.000 penutur
UKDW. 1.1 Latar Belakang BAB 1 PENDAHULUAN
 BAB 1 PENDAHULUAN 1.1 Latar Belakang Perkembangan teknologi komputer yang pesat pada masa kini menjadi perhatian utama bagi manusia. Kemajuan teknologi komputer yang pesat ini menimbulkan bermacam-macam
BAB 1 PENDAHULUAN 1.1 Latar Belakang Perkembangan teknologi komputer yang pesat pada masa kini menjadi perhatian utama bagi manusia. Kemajuan teknologi komputer yang pesat ini menimbulkan bermacam-macam
UKDW 1. BAB 1 PENDAHULUAN Latar Belakang Masalah
 1. BAB 1 PENDAHULUAN 1.1. Latar Belakang Masalah Universitas yang baik dan terpercaya selalu memperhatikan perkembangan dan kondisi yang terjadi di universitas tersebut, salah satunya dengan memantau kinerja
1. BAB 1 PENDAHULUAN 1.1. Latar Belakang Masalah Universitas yang baik dan terpercaya selalu memperhatikan perkembangan dan kondisi yang terjadi di universitas tersebut, salah satunya dengan memantau kinerja
BAB III METODOLOGI PENELITIAN
 BAB III METODOLOGI PENELITIAN berikut. Tahapan penelitian yang dilakukan dalam penelitian adalah sebagai Identifikasi Masalah Merumuskan Masalah Study Literatur Perancangan Struktur Menu Interface Analisa
BAB III METODOLOGI PENELITIAN berikut. Tahapan penelitian yang dilakukan dalam penelitian adalah sebagai Identifikasi Masalah Merumuskan Masalah Study Literatur Perancangan Struktur Menu Interface Analisa
INDEXING AND RETRIEVAL ENGINE UNTUK DOKUMEN BERBAHASA INDONESIA DENGAN MENGGUNAKAN INVERTED INDEX
 INDEXING AND RETRIEVAL ENGINE UNTUK DOKUMEN BERBAHASA INDONESIA DENGAN MENGGUNAKAN INVERTED INDEX Wahyu Hidayat 1 1 Departemen Teknologi Informasi, Fakultas Ilmu Terapan, Telkom University 1 wahyuhidayat@telkomuniversity.ac.id
INDEXING AND RETRIEVAL ENGINE UNTUK DOKUMEN BERBAHASA INDONESIA DENGAN MENGGUNAKAN INVERTED INDEX Wahyu Hidayat 1 1 Departemen Teknologi Informasi, Fakultas Ilmu Terapan, Telkom University 1 wahyuhidayat@telkomuniversity.ac.id
BAB IV METODOLOGI PENELITIAN. Penelitian ini dilakukan dengan melalui empat tahap utama, dimana
 BAB IV METODOLOGI PENELITIAN Penelitian ini dilakukan dengan melalui empat tahap utama, dimana tahap pertama adalah proses pengumpulan dokumen teks yang akan digunakan data training dan data testing. Kemudian
BAB IV METODOLOGI PENELITIAN Penelitian ini dilakukan dengan melalui empat tahap utama, dimana tahap pertama adalah proses pengumpulan dokumen teks yang akan digunakan data training dan data testing. Kemudian
PENYUSUNAN STRONG S CONCORDANCE UNTUK ALKITAB PERJANJIAN BARU BAHASA INDONESIA , Indonesia.
 PENYUSUNAN STRONG S CONCORDANCE UNTUK ALKITAB PERJANJIAN BARU BAHASA INDONESIA Gunawan 1, Devi Dwi Purwanto, Herman Budianto, dan Indra Maryati 1 Jurusan Teknik Elektro, Fakultas Teknologi Industri, Institut
PENYUSUNAN STRONG S CONCORDANCE UNTUK ALKITAB PERJANJIAN BARU BAHASA INDONESIA Gunawan 1, Devi Dwi Purwanto, Herman Budianto, dan Indra Maryati 1 Jurusan Teknik Elektro, Fakultas Teknologi Industri, Institut